调优MapReduce工作负载
2014-07-01冯秋燕
冯秋燕
(河南财经政法大学,河南郑州 450000)
调优MapReduce工作负载
冯秋燕
(河南财经政法大学,河南郑州 450000)
大规模的数据密集型计算引起了研究界和工业界的广泛关注,Hadoop、MapReduce等的开源实现,越来越多地应用于大数据分析。针对MapReduce工作负载的调优问题,通过实验验证了参数配置对MapReduce工作性能的影响,从5个方面介绍了调整MapReduce工作负载的常见调优场景。
大数据;MapReduce工作负载;参数配置;调优场景
1 引言
MapReduce是处理大规模数据的一个相对年轻的框架,MapReduce是一个编程模型、一个关联型运行时系统[1]。Hadoop是奠定在原始基础上的最流行的MapReduce实现的开源框架之一[2],并应用于大多数公司生产配置阶段的应用程序中。IaaS云平台允许用户即时的配置集群,用户仅仅需要为使用时间和所使用的资源付费,这使得Hadoop工作负载运行更为容易。Hadoop有如下优点:较好的容错能力、本地数据调度、异质环境下的操作能力、错误环境下的执行能力、模块化、可制定的框架等。本文将证明配置参数设置对MapReduce工作的性能影响。然后,列举日常中出现的各种各样的优化和调整场景。
2 配置参数设置的影响
Hadoop由190多个配置参数,而本文目前只考虑其中14种对工作性能的影响[3]。本文所使用的实验对象是WordCount(简称为WC)、TeraSort(简称为TS)。WC处理由Hadoop’s RandomTextWriter生成的30GB的数据,TSt处理由Hadoop’s TeraGen生成的50GB的数据。图1(a)、图1(b)与图2(a)、图2(a)分别为测量WC与TS工作执行时间生成的反映面,其中,这些图中有3个参数产生了变化,而其他的工作配置参数保持常量。
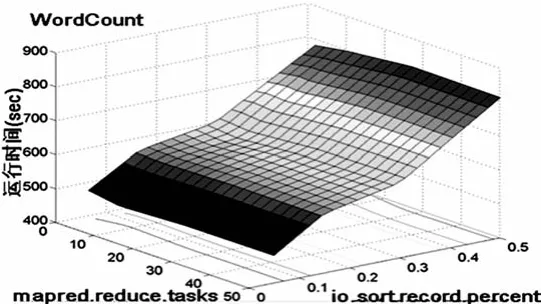
图1 (a)设置mapred.reduce. tasks时WC反映面

图1 (b)设置io.sort. mb时WC反映面
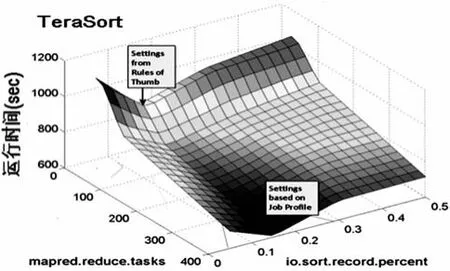
图2 (a)设置mapred. reduce.tasksTS反映面

