基于改进K-means的网络舆情热点事件发现技术
2014-08-23孙玲芳周加波候志鲁
孙玲芳,周加波,徐 会,许 锋,候志鲁
(江苏科技大学经济管理学院,江苏 镇江 212003)
0 引言
目前互联网已经成为我国民众发表言论和获取信息的主要渠道,然而网络是一把双刃剑[1],一方面网络使得信息的传播更加自由与便利,能够及时反映社情民意,对社会的发展起了积极作用;另一方面由于网络具有虚拟性、发散性、渗透性以及匿名性等特点,再加上我国目前处于社会转型期,社会矛盾多且复杂,网络中充斥着许多淫秽、暴力、反动、迷信等不良信息,对国家安全和社会稳定构成一定的威胁。有些网民或者团队为了追求利益,利用互联网散布各种虚假或者扭曲事实的言论,引诱公众产生具有强烈负面倾向的情绪、态度和意见,影响人们的正常生活,干扰企业的运作和政府的决策[2]。因此为了充分利用网络舆情对社会发展的积极作用,尽量降低网络舆情的消极影响,有必要对网络舆情的产生、传播、预警以及应对方法进行深人研究。
学术界对网络舆情的概念还没有达成一致意见,刘毅认为“网络舆情是通过互联网表达和传播的各种不同情绪、态度和意见交错的总和”[3]。华中科技大学的曾润喜博士认为“网络舆情是由于各种事件的刺激而产生的通过互联网传播的人们对于该事件的所有认知、态度、情感和行为倾向的集合”[4]。军犬舆情创始人彭作文先生认为网络舆情是以网络为载体,以事件为核心,广大网民情感、态度、意见、观点的表达、传播与互动,以及后续影响力的集合。浙江工商大学的柳虹认为网络舆情热点指网民思想情绪和群众利益诉求在网上的集中反映,是网民热切关注的聚焦点,是民众议论的集中点,反映出一个时期网民的所思所想[5]。由此可见,网络舆情的主体是广大网民,客体是社会事件,手段是互联网,目的是表达网民的认知、意见和情感。
国外舆情热点发现研究较为有名的如美国的话题发现与跟踪(TDT)研究项目,这项技术旨在帮助人们应对日益严重的互联网信息爆炸问题,对新闻媒体信息流进行新话题的自动识别和已知话题的持续跟踪[6]。目前我国网络舆情的主要研究方向之一是网络舆情规律及热点发现技术[7],郑魁等根据公共安全网络舆情研究的需求,提出基于ICTCLAS分词技术网络舆情热点信息的自动发现方法[8],王伟等根据对网络舆情分析的需求,构建了基于聚类的网络舆情热点问题发现及分析系统[9]。中文信息处理与数据挖掘是网络舆情热点发现在实践上的主要研究领域,因此本文紧扣这2个研究领域设计一个基于改进的K-means网络舆情热点事件的聚类研究模型,并且将该模型用于实证研究,得到了比较满意的结果,证实了改进算法的可行性和优越性。
