一种基于自动特征权值的实体相似度计算方法
2014-08-14刘杰
刘 杰
(安徽钱楼矿业集团, 安徽 六安 237000 )
本体已成为知识表示的最佳工具之一,也是语义网技术的基础。W3C(万维网联盟)公布了用RDF(资源描述框架)和OWL(Web本体语言)等表示本体,也有其他组织开发和使用的如:CYCL,DOGMA,F-Logic等语言。目前,领域本体已经应用于人工智能、软件工程、图书馆学和语义Web等多个领域[1]。不同领域之间,通过本体映射整合归类不同本体表示的资源。实体相似度计算是本体映射的关键问题,相似度计算大致分为:基于术语、基于结构和基于语义的方法,映射的过程分为:手动、半自动和自动。
本体受到分类方案、表示语言和背景知识等因素影响,同一个领域中的本体表示可能看起来颇为不同。因此,在本体映射问题中,不仅要研究本体间“类”的匹配,同时实体间的特征(例如:关系)映射也很重要。本体映射系统一般有单一策略和多重策略,在多策略系统中,不同的相似测量需要适当合并成一个单一相似值[2-3]。目前,大多数采用由专家凭经验和实验的方式给资源分配权值的方法[4],但是在不同本体表示的Web资源里,这种方法不仅耗时且不稳定。
本体映射是将源本体中的实体(包括类和特征)映射到目标本体表示,实体间的相似度计算不仅仅是实体本身,还包括其他通过关系特征联系的实体。本文提出了一种本体表示里“类”之间“公有性”概念,如果特征具有高“公有性”,则类的区分度就低,也就不能识别相似类,即如果特征“公有性”越大,则权值越小。
1 特征语义
本体有标签、注释、属性、关系(父类和子类)以及实例等多种特征类型,我们把实体之间区分特征称做“唯一性”。假设,一个特征其本体具有“唯一性”,同时在另外一个本体中具有相同特征的类,则这两个实体是等价的。例如:“人类”是世界上唯一具有思考能力的动物,因此我们可以很容易在动物本体中通过“思考”特征识别出“人类”类。相反,由于“人类”类每个实例都具有相同特征,所以他们很难区别。
本文定义Comf(c1,c2)表示基于特征的两个实体关联语义相似度不同的特征类型具有不同的语义形式。例如,对于字符串类型的“标签”和“注释”,相关的语义可能是一组词语的标签串的同义词,而一个关系特征的关联语义可能是通过关系连接的一组类。定义value(c,f)表示类c的特征f值,sem(f,c)表示与类c上特征f的语义关联值,则定义一个字符串类型的特征f,实体c1和c2的Comf(c1,c2)值定义如下:
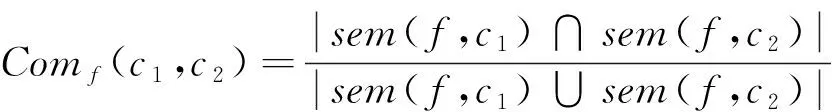
(1)
式中:sem(f,c1)和sem(f,c2)分别表示与value(c1,f)和value(c2,f)相关联的同义词组。另一方面,约束特征f,c1和c2之间的共性定义为:
(2)
最后,针对关系特征如:“父类”、“子类”和“实例”的值可以认为是一个源自特征实体的集合。c1、c2之间的关系特征Comf(c1,c2)定义为:
(3)
通过上面的计算得到特征概念Comf(c1,c2)值,用其计算特征权值。定义O表示本体,C表示属于O的一组实体,F表示C上的一组特征,包括“标签”、“注释”、“父类”、“约束”、“关系”和“实例”等。一个特征的Comf(c1,c2) 定义为:
(4)
式中:n—C中类的数量;ci、cj—C中类。特征f的权值定义为:
Wf=1-CMf
(5)
2 相似度计算
当计算出两个本体表示的实体特征权值后,类之间相似度计算可以通过整合各种特征权值计算得到,类和特征在相似度计算中互相影响[6-7]。由于类由一组特征描述,所以相似度计算要考虑特征相似度。本文采用迭代算法进行本体映射。
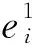
(6)
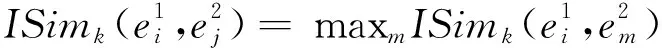
其中SIMk属性值以类型为依据:
(1)如果X和Y是不同类型,则SIMk(X,Y)=0。
