基于Map Reduce计算模型的气象资料处理调优试验
2014-07-07杨润芝沈文海肖卫青胡开喜杨昕王颖田
杨润芝沈文海肖卫青胡开喜杨 昕王 颖田 伟
1)(国家气象信息中心,北京100081)2)(南京信息工程大学,南京210044)
基于Map Reduce计算模型的气象资料处理调优试验
杨润芝1)*沈文海1)肖卫青1)胡开喜1)杨 昕1)王 颖1)田 伟2)
1)(国家气象信息中心,北京100081)2)(南京信息工程大学,南京210044)
云计算技术使用分布式的计算技术实现了并行计算的计算能力和计算效率,解决了单机服务器计算能力低的问题。基于长序列历史资料所计算得出的气候标准值对于气象领域实时业务、准实时业务及科学研究中均具有重要的意义。由于长序列历史资料数据量大、运算逻辑较复杂,在传统单节点计算平台上进行整编计算耗时非常长。该文基于Hadoop分布式计算框架搭建了集群模式的云计算平台,以长序列历史资料作为源数据,基于Map Reduce计算模型实现了部分整编算法,提高计算时效。同时,由于数据源本身具有文件个数多、单个文件小等特点,对数据源存储形式及数据文件大小进行改造,分别利用SequenceFile方式及文本文件合并方式对同一种场景进行计算时效对比测试,分别测试了10个文件合并、100个文件合并两种情况,使时效性得到了更大程度的提升。
MapReduce;云计算;Hadoop;历史资料整编
引 言
近年来,随着云计算产业生态环境日益完善[1],云平台、云服务和云应用不断发展。云计算的核心思想、技术及其应用得到了很多领域和研究机构的重视。我国也迫切需要掌握和发展云计算的核心技术,推动云计算的应用[2],其灵活性、易用性、稳定性等已经逐渐被人们所肯定。气象业务具有专业化程度高,分支机构覆盖分布广、影响范围大、数据种类多、数据总量大、实时性要求强等特点。多年来,气象部门已经形成了一套相对比较完善和独立的业务体系。在气象领域现有的计算模型中,运算量大的模式运算多借助高性能服务器完成,而运算量较小或者实时性要求不高的业务或科研运算仍在单机上完成。基于云平台或Map Reduce计算模型开发的科学计算比较少,但随着云计算的日臻成熟,气象部门已经逐渐意识到依靠云计算平台和Map Reduce分布式计算模型解决目前业务和科研中的一些时效问题,并进行了一些尝试性的探索试验。Nebula项目是NASA的一个开源的云计算项目[3],Nebula可以随时为NASA科学家和工程师提供所需的数据处理计算资源,从而替代了需要额外建造数据中心所带来的昂贵代价。同时Nebula还为NASA的科学家和研究人员提供了一条简化的向外部合作伙伴和公众共享大而复杂的数据集的途径。中国气象局热带海洋气象研究所通过与深圳云计算中心的合作,可以进行高分辨模式实时运行,实现我国华南区域公里级模式快速滚动且高频次运行,生成精细预报产品,为华南地区精细预报、风能预报和强对流预报等提供支撑,并且有望更好地捕捉到飑线、雷雨大风等天气尺度小于6 km的强对流过程,对提高数值预报水平将带来很大帮助[4]。据不完全统计,以目前中国气象局各直属业务单位在国家气象信息中心托管的各业务系统为例,其基础设施中的服务器(包括CPU、内存等)的平均使用率低于30%[5]。以先进的设计理念、有效的组织形式和技术手段,尽可能提高气象部门工作效率和效益,在当前具有很好的研究意义[6]。
1 业务现状
1.1 气候资料整编
长序列历史资料在气象预报预测、气候研究、历史资料分析统计、模式预报中的使用越来越广泛。地面气候30年整编资料作为重要气候资料的一种,已在很多天气、气候、模式计算等方面使用[7-10]。我国到目前为止已完成了4次大规模气候资料整编工作,分别为1951—1980年、1961—1990年、1971—2000年、1981—2010年。
