规则与统计结合的俄语基本名词短语识别
2014-08-29黄海红蔡东风
刘 颖,季 铎,黄海红,蔡东风
(1.沈阳航空航天大学 知识工程研究中心,沈阳 110136;2.中国商飞 上海飞机设计研究院,上海 201210)
规则与统计结合的俄语基本名词短语识别
刘 颖1,季 铎1,黄海红2,蔡东风1
(1.沈阳航空航天大学 知识工程研究中心,沈阳 110136;2.中国商飞 上海飞机设计研究院,上海 201210)
针对目前国内鲜有研究且语料资源缺乏的俄语基本名词短语(Base Noun Phrase,BaseNP)识别,提出一种规则与统计相结合的方法,其优势是在有限资源的基础上,既能充分利用俄语BaseNP在词性构成上的规律特点,通过俄汉词典统计得到最佳词性搭配模式库进行模式匹配;又无需人工标注统计工具所需的训练语料,仅依靠词典和词性搭配模式库自动构建,节省标注代价。规则与统计的结合,既能在很大程度上召回BaseNP,又能使用条件随机场(Conditional Random Fields,CRF)纠正规则标注的歧义和错误,处理规则未能覆盖的情况。实验表明,使用该方法实现的俄语基本名词短语识别效果良好,其F值达到了84.14%。
俄语;基本名词短语;词性搭配模式;CRF
基本名词短语的识别是自然语言处理领域的一项基本任务,可以被广泛应用于机器翻译、信息检索、问答系统等其他领域,其识别效果的好坏也直接影响着文本处理、句法分析等任务的准确性。
目前,基本名词短语的识别工作已有很多的相关研究,总结已有的识别方法,大致可分为两种,即基于规则的方法和基于统计的方法。然而,识别研究的对象大多针对英语和汉语,鲜有俄语的研究成果。
从语言学的角度来说,英语基本名词短语的词性构成是相对有限的,而且符合一定的排列顺序,通过在一定规模的语料上进行统计和总结,得到常见的基本名词短语词性构成模板,就可以实现大多数BaseNP的识别[1],即基于规则的识别方法。与此同时,英语和汉语又拥有较为充足的语料库资源。比如英语有华尔街日报等语料库可供使用,汉语也有哈工大汉语树库等资源。这些语料库资源使得统计工具在这两种语言的基本名词短语识别上可以发挥其作用,因此基于统计的英语和汉语的BaseNP识别取得了很好的效果。
相比之下,俄语作为典型的屈折语,既没有语序的限制,又有极其丰富的形态变化,具体表现为其各类词性下的多种语法范畴,比如名词有性、数、格的范畴,动词有体、时、态的范畴等。这些丰富的变化形式是俄语所特有的,并且难以用简单的规则加以总结和概括,因此使得单纯基于规则的方法不能得到很好的应用。傅兴尚等人虽提出过基于规则的方法对俄语的名词性构句块进行模式化分析[2],并展示了具体的程序和算法,但并没有对识别结果进行具体阐述。
除此之外,俄语不仅缺乏语料库资源,其学习者数量也较英语、汉语少得多,使得语料的人工标注代价更大。这一现状限制了统计工具在俄语基本名词短语识别中的应用。
基于俄语语言形态变化异常丰富的自身特点以及其缺乏标注语料又少有研究的现状,本文提出规则与统计相结合的方法实现俄语基本名词短语的识别。二者的结合既能使规则方法的识别歧义被统计方法修正,又不需要人工进行训练语料的标注。
本文的第一章对俄语基本名词短语识别的研究现状进行了大致地介绍,第二章阐述规则和统计相结合的俄语BaseNP识别方法,包括BaseNP词性搭配模式库的获取,基于规则的候选项标注,以及CRF训练语料的自动构建过程等具体内容,第三章描述了实验数据和实验结果。
