碎纸片拼接复原的灰度匹配技术研究
2014-07-12王文博易继荣
谢 行 王文博 易继荣
碎纸片拼接复原的灰度匹配技术研究
谢 行1王文博2易继荣3
(1.哈尔滨工程大学 船舶工程学院,哈尔滨 150001;2.哈尔滨工程大学 水声工程学院,哈尔滨 150001;3.哈尔滨工程大学 理学院,哈尔滨 150001)
鉴于破碎的文献资料在诸多领域里有着广泛的应用,本文通过对两种主要而又典型的破碎文献资料——纵向(横向)破碎、纵横向破碎的文献资料的拼接与复原问题进行分析,根据破碎纸张的大小,文字的间距等信息建立灰度匹配模型和边缘检测模型,并通过相关的算法,编写Matlab程序来解决碎纸片拼接复原问题。
灰度匹配;边缘检测;碎纸拼接;Matlab
破碎文献资料的复原在当今社会诸多领域有着重要作用,传统意义上的拼接复原方法由于低效高耗等缺点对于当今社会而言已不是最佳选择。超多的破碎文件的碎片、人们对于高效率的追求、计算机图像处理技术的迅速发展都呼唤着新的拼接复原方法的出现。考虑到对于文字资料(即使是纯粹的黑白版的),其图像是具有一定的数字或数量特征的,例如像素值、强度曲线、等值曲线等,通过对这些数学特征的分析,可以提供文字资料拼接与复原的依据,因而总体上可以采用图像处理的相关理论及分析与处理方法予以解决。
1 模型的建立
基于当代图像处理技术的相关理论,对于破碎的文字资料可以通过将其做成电子资料,进而借助图像处理软件如Matlab得到表征图像特征的数量特征例如像素值、强度曲线、轮廓曲线等,这样就可以以其中的某些数量特征来作为匹配的条件对破碎的文字资料进行匹配,建立灰度匹配模型。
1.1 灰度匹配模型的建立
对于任意第i块碎片,通过Matlab图像处理工具得到其灰度矩阵[1]:
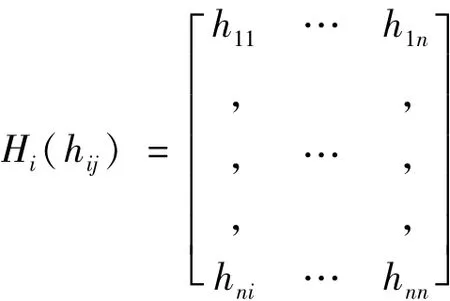
对于任意纵横切割的文字资料碎片,均存在四个切割边缘特征函数分别对应上下左右四个切割边缘,这里以式(1)-(4)成立:

对于任意两块碎片,当其以任意方式匹配时,这里不妨以第i块碎片的左边缘与第j块碎片的右边缘匹配,则其距离函数为:

规范化并且化简,同时按“1”为完全相似,“0”为完全不相似来确定匹配的正确性,那么可以以(6)式描述:

其中n为灰度级数,sik,sjk均为非负。由上分析知若Sim靠近1,则说明两碎片拼接情况较好,否则不好。
而考虑到所谓的“噪声”的影响[2],我们在此采用一个阈值加以控制,此阈值可根据灰度数以及实验的结果进行调整,我们在此取为α。
同时考虑到对任意边缘上不同的灰度级的重要性活优先级是不同的,因而我们采用权重因子Wi( 0≤Wi≤1),i的取值为1、2、3、…、n,从而(6)式转化为:
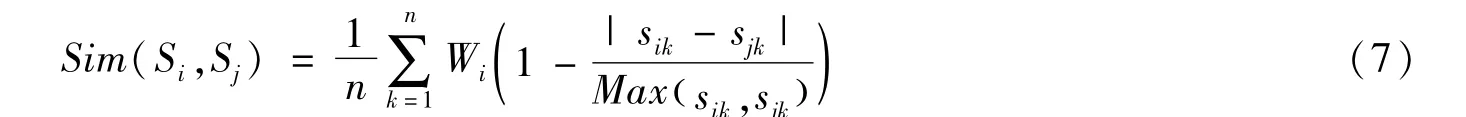
然而由于Wi(0≤Wi≤1),导致Sim(的下降,没有反应出重要成分的地位,为此我们将(7)式调整为(8)式:
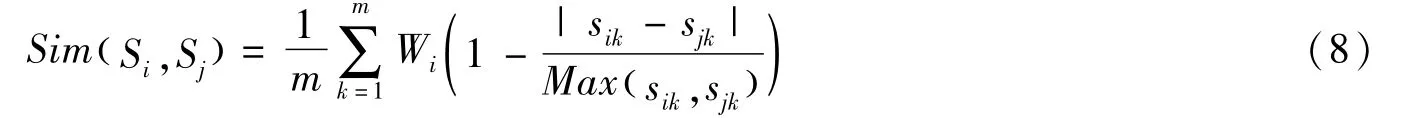
即从n个颜色级中选取m个最大的单元值进行求和平均。由此公式,结合相似性方法,可确定重要特征或特征的组合,最终实现碎片的拼接与复原[3-4]。
1.2 文字行高与行间距匹配模型的建立
拼接碎片前,先对图像进行二值化处理,不妨借助Sobel梯度算子或其他算子[5]对碎片进行处理以获取文字边界,进而获取碎片内文字行方向、高度、行间距等文字行特征,同时以特殊标志标记大于给定阈值的点和不大于阈值的点。
拼接碎片时先将两个碎片按文字行方向线位置对齐,然后计算文字行方向线或表格线与碎片边界的交点与处于同一水平位置的另一个碎片交点的距离,见图1,分别计算点A、B、C、D、E与另一个碎片边界对应交点的距离。计算两点距离时所采用的点坐标可用局部坐标,即取碎片内某固定点作为参考点,其他点的坐标取对该点的相对坐标。如果两碎片在拼接位置对齐,则点A、B、C、D与对方交点距离相等,拼接后与对方对应点变为同一点。如果碎片没有对齐,则距离相等的连续点的个数比对齐位置的距离相等连续点的个数要少,见图2上下部分,其中的水平线为参考水平线,垂直线段表示文字行方向线,图2下部分中距离相等的连续点的个数比图2上部分中距离相等的连续点的个数少,表明图2上部分的对齐位置比图2下部分对齐位置更符合实际拼接位置[6]。
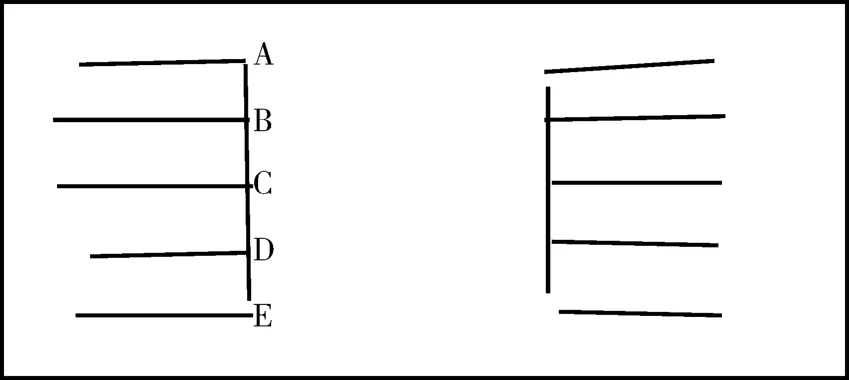
图1 对齐碎片边界交点距离

