空间数据模式匹配应用及相关研究综述
2014-08-08王育红景海涛薛华柱
王育红,景海涛,薛华柱
(河南理工大学测绘与国土信息工程学院,河南 焦作 454003)
GIS空间数据正以几何倍数逐年快速增长,为了充分利用已有数据资源,降低系统开发成本,实现综合性应用与分析,空间数据的有效共享和互操作问题一直是GIS领域研究的核心和热点。空间数据共享和互操作涉及的理论和技术问题很多,如数据模式集成(或合并)、数据实例集成、更新信息传播、语义查询处理、地理服务发现等。虽然这些技术各有特点,但它们都面临着一个基本环节——模式匹配。模式匹配是依据各种辅助决策信息,从两个或多个数据模式中确定语义相同或相关的模式元素,并根据应用需要显示声明其间具体映射关系的过程。例如,对于图1左半部分所示的来自不同GIS数据库的部分模式而言,通过匹配操作,可以发现和建立如图1右半部分所示的不同层次的相关元素及其映射关系。为进一步完善深化对空间数据模式匹配问题的理解与认识,为高效实用的空间数据模式匹配系统研发提供理论依据与技术借鉴,本文概括描述了空间数据模式匹配的典型应用,分析了当前模式匹配研究的相关内容、原理、模型及方法,并指出了现有研究面临的问题与不足。
1 模式匹配的主要应用领域
1.1 数据模式集成
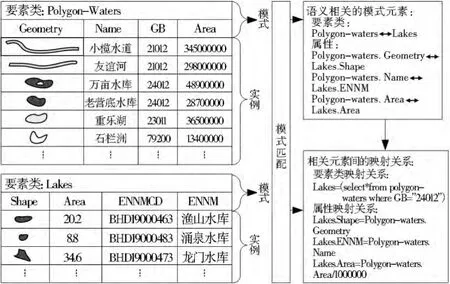
图1 模式匹配示例Fig.1 Diagram of schema matching
关于模式匹配的最早研究是从模式集成开始的。模式集成是从给定的一组独立开发的模式中构造一个全局模式的过程。由于应用领域、设计习惯及偏好不同,待集成的各种模式即使描述的是相同的现象或事物,也可能在逻辑结构和表现形式上存在一系列的差异。因此,模式集成的第一步需通过模式匹配来确定并描述这些模式间的相关元素及其映射关系。只有这些关系确定后,才可对局部模式进行合并、除冗、重构等处理,进而形成一个能综合反映多个源模式基本特征的全局模式[1,2]。
1.2 数据实例集成
简单地讲,数据实例集成就是将分散在不同数据源中描述反映各种现实事物属性特征的具体数据记录值进行有机结合,形成一个整体,在统一的环境下透明协调一致地加以使用。数据实例集成的目标是屏蔽多个局部数据源的异构性,并提供上层应用的统一查询接口。为实现这一目标,研究者提出了多种集成方式或系统,如多数据库系统、联邦数据库系统、空间数据仓库系统等[3]。这些系统遇到的问题主要集中在全局模式设计、模式映射建立、查询重写、查询优化和查询执行等方面,而其核心和基础则是通过模式匹配建立模式映射关系[4],只有依据准确有效的模式映射关系及规则,才能按照全局(或目标)模式的要求从数据源中提取所需的数据实例,并经过转换、融合、清洗等处理,最终将其提供给查询用户或者加载到数据仓库中,从而有效屏蔽不同数据源之间的实例表达差异[5]。
1.3 更新信息传播
空间数据现势性是GIS的“生命”,直接影响着其使用价值与可持续发展。伴随着GIS空间数据更新理论研究和工程实践的不断深入,更新信息传播问题已成为生产单位、应用部门及学术界共同面临的新问题。由于数据库间在数据模式和数据实例之间存在多种潜在的语义差异,当利用一个新版GIS数据库中的更新变化要素及其相关信息对另一个GIS数据库中的对应要素进行更新(即更新信息传播)时,必须首先在两个数据库间进行模式匹配操作建立模式映射关系,以引导和简化变化发现、实体识别、更新集成等操作,从而在保证更新传播实施效率的同时,最大限度地维护目标数据库的自治性、完整性、正确性和一致性[6,7]。
1.4 语义查询处理
目前使用的空间数据查询方式大都是基于关键字匹配技术,如果用户输入的查询关键字与被查数据模式元素的名称不尽相同或有所偏差,则不能返回真正需要的信息或者会返回很多无用的信息。为解决传统查询方式的不足,提出了语义查询技术[8]。语义查询又称语义检索、概念匹配,是指在相关技术(如本体等)的支持下,首先使用户的查询请求和被检索的内容在语义上都是可被计算机理解、处理的,在此基础上对用户查询语句(如Select语句)和被查数据模式元素进行匹配,然后重写查询语句中的关键字使其与被查数据模式名称相一致,从而返回准确的查询数据。
