基于人工神经网络的供水管网压力管理探索
2014-06-09张晔明
张晔明
(上海市政工程设计研究总院(集团)有限公司,上海 200092)
供水管网水力分析计算起始于1936年,是由Hardy Cross通过对环状网的水力计算而提出的。它是以节点上流量平衡和能量方程回路的水头损失平衡为准则,并引出校正流量的概念而导出的非线性方程组,然后将其线性化来求解。方程的欲求变量是环的校正变量,方程的个数是管网的基环数,由于此方法采用迭代方法便于手工运算,在没有计算机的当时比较盛行。随着计算机的出现及其应用软件的发展,供水管网的水力计算有了很大的发展,在理论及算法上日趋完善,70年代以后,随着计算机技术的应用发展,开始用图论来构造供水管网的节点方程和环方程,这些方程都是以矩阵来描述的,方程形式简单明了,而且求解这些方程的各种方法易于在计算机上实现。应用较多的是利用牛顿迭代法来求解节点方程和环方程。正是随着水力计算理论的日益成熟和完善,供水管网系统模拟仿真技术才得以实现。
国外城市供水管网建模的工作起步于60年代。1975年美国人Robert提出了配水系统客观模型,它是针对比例负荷的管网进行的,通过大量的实测数据来建立管网内部压力与水厂出水量、出水压力之间的统计关系表达式。20世纪80年代,在计算机技术飞速发展的促动下,英国在管网模拟与应用方面做了大量工作并提出了建模的标准。当时国外所采用的模型多为微观模型,即详尽地考虑到整个系统的各水力元素。同时这些研究都是针对国外的情况,如变电价政策、管网内设多个调节水池和泵站、水泵多为调速泵等。
国内有关管网建模的研究自20世纪70年代就开始了,但多为适于供水系统设计的平差理论,对于供水管网系统运行管理建模的研究较少。在供水系统优化调度研究方面采用了宏观模型,即利用给水系统的几个主要变量(如各水厂供水压力、供水量以及部分测压点的压力等),在运行记录的基础上利用统计分析的方法建立各变量间的关系式,来模拟供水系统的运行。