基于NetFlow的特征感知自适应的流采样方法
2014-08-05刘晨光刘伟辉燕丽艳
刘晨光,刘伟辉,燕丽艳
1.江苏师范大学 信息网络中心,江苏 徐州 221116
2.江苏师范大学 图书馆,江苏 徐州 221116
基于NetFlow的特征感知自适应的流采样方法
刘晨光1,刘伟辉2,燕丽艳1
1.江苏师范大学 信息网络中心,江苏 徐州 221116
2.江苏师范大学 图书馆,江苏 徐州 221116
1 概述
在网络监控和异常检测中,经常使用采样来处理大量的网络流。已有的很多采样方法,主要是优化、保留较低层次的参数,如流量值的大小或数据包的数量。然而,使用采样获得的数据进行更高级的分析,如网络行为分析,就会出现很多问题,因为采样会严重损坏异常检测及分析算法的有效性[1]。这些算法大多是基于模式识别和统计分析的,流量特征的失真破坏了它们关于流量特征的假设,显著增加了这些方法的误差程度。
通过分析NetFlow/IPFIX的流采样信息,提出一个理想的采样模型,利用此模型可以分析采样对于异常检测在信息处理中的影响;提出了后期采样的概念,它可以显著改善采样方法的性能;然后提出了特征感知的自适应采样方法,它优化了采样算法的行为,文章最后描述了实验结果的评价。
2 采样技术介绍
网络监控常用的采样技术通常分为包采样和流采样。基于包的采样技术工作在数据包的级别,每个数据包被随机采样,随机概率取决于所使用的采样方法。主要优点是,减少路由器内存和CPU资源的消耗,提高监控高速网络的可能性。
流采样的情况下,被监控的流量汇集成一条网络流,采样本身不再是数据包,而是整个流的一部分。主要优点是比数据包采样更准确[2],但它会消耗更多的内存和CPU资源。
尽管包采样很容易实施,但它会带来显著的统计误差[2-3],包采样的典型应用包括以计划和管理为目的研究[4-5]。关于包采样的更深入研究是自适应的包采样技术[5-6]。这些技术根据当前的网络负载情况调整采样频率,可以获得更加准确的流量统计。文献[7]中描述了一种自适应非线性的采样方法,文献[8]和文献[9]提出基于流的自适应采样方法,它们都可以保留大、小流量的分布特性。
在文献[10]中提出了一种新类型的数据包采样,它改进了异常检测的质量。数据包的检测在网络中的各个地方(有路由器的位置),并对数据包做出正常或非正常的标记,非正常的数据包会以很高的概率被采样。
智能采样[2]和采样保持[11]技术可以减少内存需求,这些技术都侧重于大流量的评估。文献[12]介绍了一种包采样和流采样的组合技术,作者提出了两个阶段的采样,在第一阶段进行流采样,第二阶段从第一阶段中采样的流中进行包采样。文献[13]对流采样和智能采样也进行了详细的比较,流采样在保持流量的分布特征方面有其优点,而智能采样技术更注重在大流量采样中的应用。
