基于轴承故障信号特征的自适应冲击字典匹配追踪方法及应用
2014-09-06崔玲丽高立新
崔玲丽, 王 婧, 邬 娜,高立新
(北京工业大学 北京市先进制造技术重点实验室,北京 100124)
轴承作为工业传动系统的重要组成部分,其作用十分关键。但由于工程实际中轴承的运行环境恶劣,其振动信号复杂,含有大量噪声及不稳定因素,是一种典型的非平稳信号,特别是轴承出现早期缺陷时,信号故障特征十分微弱,为故障诊断造成了更大的困难。
为了对轴承故障振动信号进行有效表达,学者们试图建立多种基函数基础上的函数表达方式,稀疏分解法即是为实现这一目标而提出的新的信号处理方法[1]。
自Mallat等[2]首次引入了匹配追踪(Marching Pursuit, MP)算法这一思想以来。匹配追踪一直是稀疏分解的研究热点,研究重点主要集中在原子库的构造和原子搜索算法的选择上。
现有的用于轴承故障诊断的匹配追踪算法基本使用冲击信号模型[3],gabor或chirplet等[1,4]传统函数模型建立字典,虽然模型与故障轴承的振动信号有一定的匹配度,但是其模型中的参数并不能与被分析轴承的参数及运行转台建立起一一对应的关系,分析效果还有待提高。
在原子选择方面,遗传算法是一种较为常用的原子选择方法,可以在一定程度上降低最优原子选择的难度,但是这种方法[4-8]的分析效率还存在一定局限,还需要对待选原子进行分析及优化以进一步减小字典的冗余程度。
为了改善这种现状,本文提出了一种自适应冲击字典匹配追踪算法。该方法结合轴承故障信号特征建立字典函数模型,使得函数模型与被分析轴承建立起了一一对应的关系。在原子的选择方面,确定了冲击模型中的位置信息为首要模型参数,通过逐步变化参数的方法构造出了冗余度小、原子利用率高的自适应冲击字典,并结合匹配追踪方法实现了对轴承早期故障的分析。
1 匹配追踪基本原理
匹配追踪采用迭代的贪婪算法,它在每一次迭代过程中,从字典里选择最能匹配信号结构的一个原子来逼近信号。
对定义信号s={st,0≤t≤N-1}为一长度为N的离散时间信号,它可看作是N维线性空间的一个波形。信号s可以表示成一系列基本波形的叠加,即:
(1)
式中di是长度为N的离散波形,称之为原子,M是原子库中原子的个数。di的集合即字典,定义为一系列波形组成的集合,其数学表达形式为D={di,0≤i≤M-1}。
ri为残余信号,在每次迭代中可表示为
ri=ri-1-cidi
