联合贝叶斯推理与遗传算法的主题信息搜索策略
2014-08-06张小琴
张小琴
(中南民族大学 图书馆,武汉 430074)
随着大数据时代的到来,快速、准确的高性能搜索引擎是下一代互联网面临的挑战之一[1].主题信息搜索引擎专注于特定主题,更新速度快,且能够提供给用户更专业更人性化的检索结果,已成为研究的热点.在主题信息搜索系统中,搜索策略是影响系统性能的关键,常用的主题搜索策略有:基于网页链接结构的搜索策略和基于内容评价的搜索策略.其中,PageRank[2]和Hits[3]是基于链接结构的搜索策略.Fish算法[4]和Shark算法[5]是基于内容评价的搜索策略.这些搜索策略存在主题漂移现象,以及在预测网页的重要程度方面存在不足等问题.
基于此,本文在目前常用的主题爬虫Heritrix[6]框架基础上,将贝叶斯推理与遗传算法相结合改进其搜索策略.通过在搜索的初始阶段引入高质量的种子集合,搜索过程中结合Hub网页对主题的贡献,利用贝叶斯推理对于网页主题进行判断,并结合遗传算法对搜索过程进行启发式引导.在提高网页搜索质量的同时扩大搜索范围.
1 系统模型
主题信息检索从初始的URL集合开始,提取链接主题信息,判断网页是否与主题相关,如果与主题相关,就保存网页并为其构建索引.反之,则抛弃网页.系统模型如图1所示.
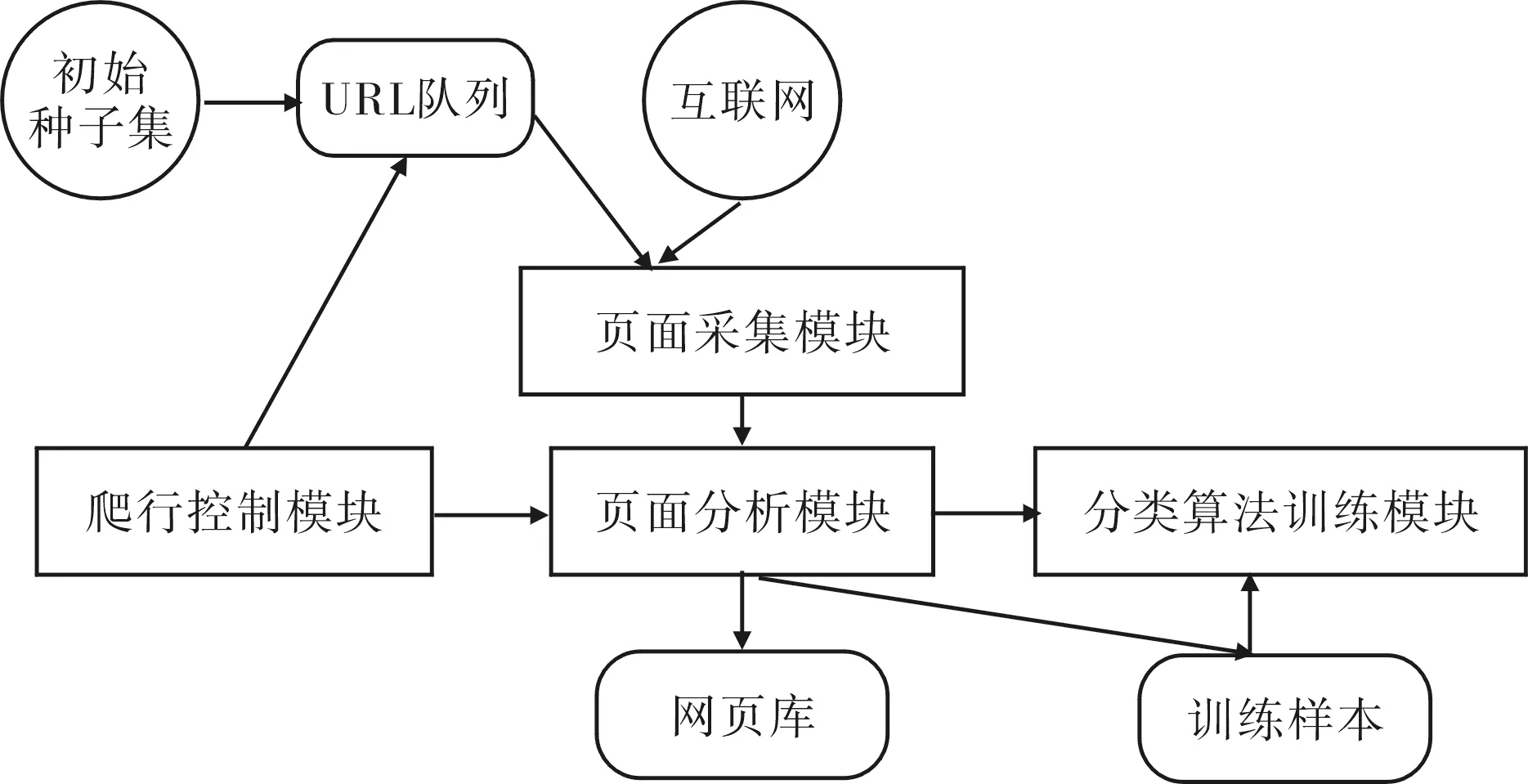
图1 系统模型Fig.1 System model
主题信息搜索过程包含以下几个步骤:(1)选择生成初始URL集合;(2)从URL集合中取出URL,并提取URL所对应的页面;(3)分析页面,提取页面所包含的所有URL链接,判断是否访问后加入URL集合中;(4)分析主题相关度,主题相关则保存页面并建立索引,反之抛弃;(5)返回步聚(2).