1.5 地理服务发现
网络地理服务是利用地理数据和相关的功能实现诸如地址匹配、地图绘制、路程安排等基本地理操作任务的Internet应用,它允许开发者将GIS功能集成到自己的Web应用中,而不用自己在本地实现该GIS功能[9]。随着越来越多的网络地理信息服务的出现,快速准确找到用户需要的地理信息服务显得尤为重要[10]。在服务发现过程中,一旦服务请求者和提供者使用不同的术语表示同一个概念或者是同样的词表示不同的涵义,就会发生找不到匹配的服务和找到的服务不能完全满足需求的情况。另外,地理服务版本差异造成的语义异构也将增加服务发现的难度[11,12]。与语义查询类似,通过模式匹配也可以有效解决这类问题。
2 模式匹配相关研究内容综述
近些年来,模式匹配作为数据管理与应用中的基础性问题受到了全球的普遍关注,在数据库、人工智能、信息检索、知识管理、语义Web等众多领域引起了广泛的讨论和研究。概括而言,当前对模式匹配问题的研究主要集中在匹配实施方法、匹配效率优化、匹配结果表达、匹配质量评价4个方面。
2.1 匹配实施方法研究
目前,大多数系统的模式匹配任务是在图形界面支持下靠操作员手动完成的,该方式不仅要求操作员充分了解模式元素的语义内涵,而且随着待匹配模式元素数据的增加,其费时、费力、易出错的缺陷也将变得更加突出。另外,用户需求的变化、数据源的变化等都可能造成模式的变化,从而导致这些模式间的匹配关系发生变化。显然,如果仅仅依靠手工匹配无法适应这种复杂动态的匹配需求。
为了尽量减少模式匹配过程中用户的参与,提出了多种自动(或半自动)的匹配方法及系统。Rahm等根据匹配所依据的信息类型及其结合方式对各种模式匹配方法进行了层次式划分(图2),结合图2的分类体系又对2001年以前的典型匹配方法及系统进行了比较权威的总结和评述[13]。在此分类体系基础上,Shvaiko等根据所用技术的特征(Heuristic or formal,Implicit or explicit)对其中基于模式的匹配方法做了更为详细的划分[14]。潘超等则进一步总结了2010年之前的主要方法及系统[15]。本文依据图2所示的分类结果,对模式匹配方法的基本策略和问题做简要评述。
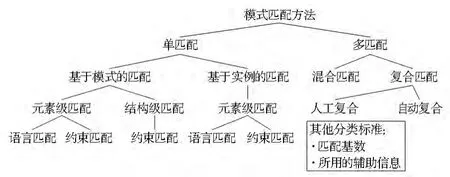
图2 模式匹配方法分类Fig.2 Classification of schema matching approaches
(1)单匹配,主要利用某一种类型的信息识别语义相关模式元素,可进一步划分为基于模式的匹配和基于实例的匹配两类。1)基于模式的匹配方法,主要通过对比模式元素本身所包含的信息(如名称标签、描述性元数据、数据类型、数据长度、结构关联关系等)判断元素是否匹配。由于数据模式设计本身是一项灵活性很大的主观活动,不同的设计者可能采用不同的机制和元素来抽象和模拟相同的现实事物或现象,并且所形成的模式结构的语义信息大部分隐含在设计者的大脑中,而模式元素本身所承载的一部分外在显式信息对模式匹配而言是不明确、不完整、易混淆的。因此,该类方法往往产生错配、漏配等情况,质量和效果不高。针对这一情况,文献[16]提出了基于信息论的模式匹配模型,尝试解决模式信息丢失或者不完整情况下的模式匹配问题。2)基于实例的匹配方法,主要依据属性字段数据值的统计概括信息(如最大值、最小值、平均值、方差)或部分重叠对应实体的属性值,来匹配识别两个数据集(如关系表)之间语义相关的属性字段[17,18],一般不能确定数据集之间的匹配关系。由于概括信息是确定属性是否匹配的必要但不充分信息,因此如果单独用其进行匹配常常会产生一些错配或漏配现象。针对这种情况有两种改进途径:一是将概括信息与其他类型的信息结合构成混合匹配;二是通过进一步分析比较数据集之间部分对应实体(或重复记录)的属性值来确定相关的属性,但这种方式目前通常以预先手动建立实体对应关系为基础,自动化程度低,属性相关性对比分析和度量模型较单一,尚没有充分考虑语义相关属性在具体属性值上的各种表达差异,仍有很大的扩展改进空间。