按照1981—2010年气候资料统计整编工作要求,所有统计项目及统计方法应支持任意年段(含建站—指定年)的统计处理,从而为各级气象部门提供日常气候资料服务、气候可行性论证等所需要的任意年气候资料统计加工产品。这对长序列气候资料整编工作所依托系统的可扩展性、灵活性、时效性提出了更高的要求。目前气候资料整编软件运行于Windows环境,由于运算数据总量大、算法逻辑较复杂,所以完成一次整编运算耗时较长。当运算过程中发现疑误数据时,需人工对疑误数据进行修改或参数调整,然后重新计算,因此总体累计计算耗时甚长,导致整编工作往往因计算耗时而时间延宕。传统的串行计算方法难以从根本上解决运算时效问题,经过详细分析,决定采用云计算技术Map Reduce,Hadoop等方法,对整编统计算法进行并行化处理,以提高运算时效。
1.2 云计算架构
1.2.1 任务调度模式
Map Reduce是Google云计算平台中的编程模型,是实现云计算的核心技术之一。Map Reduce计算框架是一个主-从模型的架构。它包括一个主节点(Job Tracker)和若干从节点(Task Tracker)。在集群模式下,集群中每个节点都有一个Task Tracker[11-12]。
图1是云平台任务调度模式。用户将计算任务提交到Job Tracker,然后由Job Tracker负责将任务添加到待执行任务队列中,任务执行顺序遵从先到先服务原则。Job Tracker负责将Map和Reduce的任务分配到不同的Ttask Tracker上,Task Tracker按照Job-Tracker的指令执行任务并处理Map阶段到Reduce阶段的数据转移[13]。

图1 云平台任务调度模式Fig.1 Task scheduling model on cloud computing platform
1.2.2 Map Reduce特点和运算流程
Map Reduce模型本身源自于函数式语言[14],主要通过Map-映射和Reduce-化简这两个步骤并行处理大规模的数据集。基于Map Reduce分布式处理框架,不仅能用于处理大规模数据,而且能将很多繁琐的细节隐藏起来,如自动并行化、负载均衡和灾备管理等,这样将在很大程度上简化代码开发工作;同时,Map Reduce具有较好的伸缩性,可以很好地适应平台中节点的变化。Map Reduce的不足则在于,它对于适应实时应用的需求方面,还不是十分完善,所以在Google最新的实时性很强的Caffeine搜索引擎中,己经采用实时处理Percolator系统所代替传统的 Map Reduce[15]。
在User program中实现了Map phase和Reduce phase。Map Reduce运算流程一般分为以下几个过 程[16]:① Map Reduce 首 先 根据 用 户 对 Inputsplit的定义将输入数据进行划分,然后使用fork将用户进程拷贝到集群内其他机器上。②Master根据每个Worker的空闲程度及配置的Worker个数将任务进行分配。③被分配到任务的Worker开始读取对应分片的输入数据,Map作业从输入数据中抽取出键值对,每一个键值对都作为参数传递给Map函数。④Map根据用户定义的进程进行运算,并将运算结果存储到Intermediate file中,同时告知Master。⑤Reduce Worker读取所有中间键值对,对其进行排序,将相同键的键值对聚集在一起,并完成Reduce函数运算,输出最终计算结果。

图2 Map Reduce运算流程Fig.2 Map Reduce computation processes
1.2.3 Hadoop分布式计算框架
Hadoop是Apache开源组织开发的一个分布式计算框架,其中HDFS(Hadoop Distributed File System)和Map Reduce分别是对Google File System(GFS)和Google Map Reduce的开源实现。Yahooo,Facebook,Amazon大型社交与商务类网站等均部署在Hadoop上,以管理基于大数据量的应用。作为一个分布式系统平台,Hadoop具有以下一些优势[17]:①可扩展,Hadoop可以可靠地存储和处理PB级别的数据。②经济,Hadoop将数据分布到由廉价PC机组成的集群中进行处理,这些集群可以由成千上万个节点组成。③有效,通过数据分发,Hadoop可以在不同的节点并行处理数据。这使得数据处理过程大大提速。④可靠,Hadoop自动维护一份数据的多个拷贝并自动将失败的计算任务进行重新部署。
