一种面向中文依赖语法的观点挖掘模型
2014-07-09胡金凤王正友
李 毅,胡金凤,王正友
(石家庄铁道大学 信息科学与技术学院,河北 石家庄 050043)
随着网络技术的快速发展,促使人们在网上接收并且分享各种信息,由此产生了大量的评论文本。这些丰富的观点评论是知识的可靠来源,不仅可以帮助用户做出更好的判断还可以帮助商品生产商及时跟踪了解顾客的喜好,并可预知经济机会和风险。对于这些非结构化数据的提取称之为观点挖掘或情感分析,处理分析人们对不同品牌、公司、产品甚至个体的观点,情感,态度和情绪[1-2]。DAVE在2003年WWW会议发表的论文中首先提出观点挖掘这一术语[3],观点挖掘对搜索到结果集合处理,生成产品属性(如:质量、特征等)列表,整合观点的情感倾向(正向,中立,负向)。观点挖掘被市场营销、客户服务、金融市场预测等行业广泛应用。
中文文本结构与英文有很大不同,在书写形式和句子结构等方面都很不同。首先,中文句子中字符串是连续的,除了动词或介词的补语在中心词之后,大部分短语以右部为中心。影响中文句子语法分析效果的重要因素之一是在句子语法分析之前需先进行分词处理。其次,中文另一个特点是具有普遍的词性兼类和灵活的词性应用。并且中文中多数是虚词和词序的变化,没有词汇的形态变化。但中文句子中的虚词经常会因为没有实际的意思而被忽略。另外,中文与英语在长句的组成上有很大的不同。中文中有一种以单句组成的长句,单句间通过逗号等标点符号隔开。在口语化的网络环境下,这种句子很常见。因此,中文句法和语法分析更有难度和挑战。
依赖语法是Tesniere于1959年提出的一种语法理论。对于自动分析语法,依赖语法很重要的一个特点是简洁的形式、便于理解。计算机领域研究人员大都不懂语言学,语法树库需要大量人工标注,所以简单的语法体系是必需的,这使得语法树库的建立很方便。此外,依赖语法对语义关系反映更接近人的语言习惯,更有利于分析中文语句,有利于一些如属性标注、信息提取等的应用,有较好的发展前景。
1 国内外研究现状
1.1 观点挖掘
1.1.1 基于情感的观点挖掘