图2 不同对齐位置碎片
2 模型的求解
本文以纵向和纵横向碎片为例进行分析求解,对模型的正确性及合理性进行验证。
2.1 纵向(横向)碎纸的拼接
对于纵(横)向碎纸的拼接,本文选取编号000,001,…,018的19个纵向碎纸片作为拼接材料。本文先通过Matlab生成灰度矩阵,取每个矩阵的第一列和最后一列作为其特征属性,再找出最左边的纸片作为拼接的起点,通过相应的灰度算法找出匹配最好的一列,与拼接起点的纸片相连接,最后再将被匹配的纸片作为拼接的起点,进行匹配,如此循环直至匹配完成。
依据Matlab寻找给定碎片中从左向右匹配的初始生成碎片的程序运行得到如下结果中只有008编号的数据列有全为255的一列(即白边)。事实上对于给定的碎片,发现除去碎片序列008其余所有的碎片均有双边切割的痕迹且序列008只有右单侧的切割痕迹,故而容易得到其最左边碎片的序列号为008。
通过Matlab的图形处理工具易得到所有19条碎片的左右两侧边缘灰度矩阵共38个。结合灰度矩阵以及最初生成碎片,我们可以开始进行匹配计算,比较上述结果发现序列008与序列014的距离函数值最小,故而此二者为正确的拼接方式,即序列008为初始生成碎片,序列014是第二号。同理可以得到其后正确的序列号排序应当为012,015,003,010,002,016,001,004,005,009,013,018,011,007,017,000,006。经过拼接合成,可以看到对于纵(横)向碎纸,该方法准确率达到100%。
2.2 纵横向碎纸的拼接
对于纵横向碎纸的拼接,本文选取纵向为19列横向为11行的编号从1到209的碎纸片作为拼接材料。本文先通过Matlab生成灰度矩阵,取每个纵向碎纸片的灰度矩阵的第一列和最后一列作为其特征属性,设碎片像素高度为L,每一行的像素宽度保存在数组pntCnt(k)(k=1,2,3,…,L)内,每行的行间距保存在数组blankCnt(k)(k=1,2,…,L)中,总的图像文字个数设为CharSum,文字行高和变量为Char-Height,令其初值为0,则文字图像个数与文字行高和可按图3中算法求解[7]。
通过以上算法,借助Matlab程序得到按文字的行高行间距匹配模型求解,实际情况下在匹配的同时仍然剩余未匹配的碎片,但此处先不考虑这些单个碎片。在上述求得的多条一次级行带中,再对每一行带在带内采用灰度匹配模型进行求解.同样得到在此第二次级的匹配中无法满足条件的碎片35,67,98,136,147,183,201,203,但此时先不考虑它。对这些满足正确排序的条带采用颜色(灰度)模型中纵向匹配的方式予以匹配。通过合成统计,拼接正确的有189,无正确拼接的有20,准确率达到了94.5%。到此为了正确拼接的拼接可以采用人工的方法将其补入所得图片中,即可得到结果如表1所示:

图3 算法流程图

表1 纵横自碎纸拼接结果计表
3 结语
颜色(灰度)匹配模型对于快速匹配的图像的取得较好的结果,能够准确的将碎纸片进行拼接复原,文字行高行间距模型并不依赖于碎片的几何特征,具有实现简单,可靠性好等特点[8]。实际问题求解中,发现当碎片总数小于400时,计算量都是在可接受范围内,可以对算法改进来简化计算量。当然模型也存在不足,例如说一旦存在诸多灰度值极为接近的情况,此法的效用会因此受到影响,因为此时存在多个碎片Sk,Sj,Sl等同时与Si的欧式距离相近甚至相等即

此时我们无法判定与Si最接近的碎片即失效,但是总体上来看,此方法有一定的优越性。对于文字行高进行匹配时,不能达到完全的自动化,需要适当的进行人工干预,人工干预的频数的减少将有待继续研究。
[1] 周孝宽,曹晓光,等.实用微机图像处理[M].北京:北航出版社,1995:37-45.
[2] 丁慧珍,周绍光,马文.一种改进的灰度匹配新算法[J].资源环境与工程,2006(1):52-55.
[3] 高进乐,康耀红,伍小芹.基于颜色特征图像检索方法的研究[J].信息技术,2008(11):4-7.
[4] 舒付祥,孙继银.一种基于灰度特征的图象匹配算法设计与研究[J].计算机工程与应用,2002(9):5-7.
[5] 吴小艳,王维庆,杨春祥,等.几种基于模板匹配法的数字图像识别算法分析[J].计量技术,2005(6):27-30.
[6] 胡晓峰,刘毅.基于内容检索的颜色特征匹配方法[J].小型微型计算机系统,1996(17):6-11.
[7] 罗钟铉,刘成明.灰度图像匹配的快速算法[J].计算机辅助设计与图形学学报,2005(5):966-977.
[8] 张素,苏和,陆雪松,等.基于形状匹配的快速图像配准[J].天津大学学报,2008(4):433-438.
Research on Gray Matching Technology ofScrap Paper Restoration Recovery
XIE Hang1WANG Wen-bo2YI Ji-rong3
(1.College of Shipbuilding Engineering,Harbin Engineering University,Harbin 150001,China;2.College of Underwater Acoustic Engineering,Harbin Engineering University,Harbin 150001,China;3.College of Science,Harbin Engineering University,Harbin 150001,China)
Since the broken of the literature has been widely used in many fields,this article uses two main and typical broken literatures,namely,vertical and horizontal broken literatures,analyzing the joining together of literature and recovery problem. According to the size of the broken paper,text information such as the spacing,the gray matching model and edge detection model is established,and through the relevant algorithm,We write thematlab program to solve the scraps of paper splicing recovery problem.
splicing graymatching;edge detection;shredding;Matlab
O13
A
1009—0312(2014)03—0021—04
2014-03-14
谢行(1992—),男,河南驻马店人,硕士研究生,主要从事现代船舶设计方法和水动力研究。