主题相关度的分析包括对页面的分析及特征提取,利用贝叶斯推理进行主题识别.在页面分析和特征提取过程中,提取页面中所有URL链接,并将页面用VSM(Vector Space Model)模型表示.
2 基于贝叶斯推理的主题识别
2.1 建模过程
将贝叶斯推理用于主题信息识别时,首先需要收集一些网页用作为训练数据,提取特征词属于每个类别的先验概率.然后在实现具体网页抓取任务时,根据特征词的先验概率计算出新文本属于每个类别的后验概率,作为分类识别的依据.其数学表达式为:
(1)
其中,Ci是某一类别,Dj是未知类别文本,wk是Dj中出现的单词,TF(wk)是wk在Dj中出现的次数.P(Ci)和p(wi/Ci)分别是需要从训练集中估计的先验概率.对于不同的类别,式(1)中分母相同,所以式(1)可简化为:
P(Cj/Dj)=P(Dj/Ci)P(Ci)=
(2)
建模的具体操作步骤如下:
(1)用分词器Htmlparser分解每个文档;
(2)去掉连接词;
(3)统计页面含有的词wk及其对应的词频数ωi,将每个文档映射成:{
(4)记录20个频数排序最高的词条,建立主题中心库centroid={C1,C2,…,C20}.
2.2 与主题相关性识别
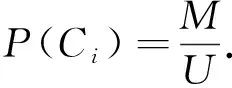

3 改进的主题信息检索算法
衡量主题信息检索算法性能指标除了识别精度外,还应考虑识别误差在实例空间中的分布程度,即差异度.在此基础上,本文将贝叶斯推理与遗传算法相结合,利用遗传算法的全局最优特点保证搜索的整体性.将遗传算法应用到主题信息搜索系统中进行查找链接,在查找过程中不断选择变异优化,对搜索过程进行启发式引导[7].
在遗传算法中,利用适应度来度量群体中每个个体在优化计算中可能达到或接近于找到最优解的优良程度.而适应度函数是用来评估个体的适应度,即区分群体中个体好坏的标准.为此,本文将适应度函数定义为:
(3)
式(3)中,Pr为查准率、Pa为查全率,λ为决定差异度影响的系数.
具体算法描述为:将搜索空间中的每个元素用一个染色体表示, 用(3)式定义的适应度函数刻画不同染色体对于环境的适应性.在算法的具体操作过程中,把待搜索的页面集看作遗传因子,首先初始化种子集合,通过爬虫抓取到第一代的群体网页,先形成初始种群Population,在每一代, 通过搜索, 即对每个染色体用适应度函数进行评价, 找到种群中适应度较高的个体.经过一代又一代染色体的交叉、变异,可以搜索到多个局部极值,最终找到全局优解.
4 实验及分析
在Heritrix框架上,通过扩展Extractor类和Frontier类,实现改进的搜索策略.实现过程为:由Extractor类分析页面内容,该类主要通过实现innerProcessor方法,这个方法大部分代码都是用于处理在解析过程中发生的各种异常和日志的写入.对Frontier类中的两个保存队列上一层的Queue和下一层的Queue进行改写操作.对Frontier中的核心函数next()和schedule()进行重写,添加遗传算法的选择、交叉和变异函数的操作.在实现过程中,next()完成从父队列中抽取下一代待抓取的URI,若父队列的抓取完成,进行交叉和变异产生新的种子集合.schedule()则主要完成选择算子的工作,进行URI去重,如果未访问过,将其加入队列中.