图2 (b)设置io.sort.mb 时TS反映面
参数设置对MapReduce工作性能的影响依赖于工作、数据、集群等特征:
2.1 工作特征对工作性能的影响:图1(a)和图2(a)展示了mapred.reduce.tasks参数设置从不同程度影响了WC、TS。无论io.sort.record.percent怎样变,reduce任务数目的增加对WordCount的性能并没有影响,却显著提高了TS的性能。WC工作由map控制,map中的计算包括数据文件的解析、组合函数的使用,而reduce任务只简单合计了字数。
2.2 数据特征对工作性能的影响:数据特征可以影响有着相同参数设置的、相同MapReduce程序的工作运行时间。图2(a)包含了一个“谷(valley)”,在该“谷”点,io.sort.record.percent设置为0.15。io.sort.record.percent表示map的顶峰规模的分值,用于描述map输出的元数据存储。由map任务产生的每一个记录要求16字节的元数据及其系列化规模。对于io.sort.record.percent的任何值,平均的map输出记录的规模将决定是否由于系列化缓存的耗尽或者元数据缓存的耗尽将数据溢出(spill)至硬盘。
2.3 集群特征对工作性能的影响:当reduce任务T的总数量NT比reduce任务执行槽S的总数目NS低时,所有的reduce任务都将并发运行。当NT≤NS,改变reduce任务的数目将对工作性能有显著的影响,假设reduce任务的执行时间与map任务的执行时间是可比的。当NT>NS时,reduce任务将在并行reduce波里运行。从图2(a)中可得,reduce任务数目增加,性能也提升,但是由于每个并行reduce波的有效并发程度的带宽的限制,提升率却下降。
2.4 参数间的交互对工作性能的影响:Hadoop中配置参数的子集显示了一个或多个参数间较强的性能交互。图1(b)显示了当io.sort.record.percent设置较低的值时,改变io.sort.mb对工作性能并没有产生显著的影响;io.sort.record.percent设置较高的值时,改变io.sort.mb对工作性能产生了很大的影响。图2(b)显示了io.sort.record.percent、io.sort.mb间的更强、更复杂的交互。io.sort.record.percent设置不同的值,io.sort.mb变化可能导致性能的变化形式也不同。
3 调整MapReduce工作负载的用户案例
本文的调优问题是,对于一个给定的分析工作量,确定集群资源和MapReduce工作级配置参数设置,以满足其执行时间和成本上的要求。本节首先讨论一些出现调优问题的常见场景。
3.1 调整工作级配置参数设置
在MapReduce框架中运行单个工作,大量的配置参数必须由用户或系统管理员设置。MapReduce工作或工作流的性能在反应时间或工作负载的完成时间上不能满足服务级要求。因此,需要理解工作行为、诊断工作执行期间所用参数设置的瓶颈。
3.2 调整弹性工作负载的集群规模
假设MapReduce工作在m1.large的10-EC2节点的Hadoop集群上花费了3个小时。控制集群的应用程序或用户可能想知道如果在集群上再增加5个m1.large节点,工作执行时间将减少多少;用户也可能想知道在集群上再增加多少个m1. large节点运行时间能降至2小时。
3.3 工作负载从发展集群向生产集群过渡
与运行关键任务和时间敏感性工作负载的生产集群相比,许多企业为程序开发维持了独立的(可能多样的)集群。弹性和现买现付特性简化了维持多样集群的任务。开发者首先会在开发集群上测试新的MapReduce工作,可能会使用生产集群中的数据中的少量有代表性的样本。在工作被调度至生产集群之前(通常作为分析工作负载的一部分定期运行在新数据上),开发者需要识别MapReduce工作级配置,这个工作级配置将提供良好的工作性能。
3.4 多重目标下的集群配置
IaaS云平台提供了一个集群中所使用节点类型的多种选择。随着这些节点上计算、存储、I/O资源的增加,每个小时的使用费用也增加。图3(a)、图3(b)分别显示了运行在EC2上的Hadoop在不同集群配置下的MapReduce工作负载执行时间、总费用。图3(a)和图3(b)中的集群使用EC2节点类型中的5种节点;每小时使用费用,记为cost_ph。计算每个工作负载执行的相关总费用所使用的价格模型是:

这里,num_nodes是集群中的节点数目,exec_time是在大多数云计算平台上完成工作负载的执行时间(向上舍入到最接近的小时)。用户可能对工作负载有多种偏好和约束[4],例如,用户目标可能是最小化工作负载运行的成本费用,以最大化忍耐工作负载执行时间为代价。从图3(a)、图3(b)可以看出,用户想以执行时间小于45分钟为前提,最小化成本。

图3 (a)运行时间对比

图3 (b)成本费用对比
3.5 及时调整工作负载以降低执行成本
公式1的成本模型被用于计算图3(b)的成本,基于所使用的节点类型收取每小时的费用,其中,这些节点被称为EC2上的按需实例。Amazon EC2也提供了现场实例。现场实例的价格随时间变化,通常依赖于云上资源的供求关系,电价时空变化等其他因素也可以导致云资源使用成本的波动。

图4 现买现付方式成本费用
综上所述,图4与图3(a)、图3(b)的工作负载是相同的,图4描述了使用EC2现场实例类型的运行情况。在该案例中,用于计算总成本的定价模式:
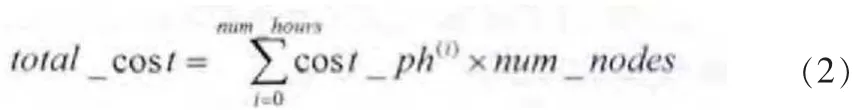
其中,cost_ph(i)代表了每个集群中使用的节点类型第i个小时的费用。比较图3(b)和图4,显而易见,如果所使用的集群资源不同,则相同负载的执行费用是不同的。
4 结束语
本文主要首先讲述了配置参数设置对MapReduce工作性能的影响,并对云上的MapReduce做简要介绍,最后以实际用户案例说明了调整MapReduce工作负载的常见场景。下一步工作是构造合适的成本模型,研究基于数据流系统的成本优化和自动调整技术,期望解决基于成本的优化和自动调整间的差异。
[1]DEANJ,GHEMAWATS.MapReduce:AFlexibleData Processing Tool[J].Communications of the ACM,2010,53(1):72-77.
[2]YAOY,TAIJZ,SHENGB,MINF.Scheduling heterogeneous MapReduce jobs for efficiency improvement in enterprise cluster[C]//IFIP/IEEE International Symposium.Belgium: 2013 IFIP/IEEE,2013:872-875.
[3]HERODOTOU H,LIM H.Star sh:A Self-tuning System for Big Data Analytics[R].Durham:in Proc of the 5th Biennial Conf on Innovative Data Systems Research.2011.
[4]林彬,李姗姗,廖湘科,等.Seadown:一种异构MapReduce集群中面向SLA的能耗管理方法[J].计算机学报,2013,36(5):977-987.
TP311
A
1003-5168(2014)04-0017-02
冯秋燕(1988.7—),女,硕士,助理工程师,研究方向:现代软件工程技术、数据挖掘。