这种方法克服了用微观模型方法所面临的基础数据缺乏或不正确、计算复杂且误差较大的缺点,其主要的问题是不能反映管网的工况,也不能进行管网的工况研究,在实际应用中不够理想。传统的供水管网建模采用微观模型,即针对管网(包括管段、阀门、水泵和水塔等)的实际情况(动态信息和静态信息),建立管网的状态方程(包括连续性方程、能量方程和管段水头损失方程),然后利用非线性方程组的求解器对管网状态方程进行求解,求得管网中各管段的流量、流速、水头损失,各节点压力以及各水源的供水量和供水压。此外还需要将所得的计算结果与监测数据相比较,如果误差不满足要求,则需修改模型。通过这一方式建立的模型可称为“白盒模型”,如图1所示。虽然利用上述微观模型可求得每个节点的压力、每条管段的流量、流速和水头损失,以便了解整个给水网络的细节情况,但是这一方法有着如下缺点:
(1)微观模型的建立需要供水管网的诸多具体信息,例如每条管段的长度、口径、材质、布置情况等。这样的信息对于新建的管网系统是可以获得的,而对于建设时间很长的管网系统,有些信息是根本无法获得的。因而在这种情况下,需要根据具体情况对管网系统进行简化,这样就会在模型中引入误差。
(2)管网状态方程是一组大型非线性方程组,其未知数数量随着管网规模的增大而呈线性关系增加,其求解计算量随着管网规模的增大而呈平方关系增加。尽管随着计算机技术的发展,中小规模的管网微观模型的求解所耗计算时间已经不长,但是仍无法满足给水系统实时优化调度的需要。而且,对于大规模的管网系统来说,微观模型的求解需要耗费大量的机时。
(3)微观模型的后期维护和更新的工作量巨大。一方面管段的摩阻系数是随时间而变化的,需要不断地根据检测数据对管段的摩阻系数进行修正,以确保误差在可接受的范围内;另一方面在管网扩建或改建的情况下,以前建立的微观模型及其计算结果无法重用。

图1 白盒模型Fig.1 White-Box Model