1 国内外研究现状
英语和汉语的基本名词短语识别已有大量研究并取得了很好的效果。如郭永辉,杨红卫等把英语BaseNP的标注看作是决策问题,用粗糙集的理论加以解决[3],谭魏璇,孔芳等采用基于转换的标注和以条件随机域模型为低层、支持向量机为高层的混合统计模型实现了中文BaseNP的识别[4],梁颖红,赵铁军等采用规则和边界统计相结合的策略实现了英语基本名词短语的识别[5]等。
而俄语的相关研究工作,不论是基本名词短语识别,还是自然语言处理领域的其他基本任务,都还未取得太多的进展[6]。比如命名实体识别的研究工作,Rinat Gareev,Maksim Tkachenko等在2013年才刚刚提出俄语命名实体识别的Baselines[6]。发布了一份可供其他学术研究者使用的人工标注语料,介绍了基于知识和基于统计的两种识别方法。
2004年傅兴尚和许汉成针对俄语句法信息的自动化处理提出了基本构句块的概念以及相应的识别算法。他们将名词构句块总结为两种类型:第一种是前置词与名词的组合结构,其中主导词是名词,前置词为从属词。第二种是由形容词、物主代词、指示代词、序数词等限定词与名词构成一致联系的结构,也包括前置词与这种结构的结合体,其中主导词为名词,前置词和限定词为从属词。最后通过基于规则的方法实现这两种名词构句块的识别。
此外,也有相关文献从语言学的角度对俄语名词短语的组构规则和应用规律进行了论述,为俄语名词短语的识别工作提供了理论支撑。
其中较为系统和详细的是,2006年黑龙江大学的李谨香在其博士学位论文中对俄语名词性短语的结构和功能与汉语进行了对比研究的阐述[7]。论文总结俄语名词性短语从结构类别上可以分为定心短语、并列短语和同位短语。其中定心短语的组合形式有:数量词与名词,代词与数词,名词与名词,形容词与名词,动词与名词,介词短语与名词。每种组合形式都有其相应的语法限制。例如:数量词+名词的BaseNP模式须在数范畴上满足对称性,例如одна ручка(一支钢笔),形容词+名词的BaseNP,例如центрирующую шестерни(定心齿轮),其中形容词必须是长尾形式,并且要与名词保持性、数、格的一致性等。这些搭配规律和一致性特点,是进行俄语BaseNP识别时的重要特征。
2 规则与统计相结合的俄语BaseNP识别
本文的俄语BaseNP识别分为两个部分:第一部分是基于规则的BaseNP候选项标注,第二部分是基于CRF的BaseNP标注。规则标注首先利用对俄汉词典的汉语端进行BaseNP
识别获得相应的俄语BaseNP语料集,然后经过词性标注并使用一种宽泛的召回率计算方法选择出最佳词性搭配模式库,再基于该模式库采用最长匹配原则进行词性搭配模式的匹配,标注出BaseNP的候选项;基于CRF的标注无需人工标注,仅依靠词典和词性搭配模式库自动构建训练语料,选择合适的特征模板,进行BaseNP的标注,以纠正候选项标注结果中的错误,提高识别的准确率。系统的示意图如图1所示。
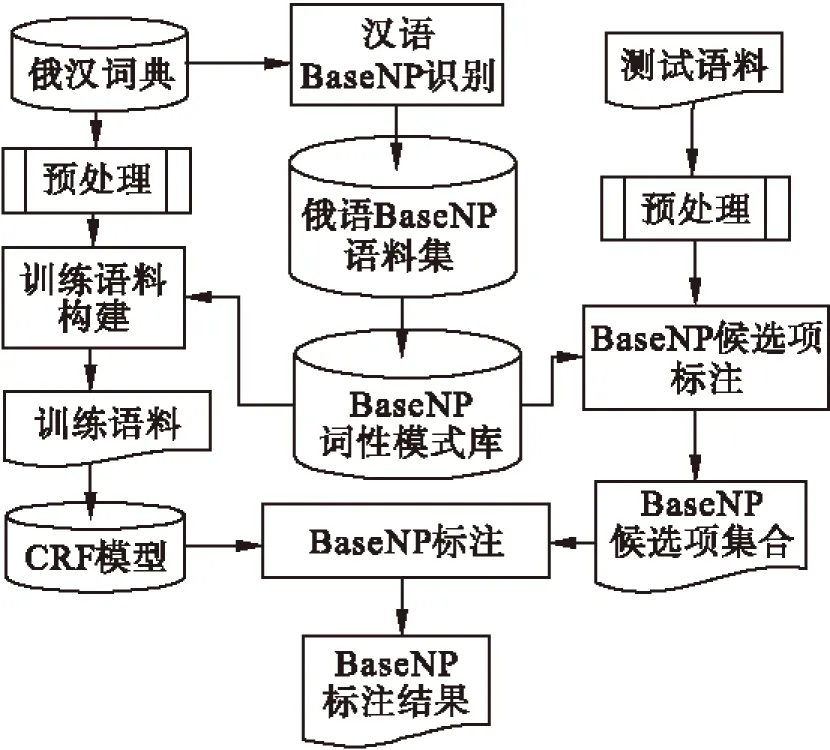
图1 系统示意图
2.1 预处理
预处理是使用一个俄语的词性标注工具2将语料按表1所示的俄语词性命名规范进行词性的标注。并处理为统一格式,如图2所示。

表1 俄语词性命名规范
BaseNP候选项和BaseNP的标注都是在这种格式的语料上进行,标注标记分别为B(BaseNP的左边界词),I(BaseNP的内部词),E(BaseNP的右边界词),O(不属于BaseNP的词)。