本文所做的研究和试验均基于Hadoop搭建分布式的计算环境而开展。
2 历史资料整编设计架构
2.1 传统统计项目计算流程
传统整编软件中计算统计项目的基本流程如图3所示。以30年累年日平均气温算法为例,采用单进程顺序执行策略,主要步骤如下:①主程序依次顺序读取用户指定的文件夹(目录)下的每个A文件。当计算30年累年日平均气温时,需要依次顺序读取360(30×12)个A文件,解析每个A文件中每日4次或24次气温值,并根据相应的统计算法计算日平均气温。②将日平均气温值以数组或记录方式存储在表或文件中;每个A文件需要记录该月中每日平均气温值。③当所有30年所包含的A文件均处理完成后,主进程对所有记录的数据表或文件值中含有相同月日(366个值)的气温值进行累加,累加结果除以日数。
通过分析可以发现,主程序需要单进程处理所有30年的数据文件,并且需要创建大小为10950(365×30)的数组或记录表,并对数组或记录表按照相同月日的条件进行累加。

图3 传统整编软件计算流程Fig.3 Calculation flow chart of traditional software
2.2 云平台软件架构
Map Reduce计算模型的数据流图如图4所示,Job Tracter启动一个任务后,根据用户定义的InputSplit和Input FormatClass解析HDFS上对应目录下的数据文件,根据匹配的数据输入源分配Map任务。
每个 Map将处理结果输出为(Key,Value)键值对,Barrier将所有输出的键值对进行排序,将Key值相同的结果进行合并。Job Trackter根据键值对结果启动Reduce,最终生成用户需要的Final Key和Value。
历史资料整编的数据源为A文件,所以本文首先按照A文件的格式重写Hadoop中的FileInput-Format;以计算日平均气温为例,在任务分配时,根据FileInputFormat识别数据输入为360个A文件并创建Map任务。每个Map任务读取一个文件并进行解析,根据日平均值算法计算出历年逐日日平均气温,并将结果以(月.日,日平均气温)的格式进行输出。Barrier将所有Key值相同的结果进行合并,即可得到30年中每个月和日均相同的日平均气温。Reduce将该月、日的所有输入结果进行计算,最终得出日平均气温(图5)。

图4 MapReduce计算模型数据流Fig.4 Data flow diagram of MapReduce computation model

图5 云平台上整编计算流程Fig.5 Reorganization flowchart on cloud computing platforms
2.3 方法优化前后对比
与传统的计算方法相比,基于Map Reduce模型编写整编算法的优越性主要体现在以下几个方面:①Map Reduce计算模型是分布式的,它充分利用了多个节点的计算能力和I/O带宽,将原本集中在一台单机上依靠顺序运行的算法改为可以并行运行,使得在较短时间内最大程度利用了现有空闲资源。②Map和Reduce之间的中间结果不需要程序干预。平台本身利用Barrier层会将所有Map输出的结果进行处理,省去用户程序中对大量中间结果的存储和处理,简化用户程序逻辑。③Map Reduce计算模型下任务运行更灵活。由于计算任务本身无需对数据源范围进行框定,所以可在不修改任务界面和程序的情况下,完成对不同时间段历史资料整编值的计算。
3 测试方案与性能优化
3.1 测试目的、环境、数据与方案
3.1.1 测试目的
为验证分析Map Reduce计算模型在处理较大规模气象数据计算中对计算时效提升的特点,本文以气象领域长序列历史资料整编过程的统计运算为测试本体,设计了一整套测试方案,包括云平台集群构成、系统环境参数、并行任务、数据自身存储结构等。期望通过测试,可与传统计算模式的计算时效进行对比,同时通过修改平台本身各项参数配置以及测试数据存储形式,分析云计算平台中影响Map Reduce计算模型运算时效的各种因子,从而更好地理解Map Reduce计算模型与气象数据科学计算的特点,为后续的通用常规科学计算向云平台上的转化提供参考。