(2)多匹配,主要利用多种类型的信息或方法识别语义相关模式元素,可以进一步划分为混合匹配与复合匹配两大类。1)混合匹配主要通过综合使用多种匹配指标或信息源(如名称信息、元数据描述信息、数据约束信息、实例概括统计信息、属性依赖关系等)来确定匹配元素。混合匹配在确定一对模式元素是否匹配时,同时考虑了多种匹配标准,对于不符合标准的候选成员能够较早地被删除。因此,这种方法与单独执行多种匹配方法相比,可以减少比较模式信息的遍历次数,不仅能取得较好的匹配性能和效果,而且匹配效率也得到了提高。但由于多种来源的信息具有不同的表达形式,一般并不能被直接应用于混合匹配,常常需要制定高效的策略和规则对其进行规范化处理。混合匹配所依据的匹配信息和规则往往由设计者事先规定,一般不易进行调整和修改,灵活性较低。2)复合匹配主要通过对多个独立匹配方法(如基于模式的匹配、基于实例的匹配、混合匹配等)所取得结果的组合分析来确定匹配元素。复合匹配允许用户根据应用需要,灵活地选择现有方法并按不同的顺序(如并行顺序、串行顺序、混合顺序)加以执行。在串行执行时,前面匹配方法所取得的匹配结果,可以用作后面匹配方法的输入,从而达到反复修改匹配结果的目的。复合匹配是以单个匹配方法为基础的,为保证其效率和效果,不仅要尽可能地提高每个成员匹配方法的效率和效果,而且应该选择正确的执行顺序、制定合理的结果重用和组合策略[19]。静态组合的匹配算法和人工调节的匹配参数难以适应自动匹配的要求,如何对现有的匹配算法进行动态选择、搭配、组合、重用以及对匹配参数进行自动调节是复合匹配面临的一个有待深入研究的重要问题。
每种匹配技术都各有其优点和适用范围,综合使用多种匹配信息或方法能够充分发挥不同技术间的互补性优势,有效提高匹配系统的匹配质量和通用性。但随着匹配信息或方法的增加,系统的复杂性也将随之增加。
2.2 匹配效率优化研究
当前模式匹配的难点,不仅在于缺乏切实可行的判别模式元素是否匹配相关的策略和规则,更在于依据判别规则执行模式匹配的代价偏高,必须进行大量的计算比较才能确定获取潜在的匹配元素。模式匹配中最常用的两两比较法,也称嵌套循环法或笛卡尔法,是将两个待匹配模式元素集合做笛卡尔乘积,根据用户所定义的规则和策略,对结果集中的每对元素进行比较,如果比较结果满足所定义的规则条件,则认为它们是匹配元素。该方法简单,能够最大限度地保证匹配结果的质量和精度,但是随着待匹配元素数量的不断增加,所需的处理时间和系统资源的消耗将呈指数级增长,在实际应用中的可行性和使用价值并不高。因此,必须加强模式匹配效率优化模型及算法的研究。
目前,只有少数几个系统考虑处理了模式匹配的执行效率问题,根据模式匹配策略的不同,提出了不同的模式匹配执行效率优化技术。概括而言,现有模式匹配执行效率优化所采取的基本策略主要有如下5种[20]:1)分而治之,先将待匹配的模式元素集划分为不 同 的 块 (Blocks)、区 (Partitions)或 簇(Clusters),然后在块(区或簇)之间执行模式匹配。该策略降低了匹配比较的搜索空间,效率较高,但可能降低匹配质量。2)模式过滤,依据相关的上下文信息或通过问卷调查预先排除掉一些模式元素,从而降低比对次数,提升匹配效率。3)避免重复,在模式匹配执行过程避免一些相同子任务的重复执行。4)改善数据结构,利用诸如索引、Hash表等特殊类型的数据结构,减少待匹配模式元素间的比较次数,从而提高执行效率。5)优化模式元素相关性度量模型(如编辑距离等)的计算效率等。
随着大数据时代的到来,势必出现大模式的匹配问题。大模式的“大”不仅意味着数量的大,还代表着模式种类多、结构杂、差别大、变化快等。由于目前尚没有对大模式匹配问题给予充分的考虑和有效的处理,若采用现有策略执行匹配将会因时间复杂度过高而得不到理想的匹配结果。针对大模式匹配执行效率问题,可通过大模式聚类分割技术加以解决[21]。目前这一技术仍需攻克3个核心问题:如何分割模式;如何选择需要进行匹配的模式片断;如何避免模式分割可能造成的结果遗漏。
2.3 匹配结果表达研究