1 K-means算法
文本聚类方法是网络舆情热点发现关键技术之一,文本聚类分析指使得同一类文本之间的相似度比其他类文本的相似性更强,按照聚类分析算法的思路不同,可将聚类算法分为划分法、层次法、基于密度的算法、基于网格的算法和基于模型的算法。K-means也被称为K-均值,是一种得到最广泛使用的聚类算法。K-means算法以K为参数,把n个对象分为K个簇,以使簇内具有较高的相似度。相似度的计算根据一个簇中对象的平均值来进行。K-means算法[10]的流程如下:
输入:包含n个数据对象的数据集及聚类个数K;
输出:满足目标函数最小值的K个聚类。
(1)从n个数据对象中任意选K个对象作为初始聚类中心。
(2)根据每个聚类对象的均值,计算每个对象与这些中心对象的距离,并根据最小距离重新对相应对象进行划分。
(3)重新计算每个聚类的均值(中心对象)。
(4)循环上述流程(2)和(3),直到目标函数的值不再变化。
K-means算法具有应用最为广泛、收敛速度快、能扩展以用于大规模的数据集等优点。同时也存在结果好坏依赖于对初始聚类中心的选择、容易陷入局部最优解、对K值的选择没有准则可依循、对异常数据较为敏感、只能处理数值属性的数据、聚类结构可能不平衡等缺点。
2 网络舆情热点事件发现模型
本模型包括舆情信息采集、舆情信息预处理和舆情热点发现3个部分,其基本流程如图1所示。
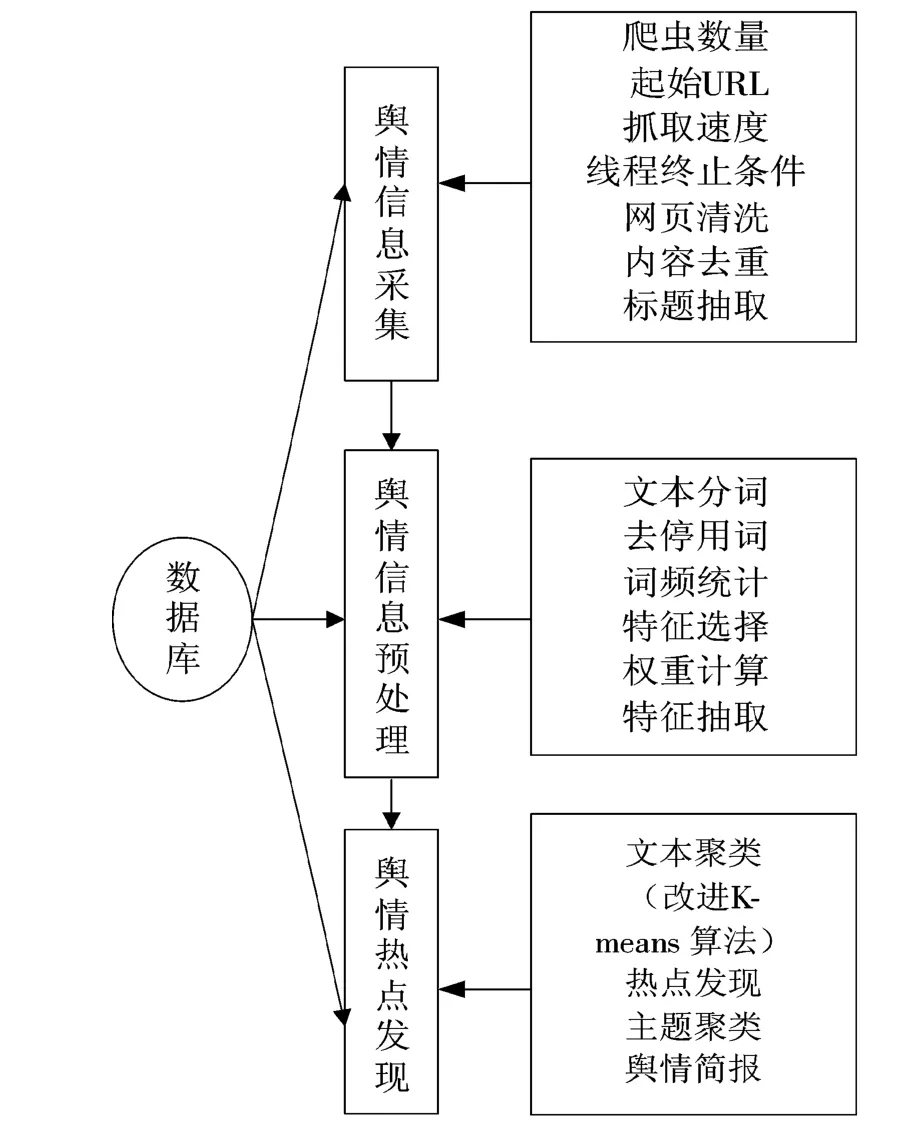
图1 网络舆情热点事件发现模型结构
2.1 舆情信息采集
网络爬虫技术是采集网络舆情信息的常用手段,网络爬虫是一个自动提取网页的程序,爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。本文采用KWebWatcher爬虫软件采集舆情信息,具体设置如下:检测主题为社会新闻类,指定 http://news.163.com为采集网站,检测结果显示新闻标题、新闻作者、新闻来源、发表时间、采集时间等信息,而爬行策略、线程分配和爬行深度则采用软件默认值,通过软件的智能过滤模块将采集到的网页中的导航信息、版权信息和广告信息等无用信息过滤掉,最后将处理过的结果导入本地数据库。
2.2 中文分词