基于情感的观点挖掘研究和应用都较为成熟。方法主要有两种:一是传统的文本分类技术;二是运用情感词典,用各部分观点倾向的总和计算整篇文档的观点倾向,提取情感极性词语作为分类的依据。Tumey利用非监督的方法进行情感分类,提取符合某些词性序列模式的两个连续词作为特征短语,然后对所有特征短语的平均语义倾向值进行计算以用来分类。该算法对汽车类文本分类准确率较高[4]。Pang先对若干电影评论中常有的特征情感词进行人工标记,以特征词在文本中出现的频率作为分类依据,采用朴素贝叶斯、最大嫡和支持向量机分类器进行实验[5]。Dave等人下载带有情感极性的产品评论作为归纳学习的语料库,从中选出分类的特征词,经过参数平滑后,可达88%的最高准确率。
1.1.2 基于特征的观点挖掘
基于特征的观点挖掘是建立在情感分类的基础上的观点挖掘,其深入到语句级别,更具有现实的意义。
Hu假定产品属性都是名词,进行词性标注后通过关联规则算法分析高频出现的名词以作为产品属性。抽取高频属性和情感词后,在剩下的带有情感词的句子中提取名词和名词短语作为低频属性[6-7]。Li构造电影评论语句中的特征和情感词对,用WordNet和演员表提取特征和情感词列表[8]。Liu等人采用分类(即有监督)的方法提取产品属性,把语料进行人工分词后再标注属性词,通过关联规则挖掘其中的规则,提取产品属性[9-10]。
国外已经投入使用了一些相关系统。美国微软研究院的Gamon等人设计的Pulse系统,可自动挖掘网络上汽车主题的非结构化文本中包含的贬褒信息及强弱程度[11]。美国伊利诺斯大学的Liu等人设计的Opinion Observer系统能够处理分析网上用户对产品的评价。统计特定产品的每个特征的褒贬信息,综合比较并采用可视化方式显示各个特征的优缺点[12]。
综上,国外的观点挖掘在理论及实践方面的研究都较成熟。由于中文在机器语言处理中存在的一些特点和难点,使得国内的观点挖掘研究还处于摸索阶段。国内这方面的研究在近些年也取得了一些进展。如上海交通大学的姚天防等人开发了基于本体的关于汽车评论的意见挖掘系统,效果很不错[13]。
1.2 依赖语法
依赖语法体系中句子中词间的有方向的支配从属关系称为“依赖”。处于被支配地位的叫做从属者(modifier),处于支配地位的叫做支配者(govemor)。依赖句子语法结构图如图1所示。

图1 依赖句子语法结构
图1中,英文缩写的含义分别为:HED为核心词;DE为“的”字结构;ATT为定中关系;SBV为主谓关系;ADV为状中结构;CNJ为关连结构,IC为独立分句。
