基于样本抽样和权重调整的SWA-Adaboost算法
2014-06-06高敬阳
高敬阳,赵 彦
(北京化工大学信息科学与技术学院,北京100029)
基于样本抽样和权重调整的SWA-Adaboost算法
高敬阳,赵 彦
(北京化工大学信息科学与技术学院,北京100029)
根据分类算法是依据样本区分度进行分类的原理,提出增加样本属性以提高样本区分度的方法,在样本预处理阶段对所有样本增加一个属性值dmin以加强样本之间的区分度。针对原始Adaboost算法在抽样阶段由于抽样不均而导致对某些类训练不足的问题,采用均衡抽样方法,保证在抽样阶段所抽取的不同类样本的数量比例不变。针对原始算法样本权重增长过快的问题,给出新的权重调整策略,引入样本错分计数量count(n),有效地抑制样本权重增长速度。给出一种改进的Adaboost算法,即SWA-Adaboost算法,并采用美国加州大学机器学习UCI数据库中6种数据集的数据对改进算法与原始算法进行实验对比,结果证明,改进算法SWA-Adaboost在泛化性能上优于Adaboost算法,泛化误差平均降低9.54%。
样本预处理;均衡抽样;权重调整;泛化性能;类中心最小距离;样本区分度
1 概述
Adaboost算法[1]作为最受欢迎的分类集成算法在机器学习领域得到了极大的关注[2-3]。该算法是boosting算法中应用最广泛的算法[4],将若干个弱分类器通过线性集成而得到一个强分类器[5]。Adaboost算法已经通过数学证明得到:只要弱分类器的数目趋于无穷时,Adaboost算法的分类误差将趋于0[6]。
虽然Adaboost算法已经在文本分类、人脸检测、信息安全等很多领域得到了广泛应用[7],但该算法仍然存在以下缺陷:
(1)样本属性部分的区分度不明显而影响样本分类效果。
(2)训练过程中由于对样本抽样不均而使分类器对某些类训练不充分。
(3)训练过程中错分样本的权重增长过快[8]。
分类器是根据不同样本属性的区分度来对样本进行分类的,属性的区分度越明显则分类效果越好。因此,可以通过增加样本间的区分度来提高分类器的分类准确率。本文通过对所有样本增加一个属性值来增加样本的区分度,提高分类的效果。原始Adaboost算法在对分类器进行训练时,所有类均应当得到充分的训练,但由于抽样不均导致分类器对某些类的训练不足,从而降低了样本的分类效果。为此,本文提出均衡抽样的方法。此外,针对错分样本权重增长过快,给出新的权重调整策略,旨在降低错分样本的权重增长速度。就以上缺陷对原始Adaboost算法进行改进,并提出新的算法SWA-Adaboost。
2 算法改进分析
2.1 样本属性的增加
每个样本均可以表示成由n个属性位与1个分类位组成,例如样本 S={P1,P2,…,Pn,Ci},P1, P2,…,Pn为属性,Ci表示样本所属类别。分类器是依赖于样本属性的不同来区分不同样本,故属性的区分度直接影响到分类效果。本文将训练样本和测试样本均做了预处理,增加了一个属性值以提高样本之间的区分度,属性值为该样本到所有类中心的欧氏距离的最小值dmin[9]。若某样本属于Ci类,那么该样本到Ci类中心的距离较它到其他类距离更小,因此,此属性值具有实际意义。预处理方法如下:
(1)求类中心向量
假设第i类Ci中的样本数量为T,有:

求出该类样本中心向量:

以此类推得到 K类样本的中心向量:SC1, SC2,…,SCK。
(2)求dmin


2.2 样本训练不均衡分析

2.3 错分样本权重分析
Adaboost算法的样本权值调整策略是:

其中,Zt为归一化因子[11]。此权值调整策略存在一个问题:错分样本的权重增长速度过快[12]。为了缓解这种情况,改进算法对样本权值调整策略做了如下改进:

其中,Zt为归一化因子。
该策略中新引入了样本错分计数量:count(i), count(i)初始化为1。其表示第i个样本在前t个弱分类器中被错分的总次数。这种改进方法可以使错分样本的权值增长速度减缓。

(3)假设第i个样本被连续错分若干次,则count(i)=1,2,…,N。

由此可知,当某个样本被错分N次时,每次的权重增长幅度Δw小于原始算法的权重增长幅度。这样就达到了减缓错分样本权重增长的速度的目的。
3 SWA-Adaboost算法
SWA-Adaboost算法步骤如下:
(1)对训练样本集进行预处理。
(2)输入预处理后得到的新的训练样本集:

其中,xi∈X,yi∈Y={1,-1}。
(3)初始化样本权值和错分计数量:

(4)循环t=1to T
1)按均衡抽样法抽取样本;
2)弱学习算法训练得到弱分类器:

3)计算ht(x)的错误率:

4)计算个体网络的权值:
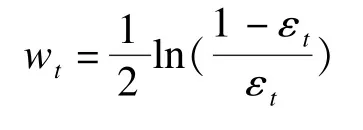
5)调整样本权值:

其中,Zt为归一化因子。
(5)集成分类器:

4 实验及结果分析
为了验证SWA-Adaboost算法在泛化性能上优于原始Adaboost算法,实验选用50个BP网络作为弱分类器进行集成,并采用UCI数据集中的sonar, glass,diabetes,breast-cancer-wisconsin,ablone,wine数据。2种算法的泛化误差如表1所示,性能对比如图1所示。
如表1所示,该表呈现出随着个体网络数的增加泛化误差的变化趋势(ADO表示原始Adaboost算法,SWA表示SWA-Adaboost算法)。由表1数据可以看出:改进算法SWA-Adaboost在数据集sonar,glass,diabetes,breast-cancer-wisconsin 和ablone上的集成泛化误差明显小于原始 Adaboost算法的集成泛化误差,只有wine数据集的SWAAdaboost算法的泛化误差较大。因此可得结论: SWA-Adaboost算法的泛化性能优于原始Adaboost算法的泛化性能。
由图1(a)~图1(e)可以看出,原始算法与改进算法在网络数较少时(少于5个)泛化误差均较大,随着个体网络数目的增加大致在10个之后,泛化误差虽有小幅波动但基本趋于平稳。图中显示,改进算法的泛化性能明显优于原始算法。只有图1(f)wine数据集的改进算法泛化性能不及原始算法。