(2)
当分解次数为i=1时,r0=s;
ci为投影系数,即信号与原子的内积,可表示为
ci=〈ri-1,di〉
(3)
匹配追踪采用迭代的贪婪算法,它在每一次迭代过程中,从字典里选择最能匹配信号结构的一个原子来逼近信号,即需要使得ci在每次迭代中满足
ci=max〈ri-1,di〉
(4)
通过循环迭代,使得s的分解归结为如下优化问题
(5)
2 自适应冲击字典的构造方法
使用原子分解的方法进行信号处理的关键是原子库的构造与原子的选择,如果原子库的选择不合适可能无法进行信号处理或者处理的结果与实际情况有所偏差。
本文设计的原子库构造与原子的选择方法引入了转频、轴承尺寸等参数更能体现轴承故障的真实情况。在原子的选择方面利用了逐步改变参数的方法,可以提高算法的计算速度。
2.1 原子库的理论模型
轴承这种典型旋转机械的振动信号主要是由轴承滚动体与故障位置发生碰撞而产生的,这种碰撞可以看做一个弹簧阻尼系统,将出现冲击和瞬态振动特征。
为了有效匹配分析齿轮振动信号的特征结构,针对信号的结构特点,采用参数化函数模型的方法构造冲击字典,传统的字典构造方法如下所述:
冲击字典的基元函数是指数衰减函数,其函数模型为:
(6)
式中p为冲击响应的阻尼衰减特性,u为冲击响应事件发生的初始时刻,f对应于系统的阻尼固有频率,Kimp为归一化系数。
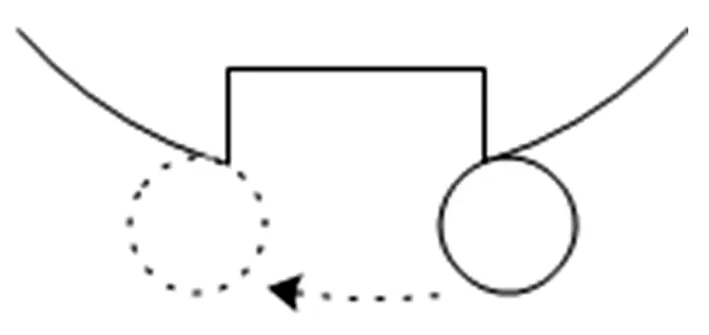
图1 物理模型图
然而对于轴承局部损伤的面积很小时,可以假定脉冲是理想脉冲,可用传统模型描述。但是当局部损伤的面积增大时,故障引起的脉冲就不可能呈一种理想状态了,而是有一定宽度的,脉冲的上升沿可认为是滚动体与故障边缘刚刚接触时的状态,脉冲的下降沿可认为是滚动体离开故障另一边沿时的状态。在时域图中可以体现为一次冲击出现两次峰值。如图1所示:
可见,使用常规方法建立的模型不能反映出一次冲击中,滚动体与故障边缘两次碰撞的复杂状态,分析精度有待提高。
通过对轴承故障机理进行详细的分析,可以判定故障引起的脉冲宽度与轴承的型号,测量过程中电机的转速,干扰情况以及局部损伤的面积大小有关。为了更准确地反映故障轴承信号的真实状态,基于上述分析结果,建立了一种能够精确反映故障大小的新模型构造冲击字典。
为得到精确的函数模型首先需计算出滚动体运动的线速度以及不同故障引起的脉冲宽度,其中滚动体线速度
s=πdfr
(7)