有些研究不仅注重采样方法的准确性,而对异常检测效率的研究也在加强。文献[1]评估了一些采样技术是如何影响异常检测算法的性能,如随机包采样、随机流采样、智能采样和智能保持采样。研究结果证明,随机包采样具有偏差可测性并且降低了算法的有效性。
文献[14]提出了选择性流采样,优先小流量采样,明显改善了异常检测方法的效果,但这种采样技术在保留流量分布特征方面存在着偏差,仅用于特定场合的异常检测。
表1中描述了几种采样方法的适用性,可以看出大部分的采样方法适用于流量监控,可以很好地保留网络流量特征;也可以看出随机流采样在三个方面都适用;选择性采样方法仅适用于异常检测。
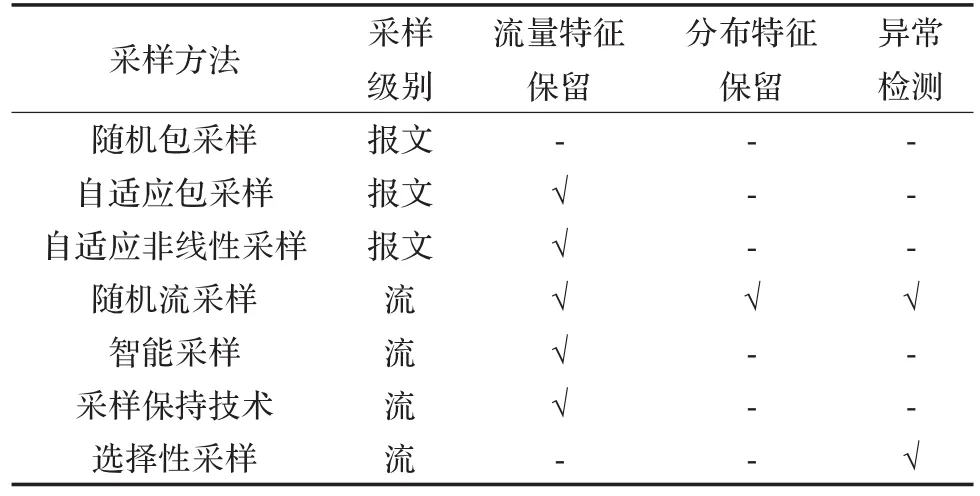
表1 采样方法的适用性
3 理想的采样模型
从网络安全的角度来看,理想的流采样过程是用来选择最相关的数据流。在这个过程中,采样结果表现出来的分布特征损失最小。多数的异常检测方法都使用数据流的统计分布特征对网络流量建模,这样可保留更多的统计特征,使得信息损失达到最小化。
假定每个流x由一组元素来确定,如IP地址、协议、流量、数据包或字节,把第k个流的特征表示为Xk,采样一个流x的概率为 p(x),采样的时刻在特征点,特征点根据特征值来计算。特征点包括以下两种:
(1)特征计数c(x|Xk):表示符合特征 Xk的数据流x的个数统计。
(2)特征熵eXk(x|Xl):表示特征 Xk的熵,这些特征与流x的特征Xl相同。
将原始有限的、未采样的数据集表示为U,已经采样的数据集表示为S。因此,cS(x|srcIP)表示流x的数量,x来自于带有相同的源IP地址的数据流采样集S。而eUsIP(x|dP)表示源IP地址的熵,这些源IP地址来自于数据集U,相应的目的端口和流x的目的端口相同。多个流的特征计数表示为c(x|X1,X2,…,Xq)。
通过使用特征点,在大多数的异常检测方法中都可以计算NetFlow流的特征。信息丢失改变了它们原有的数值,因而影响了这些特征点数据的计算。因此,理想的采样应该使这种信息丢失最小化。
定义1 S1,S2,…,Sm表示以概率 p(x)从U中选择的各个数据流集,特征点c(x|Xk)是可逆的当且仅当:
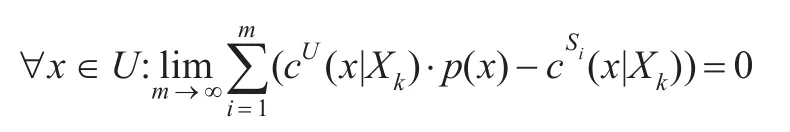
特征点可逆确保了信息丢失最小化。
把描述正常化的特征点exk(x|Xl)的相对不确定性表示为:
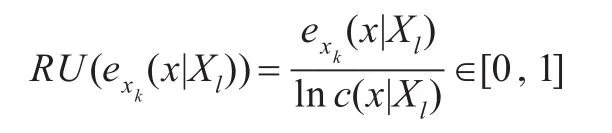
定义特征点的可逆性,是使用相对不确定的值而不是熵值,因为相对不确定的值能更好地说明特征分布。