周明是国内较早开始研究中文依赖语法的学者,他将语句按照规则分为若干组,提取出有确定关系模式的句组,最后对整句进行依赖句法研究。罗强等人将产生式模型和SVM(Support Vector Machine,支持向量机)分类器结合,先用产生式模型进行依赖分析,然后再用SVM分类器进行训练,在哈工大树库语料上达到了不错的效果[14]。段湘煌等人提出了一种基于动作建模的汉语依赖句法分析方法,改进了英文中的决策式建模方法,在转换的CTB(Penn Chinese Treebank宾州中文树库)上进行实验,达到了88.64%的正确率[15]。
目前,许多国家的研究人员目前都在研究依赖语法体系,并把其应用到不同的语言中。中文等多种语言的依赖语法分析在2006、2007年两年的国际自然机器语言学习会议的测试中都取得了较好的结果。
2 中文依赖语法的观点挖掘模型
提出了基于中文依赖语法的观点挖掘模型,以中文依赖语法规则进行观点挖掘,以期望更好地对文本进行情感倾向分析。其模型如图2所示。
2.1 文本爬取和文本内容预处理
文本爬取是指利用计算机技术从网络中获取数据的方法,是观点挖掘的第一步。主要利用网络爬虫进行文本的爬取。预处理的方法有多种,在不同的算法和语料中的方法多样。包括文本结构化处理、分词、修剪词缀、标注词性、停用词、N元词及必要的简化替换(如以“产品名”替换“电脑”,或以“NOUN”替换“笔”)等。
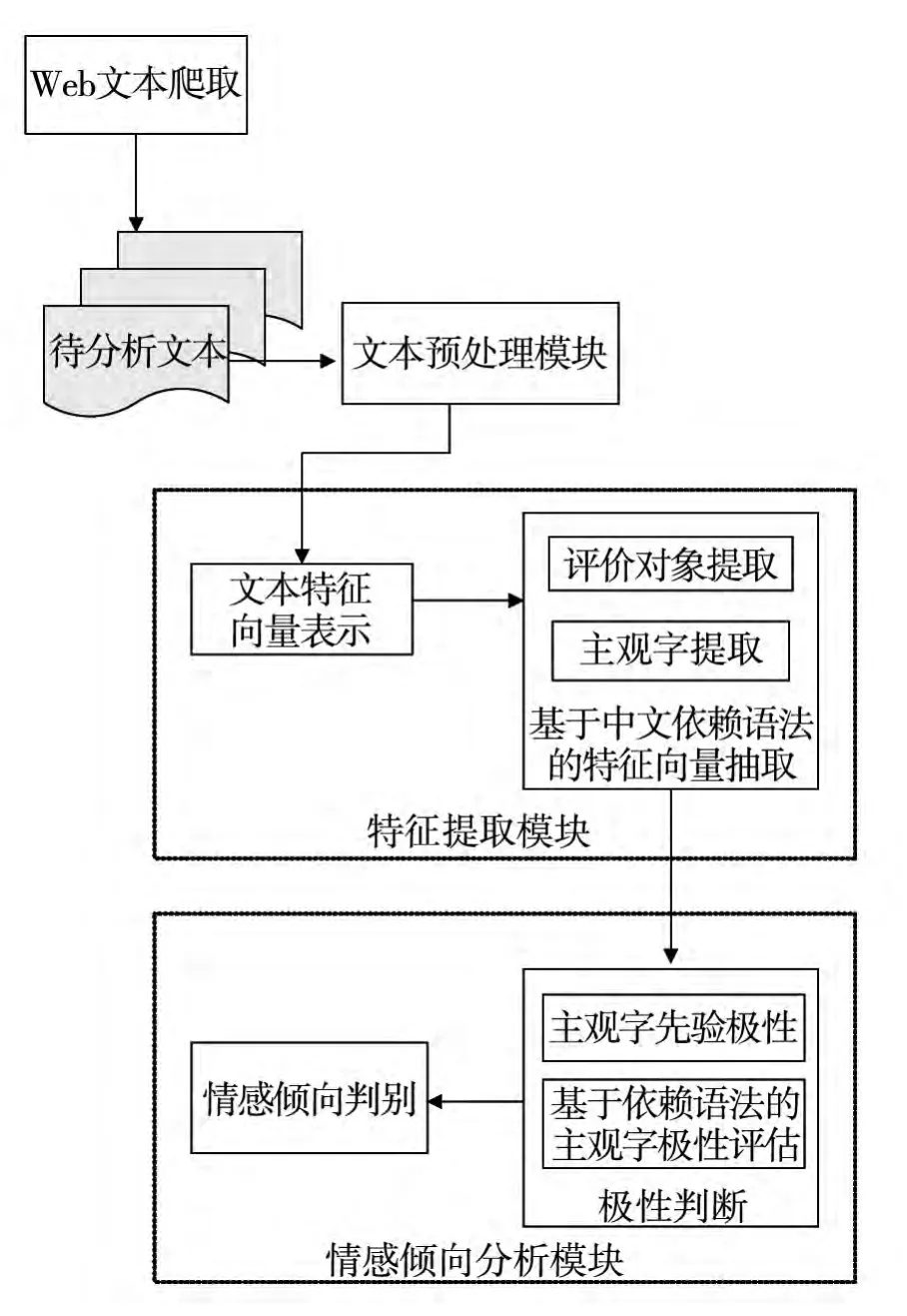
图2 基于依赖语法的观点挖掘模型
2.2 特征抽取
2.2.1 特征向量表示文本
Salton等人于20世纪70年代提出的向量空间模型(Vector Space Model,VSM)在文本表示中使用较多且效果较好。向量空间模型中每一个文本用不同权重的词频表示,每个词语轴上的值代表该词语在文本中的重要性。文本向量可由如下的集合表示:V(d)=(t1,w1,post1;…;ti,wi,posti;…;tn,wn,postn),这里ti表示词语i;wi是代表词语i在文本中重要性的值,posti表示词语ti的词性。wi=ψ(tfi)定义为ti在文本中的频率函数tfi。
TF-IDF (term frequency-inverse document frequency词频-逆文档频率)方法是向量空间模型中常用的评估词语权重的方法。下面给出词语权重的公式:
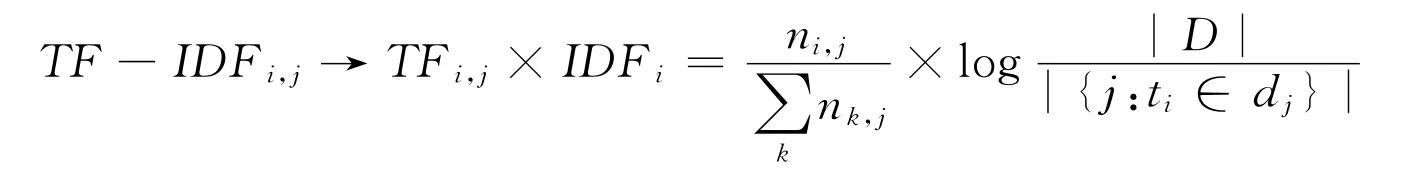
TF部分中ni,j表示该词在文件dj中的出现次数,分母部分表示在文件dj中所有字词出现的次数之和。