3.1.2 测试环境
因当时尚无成型的云计算平台,笔者利用闲散资源,搭建了一个由5台服务器组成的实体机云平台;同时为了测试Map Reduce计算模型在虚拟机上的运行效果,笔者在VMware虚拟环境中申请了10台虚拟主机。下文所述的所有试验和测试,均基于这两个小型云计算机平台上展开,5台实体机配置见表1。
10个虚拟主机均部署在同一台实体主机上,共享计算和存储I/O,每个虚拟主机配置相同,操作系统为SUSE11(x86_64),CPU 核数为1,内存为4 GB。
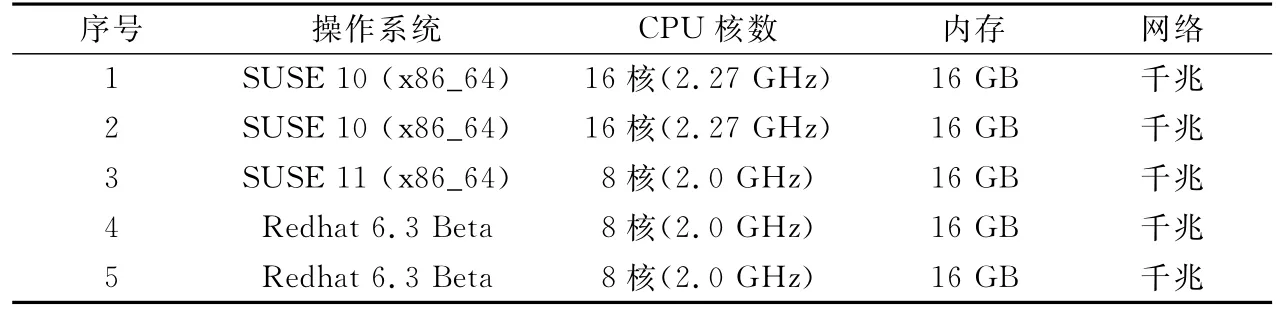
表1 实体机云平台中各主机配置表Table 1 Configuration of host machine on physical cloud platform
3.1.3 试验数据与测试方案
所有试验数据均来自1951—2010年245个气象观测站A文件,试验数据文件总数为152758个,数据总量为3350 MB,单个文件大小为5~200 KB,平均每个文件大小为22 KB。
每组试验进行两次,取两次试验结果的平均值作为该组试验的最终结果。试验从以下几个方面分别进行:①在其他配置不变的情况下,测试云平台随节点数变化对计算时效的影响;②在其他配置不变的情况下,测试云平台环境参数变化对计算时效的影响;③在其他配置不变的情况下,测试云平台随总体并行任务数变化对计算时效的影响;④在其他配置不变的情况下,测试数据本身存储结构及数据大小等方面对计算时效的影响;⑤比较和分析传统计算模型与Map Reduce模型的计算时效量级。
因为传统整编软件只能在Windows系统环境下运行,而Map Reduce运行在Linux系统环境下,所以很难在相同的系统环境下与传统计算模式进行时效性比较。为此采用变通方案,由于当实体机云平台中只配置1个计算节点时,所有计算都由该计算节点完成,因此设定1个计算节点的计算效果为传统整编软件单机环境的模拟效果。
3.2 试验结果
3.2.1 时效随计算节点变化测试
测试主要考察在数据量、计算量以及其他系统配置不变的情况下,通过改变平台计算节点数而引起的计算时效的变化。
计算全过程为1个台站日平均气温的计算,过程中需要顺序读取该站30年中每月的A文件并进行读取、计算、中间结果存储、合并汇总等。
单节点总耗时为966 s。此后,分别在云平台配置了3,4,5个计算节点,并进行同样的计算过程,3个计算节点总耗时为245 s,5个计算节点总耗时为124 s。结果见图6。

图6 时间随计算节点数变化的测试Fig.6 Experiment on time change with node numbers
由图6可看出,随着平台中计算节点数的增加,同一任务的完成墙钟时间随之降低。但随着节点数的增加,墙钟时间与节点的的斜率绝对值呈逐渐降低态势,这说明在计算节点数增加的同时,节点间通信、数据传输的时间成本也会相应增加,并抵消由于Map计算所节省的时间成本。
在配置5个计算节点的情况下,计算245个站日平均气温,总耗时25380 s。
3.2.2 时效随云平台系统参数变化测试
测试主要考察在数据量、计算量及其他系统配置不变的情况下,通过改变每个计算节点的Map Slot而引起的计算时效的变化。
在虚拟云平台中,共进行了3组试验,每组试验选取的节点数分别为6个、8个和10个。在每组测试中,通过调整 MAPRED.TASKTRACKER.MAP.TASKS.MAXIMUM参数来修改平台中最大并行任务数。试验数据选取10个台站整编数据,共计6476个文件,数据总大小为155 MB。