图2语料格式
2.2 基于规则的BaseNP候选项标注
BaseNP的候选项标注是在词性搭配模式库的指导下,标注出所有匹配词串的过程。具体操作是:首先,对俄汉词典的汉语翻译进行BaseNP的识别,据此将对应的俄语词条选入俄语BaseNP语料集,对该语料集进行词性标注,统计词性搭配以获得模式库。然后,基于该词性搭配模式库,采用最长匹配原则对俄语句子进行候选项的标注。标注的目标是获得尽可能多的BaseNP候选项,以保证识别的召回率。
2.2.1 词性搭配模式库的获取
词性搭配模式库的获取,有一个选择和过滤的过程,也就是说,并不是所有从俄语语料集中统计得到的词性搭配模式都用于BaseNP候选项的标注。
基于词性搭配模式库采用最长匹配原则标注出的BaseNP候选项,会有很大一部分并不与正确答案完全相同,而是在其内部包含正确答案,如图3所示:

图3BaseNP候选项标注结果
图3中的词性组合“J J N”和“J N”都在词性搭配模式库中存在,但由于最长匹配的原则,所以将“J J N”对应的短语标注为BaseNP候选项,而不能标出“J N”对应的短语,此时,标注出的BaseNP候选项就不是正确答案,而是包含正确答案。这种情况应该被认为是正确识别,因为词性搭配模式匹配的目的就是使标注出的BaseNP候选项集合尽可能多地包含正确答案。
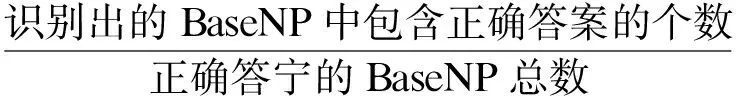
以R′作为指标进行词性搭配模式库获取的方法是:对于所有从俄语语料集中统计得到的词性搭配模式,按频率由高至低依次加入模式库中,若加入某条词性搭配模式后,当前模式库对BaseNP候选项的标注召回率较前一次增大,则在模式库中保留该条词性模式并继续添加下一条,否则,在模式库中把该条词性搭配模式删除,再增加下一条。伪代码如算法1所示:

算法1词性搭配模式的获取定义 r_dic:从词典中统计得到的所有词性搭配模式的集合,包含N个元素r_set:词性搭配模式库ri:第i条词性搭配模式R':召回率fori∈[1,N]doaddritor_set基于r_set进行BaseNP候选项的标注ifRi'>Ri-1' nextelse 在r_set中删除ri nextendifendfor r_setretum
由此得到使召回率R′最大的最佳BaseNP词性搭配模式库,共包含词性搭配模式83条,其中一部分如表2所示:

表2 BaseNP词性搭配模式(Pattern)统计(部分)
由表可知,存在很多嵌套的词性搭配模式,这样在最长匹配原则下会产生很多包含子BaseNP的候选项,而这种嵌套的拆分,正是进行下一步基于CRF标注的目的。
2.3 基于CRF的BaseNP标注
对于基于规则标注得到的BaseNP候选项集合,再使用CRF在基于词典和词性搭配模式库自动构建的语料上进行训练,得到标注模型并进行BaseNP的标注,从而切分由于最长匹配原则导致的包含子BaseNP的标记、剔除错误的标记,达到准确率的提高。如图4:

图4标注结果对比
由图可知,CRF标注的作用是在基于规则标注出的候选项中识别出正确答案,剔除错误标记。
2.3.1 条件随机场
条件随机场是John Lafferty等人于2001年提出的一种在给定输入节点条件下计算输出节点条件概率的无向图模型[8],用于序列标注和分类。