定义2 S1,S2,…,Sm表示以概率 p(x)从U中选择的各个数据流集,特征点exk(x|Xl)是可逆的当且仅当:

定义3 Xi表示第i个流的特征,特征 Xi的特征变量ν(XiU)定义为在集U中的特征Xi不同值的数量。
定义4概率 p(x)的采样定义为以下的过程:
(1)所有的特征点都是可逆的(包括计数和熵)。
每个标准适合不同类型的异常检测方法,对基于统计和模式识别的方法来说,可逆的特征点是必不可少的;对基于知识库的方法来说,特征可变性也是必不可少的。这个过程定义了两个质量指标,适用于任何已经实施的采样方法,可以量化检测结果的质量,包括:
(1)特征描述,描述了从理想分布中得到的概率分布误差(区间[0,1]),包括:
在可逆点c(x|Xk)进行误差计算:

将用这两个指标来分析各种采样技术的特点。
4 采样算法
本章中介绍特征感知的自适应采样算法,它是采用多级处理过程的异常检测算法,这些算法可以改善采样质量,减少采样带来的误差。
4.1 后期采样
特征描述和特征覆盖两者的标准存在着一定的矛盾,改善其中的一个方面,如加强采样率,将直接对另一方面产生负面的影响。本文提出的算法通过对特征提取的划分,来避免这些标准的冲突,但需要在采样之前来完成,这样做会增加很多的计算成本,但可以大大节省后面特征提取阶段的计算成本。
目前,执行早期采样的技术是在采样之后计算特征点的统计数据,这会导致精度的不准确[14],优点是不需要处理特征点的初始化过程。
而后期采样是在系统采样之前计算特征点的统计数据,特征点是由原始的、完整的数据集计算出来的。这种采样方法对于采样技术本身以及后续的异常检测来说,能够使用原始数据集的统计信息,提高了精确度。
4.2 特征感知的自适应采样算法
特征感知的自适应采样算法基于这样的假设,在单个数据集中流的增量值随着已经存在于这个数据集中的相似流数量的增加而降低,其中,增量值由一个或多个特征值来定义。这可以缩减巨大的数据流集,对少量的小数据流也会关注。从安全的角度来看,大的和小的数据流具有同等的重要性,在异常检测时具有或大或小的影响,把最重要的特点表示为主要的特征,其余的表示为次要的特征。
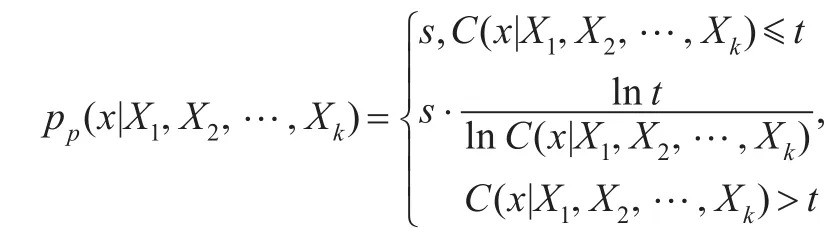
定义5X1,X2,…,Xk表示主要特征,主要概率定义为符合特征X1,X2,…,Xk的流x被选中到采样集中的概率:其中,参数s∈[0,1],表示采样率,阀值t是在分布中定义的一个点。采样技术初始设置采样率与时间大小成比例,较大的时间值,设置较低的采样率。减少在阀值以上的、具有较大时间值的攻击的采样数量,不影响异常检测的有效性,因为这些攻击很容易被检测到。而需要保持采样流的总数量没有变化时,采样率的降低则允许增加采样频率。