脉冲宽度
(8)
由此可以得到缺陷产生的脉冲可表示为:
(9)
由缺陷产生的冲击可表示为:
φimp(p,u,f,dx,d,fr)=conv(σ(t),φimp(p,u,f))
(10)
其中d为轴承小径,fr为转频,dx为故障直径(mm),其中p为冲击响应的阻尼衰减特性,u为冲击响应事件发生的初始时刻,f对应于系统的阻尼固有频率,conv为卷积运算符。
上述模型充分考虑到了轴承运行时的具体状态,与常规模型相比这种模型所建立的字典构造方法更可以反映轴承故障冲击的真实状态。
2.2 自适应冲击字典的构造方法
字典模型建立好之后,最简单的建立字典的方法是在一定的取值区间内对函数模型(10)中的参数进行离散化赋值,将一组参数代入函数模型中从而得到一个原子,所有参数组得到的原子集合即为原子库。
然而,原子模型中不能确定的参数有4个,如果在这一范围内对原子模型一一赋值,得到的原子数目将十分庞大,难以实现。为处理这一问题,学者们提出了使用遗传算法方法进行原子的选择,解决了原子选择的问题。但是这种方法字典的冗余程度仍然很大影响了运算速度和效果。
为分析轴承的故障情况,一般需要分析其振动信号的频谱图中是否含有相应的故障特征频率,对应在时域图中可表示为故障特征周期,即两相邻冲击所间隔的时间,如果冲击间的时间间隔都能固定下来那么一定可以在频谱图中找到相应的故障特征频率,从而实现轴承的故障诊断。因此,如果使用冲击原子提取出轴承故障信号中的一个冲击成分,最应当重视的参数是冲击响应事件发生的初始时刻参数u,也就是冲击的位置参数。
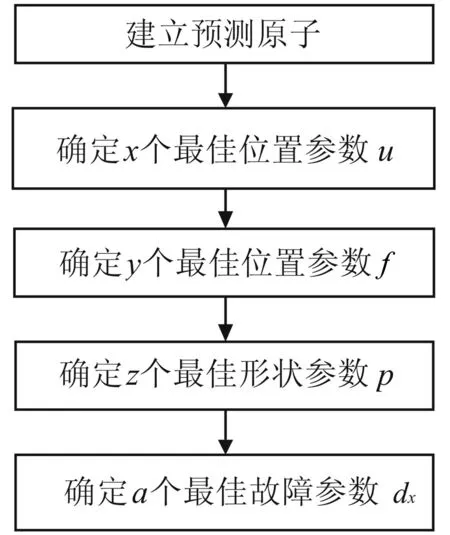
图2 自适应冲击字典建立过程
为了能够提取出被分析信号中的位置参数,可以先预测一个不含有u值的原子,即估计一组p,f,dx的取值带入到冲击函数模型中建立一个预测原子。改变预测原子的u值,即移动预测原子,与被分析信号进行内积计算。根据内积的几何意义可知,在u某一取值上得到的内积值越大,预测原子与被分析信号的匹配程度越高,该位置存在由故障引起的冲击成分的可能性越大。
随后逐步确定f,p值和dx值,将这些值代入到函数模型中即可建立一个冗余度小,并且与被分析信号故障成分匹配程度高的自适应字典,使用这种字典将会大大减少计算的时间。并且,新建立的字典中的原子与真实信号中故障的成分更为接近,这将会提高计算的准确性。
具体方法可以做如下描述:
(1)建立预测原子:为分析一个长度为n的信号,首先建立长度为n的预测冲击原子,其表达式中的f,p,dx值固定为预测值(f,p两个参数由被测轴承的特性决定,其中f的初值取为被测信号频谱图中共振带谱峰所对应的频率值,p的初值取经验值600-1 000,dx的初值在0-1之间即可),变化u值。
(2)选择u值:令预测原子的初始位置为0(u的初值为0),以1为单位位移并与被分析信号做内积运算循环n次,即预测原子由初始位置开始每移动一次与长度为n的故障信号做一次内积,比较n次内积结果,选取使得内积值最大的x个位置u值(x远小于u的取值范围,对于比较简单的故障信号x可取信号长度值的2%,对于比较复杂的信号可提高这个比例)。
(3)选择f值:将选择到的u值带一一代入到预测原子表达式中,其表达式中的p,dx值固定为步骤1中的预测值,改变f值,在x个u的取值上分别求出使得内积值最大的y个f值(y远小于f的取值范围,对于比较简单的故障信号y可取信号长度值的2%,对于比较复杂的信号可提高这个比例)。
(4)选择p值:将确定下的u值和相应f值带入预测原子表达式中,其表达式中的dx值固定为步骤1中预测值,求得z个使得内积值最大的p值(z远小于p的取值范围,对于比较简单的故障信号z可取信号长度值的1%,对于比较复杂的信号可提高这个比例)。
(5)选择dx值:最后将确定下来的p,f,u值代入预测原子表达式,求得a个使得内积值最大的dx值(a的取值远远小于dx的取值范围,对于比较简单的故障信号a可取信号长度值的1%,对于比较复杂的信号可提高这个比例)。
(6)建立字典:将p,f,u,dx的取值带入原子库模型的数学表达式中,同时进行归一化处理。
通过上述步骤可以建立一个大小为x·y·z·a的原子库。相比于对原子模型一一赋值,利用上述方法建立的原子库的冗余程度大大降低,并且其中的每一个原子都可认为能够较好表达被分析信号中冲击成分。
2.3 自适应冲击字典匹配追踪方法
根据被分析信号的特征建立好自适应原子库后,使用被分析信号与自适应原子库中的原子一一进行内积计算,在每次迭代中选择一个最匹配原子 ,并计算投影系数,直至达到迭代终止条件。
上述思想的引入称之为自适应冲击字典匹配追踪,其计算过程如下:
(1)将被分析信号分为m段,每一段的长度为n。
(2)根据待分析轴承的参数建立相应特征函数构造字典。
(3)根据待分析轴承的参数及信号特征建立原子数量为x·y·z·a,原子长度为n的自适应冲击原子库D。