IDF部分中|D|表示语料库中的文件总数;|{j:ti∈dj}|表示包含词语ti的文件数目(即ni,j≠0的文件数目)。如果该词语不在语料库中,导致被除数为零,因此一般情况下会使用1+|{j:ti∈dj}|。
TF-IDF方法的目的在于突出重要单词,抑制次要单词。本质是取词语在文本中的频数TF为单词权值,再用IDF函数乘以TF以完成对权值的调整。但是IDF函数的简单结构无法很好的对权值进行调整,所以TF-IDF方法精度不高。李凡等[16]用期望交叉熵算法代替IDF函数加权,这样克服了IDF函数的缺陷,并避免了特征选择的极端性。本文也采用此种方法,在其实验中,原始的向量空间法分类精度为75%,用期望交叉熵作为权值对词频加权,分类精度将高达94%。
2.2.2 基于中文依赖语法的特征向量提取
准确识别句中的主观字是观点挖掘和情感倾向分析中首先要考虑的问题。以前的研究多数只提取句子中的形容词作为主观字,但是有些主观字也常常是动词,比如:“我讨厌这个电影。”句中的讨厌既是动词又是主观字。为了更好的挖掘观点,仅提取形容词为主观字会导致句子的情感倾向的错误判断。
采用中文依赖语法关系规则提取主观字的特征。中文依赖语法树中的每个节点表示一个词且词与词之间有多个二进制关系。每个二进制关系有一个父节点的词和一个子节点的词(或者修饰词)。每个词有一个且只有一个父节点,而一个词可有多个子节点。文献[17]把中文两个词之间的依赖语法关系归为8类,将其扩充为表1中的9种类型。添加了评价对象的提取思想,并对主观字提取过程作了一些改进。
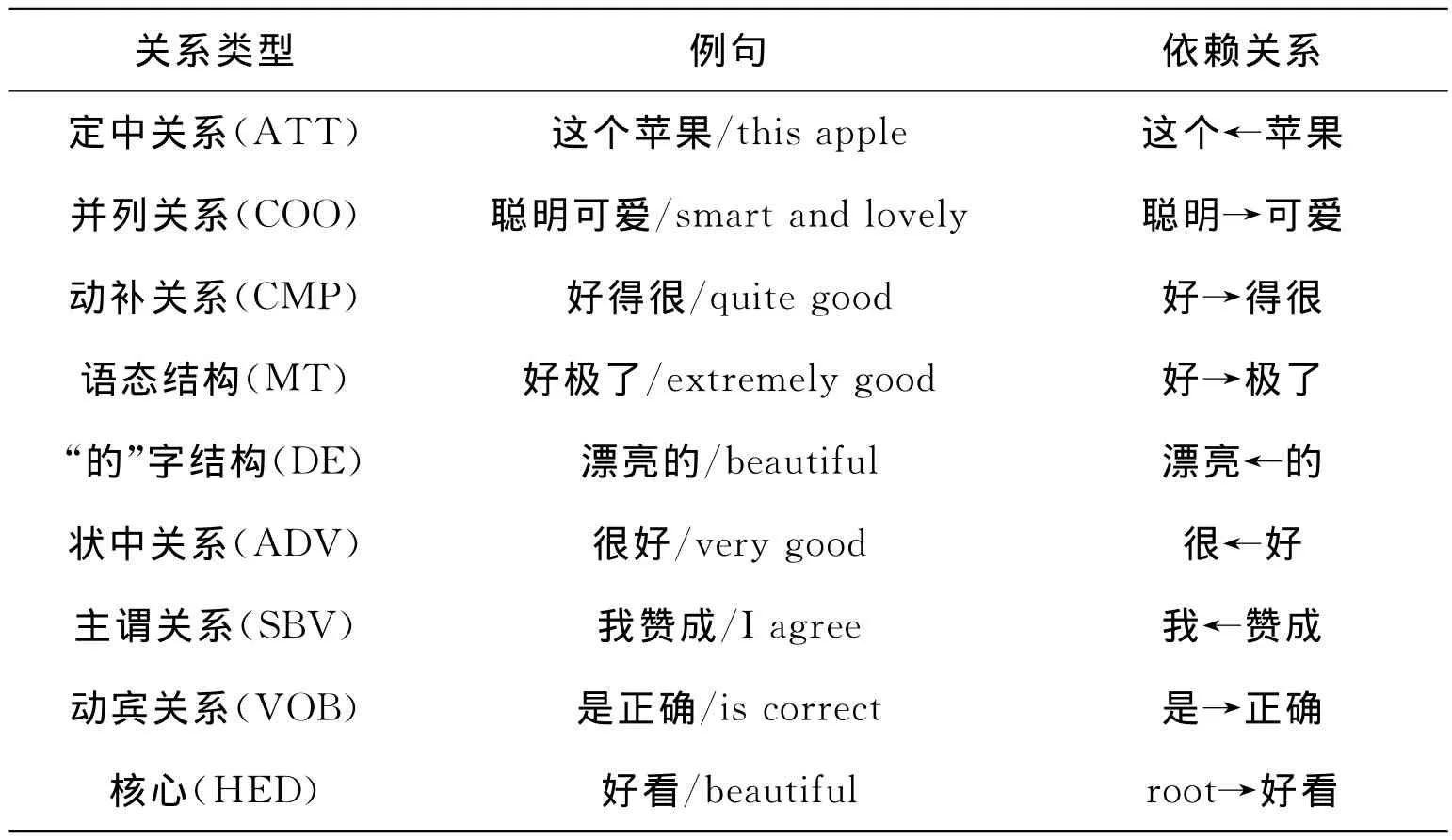
表1 中文语法依赖关系表
情感词描述的评价对象提取的算法思想:
(1)若情感词是依赖关系SBV(主谓关系)或VOB(动宾关系)的支配词,则判断相应关系对中的从属词词性是否为名词、代词或动词,若是则将其作为评价对象;
(2)若情感词是依赖关系ATT(定中关系)、CMP(动补关系)或者ADV(状中关系)的从属词,则根据其支配词的词性判断其是否为评价对象;
(3)若情感词是依赖关系DE(“的”字结构)的从属词,则判断其向后链接中是否存在ATT关系,根据ATT关系中支配词的词性判断是否为评价对象;
此处的评价对象可以是对象本身,也可以是对象的某一个属性,如果某一情感词没有找到对应的评价对象,则表示情感词是描述被评论对象整体的看法。
基于中文依赖语法规则的主观字抽取算法思想:
