基于三维上下文的图像几何分割方法
2014-08-23陶铭洋
陈 肖,王 敏,陶铭洋
(河海大学计算机与信息学院,江苏 南京 211100)
0 引言
人类的视觉是一个全局识别的综合系统。人类在识别路上行人的时候,不只是通过行人的轮廓,还有许多其他的信息,比如行人所站立的地面、马路的三维结构、观察者的方向等。这给计算机视觉研究人员极大的启发。
当前,大多数目标识别算法都是单纯地采用局部信息,例如,现有的物体识别算法[1-2]大都假设图像中一个物体的所有相关信息都存在于图像平面的一个小窗口中。这类方法典型的弊端就是经常在目标不可能出现的地方检测到目标,例如:在桌子上检测到汽车,在树干上检测到人脸等。如果计算机视觉的最终目标是像人类一样观察这个世界,就必须从图像整体出发,考虑物体之间的关系,即上下文信息。
近年来,出现了一些相关的有影响力的论文。Torralba等人[3-4]论述了全局上下文信息在目标检测中的重要性。Bose[5]等人用图像的底层特征来粗略地描述场景。其他一些研究整合了局部上下文信息,利用随机场的方法也得到了不错的结果[6-7]。然而这些方法存在一个共性的问题:它们建立的关系都是二维图像上的关系,而不是三维世界中的真实关系。事实证明这种局限性会忽略一些重要的信息,例如尺度关系、表面方向等。而三维上下文信息能更好地说明物体之间的关系。
本文的创新点是将三维上下文信息成功地引入场景图像的几何标记,并使用可靠性高的逐步构建场景结构的方法,更好地完成了图像的几何分割工作。
1 超像素
数字图像可以简单表示为RGB像素点矩阵。在不考虑像素间关系的情况下,只能得到一些简单的信息,包括像素颜色等。本方法的第一步就是利用图像的过分割来获取超像素,超像素是具有相似外观的相邻像素的集合,超像素与普通像素不同,它不仅能提供颜色信息,同时还有纹理、形状等其他底层信息。这样在提取特征的时候,更多的特征信息可以帮助后续的机器学习算法得到更好的结果。本文采用Felzenszwalb[8]提供的基于图的图像分割方法产生超像素,该方法将每个像素看作是图模型的一个节点,分析节点之间的颜色差异决定是否进行合并,从而达到图像分割获取超像素的目的。该方法速度快,得到的图像区域几何标签一致性较好。
2 特征提取
在特征提取部分,本方法提取了一系列特征,包括:颜色、纹理、位置以及三维上下文特征。
2.1 颜色特征
颜色本身对三维方向的贡献并不是很大,然而通过建立颜色模型,可以粗略地判断被检测的对象是特定几何类别的物体或者材料。这使得颜色特征成为了一个非常重要的信息。例如天空经常是蓝色或者白色的,地面经常是绿色的草地或者是棕色的土地等。分割区域的颜色特征本文采用RGB和HSV两个色彩空间,计算出分割区域中每个像素各个分量的均值,作为其颜色特征。
2.2 纹理特征
和颜色特征类似,纹理特征也建立了物体和材料与几何类别之间的关系。这是因为竖直类的物体更容易产生纵向纹理,而水平类的物体更容易产生横向纹理。本文采用了 Leung and Malik设计的 Filter Bank[9]来表示纹理特征。
2.3 三维上下文特征
平面的消失线完全确定了该平面相对于观察者的三维方向,但是这些信息很难检测,尤其是在室外场景中。本文采用文献[10]所介绍的方法进行直线边缘的检测以及消失点的估计。
在人工场景图像中,可以从图像中提取出大量的直线边缘,通过统计这些直线边缘以及它们的交点,可以获取平面消失点或消失线的位置。这里可以得出一系列可能的消失点以及每条线属于每个消失点的概率。如果得到的消失点的数目小于3,就不考虑缺少的那个消失点。根据消失点的位置,可以得到一些结论:出现位置非常高或者非常低的消失点,往往就是竖直类的消失点;同理,高度位于图像中间位置的消失点往往就是水平类的消失点。
确定了消失点(消失线)的位置之后,可以根据分割区域与消失点之间的位置关系进行大量的数据统计,包括:(1)分割区域在消失线之上、之下或者跨越消失线;(2)分割区域的重心到消失线之间的距离;(3)分割区域中贡献某消失点的线段像素数量。这些均属于三维上下文信息。
3 图像的多尺度分割
要估计出一个超像素区域的几何方向(几何标签),需要寻找大量的图像区域来计算上述复杂的特征。一种可行的方法就是利用多尺度图像分割算法,将一幅图像按不同的尺度进行分割,可以得到大量的图像区域。
为了提高分割的质量,本文在基本特征的基础上加入了每个分割区域的空间位置信息。理想状态下,要估计所有可能的分割来选取最优分割区域,这显然难以操作。Hoiem等人[11]采取了一种简单的方法,将超像素组合成为更大的连续的分割区域,而组合的依据就是2个相邻超像素或分割区域之间的似然值,当然这些似然值都是从训练图像中学习得来的。本文也采取了这种方法,其算法流程见图1。

图1 多尺度分割算法流程

图2 图像的多尺度分割,(1)(2)(3)(4)的分割区域数分别是 5,10,50,100
场景图像的多尺度分割效果如图2所示,该方法根据预设分割区域的数量,得到了相应的分割结果。
4 几何标记
要达到几何标记的目的,需要估计每个分割区域属于每个标签的似然值,这里的标签为几何标签,即天空、竖直、水平3种。
4.1 分类器
本文利用boosted决策树进行分类。决策树可以很好地组合弱分类器,它们提供了一个自动的特征选择,每个决策树提供一个数据的分割面并输出一个带有置信权值的结果。本文训练2种分类器:同标签分类器和同质分类器,所谓的同质是指一个分割区域中所有的超像素都属于同一个标签。分类器训练算法如图3所示。