正是以上缺点,导致在给水系统的优化调度中无法利用管网的微观模型。为了克服基于微观模型的管网建模的缺点,可采用基于神经网络的建模方式,这一方式又称为宏观建模,所建立的模型可称为“黑盒模型”,如图2所示。在这一建模方式中,无须了解管段的具体信息,而是通过神经网络的学习和训练对输入和输出之间的非线性关系进行模拟。
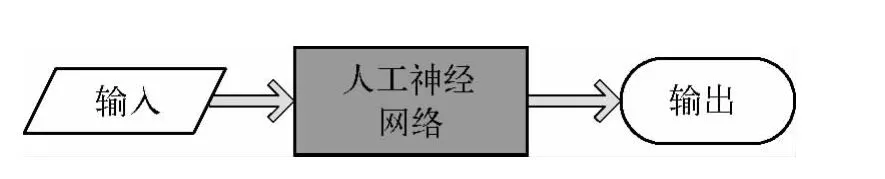
图2 黑盒模型Fig.2 Black-Box Model
国内也有研究者利用人工神经研究供水管网,但是多集中在研究需水量和供水管网的设计[1-3],还没有见到利用人工神经网络进行供水管网压力管理的文献。
1 人工神经网络原理
人工神经网络(artificial neural network,ANN)是在模拟大脑神经网络处理、记忆信息的基础上发展起来的,由大量处理单元互联组成的非线性、自适应信息处理系统,其特点就在于能充分逼近任意复杂的非线性关系。
在模拟和预测中经常使用的一类人工神经网络是BP(Back Propagation)型人工神经网络,其结构如图3所示。该人工神经网络由输入层、隐含层和输出层构成,隐含层可分为多层,其中每一层可包含多个神经元。
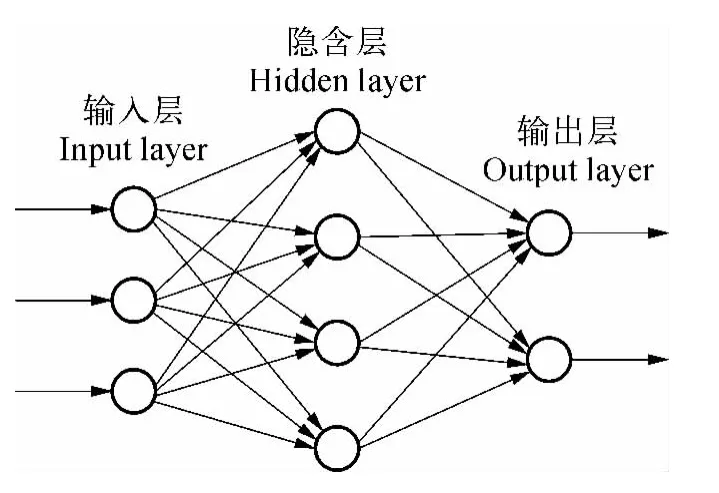
图3 BP型人工神经网络结构Fig.3 Structure of BP ANN
隐含层和输出层的神经元的结构如图4所示。神经元执行两个任务:一是对与之相连的其他神经元的输出求加权和;二是非线性激励函数f作用于该加权和,并将结果输出。
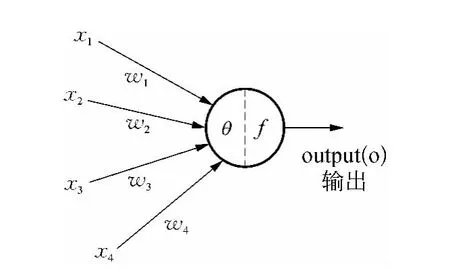
图4 神经元的结构Fig.4 Structure of Neural Cell
由此可见BP型人工神经网络具有三大要素:拓扑结构(输入层神经元的数量、隐含层的层数及其各层神经元的数量、输入层神经元的数量);各神经元之间的权值矩阵;激励函数。利用神经网络对物理现象的建模实际上就是针对实际测得的输入和输出确定这三大要素。人工神经网络的拓扑结构的确定需要考虑所模拟的物理现象的一些特征;激励函数一般选择为sigmoid函数;而权值矩阵的确定需要用输入和输出对神经网络进行“训练”,这种训练实际上是使模型输出与给定输出最接近的数值优化过程。