用户和搜索引擎系统之间通过Internet进行交互,Heritrix爬虫从互联网上抓取数据,获取到的原始数据经过Htmlparser工具包处理,过滤掉网络标签等信息得到文本内容,经过Lucene索引框架对内容建立索引,建立数据库.通过Java语言开发前段用户接口界面,将制作好的Web页面放在Tomcat应用服务器上,用户通过Internet访问Tomcat上的页面,服务器和数据库交互之后反馈搜索结果.选取了国内5个知名度和访问流量比较高的网站作为测试对象.在Seeds表中输入http://www.sina.com.cn/、http://www.sohu.com/、http://www.163.com/、http://www.qq.com/ 、http://www.xinhuanet.com/五大门户网站的地址.
利用Runnable接口的类Extractor逐个对网页镜像进行分析.使用HTMLParse进行分词,它提供了Visit和Filter两种访问结点模式,本文选择Visit模式.词频统计时,使用HashMap装载需要统计的关键词,HashMap继承Map接口,可以实现数据以
选择“数字图书馆”和“大数据”作为特定的搜索主题.爬虫框架不做任何改变,保持相同的模式,对Heritrix中的Frontier进行修改.选取百度搜索到的前二十条结果作为起始的种子集合,对设定主题搜索返回的页面,统计关键词的权重.设定搜索深度为5,最大线程数设定为100,阈值设为0.01.设定遗传算法的交叉概率为0.9,变异概率为0.1.在爬虫完成抓取任务之后,对Logs选项和Reports选项进行数据分析,其中Logs选项记录了每条抓取的时间,网站返回的状态码,如200表示抓取成功,404表示请求错误.Reports表中记录了被抓取网页的分布情况,包括页面的分布概率、站点的名称等数据,对抓取的所有页面进行主题相关度分析,反复进行测试,统计抓取页面的平均值,然后分析数据.因为搜索过程是按照结点不断延伸,在Logs表中详细记录了被抓取页面的顺序,从种子集合的URL开始分析,将这些页面集合在Alexa排名中进行流量和访问量的分析.在进行性能对比中,改进前Heritrix默认为广度优先策略,通过大量实验,统计结果如表1所示.

表1 统计结果比较
搜索策略改进前后,对特定的主题关键词的页面抓取结果如图2和图3所示.
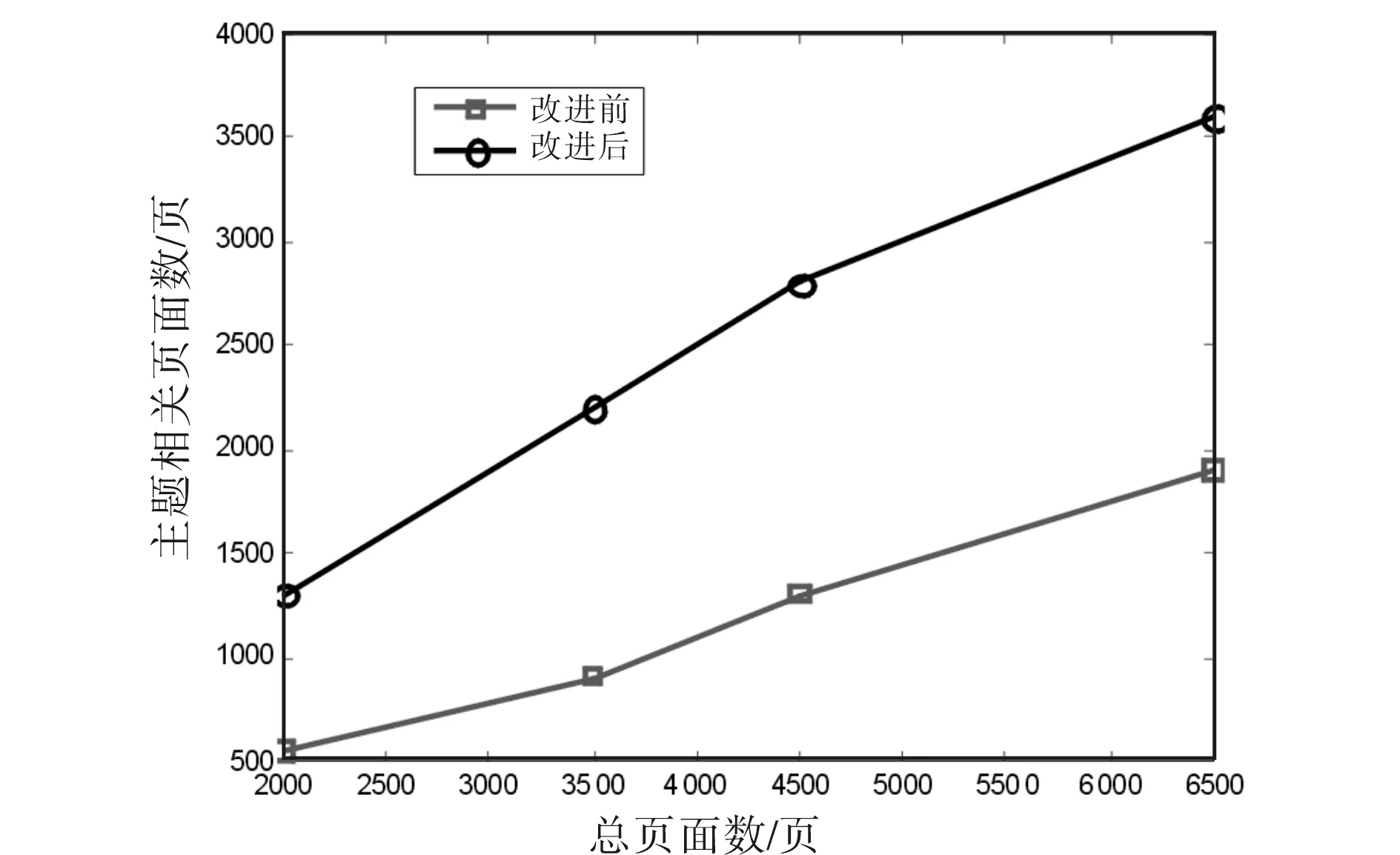
图2 主题相关页面所占比例比较Fig.2 Comparison of correlation topic page rate
从图2改进后的系统抓取页面的正确数量有了明显提高,这表示主题爬虫对对页面进行主题判断时,也抛弃了一定数量的错误链接和死链接.
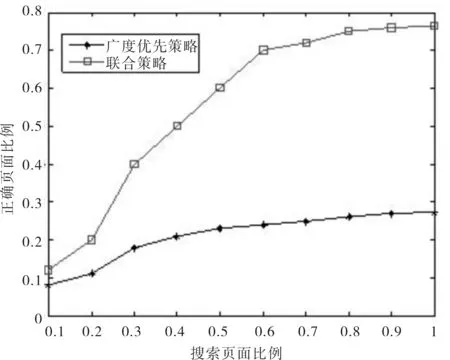
图3 不同搜索策略性能比较Fig.3 Comparison of performance of searching strategy
由图3可以看出,在不同搜索策略中,广度优先策略的性能低于本文提出的联合启发式搜索策略.联合启发式搜索策略在访问了50%的页面后,已经找到了60%以上的相关资源,表明联合启发式搜索策略具有明显的优越性.
5 结语