试验中,Map Slot从2逐渐增大到20。由图7可知,无论多少节点,3条曲线所对应的计算时间都会随Map Slot的增加呈先逐渐减少后逐渐增大的趋势;在计算节点数不变的情况下,计算时间与Map Slot之间并不是单一线性关系;当Map Slot配置固定时,计算时间随节点数的增加而降低;Map Slot为16时,10节点和8节点的两种配置下的计算时效达到整个平台的最优,Map Slot为18时,6节点下的计算时效达到整个平台的最优;Map Slot从16~18增加到18~20时,整个平台的计算时间反而升高。

图7 时间随云平台系统参数变化的测试Fig.7 Experiment on time change with system parameters of cloud computing platform
3.2.3 时效随数据存储结构和数据大小变化测试
测试主要考察当数据总量、统计方案(计算量)以及其他配置不变的情况下,通过改变整编数据本身的存储结构以及数据文件大小而引起的计算时效的变化。
在虚拟云平台中,共进行了4组试验,除第1组试验使用原始整编文件外,其余3组试验都对整编文件进行了改造。在第2组试验中,将原始的整编文件通过纯文本合并方式将每10个文件合并为1个大文件;在第3组试验中,将原始的整编文件通过纯文本合并方式将每100个文件合并为1个大文件;在第4组试验中,将全部152758个文件采用SequenceFile方式合并为1个文件(SequenceFile方式是Hadoop用来存储二进制形式的Key-Value对而设计的一种平面文件格式)。本文将245个站(152758个文件)以SequenceFile方式合并,合并后文件总量3454.6 MB。
表2中,在平台计算节点数相同的情况下,10个文件合并方式的计算时间大概缩短为原始文件方式的1/10左右;100个文件合并方式的计算时间缩短为原始文件方式的1/70左右,而所有文件合并成1个SequenceFile方式的计算时间则平均约为原始文件方式的1/200左右。Hadoop任务在运行时间主要由几个部分组成,即任务初始化时间和寻址时间、数据拷贝时间、程序执行时间、结果合并和输出时间等。如果分配的任务数量多,每个任务本身计算量不大,造成任务初始化时间和寻址时间占整体运行时间的比例过大,就会降低整体任务的运行效率;通过将大量的小任务合并为较大的任务后,减少了任务数,降低了任务初始化时间和寻址时间的比例,大大提高任务执行的效率。
在每组试验中,云平台节点分别从5逐渐增大到10。由表2和图8可以看出,3种方式在相同的环境下,计算时效均有了很大的提升;当节点数配置不变时,计算时间从高到低的分别为原始文件、10个文件合并、100个文件合并、SequenceFile方式。
图8a纵坐标是等间距的时间轴,可以看出,当存储结构变化后对处理性能的提升是非常明显的;图8b纵坐标为指数坐标,可以较清楚地看到每种存储结构下,随着节点数不同,运行时间也发生变化。

表2 不同存储结构及数据文件大小试验结果(单位:s)Table 2 Experiment results of different storage structures and data file size(unit:s)

图8 时间随云平台最大并行任务数变化的测试(a)均匀纵坐标,(b)指数纵坐标Fig.8 Experiment on time change with max parallel tasks of cloud computing platform(a)uniform ordinate,(b)index ordinate
3.2.4 文件上传到HDFS文件系统的时效测试
在以上几组试验中,假设和前提条件是数据文件已存储在HDFS系统中,所进行分析和测试的只包括Map Reduce计算模型和任务的计算时间。除上述3组测试之外,本研究在数据总量不变的情况下,文件个数和体积大小对上传到HDFS分布式文件系统的时间影响情况进行了1组测试。
试验文件在未做任务合并的情况下,文件总量为152758,上传时间为19840 s;当文件采用10个文件合并策略合并后,文件减少为15401个,上传时间减少为3218 s;当文件减少为21个时,上传时间减少为945 s(图9)。
