基于有向边和属性的相似度模型设计
2014-08-07张淑丽
崔 岩,张淑丽
(西北工业大学明德学院计算机信息技术系,西安710124)
基于有向边和属性的相似度模型设计
崔 岩,张淑丽
(西北工业大学明德学院计算机信息技术系,西安710124)
通过分析单一条件下相似度算法的计算原理及设计思想,以有向图的形式描述概念,分析和推导了有向边、语义重合度及属性相似度的计算模型,给出了一个含有语义及属性权值的概念相似度计算模型。最后通过对比传统模型的性能测试,验证了新模型对相似度计算的精度。
概念相似度;有向边;属性权值;本体
1 设计背景
概念相似度的研究,是在以本体为设计核心的检索系统中研究的重点问题。它不仅对于语义提取中词频分析及阈值的设定有一定的参考意义,从应用角度分析,它也直接影响查询效率的高低与查找代价的大小。因此对于概念相似度的研究十分重要。
通过不同角度对概念之间相似度特点的分析和描述[1],可以总结出某一个方面对概念相似度描述的计算模型。不同角度的侧重各有差异,都有明显的优势和缺陷,基于这些不同描述角度给出的计算模型,找出一个或者几个最适合或最接近现实情况的模型,作为相似度计算的主要依据。
1.1 单一条件下的计算模型
(1)基于内容的语义相似度计算模型
如果两个概念共享的信息越多,则它们之间语义相似度也就越大。基于这样的原理,在概念网络层次中,每个概念结点都可以看做是对其父结点的细化,它们继承了父结点的信息。那么两个概念的语义相似度就可以用它们最近共同的祖先结点的信息内容来衡量。
这样可以得到概念层次网络中任意两个概念之间的语义相似度。给定两个概念c1和c2,其计算模型为公式(1)所示:
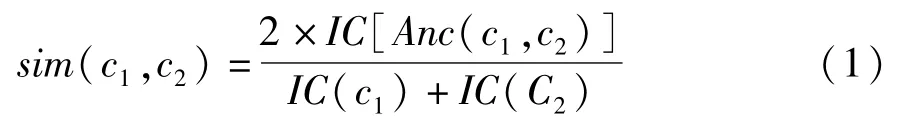
其中Anc(c1,c2)表示概念结点c1和c2在网络中的最近共同祖先结点;IC(c)表示概念c所拥有的信息量。
(2)基于属性的语义相似度计算模型
一般情况下,两个客观事物如果有多个属性相同,则说明它们是相似的事物,概念,也具有类似的性质。基于属性的语义相似度计算模型就是根据这个原理来进行相似度计算的。
由Tversky提出的一种语义相似度计算方法就是基于属性的。如公式(2)所示。

其中:(c1∩c2)表示两个概念相同的属性集;c1-c2表示c1相对于c2所独有的属性集;c2-c1表示c2相对于c1所独有的属性集。
(3)基于距离的语义相似度计算模型
通过文献[1]指出,语义相似度的计算是以概念层次结构为基础的,计算概念间与它们的最近公共父节点的距离来计算它们的语义距离,进而计算出概念间的相似度。
在只存在上下位关系的概念层次机构中,任意的两个概念间,连通它们的最短路径就是通过它们的最近公共父节点或者是通过它们的最近公共子节点,因此可以计算它们通过最近公共父节点或子节点的路径距离为:

其中:d(c,min f)=|s(min f)-s(c)|。min f是c1和c2最近公共父节点或子节点。由此,就可以计算出两个概念之间的语义相似度了。
1.2 相似度分析与设计思路
上述三种计算模型是通过不同的三个角度来量化概念之间的相似度。基于内容的语义相似度计算模型更具有理论说服性,它是由信息理论和概率统计理论当中的有关知识作为理论根据的。基于属性的语义相似度计算模型更符合人类对于客观世界中事物相似性识别的认知过程。但如果要做到准确识别,就必须要对客观事物的所有属性进行详细描述才可以保证结果的正确性。基于距离的语义相似度计算模型,相对比较直观,便于理解和认识,但是它首先应该是在一个完整的概念层次网络的基础上才可以发挥作用。概念层次的组织结构可以直接影响到语义的计算结果。
除了单一模型的提出,目前国内研究中还提供了一些在综合因素的考虑下建立的计算模型,如文献[2-7]中,一方面是在语义重合度、语义密度、概念属性的角度综合考虑;另一方面,另辟蹊径如从过滤无关概念的角度或语义矩阵的方式出发给出了新型的计算模型。这些都是从不同角度进行的优化。但基于本体的思想,构建相似度计算模型的本身是为了构造一个完整的领域本体之上的分析系统,紧扣语义和概念应该是最为重要和本质的要求。加入过多的因素或脱离语义本身进行的排除性算法都会脱离基于本体的这个基础概念。
针对上述分析结合不同计算模型的特点,本次项目把概念相似度放在一个层次结构进行描述,并在建模过程中,考虑结合属性及语义重合度方面的因素作为影响因子,紧扣语义本身的特性推导影响因子,建立一个全新的计算模型。
2 新型相似度计算模型
2.1 计算模型的分析与构想
系统中所有的概念都存在于本体层次网络结构当中,这是一个有着比较严谨的语义结构的体系[3]。因此,在这个结构中所处的位置可以体现出概念之间的一些关系。这个结构可以看成是一个由点和有向边构成的一个有向图。其中的有向边表示了概念间的相关性关系。
如果假设这个有向图中所有的边权值都是1,所有概念结点没有属性,那么计算任意两个概念结点之间的相似度就是计算它们之间的距离。当然现实情况并没有这么简单,概念的属性在其中也起着重要的作用,它一方面可以直观反映出概念本身的特征,另一方面两个概念的属性之间相似性越大,概念的相似度也越高。所以它也可以很好的反映概念间的相似性关系。
概念之间有向边的距离和概念属性的相似性都可以从各自的角度反映出概念相似度的情况,但是都不够完整[2]。这类问题已在文献[3-6]中有很多论证。如果在计算概念间有向边距离的同时,可以考虑到属性对最后结果的影响,那么将无疑大大增加相似度计算的精度。所以,为了得到尽量接近现实描述的相似度计算模型,就必须考虑到概念的属性对概念之间相似度的影响。另一方面文献[6]针对相似度计算也提出要考虑属性、内容重合度等方面的因素。但是对于计算模型的建立只是通过简单的调节因子之间的叠加进行。并且语义重合度与语义密度的计算有重复部分。在一个基于词汇相似度计算的模式中,加入语义密度的因子似乎没有太大的意义。
因此本项目的重点放在考虑属性相似度计算及语义重合度和有向边的相似度计算上。可以通过合理的公式推导,把属性相似度及语义内容的重合因素加入基于有向边相似度的计算模型,建立一个统一的相似度模型。通过分析发现,在计算有向边距离的时候,每条有向边都假设权值为1,其实由于关系类型不一样它们应该具有不同的权值。可以把语义内容重合度计算加入到有向边计算模型中,而概念属性之间的相似性从层次网络的角度来分析,也可以看作是对每条边权数的反映。所以,如果从层次网络结构中描述概念之间的相似度模型,可以考虑两个方面的因素,一是加权之后有向边的距离;二是概念属性的相似性转换成为边的权数。
基于上述分析,建立计算模型的基本思想是:基于加权的有向边和属性的计算模型。确定影响有向边权值的因素即属性相似性的计算,给出计算这些因素的公式。而后推导出单位有向边的距离与权值关系的计算公式。再根据任意两个结点之间有向边距离的计算公式,得出概念之间的权值从而给出概念间的相似度计算模型。
2.2 有向边计算
一般在领域本体中,概念之间的关系有:上下位关系、同义关系、反义关系、对义关系、整体与部分关系等等[8]。在实现中,本体构成的层次网络中只需要考虑三种关系即可,继承关系、整体与部分关系、同义关系。这三种关系几乎占到了概念间关系的绝大多数情况。每种关系都是概念间不同的相关程度,一般地,同义关系的有向边表示其两端的概念为同一个意思,相关度最高。部分与整体关系的相关度小于继承关系的有向边。在本体层次网络中,两个直接相连的概念结点一定是处于不同层次,因此也就是父子结点。
设任意两个相连父子结点为x和y,则有向边相关程度的计算公式,如公式(4)所示:

其中:3/4和1/4为领域专家给出的权值。该计算模型反映了有向边的相关度和其类型之间的关系,将不同的类型转换为对应的数值。
2.3 属性相似性计算
在本体的层次网络中,概念的描述是非常详细和准确的,其中也包括了属性描述。通过概念间拥有相同属性的多少,在一定程度上就可以表示结点,也就是概念之间的相似程度。相同属性越多,说明相似度越大,有向边的权值也就越大。
由此得到有向边与概念间属性关系的公式,如公式(5)所示。