2 人工神经网络在压力管理中的应用
2.1 供水管网和流量、压力测点
苏州工业园区清源华衍水务有限公司负责建设和运营苏州工业园区300 km2区域内的给水、排水设施,现有给排水管网总长度为2 000 km以上,有1座水厂、2座污水厂、47座污水泵站,近几年内将陆续新建1座水厂和200个以上的小区二次加压供水泵房。2011年初,公司建立生产调度中心,逐步将管网 SCADA 系统[4,5]、污水泵站控制系统、水厂/污水厂监控系统、小区二次供水泵房监控系统、客户服务热线系统集中到调度中心,进行统一监控。图5示出了供水管网。
随着公司调度中心的硬件设施建设逐步到位,基于公司整个供排水管网的综合调度系统的建设日渐显现出必要性,包括给水管网综合调度、污水管网综合调度和水处理工艺优化等。
给水管网调度的目标是通过执行优化后的调度方案,在满足用户对供水压力、流量、水质要求的前提下,尽可能降低生产的直接成本(水泵能耗、物理漏耗、药剂费)和间接成本(设备损耗、管理费用等),并提高生产和输送过程的安全性、稳定性。过去公司只有一个水厂,给水管网调度比较简单。随着公司新水厂的筹建和投产,给水管网的输入因素增多,调度优化的空间较大。
为此,在供水管网中的关键节点处安装了流量计和压力变送器,共计52个压力测点,32个流量测点,分别如图6和图7所示。
图5 某市供水管网Fig.5 Water-Supply Networks of A City
2.2 研究路径
本研究的技术线路如图8所示。
(1)现场数据的预处理。现场数据是在不同的采样频率下采集的,因此需要用插值的方法对采样频率低的数据进行补值;此外,还需要对含有较大噪声的现场数据进行平滑处理。
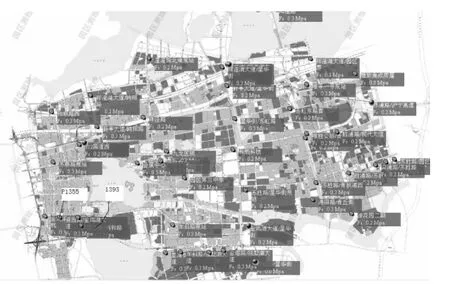
