基于云计算的多重查询优化系统
2014-06-06徐常亮
葛 星,沈 耀,徐常亮
(1.上海交通大学计算机科学与工程系,上海200240;2.阿里云计算有限公司,杭州310099)
基于云计算的多重查询优化系统
葛 星1,沈 耀1,徐常亮2
(1.上海交通大学计算机科学与工程系,上海200240;2.阿里云计算有限公司,杭州310099)
在常规海量数据分析作业中,CPU/IO密集型的查询语句通常复杂、耗时并存在大量可复用的公共部分。如何检测、共享和复用回归查询集中语句间的公共部分成为亟需解决的问题。为此,提出特征值索引方法,并构建适用于云计算场景的LSShare多重查询优化系统。基于查询语句的抽象语法树将语句划分为不同的查询层次,针对每个查询层次抽取特征向量并计算特征值。建立简单高效的特征值索引表以识别多重查询语句间的公共部分,并结合SQL重写技术来复用其中的公共部分。随着运行迭代次数的增加,LSShare系统将逐步优化云计算场景中的回归查询集。实验结果表明,该系统在运行效率上优于传统查询语句系统,可节约近1/3的执行时间。
云计算;多重查询优化;查询处理;子表达式识别;海量数据处理;回归查询集
1 概述
多重查询优化(Multiple Query Optimization, MQO)是数据库领域的典型问题,它描述了如何高效地利用公共任务来优化多个查询语句从而产生执行结果。给定一个查询语句集,每个查询语句都将产生一个包含若干执行计划的候选集合。其中,每个执行计划又有一个包含若干任务的候选集合。MQO问题旨在为每个查询语句选择适当的执行计划,从而通过高效复用各执行计划间的公共任务(一次执行)来最小化整个语句集合的执行时间。对MQO问题的研究可以追溯到20世纪80年代, Sellis[1]首次系统地定义了该问题,同时也证明了该问题是一个 NP-Hard问题[2]。此后,大量启发式[3-5]和基于遗传算法[6]的近优解法被提出。
MQO问题在关系数据库领域已经得到了广泛深入的研究[7-9],但近期基于云计算海量数据处理中的MQO问题逐渐成为热点[10-11]。随着云计算的出现,网络点击流、网络爬虫、服务日志等应用每天持续不断地产生海量数据[12]。云计算应用通常维护一个数量巨大且持续增长的查询语句集来处理每天例行性的数据作业。传统MQO问题的解决方案通过构建每个语句的执行计划候选集来共享少量语句之间的公共任务,而针对大量语句将造成冗杂庞大的候选集和极其耗时的检测代价。同时,这些解法通常要求查询集以批处理方式进行,因而无法统一处理不定期加入到集合中的语句。针对关系数据库系统,仅在一个很小的范围内(不超过10条)近似最优算法[13]才能产生高效的全局计划。文献[14]针对类似的多重查询脚本场景,通过收集本地历史数据进行研究优化。然而,如何在云计算中解决回归查询集场景下的MQO问题依然十分具有挑战性。云场景中的查询语句集包含如下特征:(1)该集合包含大量结构相近、操作相似的语句;(2)该集合是参数化的;(3)该集合是回归化的;(4)该集合是动态增长的。称包含上述4种特征的集合为回归查询集。以Alibaba云计算系统数据存储与分析平台开放数据处理服务(Open Data Processing Service,ODPS)的日常回归查询集为例:该集合包含超过2 000条结构相近的查询语句;依据简单的字符串规则定期修改其中的时间字段或地域字段;通常按时或天为单位周期性运行以支持关键性的应用决策;根据不断变化的业务需求,将不定期有新的查询语句加入其中。ODPS平台每天处理该回归查询集以产生相关部门的日常数据报表。
现代企业通常使用回归查询集以支持PB级的海量数据处理应用。传统数据库中的MQO问题已经有了大量的近优解法,但并不适用于云计算场景。在云计算场景中,如何定义、检测和复用回归查询集中语句间的公共部分成为研究的关键。本文针对云场景下的多重查询优化问题,详细介绍了该问题的基本概念、查询语句间特征值抽取与特征值计算、LSShare系统的实现。
2 基于云计算的特征值索引方法
本文基于云计算场景的MQO问题,提出了特征值索引方法并构建了LSShare多重查询优化系统。首先,基于查询语句的抽象语法树(Abstract Syntax Tree,AST)将语句划分为不同的查询层次,针对每个查询层次抽取特征向量并计算特征值。然后,建立简单高效的特征值索引表以识别多重查询语句间的公共部分。最后,结合SQL重写技术来复用其中的公共部分。通过迭加运行次数,本文系统将随时间逐步优化云计算场景中的回归查询集。
2.1 基本概念
本文以SQL语句Q1为例说明本文方法中的基本定义。每个SQL语句都可以处理为一棵抽象语法树AST,该抽象语法树描述了SQL语句的语法结构。一个SQL语句依据其AST树结构,可以划分为不同的查询层次。查询层次描述了一颗抽象语法树或抽象语法子树。