由图9可以看出,在文件容量不变的情况下,当文件拆分得越小,上传文件到HDFS系统上的总体时间越长。
此外,随着文件数量的逐渐减少,文件上传到HDFS系统的时间优化趋势也逐渐减弱,趋于平缓。
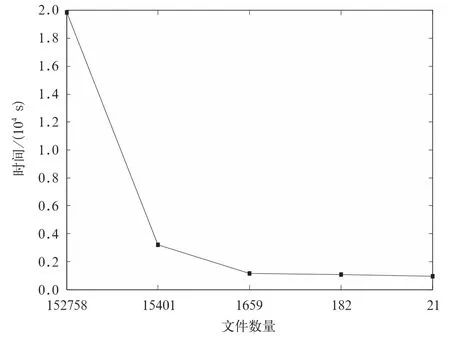
图9 文件上传到HDFS文件系统的时效测试Fig.9 Experiment on time change with upload files to HDFS
3.3 结果分析
综合以上所进行的多组试验可以看出,云计算平台的计算能力和运行时效与云平台集群构成、系统环境参数、并行任务、数据自身存储结构以及服务器性能、最大并行任务数、单个任务计算量、平台稳定性等诸多因素有关,在其他参数不变的情况下,任意两参数之间也并不是简单的线性关系。
Hadoop在任务调度时,任务初始化时间和寻址时间在任务整体运行时间的比例是决定任务时效能否提高的重要标准。由于基于传统小文件方式运行的任务初始化时间和寻址时间占总体任务的很大一部分,所以可优化空间较大。
由于单个A文件大小均在200 KB以下,且整编统计算法计算量相对较小,导致实际计算时间占整个任务执行时间比例很小,所以将大量A文件以文本方式进行合并,在文件总量不变的前提下,测试合并前与合并后的运算时效差别非常明显。采用SequenceFile方式大大减少了任务数量,使任务初始化时间和寻址时间占总体任务的比例大幅降低,任务整体运行时效得到了很大的提升。
当实体机和虚拟机个数均为5台时,在计算245个台站30年日平均气温,实体机需要25380 s,而虚拟机在最高配置下需要36720 s,计算时间为实体机环境的147%。试验结果说明在计算任务相同时,实体机环境的效率优于虚拟机环境。
4 小 结
本文基于Hadoop搭建了集群模式的云计算平台,并以长序列历史资料统计整编为例,在云计算平台上基于Map Reduce计算模型进行了多种统计项目、统计方法的算法实现,并在Hadoop平台上进行运行测试。制定了较完备的测试计划和测试方案,通过修改Hadoop集群环境的节点数、任务数等参数,分组进行运行效率的对比测试。根据测试结果以及对数据源特征的分析,对数据源存储格式进行多种方式修改和处理,一方面利用SequenceFile将<Key,Value>对序列化到文件中,将大量小容量的源文件合并为1个相对较大的文件,在同一场景的测试计算中处理效率得到了显著提升;另一方面试验了多种不同的粒度将大量小文件进行纯文本合并的方式,将合并后文件作为处理对象,对同一种场景进行计算时效对比测试,且分别在不同节点的环境下测试了10个文件合并、100个文件合并两种情况,使时效性得到了较大程度的提升。
气象领域的很多科学计算都具有数据量庞大、计算复杂、时效性要求高等特点,因此对计算资源的需求较高[18-19]。云平台的适当应用能解决现有气象业务中一部分科学计算任务面临的问题,所以探索和开展基于云计算平台的通用大数据量科学计算的适用性和可行性是有意义的。
在后续的研究与应用工作中,将进一步关注根据NP理论分析数据源、运算量、资源消耗量等特征,分析各种物理量和参数对云平台计算时效的影响因子,得到量化指标,继续开展不同的应用场景下更多气象资料处理算法及模块在Hadoop平台上的实现和移植试验。
致 谢:本项工作在分析、构思、设计、实施及总结等各阶段得到了国家气象信息中心赵立成、熊安元、肖文名、林润生、马强等专家的指点,在此深表谢意。
[1] 郎为民,杨德鹏,李虎生.中国云计算发展现状研究.电信快报,2011,10:1-6.
[2] 李德毅.2011云计算技术发展报告.北京:科学出版社,2011,5:1-10.
[3] Ray O’Brien.[2011-12-11].http:∥nebula.nasa.gov/blog/2012/05/29/nasa-and-openstack-2012/.
[4] 张诚忠.广东借助云计算破预报瓶颈天气分辨率升至3公里.[2011-12-11].http:∥news.xinhuanet.com/2011-12/11/c_111234079.htm.