(2)如果X和Y都是“字符型”、“数值型”等相同类型,如果X=Y,则SIMk(X,Y)=1;否则:
(3)如果X和Y是实体集合,则:
图1为样例本体表示。源本体中的实体“Book”和目标本体中的实体“Book”相似度计算如下:
其中SimilarityOnSuperClass、SimilarityOnLabel和SimilarityOnSubClass是相似度(SIMk)计算通过features、super_class、label和sub_class各自对应的特征相似度(Simk)和特征权值(W)。
在循环过程中,当最近的调整函数Ak+1和相似度函数Simk+1与Ak、Simk值相同时,则跳出循环,停止迭代。调整算法如下:

图1 样例本体表示
PROCEDURE: Ontology Mapping
INPUT: Ontology O1,O2OUTPUT: Alignnment A
BEGIN
W1=ComputeWeight(O1)
W2=ComputeWeight(O2)
A0=ComputeInitialAlignment(O1, O2)
Sim0=ComputeInitialSimilarity(O1, O2,A0)
k=1
WHILE k≠-1
FOR eiin O1
FOR ej in O2
PUT(Simk, ComputerSimilarity(ei, ej, Ak-1))
END_FOR
END_FOR
Ak=GetAlignment(Simk)
IF Simk≒Simk-1AND Ak≒Ak-1THEN
k=-1
ELSE
k=k+1
END_IF
END_WHILE
OUTPUT(A)
END_BEGIN
END_PROCEDURE
如算法所示,如果本体O1和O2的实体数分别是n和m,算法的时间复杂度是O(n×m)。
3 实验结果与分析
采用OAEI 2009语料库作为测试数据,评价性能指标有准确率p、召回率r和F。计算公式如下:
实验数据包含了33个确定类、24种关系、44个属性、56个实例和20个无属性实例。实验将文中提出的AFW法与Lily、MapPSO、TaxoMap等方法[8]做了比较,如表1所示,文中提出的AFW法由于采用了自动权值计算方法,提高了匹配效率,在3个标准方面都有显著提高。

表1 实验结果比较
4 结 语
本文提出了用权值法表示特征的重要性,通过对特征语义的分析,设计出实体权值的计算模型,计算出各关系间的相似度权值。通过采用迭代法的本体映射实验,采用自动特征权值计算方法提高本体映射效率,与其他的系统相比在准确率、召回率、F-measure等方面都具有较好的特性。今后还将增加算法的鲁棒性和可调试性能研究。
[1] 周胜臣,瞿文婷,石英子,等.中文微博情感分析研究综述[J].计算机应用与软件,2013,30(3):161-164.
[2] 熊芳,黄宏斌,黄玉成.一种基于语义相似度的信息资源语义聚类算法[J].计算机工程与科学,2012,34(11):175-179.
[3] 姜孟晋,周雅倩,黄萱菁.基于同义实体扩展的冗余信息去重[J].中文信息学报,2012,26(1):42-50.
[4] 崔晓军,肖红宇,丁立新.基于距离的自适应 Web 数据库记录匹配方法[J].武汉大学学报:理学版,2012(1):19.
[5] 赵海霞,李道申,刘勇,等.一种 Deep Web 查询结果的实体抽取方法[J].计算机工程与应用,2012,48(36):160-163.
[6] 齐玉东,闫晓斌,谢晓方.基于LISA理论的概念模型相似度计算[J].计算机工程与应用,2012,48(3):40-42.
[7] 董登辉, 肖刚, 张元鸣, 等.基于多粒度服务库的SOA参考模型及其应用[J].计算机应用与软件,2012,29 (10):152-155.
[8] 孙明,陆春生,徐秀星.一种基于 SVM 和AdaBoost的Web实体信息抽取方法[J].计算机应用与软件,2013,30(4):101-106.