其中:Attr(x)、Arrt(y)表示概念x、y的属性集合;Attr(x)∩Attr(y)表示概念x与概念y相同的属性集合;Attr(x)∪Attr(y)表示概念x与概念y所有的属性集合;cou()表示属性个数。
2.4 语义重合度计算
语义的重合度可以通过分析任意两个概念结点之间所拥有的祖先结点的个数来判断它们之间的重合度高低。显然,如果两个结点的祖先结点的个数越多,重合度就越高,如果一个都没有,说明是完全没有语义重合的两个概念。
由此得到任意两结点间的语义重合度的计算公式,如公式(6)所示。

其中:Up(x)、Up(y)表示概念结点x、y的祖先结点集合;Up(x)∩Up(y)表示概念x与概念y相同的祖先结点的集合;Up(x)∪Up(y)表示概念x与概念y所有的祖先结点的集合;cou()表示对象个数。
2.5 权值因子计算公式
通过上面的推导,已经把影响权值的因素量化并给出了公式,接下来计算有向边的权值。这部分是相似度计算模型中最核心的部分,其表达式应该为:

可以发现,当WAttr(x,y)与WNode(x,y)的值为1时,权值最大。表示两个结点是相同的概念。其他取值都小于1且无限趋近于0,当然理论上存在属性或语义完全不相交的情况,这时取值等于零。因此权值的取值范围是[0,1]。
由此给出有向边长度与权值的公式,如公式(7)所示。

其中,β为调节因子。显然当权值为1时,长度为0,表示父子结点x,y表示同一个概念。
基于2.2中的分析已经得出了有向边单位长度的计算公式。在本体层次网络中对于任意两个结点的计算公式也可以得出。这里借鉴Leacock模型中的结点距离公式来得出任意两个结点距离的计算公式。
Leacock模型中距离公式如公式(8)所示。

其中Anc(p,q)表示任意结点p、q的最近共同祖先结点。这里可以代入单位距离的公式从而建立任意结点距离与单位结点距离的关系。如公式(9)所示。

其中path(p,q)表示两个结点p,q在网络中最短的路径上所有结点的集合。
由此,可以得出本体层次网络中任意两个概念的相似度计算公式,如公式(10)所示。
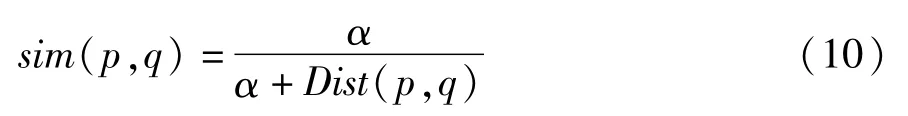
其中的α为调节因子。虽然从公式上看,这里概念的相似程度的量化似乎只和结点距离有关系,但实际上,这里距离的得出是包含了有向边相关程度,和概念间属性的相似度来作为计算依据的。因此可以较为准确的反映出任意两个概念之间的语义相关程度。
3 实际应用效果
以基于有向边和属性的计算模型作为算法核心构建的搜索引擎,已在一个实际项目上进行应用。对其基于本体的搜索引擎做了相关的性能测试。为了突出实验的对比效果,除了实现本模型外,加入Montserrat模型与传统的Leacock模型进行相同实验对象的结果比对。为方便区别,提出的相似度计算模型用ZKM模型表示。
利用Protégé本体建立工具,使用Jena API,Lucene开源工具包,Java语言作为编程语言。选取5组,共41个概念作为分析对象,实现了本项目的模型和其它两个比对模型。
实验结果得到了比较理想的数据结果,选取其中一部分进行介绍,如表1所示。
通过表1中计算的结果可以发现,本项目的相似度计算结果比其他两个计算模型计算结果的有效性有了明显提高。前四个例子分别选取的是belong-to、part of关系的概念,在计算结构中都体现了比较好的相似性。最后一组是一个特例,概念“软体”并不是本领域的专业词汇,但是在台湾的词汇体系中,软体就是软件。这里算作是一种特殊关系进行测试。由于在构建领域本体中,作为陌生词汇的“软件”本身和软件没有直接联系,但是通过追溯祖先结点和属性重合度的权值调节,在最后的计算结果中也显示了较高的相似度。从语义上,基本符合现实情况。