采集到的舆情信息是非结构化的数据,计算机很难理解其语意,必须将非结构化的数据转化为结构化的数据。中文分词是中文信息处理的最基本的部分,本文采用SCWS中文分词系统,这是一套基于词频词典的机械式中文分词引擎,它能将一整段的中文文本基本正确地切分成词,经小范围测试大概准确率在90% ~95%,已能基本满足一些小型搜索引擎、关键字提取等场合运用,45kb左右的文本切词时间是0.026 秒,大概是 1.5MB 文本/秒[11]。
2.3 特征选择
经过中文分词后的文本向量空间的维数相当高,高维文本既影响计算机的运算速度又会引入过多的噪声,因此有必要降低向量的维数。本文首先运行SCWS中文分词系统的自带停用词表对文本进行初步处理,去除文本中的停用词。其次,由于能够代表某件新闻事件的关键词主要是名词和动词,而副词、连词、介词和叹词等的作用不大,所以在选取特征词时只选择名词和动词,这一步可以通过分词系统的词性标注来实现。最后,采用具有简单与高效特性的文档频率法来选择特征词,去除文档频率高于90%和低于20%的特征词。
2.4 文本表示——向量空间模型(VSM)
布尔模型、概率模型和向量空间模型是目前最常用的文本表示方法,本文选用向量空间模型表示文本。向量空间模型(Vector Space Model,VSM)由Gerard Salton等人在20世纪60年代提出,并成功应用于SMART系统中[12],具体形式如下:

每个文本可以表示成 D={T1,T2,T3,…,Tm},T为特征集,m是特征词的总个数,根据各个项Tk在文本中的重要性给其赋予一定的权重Wk,这时文本D={T1W1,T2W2,T3W3,…,TmWm},文本 D 也可以简记为 D={W1,W2,W3,…,Wm},如果把 T1,T2,T3,…,Tm看作为一个 m 维的坐标系,则{W1,W2,W3,…,Wm}可以被看作是m维空间中的一个向量,即每个文本对应一个m维的空间向量。
本文采用词频逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)法确定权重 Wk,计算公式如下:
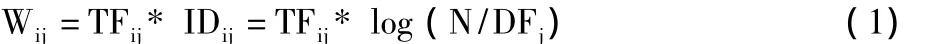
其中,TFij指特征词Tj的词频,即该特征词在文本Di中出现的次数,DFj指特征词Tj的文档频率,即文本集中含有该特征词的文本数目,N指文本集中文本的数目。公式(1)表明,文本集中包含某个特征词的文本越多,则该特征词区分文本类别的能力越低,其权值越小;同时,某个文本中某个特征词出现得越多,说明该特征词区分文本类别的能力越大。文本向量空间模型如图2所示。