定义x=x1,…,xN为给定的输入观测值序列,比如文本输入的俄语词序列,定义y=y1,…,yN为输出的状态序列,比如输出的BaseNP标记序列,CRF定义从输入x得到序列y的条件概率为:
其中,Z(x)是归一化函数,Fj(y,x)是特征函数,λj是第j个特征函数的权重参数,可在训练中得到。BaseNP的识别目标就是要找到最优序列p*,使得:
2.3.2 训练语料的构建
基于CRF的标注,是在每个BaseNP候选项内部的标注,目的是将包含多个BaseNP的候选项拆开,将错误识别的候选项剔除,所以训练语料的构建,是针对每条词性搭配模式而进行的短语语料构建,而不是句子语料的构建。
具体做法是:对于某个词性搭配模式库中的BaseNP词性搭配模式,若在该模式内部还包含子模式,则当前模式就可以有其他不同的标注方式,对于每种标注方式,分别在词典中找到相应词性组合的词条作为实例添加至要构建的训练语料中。每种标注方式都各扩展10个实例添加至构建的训练语料中,每次所选的词条不可重复。
例如:词性搭配模式J N J,
该模式内部还包含模式库中存在的模式“N”、“N J”,所以其可能的标注方式有:B I E,O B E等,对每种标注方式,都各自在词典中找到相应词性的词,加以词性标注和BIEO标记的标注,然后添加到构建的训练语料中,每种标注方式以此方式进行10次,每次选择的词都不可重复。示意图如图5所示。
2.3.3 特征模板的选择
特征模板的选择要考虑到每个词所携带的词性信息以及其上下文环境两个因素,这里所说的词性信息,包括词类和性、数、格属性。本文所选特征模板及其代表的含义如表3所示。
3 实验数据及结果分析
3.1 实验准备
实验所用的词典抽取自俄汉基本大词典、科技大词典、物理大词典等多部词典,共有词条520223条,词条既有单词也有词组,最长的词条长度为22个单词。
测试语料是由俄语专业学生标注的800句专利文本。

图5 训练语料构建过程示意图

表3 特征模板
3.2 评价指标
采用自然语言处理领域三个通用的评价指标,准确率(P),召回率(R)和F值,具体定义为:
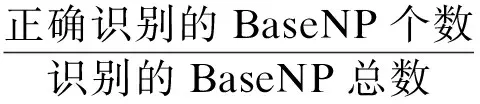
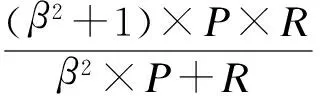
3.3 实验结果
在测试语料上进行词性模式匹配(Pattern_match)的标注结果与在其基础上进行CRF模型(Pattern_match+model)的标注结果如表4所示。
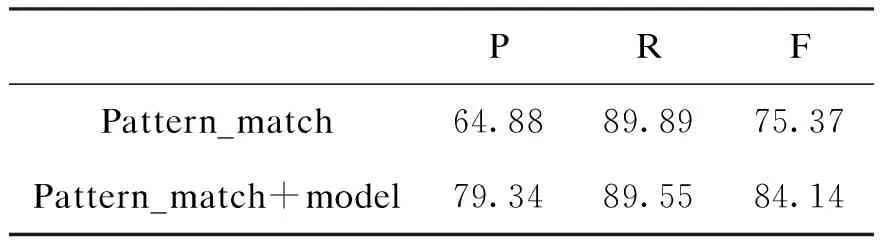
表4 实验结果 (%)
结果表明,基于词性模式匹配的标注结果召回率接近90%,实现了BaseNP的大部分召回,而在此基础上进行的CRF模型标注,使得实验结果在召回率没有明显下降的前提下,准确率提高了15.5%,整体提升了F值。体现出规则与统计方法相结合对于识别效果的有效性。
4 总结
俄语基本名词短语的识别同英语、汉语等语言一样具有重要意义,其研究成果对于俄汉机器翻译的发展具有直接的指导意义和应用价值。
本文在兼顾俄语自身语言特点的基础上,不需要人工标注训练语料,结合统计工具的使用,实现了俄语基本名词短语的识别,并取得了良好的效果。
在今后的研究中,还将进一步针对CRF工具标注时的特征选择进行实验,达到更好的消歧能力和BaseNP的标注准确率。
[1] 游斓.基于转换的基本名词短语识别[C].复旦大学·政学者论文集,2002:236-245.