(5)将原始信号x(t)赋给残差信号,得到初始残差r0。
(6)残差信号ri(i=0,1,2,…,I-1,I为迭代次数)在字典D中各寻求一个最佳匹配原子di,求出投影系数
ci=max〈ri-1,di〉
(11)
计算前i次迭代的总投影为:
(12)
(7)残差信号减去总投影,得到新的残差信号。
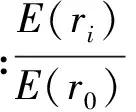
(9)分解结束,得到各阶匹配系数ci和各阶匹配原子di。
为了处理后的信号进行观测,需要对信号进行重构。重构算法是分解算法的逆过程,计算公式如下:
(13)
3 轴承法仿真信号分析
对滚动轴承外圈故障信号进行模拟仿真,信号长度为512点,如图3所示。在仿真信号的基础上加入标准正态分布随机噪声如图4所示,染噪后的信号信噪比SNR为-7.803 dB(信噪比计算公式见式(14)),其波形如图4所示。从图中可以看出,染噪后信号的冲击成分基本被淹没了。
SNP=20lg(vs/vn)
(14)
其中,vs和vn分别为原始仿真信号和噪声的有效值。
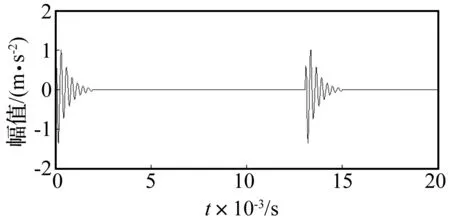
图3 不加噪的轴承仿真时域信号
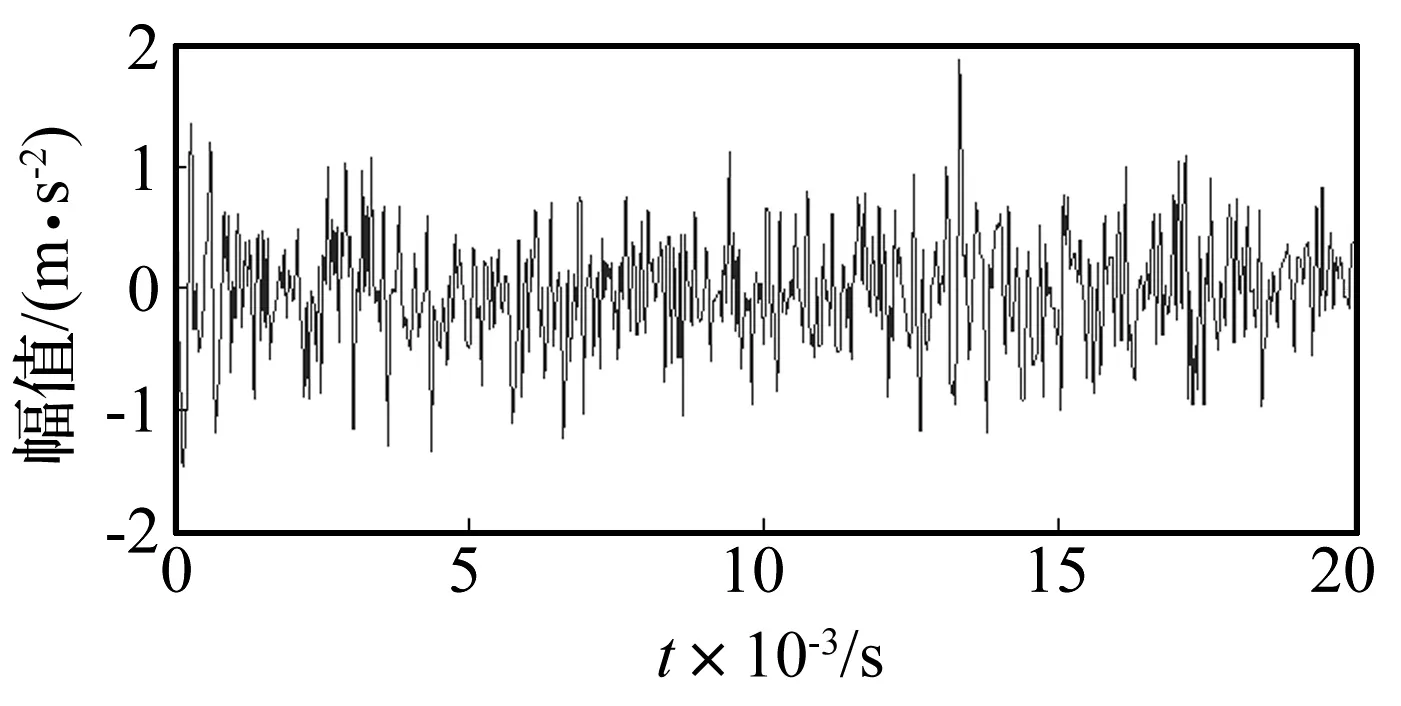
图4 加噪后轴承仿真时域信号
使用遗传算法匹配追踪的计算,其中冲击时频原子中p取值1 001~2 024,f取值1 501~3 000,u取值1~512,联合编码长度30,种群大小300,进化代数100,交叉概率0.6,变异概率0.1。得到的时域重构图如图5所示。由图5所示,使用遗传算法匹配追踪方法并不能搜索到淹没在噪声信号中的冲击成分。
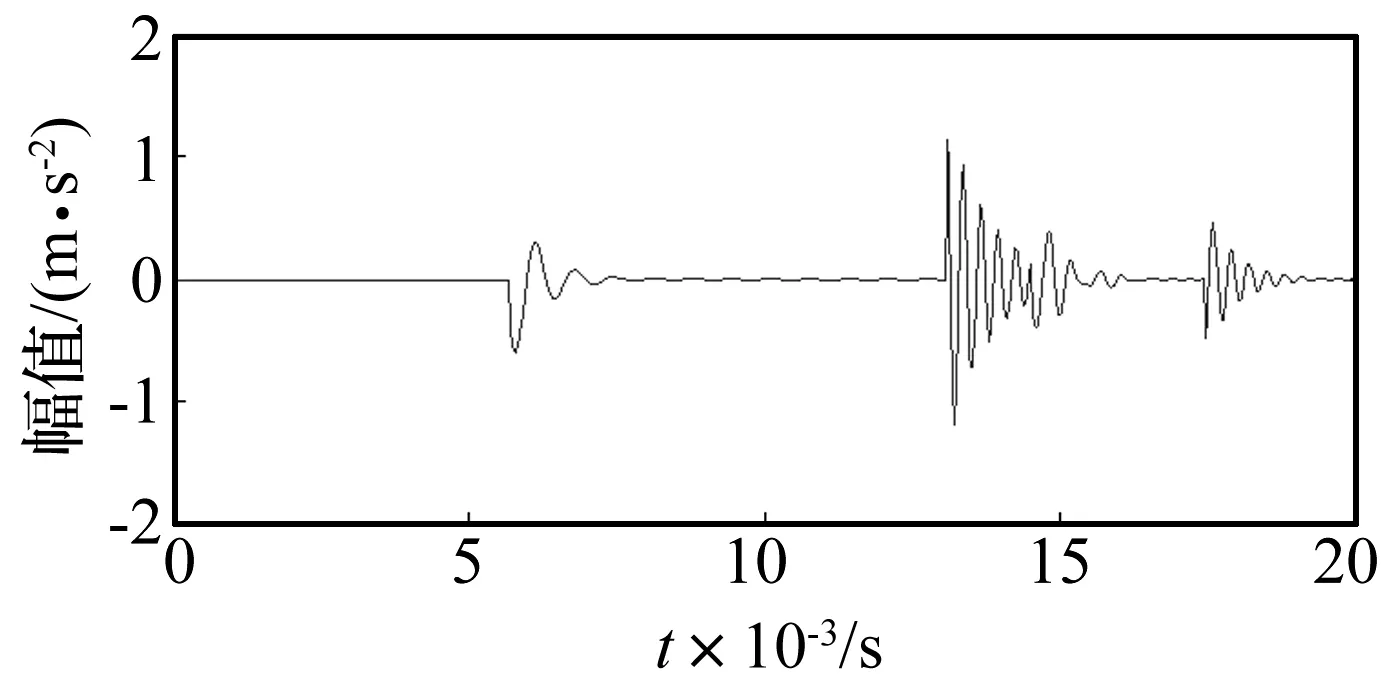
图5 使用遗传算法匹配追踪重构后的信号
使用自适应冲击字典匹配追踪的计算得到的结果如图6所示。由重构图可知,重构得到的冲击信号与原始信号的仿真结果十分接近。由此可知使用新型冲击字典的自适应冲击字典匹配追踪方法效果较好。

图6 使用自适应冲击字典匹配追踪重构后的信号
在进行信号重构的同时记录了上述两种方法的计算时间如下表所示(对于自适应冲击字典匹配追踪计算时间从该方法的步骤(1)开始计时直至信号重构结束,这段时间包括字典的构造时间)。比较各种方法的分析时间可知,使用自适应冲击字典建立方法进行匹配追踪的速度比使用遗传算法快很多。

