基于多样本字典的单音符实时稳健识别算法
2014-08-10刘兴永
刘兴永,李 锵,关 欣
(天津大学 电子信息工程学院,天津 300072)
基于多样本字典的单音符实时稳健识别算法
刘兴永,李 锵,关 欣
(天津大学 电子信息工程学院,天津 300072)
在时域线性叠加识别法原理的基础上,提出多样本字典、多样本字典后处理等技术,这些技术克服了单样本字典中单输入对应单输出权重系数α,导致正确识别帧数少,从而引起结果可靠性降低的缺点,提高了音符识别正确率和稳健度。经实验验证,本文音符识别算法与单样本字典识别法相比,识别率提高了3%,稳健度提高近2倍(尤其对于高八度区音符识别稳健度更高),实现了对输入单音符音频实时、准确的识别。
单音符;时域识别;多样本字典;实时;稳健度
音乐转录是计算机自动将实际音乐音频转换到音乐抽象符号的技术,与人工音乐转录相比,可大大提高转录效率与质量,是音乐信息检索领域中重要且具有挑战性的研究问题之一[1]。本文主要针对单基音音乐进行转录(音频信号来源于实际钢琴演奏的88个单基音音乐),提取音频信号中的音符信息,即根据演奏者演奏的实际音乐音频,确定某特定时间片段内的声音由哪些单音符组合而成。该技术在乐器辅助练习、计算机自动伴奏、音乐信息检索等相关领域具有广泛的应用价值。
早期单基音音乐音频中音符识别方法通过分析所录制音频频域信息得到音符信息[2-3],klapuri采用迭代估计、消除机制来估算音乐音频中存在的基频f0[4]。但由于跨八度音符的基音频率、谐波频率重合与时频分辨率等问题,音符频域识别较为困难。Raphael采用模式识别的方法,在提取和弦序列频域特征的基础上,用隐形马尔科夫模型来描述和弦序列,进而实现音符的识别[5],RBF神经网络模型也可用于钢琴音符的识别[6]。但是模式识别只适用于非实时识别,且计算量大。日本学者Yoshiaki Tadokoro提出采用梳状滤波器的方法,即建立多个并行滤波器,仅滤掉或保留特定频率的信号(88单音符所在频率),从而判断输入信号的频率即音符名,达到了较好的识别效果[7]。法国学者Juan Bello提出时域音符识别方法,建立88个独立音符的样本字典,将输入数据与样本字典中各音符样本数据分别做互相关,得出输入信号中各单基音音符所占权重系数[8]。Juan Bello时域识别法使用单样本字典,正确识别帧数较少,识别结果不稳健,难以应用到实际音符识别系统。
笔者在Juan Bello线性叠加时域识别法的基础上,采用多样本字典、多样本字典后处理与能量检测技术,将正确识别率提高到98%,稳健度提高了2倍,实现对钢琴单音符实时、稳健的识别,达到较好的实际应用效果。
1 线性叠加模型
时域线性叠加模型假设任何音乐音频都是由一个或多个单基音音符线性组合而成的,通过与事先建立的单基音音符样本字典比较,即可得到音乐音频中所包含的单音符音名。xi(n)为归一化后的钢琴单音符时域信号(i=1,2,…,M,M=88)。定义样本字典D={xi},i=1,2,…,M,即包括88个单音符波形的数据库。s(n)为测试输入信号波形(n=1,2…,N,这里输入信号时长为100 ms,则N=0.1×fs,fs为音频采样率)。本文假设样本库中单音符xi(n)与其响度无关,即波形与按键力度、速度无关。测试输入信号s(n)是由一个或多个单音同时发声组成的,这些单音符是线性无关的,即实验中忽略了单音发声时的耦合现象,简化为下列线性模型:
ε.
(1)
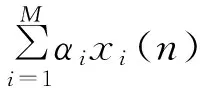

(2)
在上述定义下,音符识别任务转换为计算输入信号中各音符的权重系数αi,只需通过简单的矩阵计算,即可得到权重系数,即s(n)中包含的单音符的音名。样本字典D是M×N矩阵,包括M个单音符归一化后的波形。由于D中各行是线性无关的[8],因此M×M矩阵DDT是非奇异矩阵,即可逆。s是输入信号s(n)的矩阵形式,因此权重系数可用下式求取:
α=(DDT)-1Ds-ε′.
(3)
其中ε′=(DDT)-1Dε.