图6 管网压力测点分布图Fig.6 Pressure Probe Locations in Water-Supply Networks
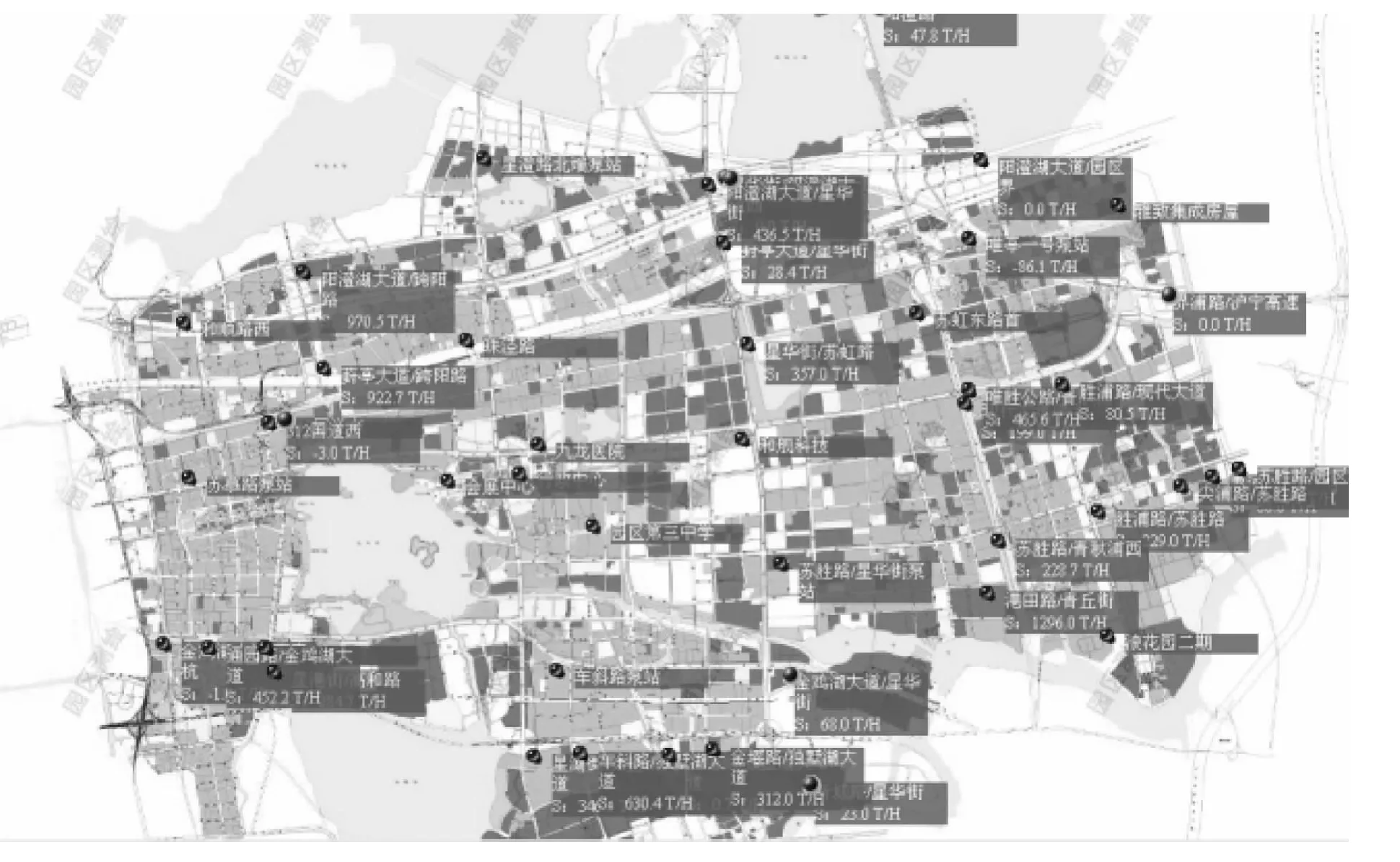
图7 管网流量测点分布图Fig.7 Flowrate Probe Locations in Water-Supply Networks
(2)选择模型的输入输出变量。对现场数据进行相关性(线性相关性和非线性相关性)分析,并根据现场数据的物理意义,选择相关性小的现场数据作为输入变量。在本研究中,将水厂的供水压力作为独立的输入变量,而将主要干管节点的压力作为关联的输入变量。
(3)建立ANN模型。在模型的建立中,将现有的现场数据分为训练数据集、测试数据集和验证数据集。采用训练数据集中的数据来训练ANN模型,以更新ANN模型中的权值;测试数据值用于测试ANN模型的权值;并最终用验证数据集中的数据来验证ANN模型。
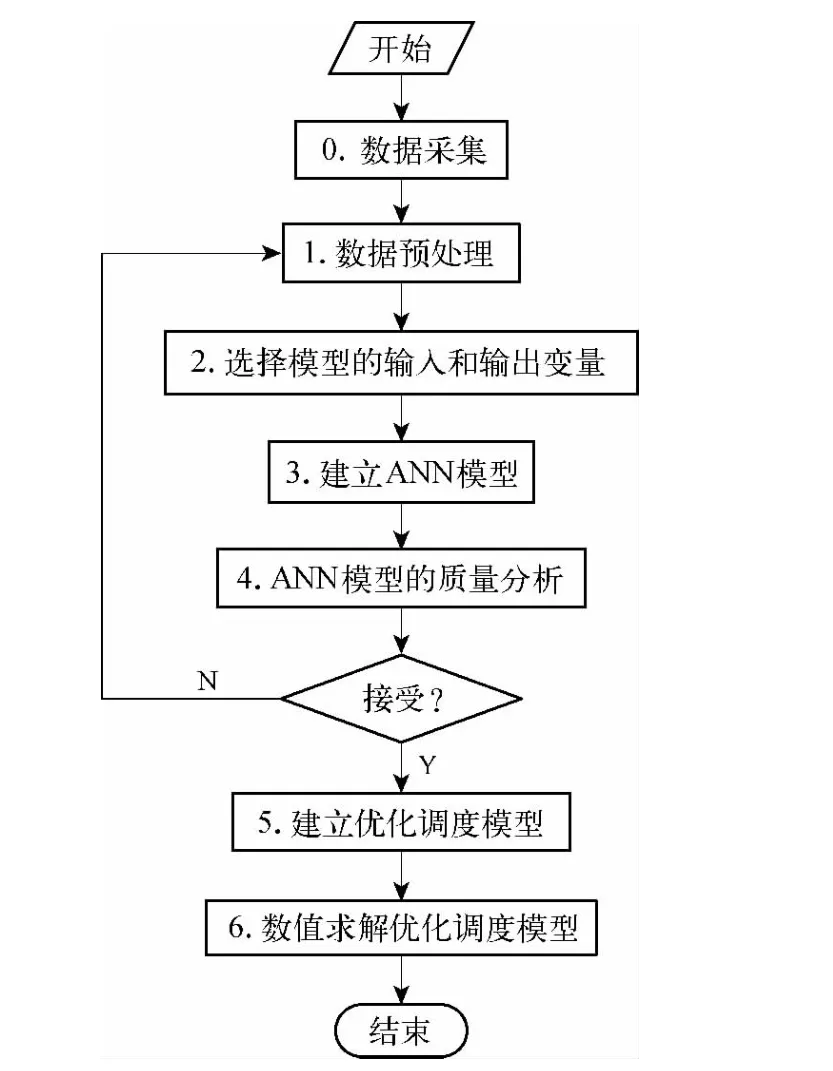
图8 研究路径流程图Fig.8 Flow Chart of Investigation Methodology
(4)ANN模型的质量分析。除了利用验证数据集中的数据来验证ANN模型之外,ANN模型还需要从误差、灵敏度等方面加以分析和评估。误差较大,有可能是模型的关联输入变量选择得不合理导致的,此时就需要重新选择模型的关联输入变量;也有可能是一些现场数据本身就带有较大的误差,此时就需要剔除这些现场数据;通过灵敏度的分析,可以计算输出变量对所有输入变量(独立的输入变量以及关联输入变量)的灵敏度,灵敏度小,则表明输入变量对输出变量的影响小,在必要时也需要重新选择输入变量。此外,还可通过另外收集的现场数据来检验ANN模型的质量。在ANN模型的质量可接受的情况下,可以ANN模型为基础来建立优化调度模型。否则,则需要从数据的预处理、输入输出变量的选择等方面加以调整和改进。