图3 boosted决策树训练流程
对于同标签分类器,每个分割区域的初始权值是相同的。对于同质分类器,初始的权值是分割区域面积与整个图像的面积的比值。分割区域之间的面积差异比较大时,较大分割区域的重要性要远高于较小区域。因此,这种权值的初始化方式也更符合实际。
同标签分类器输出估计值P(yi=yj|I),其中i,j是相邻的2个超像素,I是图像数据。同质分类器输出的是第k个分割区域的P(sk|I)。
4.2 训练和推理
对于训练样本中的每幅图像,均采取以下步骤:先将图像分割成超像素,提取每个超像素的特征,接着对每一幅图像进行多尺度分割,并对分割出来的区域进行手工标记,再计算每个分割的特征向量。根据前面的方法训练标签分类器和同质分类器。
在推理阶段,同样要将图像分割为超像素,并利用训练好的同标签分类器对图像进行多尺度分割,然后重新计算每个分割的特征向量,再对每个可能的标签计算其标签似然值P(yj|I,sj),计算同质似然值P(sj|I),最终求出每个超像素的标签置信度:
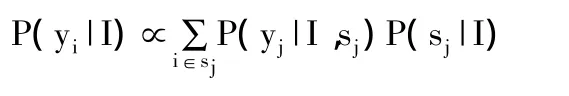
5 实验及结果
本实验采用来自Stephen Gould[12]的数据集。该数据集共有715幅图像。统计整个数据集,3个几何标签类别水平、竖直、天空所占的比例分别为31.4%、48.0%、20.6%。随机选取其中的300幅,以50幅为一组分为6组,将第一组用于训练同标签分类器,以估计相邻2个超像素属于相同标签的概率。剩余的5组进行交叉验证。
首先利用上面的同标签分类器对每幅图像进行多尺度分割。对于每个组进行测试时,都用其余4组进行几何分类器和同质分类器的训练。最终对后5组的所有图像进行几何分割。得到的分割结果如图4所示。

图4 分割结果
通过对几何分割的最终结果与其数据集中的原始标签进行对比,得出了实验的混淆矩阵。再重复上述过程,此次加入三维上下文信息得到新的混淆矩阵,通过对比2个混淆矩阵(见表1、表2),加入三维上下文信息后,本文方法几何分割的准确率更高。
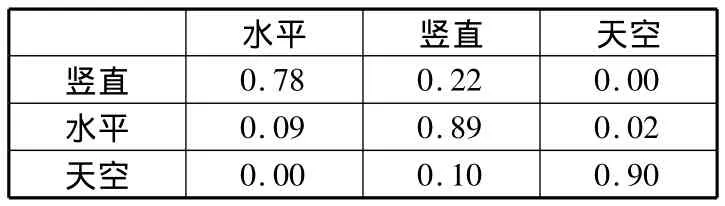
表1 原方法得到的混淆矩阵
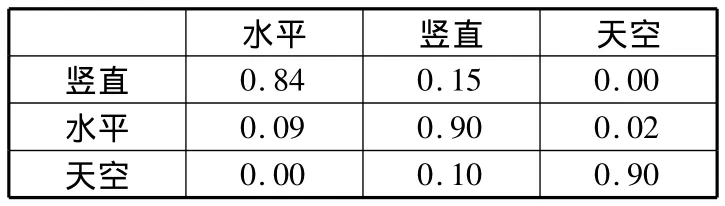
表2 本文方法得到的混淆矩阵
6 结束语
本文提出的基于上下文的图像几何分割方法,成功地将三维上下文信息引入到图像的几何分割中,建立了三维空间中物体之间的关系,提高了几何分割的准确率。然而,这种方法还存在效率不高、运算复杂、误识别等不足,这些问题将在今后的研究工作中进一步解决。
:
[1]Schneiderman H.Learning a restricted Bayesian network for object detection[C]//Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.2004,2:639-646.
[2]Viola P,Jones M J.Robust real-time face detection[J].International Journal of Computer Vision,2004,57(2):137-154.
[3]Torralba A.Contextual priming for object detection[J].International Journal of Computer Vision,2003,53(2):169-191.
[4]Torralba A,Murphy K P,Freeman W T.Contextual models for object detection using boosted random fields[C]//Advances in Neural Information Processing Systems(NIPS).2004.
[5]Bose B,Grimson E.Improving object classification in farfield video[C]//Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.2004:181-188.
[6]Carbonetto P,de Freitas N,Barnard K.A statistical model for general contextual object recognition[C]//Computer Vision-ECCV 2004.Springer,2004:350-362.
[7]Kumar S,Hebert M.Discriminative random fields[J].International Journal of Computer Vision,2006,68(2):179-201.
[8]Felzenszwalb P F,Huttenlocher D P.Efficient graph-based image segmentation[J].International Journal of Computer Vision,2004,59(2):167-181.
[9]Leung T,Malik J.Representing and recognizing the visual appearance of materials using three-dimensional textons[J].International Journal of Computer Vision,2001,43(1):29-44.
[10]Košecká J,Zhang W.Video compass[C]//Computer Vision—ECCV 2002.Springer,2002:476-490.
[11]Hoiem D,Efros A A,Hebert M.Recovering surface layout from an image[J].International Journal of Computer Vision,2007,75(1):151-172.
[12]Gould S,Fulton R,Koller D.Decomposing a scene into geometric and semantically consistent regions[C]//IEEE 12th International Conference on Computer Vision.2009:1-8.