表1 各种方法的分析时间比较
上述仿真分析可以说明自适应冲击字典匹配追踪方法在处理效果和速度上优势明显。
4 轴承实验信号分析
实验系统由轴承实验台、HG3528A数据采集仪、笔记本电脑组成。其中实验台(如图7所示)由三相异步电机①通过挠性联轴器②与装有转子④的转轴连接,轴由两个6307轴承支撑,③为正常轴承,⑤为不同点蚀模式的轴承。电机转速R=1 496 r/min(转频:24.933 Hz),轴承的大径D=80 mm,小径d=35 mm,滚动体个数为Z=8,接触角α=0。依据上述参数计算出轴承外圈故障特征频率为76.728 2 Hz,内圈故障频率为122.738 Hz,滚动体故障特征频率为99.38 Hz,采样频率为15 360 Hz,被分析信号长度为8 192点。

图7 实验台示意图
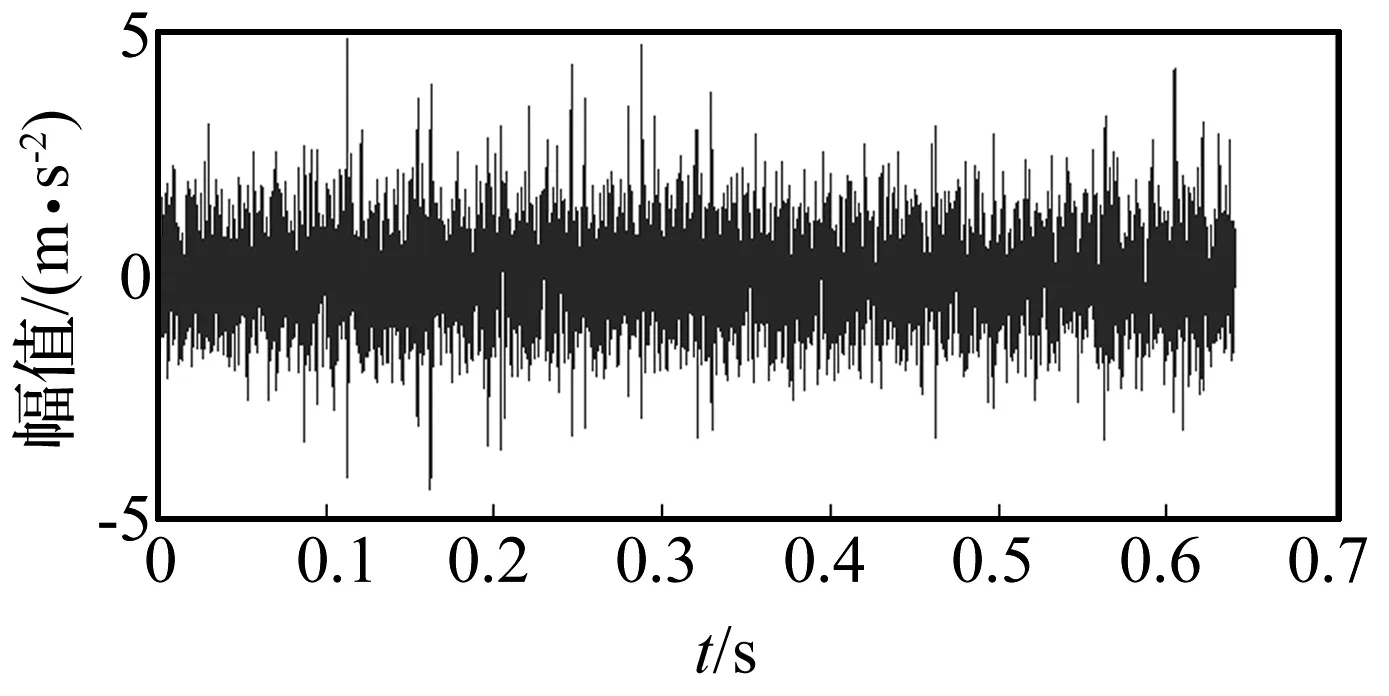
图8 故障为0.2mm内圈原始时域信号
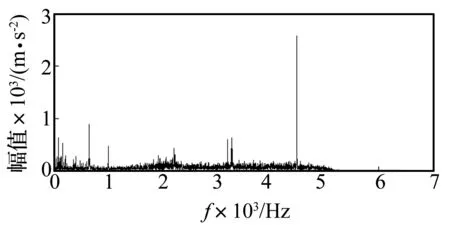
图9 故障为0.2mm内圈原始频域信号
选取内圈单点点蚀故障实验数据进行分析,点蚀直径为0.2 mm。原始信号时域及频域波形如图8所示,时域图中的冲击成分被噪声淹没,没有明显的周期冲击,其频谱图10中也没有明显的故障特征频率。
使用遗传算法匹配追踪的计算,得到频谱如图10所示,其频谱图中可以观测到一个三倍频,但是非常不清晰,效果有待于进一步优化。
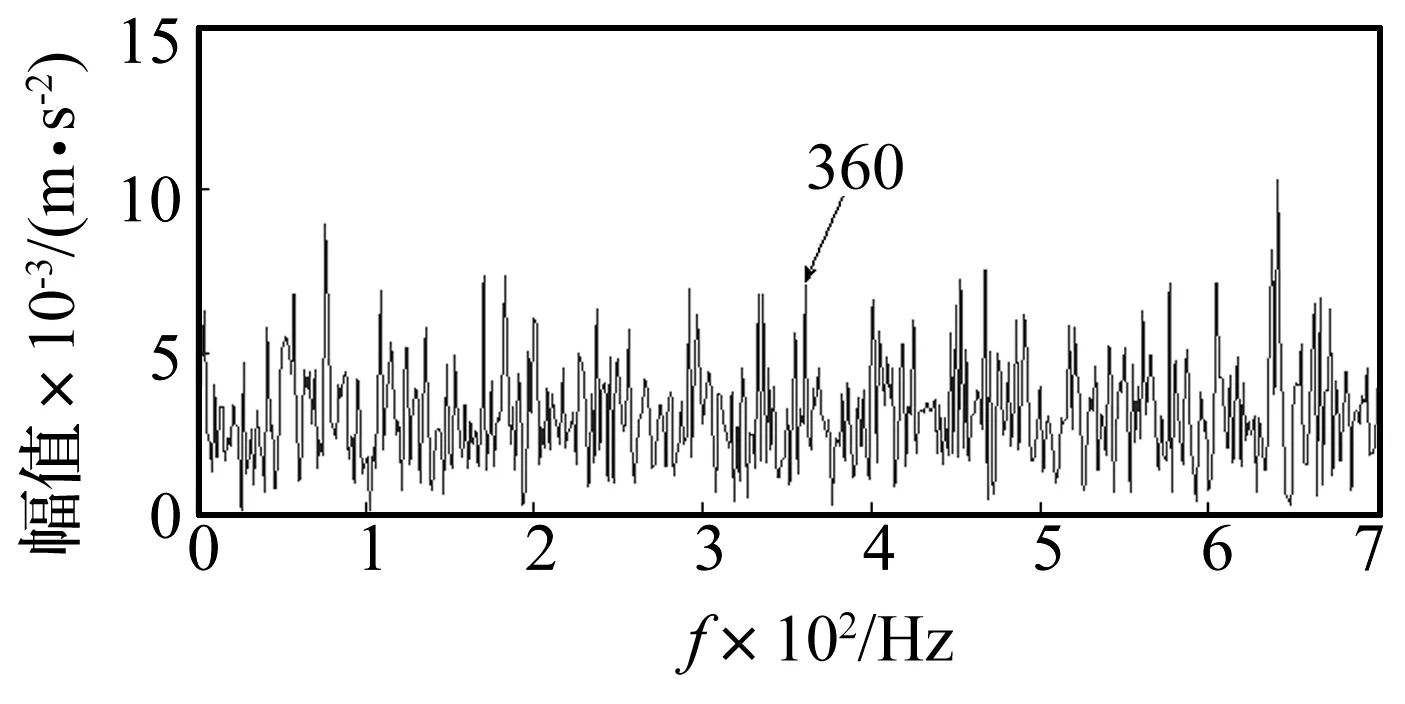
图10 遗传算法匹配追踪重构后的信号处理后频域信号
自适应冲击字典匹配追踪方法后得到频谱如图11所示。频谱中故障特征频率非常明显,且显现出了5个倍频。

图11 自适应冲击字典匹配追踪处理后频域信号
可见使用遗传算法的匹配追踪在轴承故障诊断方面都有一定的效果,但是自适应冲击字典发的效果更为明显。
5 工程信号分析
图12为某钢厂高线齿轮箱传动系统。2008年3月7日,对该钢铁企业高线增速箱南输出端水平测点进行拆箱检修,发现Ⅰ轴上增速箱南I轴角轴承外圈损坏如图13所示(如图12箭头所指轴承QJ位置)。该厂的检测系统在3月4日发现轴承状态的异常,但由于该测区共有5个共4种型号的轴承(图中椭圆位置的四种轴承D,B,NU,QJ,不包含x),不能判断故障的类型及具体位置。