测试输入信号s(n)与样本字典D中xi(n)的相位一般不同步,同时和弦s(n)中不同单音符发声的时刻可能存在差异,因此上述算法得到的结果并不精确,必须调整二者相位,以便得到更为精确的权重系数矩阵。相位调整具体过程:输入信号s(n)与样本字典D中的每个xi(n)做互相关运算,求出对应的相位延时ti:
ti=arg max{xcorr(xi,s)}.
(4)

.
(5)
在实际应用中,预先无法得到线性模型和输入实际信号的差值ε′,因此还需依据特定规则(2.2规则I)对计算所得α系数矩阵进行筛选,最终取出符合规则的α系数矩阵,其最大值对应的midi即可转换音符名。
2 多样本字典
2.1 构建多样本字典
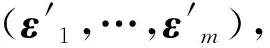
(6)
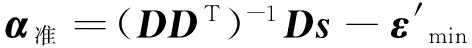
(7)
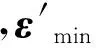
2.2 多样本字典后续处理
多样本字典后续处理主要目的在于选出最优的α矩阵。帧长为100 ms的测试输入信号s(n)分别与6个样本字典D代入(8)式计算,得到6个权重系数α矩阵。在6个α矩阵中,实验只选取满足一定规则的α(k)(k=1,2,…,6),从有效α(k)结果中得到输入信号s所包含的音符名。不失一般性,这里假设αi(k)(i=1,2,…,88)权重系数矩阵中最大值为αi max(k),则α(k)结果有效的准则I为:
1)α(k)中大于0.35×αi max(k)的个数不超过2个,且其midi号相差为12或24(一个或两个八度);
2)α(k)中大于0.25×αi max(k)的个数不超过5个;
3)α(k)中大于0.15×αi max(k)的个数不超过10个。
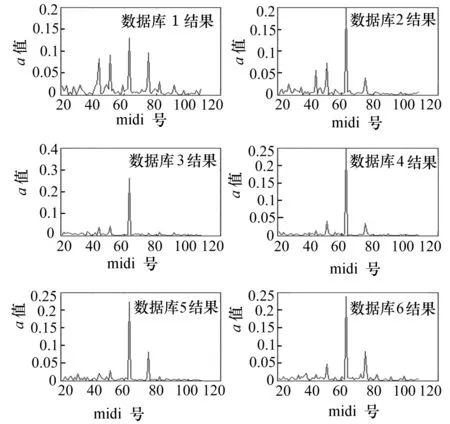
图1 多样本字典权重系数
只有同时满足上述三个条件,多样本字典后处理部分才认为α(k)权重系数矩阵是有效的,即α(k)矩阵中取到的最大值的midi号可作为测试输入信号s的结果输出。图1是测试信号为midi 63的音符计算得到的6组α(k)。样本字典D2,D3,D4,D5,D6所得αi(k)矩阵中最大值都为α63(k),且每个矩阵的剩余元素都符合规则I中的条件1、2、3,因此保留这四组权重系数矩阵,且midi63为识别结果。
多样本字典后处理部分保证了在多个样本字典条件下,结果的唯一性和准确性,不仅适用于音符多样本字典处理而且适用于单样本字典的处理,是多样本字典音符识别系统必不可少的环节。
3 实验测试与结果分析
实验中,测试数据一个月内每天随机选取时间所录制的88单音符音频数据:data1、data2、…、data30(安静室内录制88个单音符,采样率为44.1 kHz),其中随机取某一天所录制数据作为样本字典D中数据来源。对于测试数据,本文方法的平均识别率为98%。在音符起始阶段出现少数几帧跨八度的识别错误,即识别结果与正确音符相差一个八度,能量检测算法的应用在一定程度上遏制了这种情况的出现。对于单数据库和多数据库识别效果差异主要体现在对低八度区音符(midi号21~60)的识别上,因为低八度区音符的持续时间较高八度区(midi号61~108)长近400 ms。表1是Juan Bello单样本字典与本文多样本字典两种方法下,88单音符的平均识别帧数。
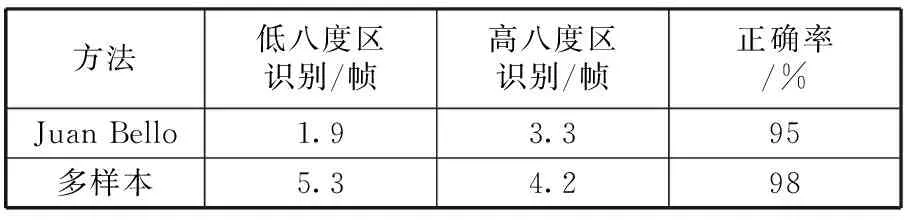
表1 测试结果
使用多样本字典D情况时,测试输入帧与6个样本字典中某一样本字典相匹配概率的较大,即对于完整测试音符,与样本库相匹配的概率为各帧相匹配概率P(S/Di)之和。匹配概率增大意味着存在连续多帧的正确识别结果。而单样本字典情况下,对于一完整测试音符,只有与样本库中相位正好相近的少数测试帧才会出现匹配,此情况下,整个音符的匹配概率为max(P(S/Di)),即存在下式:
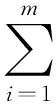
(8)
本实验程序在代码优化后,耗时有望控制在100 ms内,完全能满足实时音符检测。实验结果表明,多样本字典比单样本字典音符识别算法的识别率提高了3%,稳健度提高近2倍,即相比于单样本字典在低八度区仅1~2帧能正确识别,多样本字典平均连续近5帧测试结果正确,结果更为可靠稳健,且识别率达98%,更具有实用性。
4 结束语
本文主要讨论了在音符时域识别基础上,采用能量检测和多样本字典来提高识别率、降低计算时间以及避免单样本字典对端点检测的依赖性。在实际应用中,基于此算法的系统在识别率、运算速度与稳健度等方面完全能满足实时、稳健的识别。但是,本文时域音符识别算法唯一的缺点就是构建样本字典的数据和测试数据必须来源于同一架钢琴,这是由钢琴的物理特性决定的。在此单音符识别基础上,若要将其拓展为多音符检测系统,则需要对多数据库后处理端的规则进行调整,这个调整需要根据经验值确定。
[1]Sebastian Bock, Markus Schedl.polyphonic piano transcription with recurrent neural networks[J]. IEEE 2012.
[2]M Piszczalski, B A Galler. Automatic music transcription[J]. Computer Music Journal, 1977(4):24-31.