匹配结果(模式映射)表达的主要任务是存储和组织通过匹配识别发现的相关模式元素及其映射关系,并构建相应的存取和检索方法,以引导和简化各种应用处理中的其他操作。目前,有一些匹配工具把模式映射保存在纯文本文件中,而且不同工具定义的模式映射文件格式不同,缺乏足够的语义表现力和处理能力,使得模式映射的读取过程较烦琐,造成不同系统间难于共享模式映射,通用性不强;还有一些匹配工具使用关系数据库存储和管理模式映射,但由于模式映射的半结构化特征,往往导致数据表中出现很多值为NULL的字段,从而造成非常大的冗余,使得很多复杂的匹配关系(如条件匹配、部分匹配、计算匹配等[22])无法得到有效的表达,且每当待匹配元素数目发生变化时,将可能导致整个数据表的结构重构,不便于模式映射的管理和维护。
针对上述模型及方法的不足,一些学者开始尝试利用基于逻辑的语言(如一阶逻辑、描述逻辑、Datalog等)或半结构化模型(如XML、RDF等)来表达和存储模式映射。例如,文献[23]利用一阶逻辑表达XML模式与OWL本体间的语义映射;为评价对比现有基于逻辑的映射语言的共性与差别,文献[24]采用分布式一阶逻辑来统一现有的各种映射语言;文献[25]采用巴克斯范式(Backus-Naur Form,BNF)来表达语义映射;文献[26]提出了一种新的映射语言——RDF Mapping Schema来表达XML数据和RDF数据之间的语义映射;文献[27]在BRICKS系统中采用XML来存储和管理模式映射。
目前大部分模式匹配研究的重点仍集中在如何发现和找到语义相关元素匹配对,有关匹配结果表达的研究才刚刚起步[28],有些表达语言或模型的提出尚处于思想萌芽阶段,也只是仅仅给出了一些示例性的表达结果,仍缺乏系统性的研究,更没有形成统一的表达语言或模型。即使是同一种语言或模型,表达映射的方式也不尽相同,所支持的功能和算子差别较大[29]。匹配结果表达的研究仍然面临着许多开放性问题,如表达模型能够支持的映射关系类型及语义转换函数种类、匹配结果的检索与编辑、匹配结果的有效性检验、匹配结果的可视化等。
2.4 匹配质量评价研究
虽然人们对模式匹配问题进行了广泛研究,但大部分的自动匹配方法还停留在高度实验阶段,而得不到广泛的实际性应用。其中也有一些较为实用的系统出现,而这些系统却依旧需要大量的人机交互或后处理工作,还远远满足不了实际需要。
当前有关自动匹配质量的研究主要集中在质量评价模型和策略上,概括而言,各种自动匹配方法及系统的匹配质量可以从有效性(Effectiveness)、效率(Efficiency)、通用性(Genericity)和易用性(Ease-ofuse)4个方面加以评价[30]:1)有效性:主要考虑匹配结果的正确性和召回率,通常用Precision和Recall两个单项指标及F-Measure(a)、F-Measure、Overall等几个综合指标加以衡量[31]。2)效率:主要考虑系统执行匹配时所消耗的资源,如时间、内存等,通常情况下只采用时间指标来评价匹配效率。3)通用性:主要考虑系统的应用领域、所支持的数据模型或类型及系统是否可以支持在线匹配或离线匹配。目前还没有评价匹配系统通用性的定量指标或模型。4)易用性:不论全自动匹配能否实现,用户的参与及交互总是需要的,易用性主要考虑通过自动匹配能够节省多少人力,一般应综合考虑匹配执行的预处理与后处理两个阶段。然而,现有的评价策略常常将预处理阶段的人力参与忽略掉,只考虑后处理阶段用于添加遗漏匹配、移除或修改错误匹配的人力参与[31]。上述的有效性指标可在一定程度上反映模式匹配后处理阶段的人力参与情况,但由于这些指标的取值介于0~1,直接用其评价人力参与情况还不太恰当。针对这种情况,Bogdan等提出了简单可用性(Simple Usability)模型和简单成本(Simple Cost)模型,这两个模型分别根据人机交互过程中拖拽、单击、双击3种不同的鼠标行动及其执行成本来评价人力参与情况[32]。
以上单因素评价模型彼此间是相互矛盾的,仅利用其中的任何一种都不能全面客观地评价匹配系统,因此,需要将这些指标综合起来考虑,对匹配系统进行总体上的质量评价,这实际上是一个多目标模糊决策难题。文献[33]从有效性和效率两方面讨论分析了匹配系统的总体评价方法,但却忽略了通用性和易用性两方面的因素。总体而言,目前人们虽然认为自动匹配的质量评价与控制是一个很重要的问题,却没有高度重视它,自动匹配质量问题的研究还没有全面深入地展开。