(1)若句子中的依赖关系是VOB(动宾关系)时,提取形容词或者动词为主观字;
(2)若句子中的依赖关系是COO(并列关系)或DE(“的”字结构)时,提取形容词为主观字;
(3)若句子中的依赖关系是SBV(主谓关系)时,提取动词为主观字。(4)若句子中的依赖关系是HED(核心)时,提取核心为主观字。
2.3 情感倾向分析
通常句子中的主观字的实际极性与先验极性是不总相同的。修饰词可能改变主观字的情感强度,甚至反转极性,所以主观字的修饰极性就要考虑主观字的修饰词。修饰词一般包括否定副词和程度副词,否定副词可完全反转主观字的极性而程度副词可加强或者削弱主观字的极性。为了准确分析预测情感倾向,考虑修饰词的影响是很有必要的。
2.3.1 主观字的先验极性
先验极性是主观词语的通用极性,其分为正向、中立和负向。使用知网词库(HowNet)情感字典作为判别的依据,其是一个综合的中文观点词字典。HowNet中正向观点词有3730个(如美丽等),负向观点词有3116个(如丑恶等),正向影响词836个(如喜欢等),负向影响词有1254个(如难过等)。其还包括219个程度副词(如:非常等)。可抽取一定数量的正向句子和负向句子作为实验集用来标注HowNet中主观参考字的基线频率。主观参考字的基线频率可以通过主观参考字出现的次数除以句子在正向和负向实验集合的数目计算。
2.3.2 面向中文依赖语法的主观字修饰极性评估
每个词都有其在主观词字典中定义的先验极性,需要考虑句子中的修饰词以确定主观字的极性,句子依赖树中有也可没有修饰词情感的子节点。通过了解中文句子的语言规则,面向中文依赖语法的修饰极性评估算法思想如下:
(1)若句中的依赖关系是CMP(动补关系)或 MT(语态结构),则Pmodified=Pprior×(1±δ),其中Pprior表示先验极性,Pmodified表示修饰极性,δ为调节系数。若检测到如非常,更加等较强烈的程度副词,则Pmodified=Pprior×(1+δ);若检测到如一点,稍稍等较弱的程度副词,则Pmodified=Pprior×(1-δ)。
(2)若句子中的依赖语法是ADV(状中关系)或ATT(定中关系)。由于句中既可能有程度副词又可能有否定副词,此种复杂的情况有以下五种类型:
若只包含程度副词,则参照(1);
若只包含否定副词,则Pmodified=Pprior×Nj;其中Nj是否定参数,当检测到否定词(如:不,没有等),则设置Nj为1/2。