[3]J AMoorer. On the transcription of music sound by computer[J]. Computer Music Journal, 1997,1(4):32-38.
[4]A Klapuri. T Virtanen, J M Holm.Robust multipitch estimation for the analysis and manipulation of polyphonic musical signals[C]∥ In proceedings of the COST-G6 conference on Digital Audio Effects Verona, Italy, 2000.
[5]C Raphael.Automatic transcription of piano music[C]∥In proceedings of the 3rdinternational conference on Music Information Retrieval. Paris, France, 2002.
[6]张雪英,陈洁,孙颖.改进的HMM系统在英语语音合成中的研究[J].太原理工大学学报,2013,44(1),16 -19.
[7]Tadokoro Y, Matsushita F. Signal identification for a wide-range sound(piano) using notch and resonator-type comb filter[C]∥ICSPCS 2008 2ndinternational conference on signal processing and communication system, 2008.
[8]J P Bello, L Daudet, M B Sandler.Automatic piano transcription using frequency and time-domain information[C]∥ IEEE transactions on Audio Speech and Language Processing, 14:2242-2251.
(编辑:贾丽红)
Real-timeandRobustNoteRecognitionBasedontheMutil-sampleDictionary
LIUXingyong,LIQiang,GUANXin
(CollegeofElectronicsandInformationEngineering,TianjinUniversity,Tianjin300072,China)
Real-time and robust note recognition algorithm is the fundamental of the note music transcription and music track for the practical application. On the basis of the time domain linear superposition principle of recognition method, the article proposed the techniques of mutil-sample dictionary and mutil-sample dictionary post-processing.The techniques overcame the shortcomings that, in the single sample, the single input corresponds to the single output weight coefficient α, leading to the less correctly identified frame, thus resulting in reduced reliability.Therefore,they improved the recognition accuracy rate and soundness. The experiments prove that, compared to the single sample dictionary, under the help of this article’s note recognition algorithms, the recognition rate increased by 3%, and the soundness increased nearly two-fold, achieving the goal of real-time accurate identification of the audio-input single-note.
single-note; time-domain recognition; mutil-sample dictionary; real-time; soundness
2013-08-06
国家自然科学基金资助项目(61101225)
刘兴永(1989-),男,天津人,硕士,主要从事音乐信号处理、模式识别研究,(Tel)13302029660
李锵,教授,硕士生导师,(Tel)13820516837
1007-9432(2014)02-0252-03
TP391
:A