定义6 X1,X2,…,Xk表示主要特征,Xi表示次要特征,次要概率定义为符合特征 Xi的数据流x被选中到采样集中的概率:
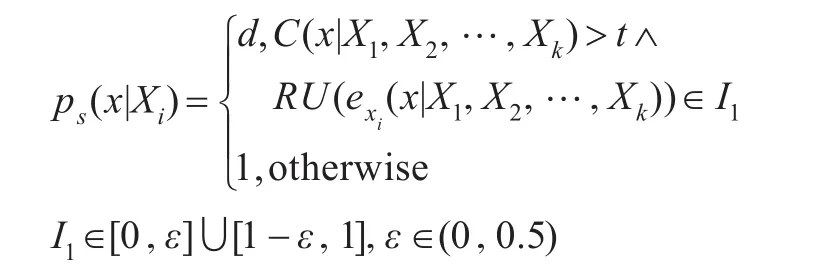
其中,参数d∈(0,1],描述了相同方向标识流(RU->0)或另一方向流的集增量信息值的降低程度,大部分的流是不同的(RU->1)。参数ε决定了间隔的大小。
定义7 X1,X2,…,Xk表示主要特征,Xk+1,Xk+2,…,Xn表示次要特征,特征感知的自适应采样选择流 x的概率是:


其中εp≥0表示由次要概率引起的采样流数量的减少,根据引用等式(2)计算的参数S保证了定理的陈述。
特征感知的自适应采样可以修改采样概率以便反映网络流量的特征分布。它根据时间值的大小选择流,目的是拟制巨大的、容易发现的事件,并且注重从小的流中获取有用的信息,而稍微改变一下这些特征分布,更有利于异常检测。特征感知的自适应采样也提出了如定理1中陈述的采样流量总和的上限,这个定理保证了采样流总和不会超过预定义的限制。
5 实验评价
采样评估的目标是在实际的网络流数据中比较各种采样算法的适用性。首先,考察采样方法在流量特征方面的影响,自适应方法的设置如下:c(x|srcIP)为主要特征,esrcPrt(x|srcIP),edstIP(x|srcIP)以及edstPrt(x|srcIP)为次要特征,d=0.8,ε=0.1,t=1 000。
直接在真实的万兆校园网络中进行攻击实验,会伤害到普通用户的网络服务,因此在独立的测试实验平台上执行一套攻击实验,然后将这些攻击插入到实际的校园流量环境中。
实验攻击分两次进行,第一次攻击是从一个攻击者的IP地址到受害者的IP地址的垂直扫描。这次攻击开始设置每5 min 250个流,逐步增长到每5 min 1百万个流;第二次攻击比较隐蔽,攻击者首先发起较大规模的DDos攻击,同时发起强度很小的、但更严重的SSH暴力攻击,以这种方式来攻击本网络上的其他用户。
5.1 保留网络特征的性能分析
通过使用前文中描述的测量方法,比较随机性的、选择性的和自适应的三种采样技术,评估它们保留网络特征的性能。对这种评估来说,使用的网络流量来自于巨大的DDos攻击和隐藏的SSH暴力攻击。
首先,评估两个被广泛应用于异常检测的指标,源IP地址c(x|srcIP)的数量以及给定源IP地址对应的目标IP地址edstIP(x|srcIP)的熵。特征值越低,特征点的可逆性越好。从表2中可以看出,随机采样技术优于其他采样技术,而选择性采样技术的可逆值相对最小,所以可逆性最好。然而,由于采用可变的采样率,使得自适应采样在熵时刻,具有最小的重构误差。