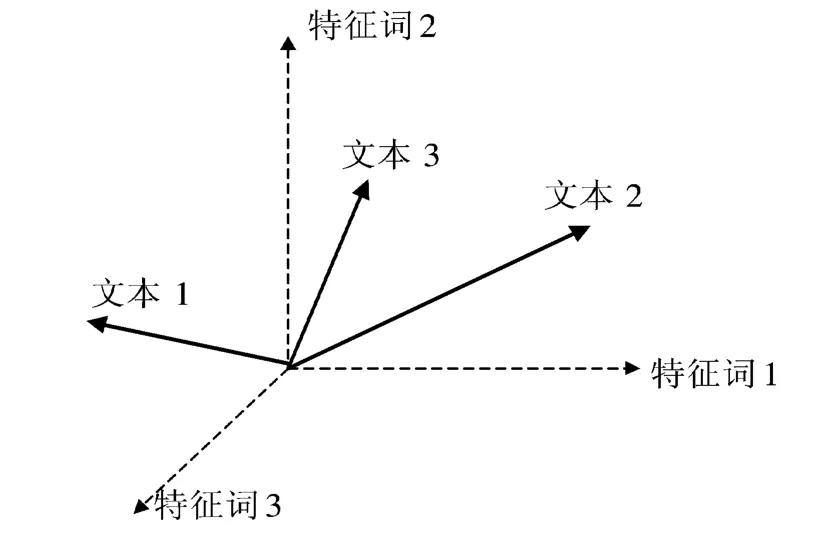
图2 文本向量空间模型
2.5 改进的K-means算法
通过舆情信息采集子系统和舆情信息预处理子系统的运行,从指定网站抓取的非结构化Web文本转化为计算机能够处理的结构化向量,下面将对中文文本进行聚类分析。传统的K-means算法对初值敏感且要求用户事先确定要生成的簇的数目K,还对于“噪声”和孤立点数据敏感,少量的该类数据能够对平均值产生极大影响,每一次迭代都要重新计算簇中对象的均值,这就会增加算法的时间复杂度和空间复杂度。本文对传统的K-means算法进行了改进,目的是减少算法对孤立点的敏感性和降低算法的时间和空间复杂度。改进的K-means算法流程如下:
输入:簇的数目K;包含n个对象的数据集;
输出:K个簇的集合。
(1)计算n个对象的距离矩阵,将其平均距离记为R。
(2)从n个数据对象中任意选择K个对象作为初始簇中心。
(3)将剩余的每个对象根据其与各个簇中心的距离,将它赋给最近的簇。
(4)计算接受了新对象的簇的中心(均值)Oi(i=1,2,3,…,k)。
(5)分别计算每个对象与其簇中心的距离。
(6)重复迭代,即将与簇中心的距离小于t×R(t=1,2,3,…,n初始半径R以t倍的速度扩大)的对象赋给最近的簇。
(7)如果各对象都被最近的簇吸收了,或者2×t×R与OiOj(OiOj表示2个不同中心的距离)相等时算法停止,即可得到最终的K个簇的集合,否则转到第(5)步。
本算法中的距离采用欧氏距离,如式(2)所示:
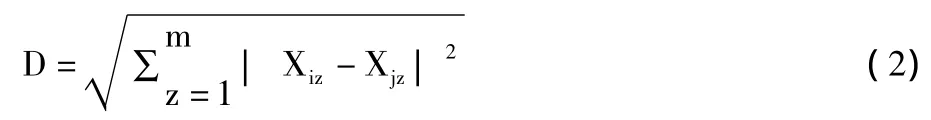
为了便于理解改进的K-means算法,绘制了该算法的二维示意图(见图3)。取 K 等于3,O1、O2、O3为簇中心,所有对象之间的平均距离为初始半径R,以t×R的速度扩张,直到与另一个圆相切,此时位于同一个圆内的对象为一个簇。
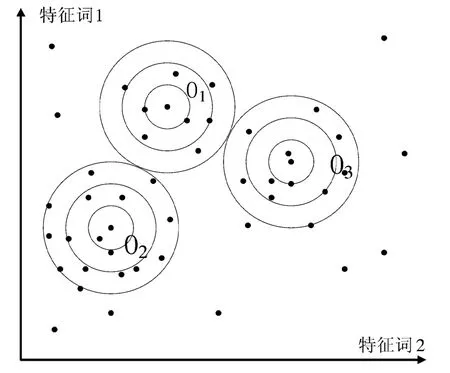
图3 算法二维示意图
3 实验及结果分析
3.1 实验环境及语料
实验是在 PC机 Windows XP系统,2.94 GHz CPU,2 GB内存环境下测试。采用KWebWatcher爬虫软件和SCWS中文分词系统,算法采用Matlab语言编写。中国互联网络信息中心第30次调查数据显示,截至2012年6月底,网络新闻的用户规模达到3.92亿,网民对网络新闻的使用占 73.0%[13],因此本文采用网络新闻作为系统实验的对象,共采集了网易新闻网站从2013年11月1日到2013年11月30日期间的150篇新闻文本作为实验语料库。