[5] 沈文海.从云计算看气象部门未来的信息化趋势.气象科技进展,2012,1(2):49-56.
[6] 沈文海.云计算受困于服务手段的有限和体制两因素.[2012-12-15].http:∥cio.itxinwen.com/Online/2011/1115/370736.html.
[7] 刘小宁,张洪政,李庆祥.不同方法计算的气温平均值差异分析.应用气象学报,2005,16(3):345-356.
[8] 王炳忠,申彦波.我国上空的水汽含量及其气候学估算.应用气象学报,2012,23(6):763-768.
[9] 张强,熊安元,张金艳,等.晴雨(雪)和气温预报评分方法的初步研究.应用气象学报,2009,20(6):692-698.
[10] 张顺谦,马振峰,张玉芳.四川省潜在蒸散量估算模型.应用气象学报,2009,20(6):729-736.
[11] 刘娜.基于MapReduce的数据挖掘算法在全国人口系统中的应用.北京:首都经济贸易大学,2011:20-43.
[12] 李军华.云计算及若干数据挖掘算法的 MapReduce化研究.成都:电子科技大学,2010:19-32.
[13] 贾雄.数值天气预报云计算环境关键技术研究与实现.长沙:国防科学技术大学,2011:2-33.
[14] 万至臻.基于 MapReduce模型的并行计算平台的设计与实现.杭州:浙江大学,2008:17-21.
[15] 朱珠.基于Hadoop的海量数据处理模型研究和应用.北京:北京邮电大学,2008:7-20.
[16] 吴朱华.云计算核心技术剖析.北京:人民邮电出版社,2011:16-44.
[17] 周敏奇,王晓玲,金澈清,等.Hadoop权威指南(第2版).北京:清华大学出版社,2011:213-224.
[18] 金之雁,颜宏.数值天气预报并行计算模式的设计与可行性讨论.应用气象学报,1993,4(1):117-121.
[19] 牟道楠,王宗皓.层次分解并行计算法在TOVS资料中尺度分析中的应用.应用气象学报,1994,5(1):77-81.
A Set of Map Reduce Tuning Experiments Based on Meteorological Operations
Yang Runzhi1)Shen Wenhai1)Xiao Weiqing1)Hu Kaixi1)Yang Xin1)Wang Ying1)Tian Wei2)
1)(National Meteorological Information Center,Beijing100081)
2)(Nanjing University of Information Science&Technology,Nanjing210044)
Cloud computing technologies,which solves the problem of low computing power of a standalone server,uses distributed computing technology to achieve the computing power of parallel computing and computational efficiency.Cloud computing is a new application model for decentralized computing which can provide reliable,customized and maximum number of users with minimum resource,and it is also an important way to carry out cloud computing theory research and practical application combining with other theory and good techniques.In many industries and fields,cloud computing has a wider range of applications,and its flexibility,ease of use,stability is gradually affirmed.In meteorological department,cloudbased platform for the development of scientific computing is still very limited,but some attempts are implemented with the maturation of cloud computing.
In meteorological operations,such as large-scale scientific computing and other general computing model are run on high-performance server clusters.Due to limitations of resources and the number of HPC nodes,scientific computing still relies on traditional standalone or clustered mode.Therefore,an internal exploration and conventional general-purpose computing and cloud computing platform is very meaningful for the meteorological department.60-year valuable and precious long sequence of historical data are stored in National Meteorological Information Center for the use of real-time,near-real-time business and research.Processing these historical data is time-consuming,therefore some new methods are implemented.Based on Hadoop cloud computing platform,a cluster mode is built and a variety of statistical methods areadopted using Map Reduce computation model.The storage format of the source data is adjusted with SequenceFile which is composed of<Key,Value>serialization,by this mean multiple files of Format-A are merged to a large SequenceFile to test computational efficiency changes.Meanwhile,many small files are merged to a larger file.Configurations are modified experimentally for the Hadoop cluster environment,and different number of task nodes are used to record different computational efficiency.
Map Reduce;cloud computing;Hadoop;meteorological data processing
杨润芝,沈文海,肖卫青,等.基于 MapReduce计算模型的气象资料处理调优试验.应用气象学报,2014,25(5):618-628.
2013-10-08收到,2014-06-03收到再改稿。
*email:yangrz@cma.gov.cn