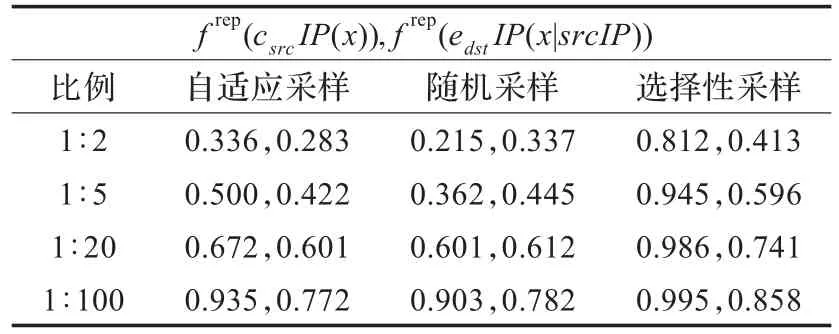
表2 源地址的数量和目标地址熵特征描述测量
其次,比较源地址和目标地址的特征覆盖情况,以便发现更好的方法来保留特征可逆性。从表3中可以看出,选择源IP地址作为主要特征,得到特征覆盖的性能参数值较大,特别是应用于自适应采样中表现得更为明显。而选择目标IP地址作为主要特征时,相对的结果要差一些。
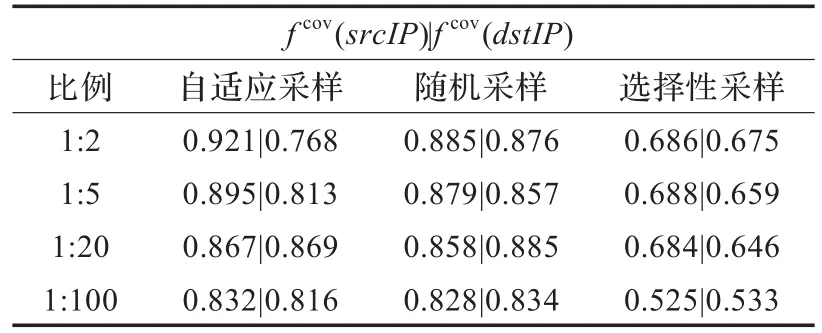
表3 源地址和目标地址特征覆盖测量
在评估中,证明了自适应采样比选择性采样具有更好的可逆性,特别是涉及到主要特征的某些值,甚至超过随机采样,这使得自适应采样在保留网络特征方面更有前途。因此,主要特征的选择对于采样后面的检测技术是非常关键的。
5.2 异常检测结果的质量分析
本节中,评估模拟攻击时的检测质量,使用的技术及数据包括:各种流采样技术;已采样和未采样部分数据;已采样和未采样原始数据集的统计信息。
具体的说,比较四种类型的采样技术,随机E、随机L、选择L和自适应L,其中大写字母E和L表示早期采样和后期采样。首先,通过网络行为异常检测设备CAMNEP[15]的测量得到了检测数据集,在此数据集中,比较了这四种采样方法的检测质量,Quality=ε-Θˉ(φj),它表示了全局阀值ε的可信度和攻击流Θˉ(φj)的平均可信度之间的差。
(1)扫描方案:首先评估关于大规模TCP扫描的采样方法
在图1中,根据已经选择的模拟攻击流的总量来比较每种方法的采样数量。扫描检测中,选择采样方法的适应性在不断增大的攻击数量时,表现得更好。自适应采样在检测较小规模扫描时的概率更高,而大规模的攻击则以较低的概率采样,结果是在所有的采样流中,对小事件的检测并没有减小。
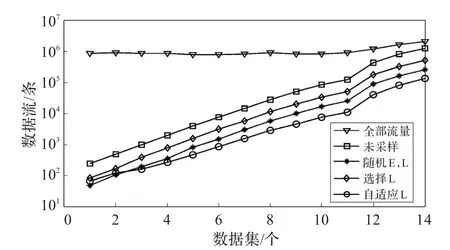
图1 TCP扫描(采样率1∶5)
图2中描绘了采样流量中模拟TCP扫描的比例,当使用选择采样时,最后的攻击规模占80%的采样数据,而使用自适应采样时,这个数据仅有40%。因此,自适应采样能很好地应对攻击流量的采样。
图3描绘了质量检测的结果,后期选择性采样、后期自适应采样和未采样的方法都成功地检测了所有规模的攻击。相反,后期随机的、尤其是早期的随机检测没有检测到第一波较小规模的攻击。
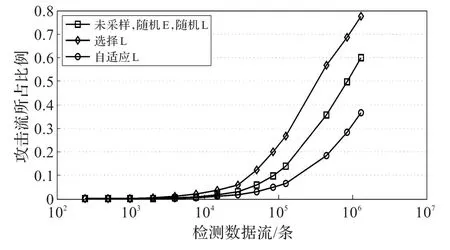
图2 TCP扫描(采样率1∶5)
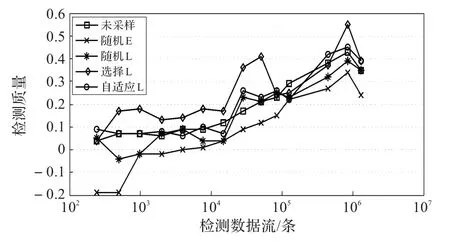
图3 TCP扫描(采样率1∶5)