若既包含程度副词又包含否定副词,且离观点字较近的是否定词,如“非常不好”,则Pmodified=Pprior×(1±δ)×Ne。设置Ne为-1。
若既包含程度副词又包含否定词,且离观点字较近的是程度副词,如“不非常好”,则Pmodified=Pprior×(1±δ)×1/2。
若检测到两个否定词,意味着双重否定,则Pmodified=Pprior×Ne×Ne’,其中Ne’表示第二个否定词。
文献[17]在以上算法(2)中只包含否定副词的情况下,将Nj的值设为-1,而本文将其改为1/2。不能直接取反原因是否定副词有时只是弱化语气,比如词语“不美丽”中“美丽”的原情感极性是+l,若直接取反就会变成类似“丑陋”的强烈的主观情感,事实上“不美丽”只是弱化情感倾向,把其除以2就可以了。
2.3.3 判别语句的情感倾向
一般每一句中会有若干个情感字,为得到一个全面的且准确的句子情感极性,需要考虑句子中每一个情感字的权重。这里给出预测句子情感倾向的公式。如下所示:

其中,Lwi表示情感字的长度,Lsentence表示包含情感字的句子的长度。Pwi表示情感字的修饰极性;λs表示句子的权重。可为第一句和最后一句设置更高的权值,因为一般情况下第一句和最后一句更能表达作者的观点。由于很多时候作者想要表达的真实情感往往都在转折词之后,所以若有转折词只对其后出现的情感字进行讨论。
3 结语
面向依赖语法的观点挖掘模型是通过中文依赖语法提取特征向量,提出判断主观字的先验极性和修饰极性的方法,并对抽取方法和极性判断方法作了改进,判定每个句子的情感倾向,最后评估所有的语句的感情倾向来推断全文的态度。下一步将通过实验对模型进行评估,可采用自然语言处理屮经常使用的准确率(precision)、召回率(recall)以及F-Measure值等评价方法对收集的语料库进行分析。未来该模型希望得到进一步的改进,目标是准确的识别主观字的上下文极性。
采用语法结构分析进行观点挖掘还是一个较新的课题,加上汉语本身多变的表达方式,准确的判断语义很困难。要想取得突破性进展,需要进行进一步的探索,由于其在各领域的应用前景很好,进一步的深入研究非常必要。
[1]Liu B.Sentiment analysis and opinion mining.Morgan & Claypool,San Rafael[M].USA:Association for Computing Maehinery,2012.53-56.