3.2 评估标准
聚类系统的准确性和有效性一般用正确率(Precision,P)与召回率(Recall,R)来测量,正确率是聚类出相关文档数与聚类出的文档总数的比率,衡量的是聚类系统的查准率;召回率是指聚类出的相关文档数和文档库中所有的相关文档数的比率,衡量的是聚类系统的查全率。正确率和召回率定义如下:

为避免正确率和召回率之间相互冲突,设定新的测试值F1,F1的值越大则系统的聚类效果越好。

3.3 实验步骤
具体实验步骤如下:
(1)舆情信息采集,下载网易新闻网站150篇新闻文本,提取网页的文本内容,按新闻标题、新闻作者、新闻来源、发表时间、采集时间5个部分的格式存储文档,以采集时间作为文档名。
(2)舆情信息预处理,将所有采集的文本,运用SCWS中文分词系统进行分词,去除停用词、副词、连词、介词和叹词,按照文档频率对特征词进行排序,选择符合阈值的特征词,利用TF-IDF公式确定每个特征词的权值,最后建立文本的向量空间模型。
(3)将所有已经向量空间化的文本,利用改进的K-means算法和传统的K-means算法进行聚类,以F1值来衡量算法的性能。
3.4 实验结果分析
将语料库中的150篇新闻文本,采用人工的方式进行统计和分类,比较改进后的K-means算法和传统的K-means算法的性能,2种算法的性能比较结果如表1所示。从表1中可以发现,在正确率、召回率和F1值方面,改进的K-means算法均优于传统的K-means算法,这说明改进的算法在一定程度上提高了热点话题发现的准确性和效率。
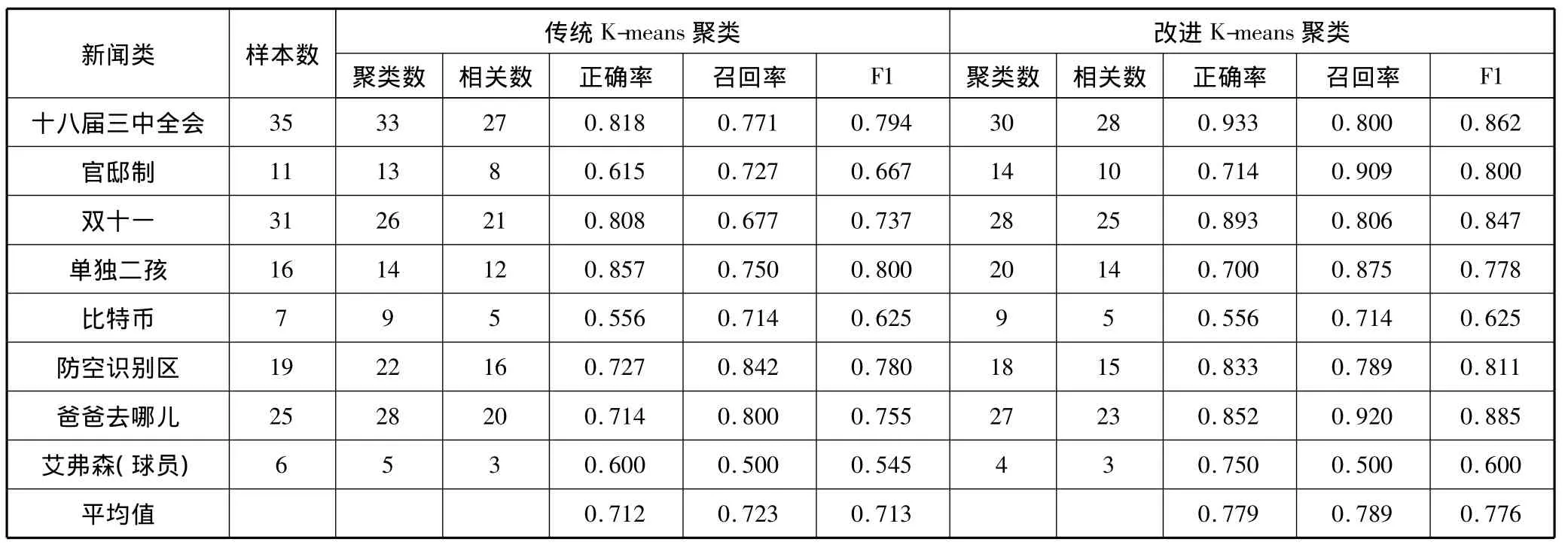
表1 两种算法性能比较结果
4 结束语
本文开发了一套由舆情信息采集、中文分词、特征选择、向量空间模型及改进的K-means算法等技术模块组成的网络舆情热点事件发现系统,并以实际案例证明了系统的实用性。在系统实现的过程中对传统的K-means算法进行了改进,降低了孤立点对算法性能的不利影响,同时降低了算法的时间和空间复杂度,为该算法运用于大规模数据聚类提供了基础。但是本系统也存在需要继续完善的地方,例如本系统不能实现网络热点新闻的动态发现,不能够对已经发现的热点新闻进行追踪,没有找到一种较好的方法确定K-means算法中的K值等,今后需要在现有的研究成果的基础上对系统的不足之处作深入研究。