(2)隐藏SSH暴力方案:本方案中包含一个大规模的DDoS攻击,它包括很多小规模的SSH暴力攻击(最大500个流)。后期选择性采样,并不是专门针对这种类型攻击的采样方法,选择攻击流的数量明显少于后期随机和后期自适应方法,如图4,该图表明了在采样集中,SSH暴力攻击的比例取决于DDoS攻击规模的大小。
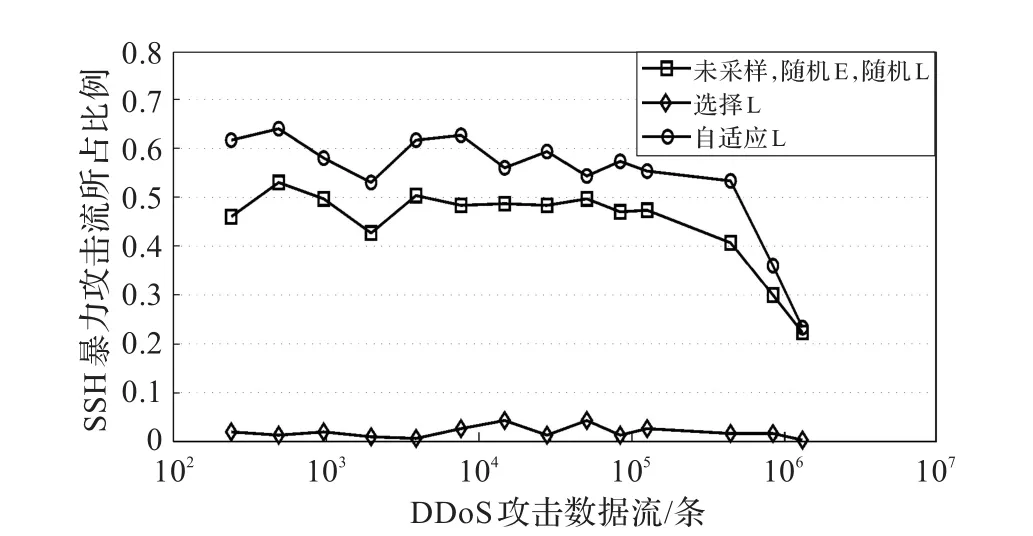
图4 SSH暴力攻击(采样率1∶5)
图5显示了初始采样率1∶5的检测质量的结果,相对较差的结果是早期随机采样技术,而通过使用后期采样技术检测攻击还是成功的,甚至比使用未采样数据的方法要好,后期自适应采样比其他技术稍好一些。
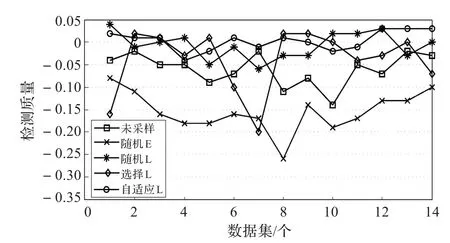
图5 SSH暴力攻击(采样率1∶5)
当把初始采样率降低到1∶100,所有的方法都变得不稳定了,如图6,后期选择采样方法只在一个数据集中选中了攻击流。所以,较低的采样率负面地影响了所有的采样技术。
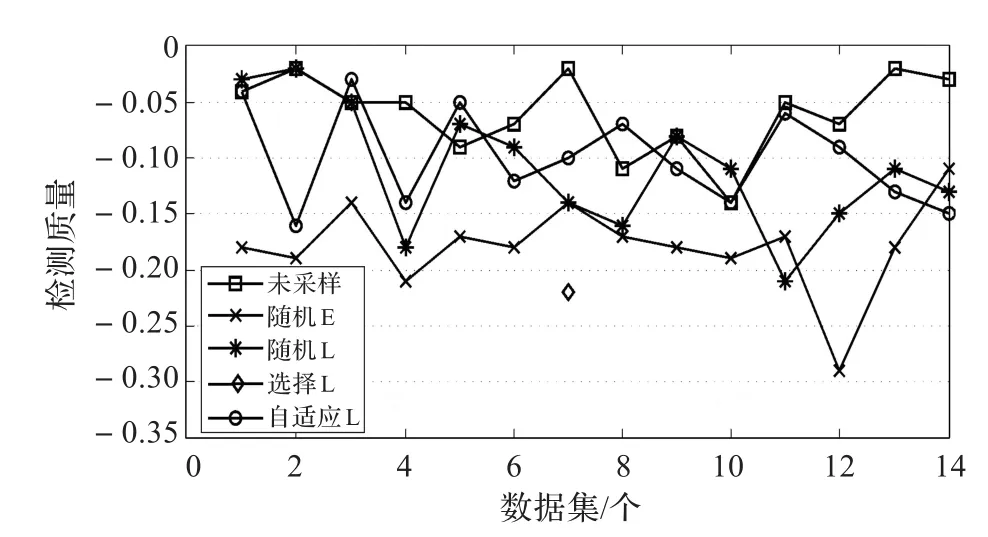
图6 SSH暴力攻击(采样率1∶100)
6 结论
本文提出了理想的采样模型和两个类型的质量指标,用来评估各类型采样算法之间的相似性,从异常检测的角度来量化检测结果的质量。其次,介绍了后期采样技术和特征感知的自适应采样方法,它提供了较为精确的、关于原始数据集的统计信息,优化了异常检测中数据的采样结果。实验表明,在保留网络特征方面,自适应采样具有更好的可逆性;在检测异常流量的效果方面,自适应采样具有更好的表现。
[1]Mai J,Chuah C N,Sridharan A,et al.Is sampled data sufficient for anomaly detection?[C]//Proc of the 6th ACM SIGCOMM Conference on Internet Measurement.New York:ACM Press,2006:165-176.
[2]Hohn N,Veitch D.Inverting sampled traffic[J].IEEE/ACM Transactions on Networking(TON),2006,14(1):68-80.
[3]Duffield N,Lund C,Thorup M.Properties and prediction of flow statistics from sampled packet streams[C]//Proc of the 2nd ACM SIGCOMM Workshop on Internet Measurement.New York:ACM Press,2002:159-171.