(5)建立优化调度模型。优化调度的目的是以尽可能低的成本满足用户对供水压力、流量、水质的要求,本研究只涉及压力的优化。优化调度模型可以有两种方式:一种是其目标函数仅包括供水成本,而将各干管的需水量和目标压力作为模型的约束;另一种是其目标函数不仅包括供水成本,还包括各干管实际供水量和压力与相应的需水量和目标压力之间的差的平方。这两种方式各有优缺点,可以在数值求解优化调度模型的过程中选择合适的方式。
(6)对优化调度模型进行数值求解。
2.3 人工神经网络建模
在本研究中,神经网络建模采用了含有三个隐含层的feed-forward back-propagation网络,其结构如图9所示。其中,隐含层的神经元数量分别为20、40、40,各隐含层采用的 transfer函数为 logsig;输出层得神经元数量为60,其transfer函数为purelin。人工神经网络结构中,其一个输入为其中一个水厂的出水压力P1314,模型的输出为流量F1178。需要指出的是,由于压力和流量的实测数据带有较大的噪音和较多的跳点,因而在利用这些数据进行人工神经网络建模之前,需要对这些数据进行降噪和除跳处理,本研究中采用Matlab中的Curve Fitting工具箱进行数据的预处理。图10为人工神经网络建模结果。
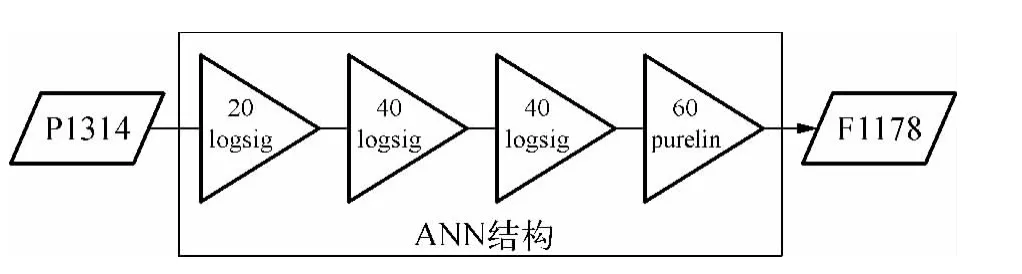
图9 人工神经网络结构Fig.9 Structure of ANN
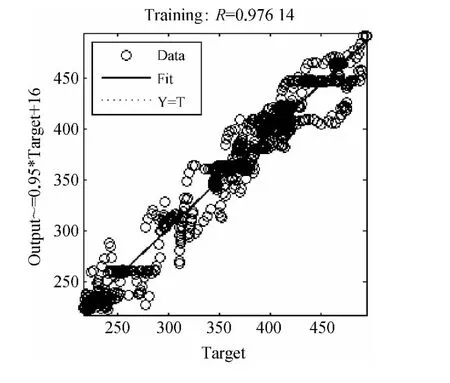

图10 人工神经网络建模结果Fig.10 Results of Modeling Based on ANN
2.4 优化
在以上建模的基础上进行优化计算,优化问题的目标函数如下:
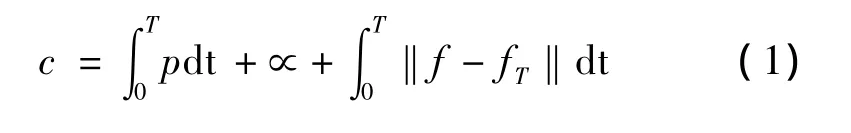