:
[1]Zheng Fen,Xu Yabin,Li Yanping.Research on Internet hot topic detection based on MapReduce architecture[C]//2012 4th International Conference on Intelligent Human-Machine Systems and Cybernetics.2013:81-84.
[2]刘勘,朱怀萍,胡航.网络伪舆情的特征研究[J].情报杂志,2011,30(11):57-61.
[3]刘毅.网络舆情研究概论[M].天津:天津人民出版社,2007:51-53.
[4]曾润喜.网络舆情信息资源共享研究[J].情报杂志,2009,28(8):187-191.
[5]柳虹.网络热点发现研究[J].科技通报,2011,27(3):421-425.
[6]Allan J.Topic Detection and Tracking:Event-based Information Organization[M].Kluwer Academic Publishers,2002:1-16.
[7]岳香芬.网络舆情文献聚类分析[J].科技创业月刊,2012(6):149-151.
[8]郑魁,疏学明,袁宏永.网络舆情热点信息自动发现方法[J].计算机工程,2010,36(3):4-6.
[9]王伟,许鑫.基于聚类的网络舆情热点问题发现及分析[J].情报分析与研究,2009,36(3):74-79.
[10]袁方,周志勇,宋鑫.初始聚类中心优化的k-means算法[J].计算机工程,2007,33(3):65-66.
[11]Xunsearch.SCWS中文简介[EB/OL].http://www.xunsearch.com/scws/,2013-01-15.
[12]Gerald Salton,Wong A,Yang C S.A vector space model for automatic indexing[J].Comn.ACM,1975,18(11):613-620.
[13]中国互联网络信息中心.第三十次中国互联网发展状况统计报告[EB/OL].http://www.cnnic.net.cn/,2012-06-01.