表1 不同相似度模型的计算结果(部分)
4 总结与展望
在本体概念架构下的搜索引擎构建中,概念相似度的分析始终是一个研究重点。相似度计算的精度会直接影响搜索的结果。目前对于相似度计算模型的优化改良算法也非常之多。通过有向图、语义、属性及过滤云服务[2-10]等方面的计算模型也层出不穷,其目的无外乎就是可以容纳更多影响语义的因素。但是在研究过程中,很容易陷入巨大的海量信息中难以自拔,一味的加入能考虑到的各种因素并不是好的解决问题的方法,最后由于边际效益递减的规律,往往会让新的计算模型反而得不到理想的计算结果。项目的研究立足于从现实相关语义的角度出发,并没有盲目追求加入很多其他的影响因素。从文献[11]中可以发现,通过统计学分析发现,并不是所有和语义相关的因素都对概念相似度有明显的影响,有些甚至会成为语义分析的干扰项。因此去掉可能成为干扰项的影响因素,加强那些真正对语义影响重大的因素是本次项目探索的主题。
当然在研究过程中也发现还有一些问题需要解决。比如领域本体的构建方式本身就可能会对将来的相似度计算模型产生结构上的影响,因此在考虑相似度计算模型的同时,还要研究领域本体构建的方式,如何可以找到最适合的相似度计算模型。不同的模型考虑的重点是存在差异性的,这也会影响到最后分析的结果。因此,下一步的分析研究,可能要在关注优化相似度计算模型的同时,考虑与领域本体构建方式上的匹配问题。
[1]张功杰.面向本体的语义相似度计算及在检索中的应用[J].计算机工程与应用,2010(5):131-133.
[2]向津.基于无关概念过滤的云服务相似推理技术研究[J].计算机应用与软件,2013(1):183-185,199.
[3]李景.本体理论在文献检索系统中的应用研究[M].北京:北京图书馆出版社,2005.
[4]刘宏哲.基于本体的语义相似度和相关度计算研究综述[J].计算机科学,2012(2):8-13.
[5]甘明鑫.一种综合加权的本体概念语义相似度计算方法[J].计算机工程与应用,2012,48(17):148-153.
[6]崔其文.改进的领域本体概念语义相似度计算方法[J].计算机应用与软件,2012(2):173-174,182.
[7]王春红.基于本体和多代理的考试系统模型研究[J].河北工业科技,2010(3):174-176.
[8]Fleischman M,Hovy E.Multi-document person name resolution[C].//Harabagiu S,Farwell D,eds.Proceedings of the Workshop on Reference Resolution and its Applications.Barcelona,Spain july 2004:1-8.
[9]Kivela A,Hyvonen E.Ontological theories for the semantic Web[M].Helsinki:HIIT Publications,2002:111-136.
[10]Rodriguez M,Egenbofer M.Derermining Semantic Similarity Among Entity Classes From Different Ontologies[J].IEEE Transactions on Knowledge and Data Engineening,2008,15(2):442-456.
[11]Alexander Maeche.Ontology learning for the semantic web[M].Norwell:Kluwer Academic Publishers,2008:15-17.
[12]武成岗,焦文品,田启家.基于本体论和多主体的信息检索服务器[J].计算机研究与发展,2001,38(6):641-647.
[13]Bray T,Paoli J,Sperberg-McQueen C M,et al,Extensible Markup Language(XML)1.0(Second Edition)[EB/OL].W3C Recommendation,http://www.w3c.org/TR/2000/TEC-xml.2007-10-06.
[14]Jianmin Yao,Ming Zhou,et al.An Automatic Evaluation Method for Localization Oriented Lexicalised EBMT System[A].In Proceeding of the 19th International Confernce on Computational Linguistics[C].(COLING2002).Taipei,200.
[15]史英杰.云数据管理系统中查询技术研究综述[J].计算机学报,2013(2):219-225.
[16]常万军.OWL本体存储技术研究[J].计算机工程与设计,2011(8):2893-2896.
Sim ilarity Model Design Based on Edge and Attribute
CUIYan,ZHANG Shu-li
(Department of Computer Information Technology,Ming De College,Northwestern Polytechnical University,Xi'an 710124,China)
Through the analysis of the calculation principle and design concept of similarity algorithm under the single condition,the concept of directed graph is described.The calculation models of the directed edge,the semantic overlap and the attribute similarity are analyzed and concluded to establish the concept similarity calculation modelwith semantic and attribute weight.Finally,the accuracy of the similarity calculation of the new model is verified by comparing with the traditional one.
Concept similarity;Directed edge;Weights of attributes;Ontology
10.3969/j.issn.1002-2279.2014.05.014
TP391
:A
:1002-2279(2014)05-0047-04
崔岩(1976-),男,河北邯郸人,硕士研究生,讲师,研究方向:数据库技术与应用。
2014-01-17