3 结语
经过近30年的不懈努力,模式匹配问题研究已取得了较为丰富的学术成果,从最初的利用元素自身的各种信息进行模式匹配,到后来集成各种类型的结构信息、数据实例信息来辅助匹配,再到近年来为模式匹配方法寻找理论支持,提供人性化的用户干预工具等。但由于模式匹配本身的主观性与复杂性,目前仍然存在着一些问题和不足。
现有大多数研究主要集中在匹配方法上,一般只专注于不同模式之间的简单匹配(即1∶1匹配),不能有效识别复杂匹配(即1∶N、M∶l和M∶N匹配),应用往往局限于特定领域或特定模式,通用性有待提高。对模式匹配的不确定性、模式通用表达模型、匹配方法的质量评价、模式结果的后处理分析、匹配结果的存储管理及可视化维护等问题尚缺乏整体系统的分析和全面深入的研究。
从文献资料上看,目前针对空间数据模式匹配的研究仍比较薄弱,有关空间数据模式匹配问题的阐述大多是一些附带的概念性解释,缺乏针对性的深入分析,仅有少数研究侧重于具体方法的设计及原型系统的实现[34-39]。与空间数据模式种类多、规模大、结构复杂的特点相比,现有研究尚不能满足一个理想模式匹配系统在通用性、强壮性、灵活性、交互性和扩展性等方面的要求。因此,很有必要进一步积极开展针对空间数据模式匹配的系统性研究工作,从而为空间数据资源的高效共享与灵性服务提供理论支持与技术保障。
[1] 王宏鼎,谭少华,唐世渭,等.基于模式元素语义关系的模式合并方法研究[J].北京大学学报(自然科学版),2007,43(3):405-411.
[2] VOLZ S,DANIELAS N,GROSSMANN M,et al.On creating a spatial integration schema for global,context-aware applications[A].Proceedings of GeoInfo 2008[C].2008.13-24.
[3] 王育红.空间数据集成及冲突消解方法综述[J].测绘科学,2011,36(2):81-83.
[4] 刘敏超,刘卫东.数据集成系统关键问题研究[J].计算机应用,2006,26(7):1507-1510.
[5] 李军,苏国中,李萌.利用GML模式映射屏蔽地理空间数据源的异构性[J].测绘科学,2012,37(1):38-41.
[6] BRAUN A.From the schema matching to the integration of updating information into user geographic database[A].Proceeding of 12th International Conference on Geoinformatics,Geospatial Information Research:Bridging the Pacific and Atlantic[C].2004.211-218.
[7] 王育红,陈军.基础地理数据库更新信息传播实施方法研究[J].武汉大学学报(信息科学版),2010,35(9):1116-1120.
[8] 王艳东,龚健雅,戴晶晶.基于本体的空间数据语义查询研究[J].测绘信息与工程,2007,32(2):32-35.
[9] 安杨,边馥苓,关佶红.基于Ontology的网络地理服务描述与发现[J].武汉大学学报(信息科学版),2004,29(12):1063-1066.
[10] 程钢,杜清运,蔡忠亮.基于本体的地理信息服务查询组件设计[J].测绘信息与工程,2008,33(2):31-33.
[11] 何杰,陈能成,王伟,等.基于动态模式匹配的多版本网络要素服务统一访问方法[J].测绘科学,2011,36(1):169-172.
[12] 何杰,陈能成,郑重,等.利用语义的多版本网络覆盖服务模式匹配方法[J].武汉大学学报(信息科学版),2012,37(2):210-214.
[13] RAHM E,BERNSTEIN P A.A survey of approaches to automatic schema matching[J].The VLDB Journal,2001,10(4):334-350.