[4]Duffield N,Lund C,Thorup M.Estimating flow distributions from sampled flow statistics[J].IEEE/ACM Transactions on Networking(TON),2005,13(5):933-946.
[5]Estan C,Keys K,Moore D,et al.Building a better netflow[C]//Proc of the 2004 Conference on Applications,Technologies,Architectures,and Protocols for Computer Communications(SIGCOMM’04).New York:ACM Press,2004:245-256.
[6]Choi B Y,Zhang Z L.Adaptive random sampling for traffic volume measurement[J].Telecommunication Systems,2007,34(1/2):71-80.
[7]Hu C,Wang S,Tian J,et al.Accurate and efficient traffic monitoring using adaptive non-linear sampling method[C]// The27thConferenceonComputer Communications,INFOCOM 2008,Phoenix,2008:26-30.
[8]潘乔,裴昌幸.一种新的可变采样率的网络流量抽样测量方法[J].西安电子科技大学学报:自然科学版,2008,35(6):968-972.
[9]王丹,谢高岗,杨建华,等.一种改进的自适应流量采样方法[J].计算机研究与发展,2007,44(8):1339-1347.
[10]Ali S,Haq I U,Rizvi S,et al.On mitigating samplinginduced accuracy loss in traffic anomaly detection systems[J].ACM SIGCOMM Computer Communication Review,2010,40(3):4-16.
[11]Estan C,Varghese G.New directions in traffic measurement and accounting[J].ACM SIGCOMM Computer Communication Review,2002,32:323-336.
[12]Yang L,Michailidis G.Sampled based estimation of network traffic flow characteristics[C]//The 26th IEEE International Conference on Computer Communications,INFOCOM 2007,Alaska,2007:1775-1783.
[13]Duffield N.Sampling for passive internet measurement:a review[J].Statistical Science,2004,19:472-498.
[14]Androulidakis G,Papavassiliou S.Improving network anomaly detection via selective flow-based sampling[J]. IET Communications,2008,2(3):399-409.
[15]Rehak M,Pechoucek M,Bartos K,et al.CAMNEP:an intrusion detection system for high-speed networks[J]. Progress in Informatics and Computing,2008(5):65-74.
LIU Chenguang1,LIU Weihui2,YAN Liyan1
1.Center of Information&Network Technology,Jiangsu Normal University,Xuzhou,Jiangsu 221116,China
2.Library,Jiangsu Normal University,Xuzhou,Jiangsu 221116,China
Sampling is a major method in data acquisition in network anomaly detection.But different duration of flow, different sizes of the packet and different frequency of abnormal flow have brought about measurable negative impact on the accurate sampling.For this,this paper presents a feature perception adaptive sampling technique which can adjust the sampling rate when context is changing.Compared the adaptive sampling with the random sampling and the choice sampling,it studies the technology on retaining network feature in network behavior analysis system.The experimental result shows that the method is superior to others in retained network feature and quality assessment of anomaly detection.
anomaly detection;sampling technology;feature perception;NetFlow protocol;sampling model;sampling algorithm
采样是网络异常检测中数据采集的主要方法。而网络流的持续时间、数据包的大小、异常流量出现的频率等都在不断变化,给准确的采样带来很多负面的影响。为此,提出了特征感知的自适应采样技术,在流量特征不断变化的情况下可以自动调整采样率,并将它和随机采样技术、选择采样技术进行比较,研究了这些采样技术在网络行为分析系统中保留网络特征的能力,实验结果表明此方法在保留网络特征和异常检测质量评估中,明显优于其他方法。
异常检测;采样技术;特征感知;NetFlow协议;采样模型;采样算法
A
TP393
10.3778/j.issn.1002-8331.1212-0402
LIU Chenguang,LIU Weihui,YAN Liyan.Feature perception adaptive flow sampling method based on NetFlow. Computer Engineering and Applications,2014,50(24):104-108.
江苏师范大学校自然科学基金资助项目(No.10XLB20)。
刘晨光(1978—),男,工程师,主研方向:网络安全;刘伟辉,讲师;燕丽艳,实验师。E-mail:liucg@jsnu.edu.cn
2013-01-04
2013-02-28
1002-8331(2014)24-0104-05
CNKI网络优先出版:2013-03-26,http∶//www.cnki.net/kcms/detail/11.2127.TP.20130326.1042.019.html