面对大数据时代,高性能的搜索引擎在下一代互联网中显得更加重要.本文针对主题信息搜索系统中搜索策略进行了探讨,引入联合启发式搜索策略,提高了搜索性能.实验过程中发现,爬虫在抓取的初始阶段抓取效率较高,后期由于对下一代锚链接的预测和分析不足,导致变异较大.同时在返回页面的正确率及返回页面还存在一部分死链接和链接异常的页面问题,后期还需进一步改进系统性能.
参 考 文 献
[1] Takamasa Miyano, Minoru Uehara. Proposal for cloud search engine as a service[C]//NBiS. 15th International Conference on Network-Based Information Systems. Brisbane:NBiS,2012:627-632.
[2] Brin S,Page L. The anatomy of a large-scale hyper-textual Web search engine[C]//IWWWC. Proceedings of the 7th International World Wide Web Conference. Brisbane:Elsevier Science,1998:107-117.
[3] Kleinberg J. Authoritative sources in a hyperlinked environment[J]. Journal of ACM, 1999,46(5):604-632.
[4] DeBra P M E. The Fish-Search Navigation Algorithm[EB/OL].[2014-03-16]. http://www is win.tue.nl/~debra/tut/blue/fishal.html.
[5] M Hersovici Jacovi, Y S Maarek. The shark-search algorithm-An application: Tailored Web site mapping[C]//ACMP.Proceeding of the 7th International World-wide Web Conference. Brisbane:ACMP,1998:317-326.
[6] Chen Jianxia, Wu Wei, Wang Chunzhi. A mobile phone information search engine based on Heritrix and Lucene[C]// ICCSE. The 7th International Conference on Computer Science & Education. Melbourne: IEEE, 2012:1602-1604.
[7] Chih-Chin Lai, Ying-Chuan Chen. A user-oriented image retrieval system based on interactive genetic algorithm[J]. IEEE Transactions on Instrumentation and Measurement, 2011, 60(10):3318-3325.