为了为验证自适应冲击字典方法的有效性及精确性,本文对3月1日的系统监测数据进行了深入分析。当日Ⅰ轴转速为951 r/min(即转频15.85 Hz),已知故障轴承的外圈、内圈、滚动体的故障特征频率分别:119.523,149.925,138.700。系统采样频率为10 KHz,采样点数2 048。

图12某钢厂高线齿轮箱传动系统

图13 损坏轴承
由设备监测系统提供的振动信号及其频谱图如图14、15所示。时域图中虽然显现出明显的冲击成分,但是排列非常不规律,与轴承故障特征不符,预测为噪声信号,这说明测量环境中的背景噪声比较严重,增大了诊断的难度。其频谱图中没有显示出故障特征。

图14 原始时域波形

图15 原始频域波形
使用遗传算法匹配追踪的计算得到频谱如图16所示,其频谱图中可以找到一个不太明显的外圈故障特征近似值117 Hz。但是效果非常不明显,有待进一步改进使用的自适应冲击字典匹配追踪算法进行处理后得到的频域图如图17所示,其频域波形可以找到清晰的轴承外圈故障特征频率,并且有倍频成分。说明被分析轴承在外圈上都存在故障。

图16 遗传算法匹配追踪处理后频域信号

图17 自适应冲击字典匹配追踪处理后频域信号
可见使用遗传算法和自适应冲击字典法的匹配追踪在工程实际轴承故障诊断方面都有一定的效果,但是使用自适应冲击字典方法的效果更为明显。
6 结 论
(1)对原有轴承损伤性故障冲击模型进行了改进,在模型中引入了故障大小,转频,轴承小径等参数,使得原子库模型能够准确表达出不同型号,运行环境,故障大小的轴承所引起的不同冲击响应。
(2)建立了一种自适应冲击字典的构造方法,在选择好冲击位置信息的基础上选择其它模型参数,使得字典中的每一个原子都与被分析信号有很好的相似度,降低了字典的冗余程度。
(3)利用上述的自适应冲击字典构造方法结合匹配追踪算法提出了自适应冲击字典匹配追踪的方法。
(4)仿真数据表明使用自适应冲击字典匹配追踪方法的计算速度要快于使用遗传算法进行匹配追踪的计算速度。
(5)实验数据和工程数据分析结果表明所建立自适应冲击字典匹配追踪的方法可以对轴承不同位置的故障进行有效诊断。
[1]褚福磊,彭志科,冯志鹏,等. 机械故障诊断中的现代信号处理方法[M]. 北京:科学出版社,2009.