[14] SHVAIKO P,EUZENAT J.A survey of schema-based matching approaches[J].Journal on Data Semantics,2005,4(1):146-171.
[15] 潘超,杨良怀,龚卫华.模式匹配研究进展[J].计算机系统应用,2010,19(11):265-277.
[16] 赵晨露,申德荣,寇月,等.应用信息论的数据导向模式匹配方法[J].计算机科学与探索,2013,7(9):719-830.
[17] 李蓉蓉,王晖,陈冉.基于属性实例集合语义相似的模式匹配[J].计算机科学,2011,38(12):151-154.
[18] MOISES G C,ALBERTO H F L,MARCOS A,et al.An evolutionary approach to complex schema matching[J].Information Systems,2013,38(3):302-316.
[19] 潘峰,孙鹏,张电.一种改进的多策略模式匹配与结合方式研究[J].计算机与数字工程,2011,39(11):101-105.
[20] ERIC P,HENRIKE B,ERHARD R.Rewrite techniques fore performance optimization of schema matching processes[A].Proceeding of 13th International Conference on Extending Database Technology[C].2010.433-464.
[21] 杜小坤.数据库模式匹配算法研究[D].武汉:华中科技大学,2010.
[22] 韩忠明,陈德华,乐嘉锦.模式映射以及表达[J].东华大学学报(自然科学版),2006,22(2):42-45.
[23] YUAN A,BORGIDA A,MYLOPOULOS J.Constructing complex semantic mappings between XML data and ontologies[A].Proceedings of the 4th International Semantic Web Confrence[C].Ireland,2005.6-19.
[24] SERAFINI L,STUCKENSCHMIDT H,WACHE H.A formal investigation of mapping languages for terminological knowledge[A].Proceedings of the 19th International Joint Conference on Artificial Intelligence[C].2005.576-581.
[25] ZHU Y,LI X.Representations of semantic mapping:A step towards a dichotomy of application semantics and contextual semantics[J].International Journal of Project Management,2007,25(2):121-127.
[26] XIAO H,ISABEL F,HSU F.Semantic mappings for the integration of XML and RDF sources[A].Proceedings of the VLDB Workshop on Information Integration on the Web[C].2004.40-45.
[27] KEARNEY K.Ontology mapping in BRICKS[A].Proceedings of Workshop on Ontology-Driven Interoperability for Cultural Heritage Objects[C].2007.
[28] STUCKENSCHMIDT H,USCHOLD M.Representation of semantic mappings[A].Dagstuhl Seminar Proceedings:Semantic Interoperability and Integration[C].2005.04391.
[29] THOMAS H,O′SULLIVAN D,BRENNAN R.Evaluation of Ontology Mapping Representations[R].Knowledge & Data Engineering Group,2009.
[30] KÖPCKE H,RAHM E.Frameworks for entity matching:Acomparison[J].Data & Knowledge Engineering,2010,69(2):197-120.
[31] DO H,MELNIK S,RAHM E.Comparison of schema matching evaluations[J].Lecture Notes in Computer Science(Web,Web-Services,and Database Systems),2002,2593:221-237.
[32] ALEXE B,TAN W C,VELEGRAKIS Y.STBenchmark:Towards a benchmark for mapping systems[A].Proceedings of VLDB Endowment[C].2008,1(1):230-244.
[33] ALGERGAWY A,SCHALLEHN E,SAAKE G..Combining effectiveness and efficiency for schema matching evaluation[A].Proceedings of 1st International Workshop on Model-Based Software and Data Integration[C].Germany,2008.19-30.
[34] 关佶红,虞为,安扬.GML模式匹配算法[J].武汉大学学报(信息科学版),2004,29(2):169-174.
[35] VOLZ S.Data-driven matching of geospatial schemas[J].Lecture Notes in Computer Science,2005,3693:115-132.
[36] 章勤,孙盛,袁平鹏.基于模糊集的地理信息模式匹配算法[J].华中科技大学学报(自然科学版),2006,34(7):46-48.
[37] 王育红,陈军.基于实例的GIS数据库模式匹配方法[J].武汉大学学报(信息科学版),2008,33(1):46-50.
[38] 赵元,马劲松.GML模式匹配技术研究[J].计算机工程与科学,2009,31(7):139-141.
[39] PARTYKAA J,PARVEENA P,KHANA L,et al.Enhanced geographically typed semantic schema matching[J].Web Semantics:Science,Services and Agents on the WorldWideWeb,2011,9(1):52-70.