图11是优化输出的流量与目标流量fT的比较,可见除了有限个跳点之外,优化后的输出流量与目标流量吻合得比较好,从初始的1.025 4e+003 下降到 324.423 9。

图11 流量优化结果Fig.11 Optimization Results of Flowrate
图12是压力的初始值与优化后的压力值的比较。从整体上讲优化后的输入较初始输入有所下降,c1从427.2708 下降到423.522 8,下降0.88%。
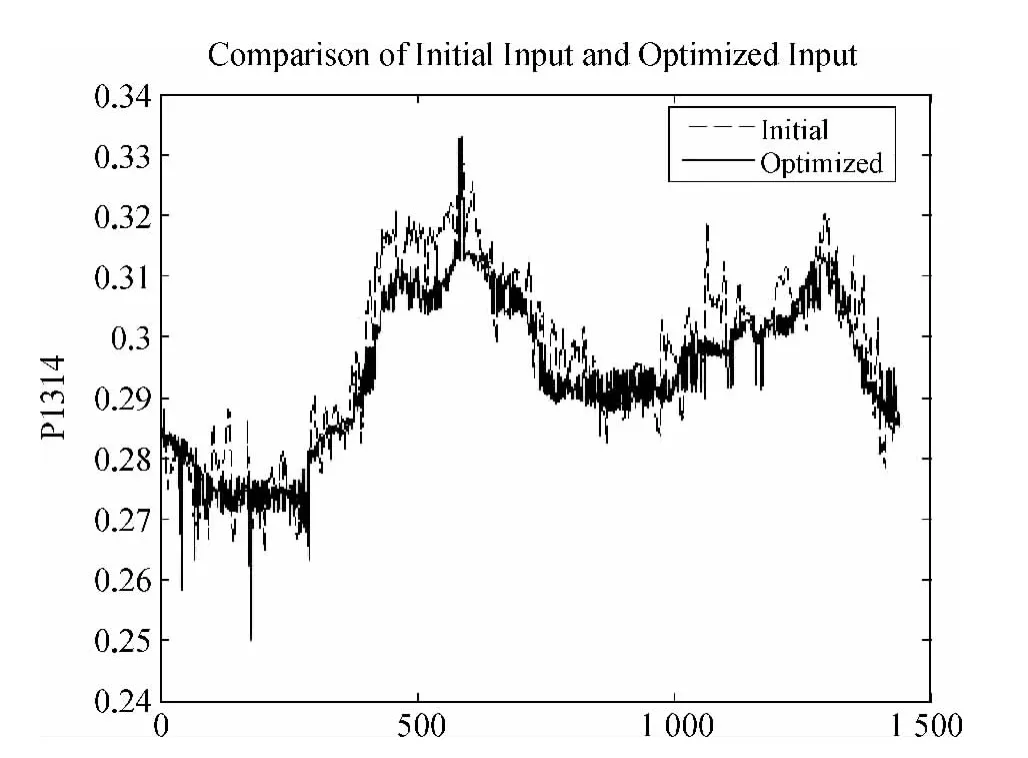
图12 压力优化结果Fig.12 Optimization results of Pressure
从优化的结果可以看出在满足目标流量的前提下,供水压力可降低将近1%。这对于降低供水能耗、减少管网漏损具有重大的意义。
3 展望
从目前的试验结果来看,利用ANN对供水管网进行建模并在此基础上进行压力管理是可行的。但是距实际应用还至少存在如下差距:
计算给出的压力值,如图12中的实线所示,有比较大的波动,导致其无法用来控制实际生产过程。在进一步的研究中可采用如下方法来克服这一问题:一是对优化给出的压力值进行平滑处理,然后用于控制;二是在优化中将变量参数化;三是在优化模型中设定更加合理、适于控制的约束条件。
在下一步的研究中,将建立包括更多流量测点的人工神经网络模型,并基于此进行压力管理。
[1]许刚,吕谋,张士乔.给水管网神经网络模型数据预处理方法探讨[J].中国农村水利水电,2005,47(5):17-19.
[2]乐永生.基于MATLAB的给水管网优化设计研究[D].合肥:合肥工业大学,2009.
[3]任彬,周荣敏.基于遗传优化神经网络的市政管网水质模型研究[J].供水技术,2010,4(3):31-34.
[4]王伟华.城市供水多系统集成SCADA调度信息平台[J].净水技术,2012,31(5):79-83.
[5]李国平.长江原水厂SCADA系统[J].净水技术,2009,29(6):18-20,25.