表1 2种算法的集成泛化误差 %
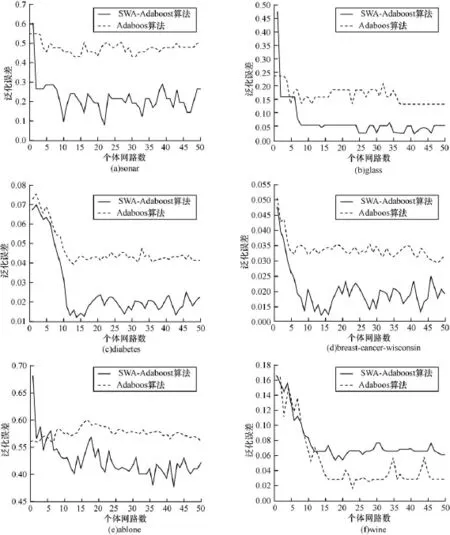
图1 改进算法与原始算法泛化性能比较
5 结束语
本文对原始Adaboost算法在样本分析阶段和抽样阶段以及样本权重调整阶段存在的缺陷进行分析,从这3个方面对原始算法进行了改进,提出了样本属性扩充、均衡抽样、新权重调整策略的方案,并给出了SWA-Adaboost算法。通过实验证明,改进算法在泛化性能上优于原始Adaboost算法。但改进算法对样本进行了预处理操作,故预处理阶段所需时间较长,从而影响算法整体的时间效率。因此,今后的研究重点应放在如何在不降低样本预处理准确率的前提下,缩短处理时间以提高算法整体的时间效率,使之成为时间效率与泛化性能俱佳的分类算法。
[1] Liu Meizhu,Vemuri B C.Rboost:Riemannian Distance Based Regularized Boosting[C]//Proc.of IEEE International Symposium on Biomedical Imaging.[S.l.]: IEEE Press,2011:1831-1834.
[2] Seyedhosseini M,PaivaA R C,Tasdizen T.Fast Adaboost Training Using Weighted Novelty Selection [C]//Proc.of International Joint Conference on Neural Network.[S.l.]:IEEE Press,2011:1245-1250.
[3] Shen Chunhua,Li Hanxi.On the Dual Formulation of Boosting Algorithms[J].IEEE Transactions on Pattern Analysis and Machine Intellgence,2010,32(12): 2216-2231.
[4] Lev R.Boosting on a Budget:Sampling for Featureefficient Prediction[C]//Proc.of the 28th International Conferenceon MachineLearning.Bellevue,USA: [s.n.],2011.
[5] An T K,Kim M H.A New Diverse Adaboost Classifier [C]//Proc.of International Conference on Artificial Intelligence and Computational Intelligence.[S.l.]: IEEE Press,2010:359-363.
[6] Schapire R.The Strength of Weak Learn Ability[J]. Machine Learning,1990,5(2):197-227.
[7] 付忠良,赵向辉,苗 青,等.Adaboost算法的推广——一组集成学习算法[J].四川大学学报,2010, 42(6):91-98.
[8] Gao Yunlong,Ji Guoli,Yang Zijiang,et al.A Dynamic Adaboost Algorithm with Adaptive Changes of Loss Funcion[J].IEEE Transactions on Systems,Man,and Cybernetics,2012,42(6):1828-1841.
[9] 饶 雄,高振宇.多分类器联合监督分类方法研究[J].四川测绘,2006,29(1):15-17.
[10] 林舒杨,李翠华,江 弋,等.不平衡数据的降采样方法研究[J].计算机研究与发展,2011,48(sl):47-53.
[11] Chen Xuefang,Xing Hongjie,Wang Xizhao.A Modified Adaboost Method for One-class SVM and Its Application to Novelty Detection[C]//Proc.of IEEE International Conference on Systems,Man,and Cybernetics.[S.l.]: IEEE Press,2011:3506-3511.
[12] 富春枫,荀鹏程,赵 杨,等.logitboost及其在判别分析中的应用[J].中国卫生统计,2006,23(2):98-100.
编辑 顾逸斐
SWA-Adaboost Algorithm Based on Sampling and Weight Adjustment
GAO Jing-yang,ZHAO Yan
(College of Information Science and Technology,Beijing University of Chemical Technology,Beijing 100029,China)
Because the classification algorithm based on the differences among samples,a new method is proposed which adds a new property value dmininto each sample in order to increase the differences.Besides,according to the situation that samples belonging to different classes are sampled unevenly in the sampling phase,a new method called even sampling is proposed to keep the proportion of difference classes invariant.For the purpose of inhibition of the increment speed of misclassification samples,a new method is proposed which brings in a variable count(n)to record the times of misclassification.In the word,an improved algorithm called Sampling equilibrium&Weight adjustment&Add attribute Adaboost(SWA-Adaboost)is proposed.Using the 6 datasets belonging to machine learning database of University of California in USA,the paper runs experiments to compare the original Adaboost with SWA-Adaboost. Experimental results show that SWA-Adaboost has better generalization performance than the original Adaboost and the average decrease of generalization error is 9.54%.
sample preprocessing;even sampling;weight adjustment;generalization performance;minimum distance of class center;different degree of sample
1000-3428(2014)09-0248-04
A
TP18
10.3969/j.issn.1000-3428.2014.09.050
国家自然科学基金资助项目(51275030)。
高敬阳(1966-),女,副教授、博士,主研方向:人工智能,模式识别;赵 彦,硕士研究生。
2013-09-02
2013-10-19E-mail:gaojy@mail.buct.edu.cn