[2]Mallat S G, Zhang Z F. Matching pursuit with time-frequency dictionaries[J]. IEEE Trans. On Signal Processing, 1993, 41(12):3397-3415.
[3]McClure M R, Carin L. Matching pursuits with a wave-based dictionary[J]. IEEE Transactions on Signal Processing, 1997, 45(12): 2912-2927.
[4]Aharon M,Elad M, Bruckstein A. K-SVD: an algorithm for designing overcomplete dictionaries for sparse representation[J]. IEEE Transactions on Signal Processing, 2006, 54 (11): 4311-4322.
[5]Neff R and Zakhor A. Matching pursuit video-partⅠ:dictionary approximation[J].IEEE Trans.on Circuits and Systems for Video Technology,2002,12(1):13-26.
[6]费晓琪,孟庆丰,何正嘉. 基于冲击时频原子的匹配追踪信号分解及机械故障特征提取技术[J]. 振动与冲击,2003,22(3):26-29.
FEI Xiao-qi, MENG Qing-feng, HE Zheng-jia. Matching pursuit signal decomposition based on impulse time-frequency atom and the extraction technologies of mechanical fault characteristics[J]. Journal of Vibration and Shock 2003, 22 (3): 26-29.
[7]Coifman R R, Wickerhauser M V. Entropy-based algorithms for best-basis selection[J]. IEEE Trans Inform. Theory, 1992, 38: 713-718.