[2]Pang B,Lee L.Opinion Mining and Sentiment Analysis[M].Now Publishers Inc,2008.88-96.
[3]K.Dave,S.Lawrence,and D.M.Pennock.Mining the peanut gallery:Opinion extraction and sentiment classification of product reviews[C].Proc of the 12th Intl World Wide Web Conference.[S.1.]:ACM Press2003:519-528.
[4]Tumey P D,Littman M L.Measuring Praise and Criticism:Inference of Semantic Orientation from Association[J].ACM Transactions On Information System(TOIS),2003,21(4):315-346.
[5]B Pang.Lee,S Vaithyanathan.Thumbs up:Sentiment classification using Machine learning techniques[J].Proceedings of the Conference on Empirical Methods in Natural Language Proceeding Philadelphia,2002:79-86.
[6]M Hu,B Liu.Mining and summarizing customer reviews[C].Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(KDD),New York,NY,USA:ACM,2004:168-177.
[7]M Hu,B Liu.Mining Opinion Features in Customer Reviews[C].Proceedings of the 19th National Conference on Artificial Intelligence(AAAI),Menlo Park,California,USA:AAAI Press,2004:755-760.
[8]Shoushan Li,Chu-Ren Huang,and Chengqing Zong.Multi-DomainSentiment Classification with Classier Combination[J].Journal of Computer Science and Technology,26(1):25-33Jan.2011.
[9]B Liu,M Hu,J Cheng.Opinion observer:Analyzing and comparing opinions on the web[C].In Proceedings of the 14th international conference on world Wide Web,New York,NY,USA:ACM,2005:342-351.
[10]HU Min-Qing,LIU Bing.Mining and summarizing customer reviews[C].Proceedings of the 10th ACM SIGKDD Intl Conference on Knowledge Discovery and Data Mining.New York,NY,USA:ACM,2003:70-77.
[11]M.Gamon,A.Aue.S.Corston-Oliver.Mining Customer opinions from Free Text[C].Proceedings of the 6th International Symposium on Intelligent Data Analysis.Madrid,Spain:Springer,2005:121-132.
[12]JINDALN,LiuBing.Mining Comparative sentences and relations[C].proc of National Conference on Artificial Intelligence.Boston:AAAI Press.2006:101-113.
[13]姚天昉,聂青阳,李建超,等.一个用于汉语汽车评论的意见挖掘系统[C].中国中文信息学会二十五周年学术会议论文集.北京:清华大学出版社,2006:261-263.
[14]罗强,奚建清.一种结合SVM 学习的产生式依存分析方法[J].中文信息学报,2007,21(4):35-37.
[15]段湘煌,赵军,徐波.基于动作建模的中文依存句法分析[J].中文信息学报,2007,21(5):68-70.
[16]李凡,鲁明羽,陆玉昌.关于文本特征抽取新方法的研究[J].清华大学学报(自然科学版)2001,41(7):12-15.
[17]杨卉.Web文本观点挖掘及隐含情感倾向的研究[D].吉林:吉林大学.2011.12.