[2] 傅兴尚,许汉成.俄语句法信息的自动化处理——基本构句块及其识别算法[J].解放军外国语学院学报,2004,27(1):38-41.
[3] 郭永辉,杨红卫,马芳,等.基于粗糙集的基本名词短语识别[J].中文信息学报,2006,20(3):14-21.
[4] 谭魏璇,孔芳,倪吉,等.基于混合统计模型的中文基本名词短语识别[J].计算机应用与软件,2011,28(8):254-256.
[5] 梁颖红,赵铁军,翟舒.规则和边界统计相结合的英语基本名词短语识别[C].语言计算与基于内容的文本处理——全国第七届计算语言学联合学术会议论文集,2003.
[6] Gareev R,Tkachenko M,Solovyev V,et al.Introducing baselines for russian named entity recognition[C].Computational Linguistics and Intelligent Text Processing.Springer Berlin Heidelberg,2013:329-342.
[7] 李谨香.汉俄语名词性短语的结构与功能研究[D].哈尔滨:黑龙江大学,2006.
[8] Lafferty J,McCallum A,Pereira F C N.Conditional random fields:probabilistic models for segmenting and labeling sequence data[J].2001:139-141.
[9] 刘飞,周俏丽,张桂平.基于辅助短语标记的名词短语识别[J].沈阳航空航天大学学报,2014,31(1):52-59.
[10] Xun E,Huang C,Zhou M.A unified statistical model for the identification of English baseNP[C].Proceedings of the 38th Annual Meeting on Association for Computational Linguistics.Association for Computational Linguistics,2000:109-116.
[11] Sang E F.Noun phrase recognition by system combination[C].Proceedings of the 1st North American chapter of the Association for Computational Linguistics conference.Association for Computational Linguistics,2000:50-55.
[12]王仲华,卢娇丽.基于 HMSVM 的基本名词短语识别研究[J].太原师范学院学报:自然科学版,2012,11(4):133-135.
[13]章忠宪.基于规则的英语名词短语结构自动识别研究[J].吉林工程技术师范学院学报,2013,29(7):70-72.
[14]钱小飞,侯敏.基于混合策略的汉语最长名词短语识别[J].中文信息学报,2013,27(6):16-22.
[15]马建军.面向机器翻译的英语功能名词短语识别研究[D].大连:大连理工大学,2012.
(责任编辑:刘划 英文审校:宋晓英)
RecognitionofRussianbasenounphrasebasedonrulesandstatistics
LIU Ying1,JI Duo1,HUANG Hai-hong2,CAI Dong-feng1
(1.Knowledge Engineering Research Center,Shenyang Aerospace University,Shenyang 110136,China;2.Shanghai Aircraft Design And Research Institute,Commercial Aircraft Corporation of China,Shanghai 201210,China)
In attempt to build Russian corpus,a method for the recognition of Russian base noun phrase based on statistics and rules is proposed.It can not only take advantage of characteristics of Russian BaseNP in the part of speech,by selecting in the best pattern corpus of speech collocation from the Russian-Chinese dictionary to do pattern matching,but also build corpus automatically instead of manually,which is for statistical tools to use,according to the dictionary and the pattern corpus of speech collocation only.The combination of rules and statistics can tag base noun phrase candidates as much as possible,and rectify those ambiguous tagged candidates or errors by CRF,dealing with the rule-uncovered phenomena.The results show that the method is efficient for identifying Russian base noun phrase,of which the F-score reaches 84.14%.
Russian;base noun phrase;speech pattern;CRF
2014-09-02
国家“十二五”科技支撑计划项目(项目编号:2012BAH14F00)
刘颖(1990-),女,内蒙古赤峰人,硕士研究生,主要研究方向:自然语言处理,E-mail:liuying_ck081@163.com;蔡东风(1958-),男,河北霸县人,教授,主要研究方向:人工智能、自然语言处理,E-mail:caidf@vip.163.com。
2095-1248(2014)06-0066-07
TP391
A
10.3969/j.issn.2095-1248.2014.06.012