(select*from src)a where id>10 group by id
如图1所示,Q1包含2个查询层次:Q1外层L1和Q1的子句L2,并且逻辑上前者包含后者。一个查询层次描述了其查询参数在该查询对象上的计算、操作和抽取的结果。Q1外层 L1中“from (select*from src)a where id>10 group by id”为其查询对象,“id,sum(value)as cnt”则是该查询层次的查询参数。查询参数描述了针对查询对象的列抽取和列计算操作,而查询对象则包含了完整的特征值抽取的信息。更详细地,“where id>1”和“group by id”组成了该查询对象的过滤特征,而“select*from src”则描述了该查询对象的流特征。

图1 Q1语句结构分析
过滤特征描述了一个查询中所有行相关的过滤操作。通过定义过滤特征来保证行信息在数据流过程中的完整性。过滤特征包含了许多SQL的操作。比如语法“WHERE”描述了行的删除操作,语法“ORDER BY”描述了行的排序操作,语法“LIMIT”描述了行的排序和删除操作。这些都作为数据流的过滤特征信息进行保存。
流特征则描述了数据的分支来源结构。查询语句可以根据其数据源的流特征分为如下类型: (1)TABREF类型,描述了数据来源于物理表; (2)SUBQUERY类型,描述了数据来源于一个子查询,又可分为一般的 SUBQUERY和 UNION_ SUBQUERY;(3)JOIN类型,描述了数据源于两表或多表JOIN操作。
2.2 特征向量抽取
特征向量是一个查询层次逻辑结构的抽象定义。它包含了完整的数据流向和过滤操作信息,因此,可以作为公共部分的特征标识。
图2详细描述了特征值索引算法针对一个查询层次的特征值定义。首先,将查询层次中的表达式进行标准化处理。然后,将查询层次的AST树拍平为包含完整信息的SqlData对象。递归遍历该对象并根据需要进行必要的信息提取和扩展。SqlData对象包含了一个查询对象所应具备的流特征和过滤特征。过滤特征由诸如“ORDER BY”和“WHERE”等条件构成。流特征则由不同的数据流结构诸如“SUBQUERY”和“UNION_SUBQUERY”构成。其中,“SUBQUERY”和“UNION_SUBQUERY”递归地使用其子查询的特征值结果。如图2所示,本文将一个查询层次的查询对象抽取为一个特征向量。

图2 特征向量定义
在具体实现上,选择开源工具 ANTLR来对SQL语句进行词法分析和语法分析,生成一颗AST树。针对每个查询层次依据其查询对象信息来递归构造特征向量。该特征向量使用JSON格式字符串存储。例如对于查询语句Q1,根据其AST树可以划分为2个QUERY层次,通过算法处理可以抽取出如下2个特征向量(由JSON串来表示):

此为内层SUBQUERY(即图1中的L2层次)的特征向量,通过MD5算法计算得特征值Sig1为: e960c2b5a542fca4feb4c0e549caf6ff。

此为外层QUERY(即图1中的L1层次)的特征向量,通过特征值计算其值Sig2为e960c2b5a 542fca4feb4c0e549caf6ff。需要注意的是,特征向量Vector_2中使用了 Vector_1的特征值 Sig1作为sourceValue。
2.3 特征值计算
特征值是特征向量计算后的固定长度的数值结果。最终以特征值为标准来比较和识别单个SQL语句内不同查询层次间的公共部分,以及不同SQL语句间的不同查询层次间的公共部分。
在实现上使用实际应用广泛的MD5算法将JSON格式定义的特征向量计算为特征值。然后,将这些特征值用 Hibernate持久化为特征值索引表。对于新加入的语句,计算其特征值并查找索引表,如果命中,则说明两者包含公共部分,结合SQL语句重写技术来复用两者之间的公共部分。
3 系统实现
针对云计算中的回归查询集场景实现了一个高效的多重查询优化系统,如图3所示,该系统可以方便地集成和扩展到其他分布式系统中。

图3 多重查询优化系统架构
使用标准查询语句集模拟了真实生产集群上的日常作业行为。该语句集包含大量结构复杂的查询语句,这些语句每天都会被自动化替换其中的日期或地点参数。每天不定期会有一些新的查询语句加入到该固有查询集中。本文系统使用特征值索引方法来初始化该查询语句集并依此生成特征值索引表。运行时它处理不定期新加入的查询语句并计算该单个语句的特征值。如果该语句的特征值命中特征值索引表中某一项,即说明新加入的查询语句与原有的查询语句集有公共部分可以复用。基于该特征值的重复频度与复用深度的权衡,为用户提供可选的SQL重写语句。将改写后的语句加入该日常回归查询集并同时优化该集合中的剩余部分。
4 实验结果与分析
本文原型系统LSShare基于Alibaba云平台的离线数据处理服务ODPS实现。使用MapReduce框架针对每个查询语句的不同查询层次进行特征向量抽取和特征值计算,并据此建立特征值索引表。实验集群包含 114个服务器节点,每个节点配置2.40 GHz CPU和24 GB内存。特征索引表方法的具体算法基于Java语言实现。
使用基于TPC-H测试标准2种典型的查询语句集:阿里金融离线数据测试机和淘宝离线数据测试集。每个查询集包含近10 000条复杂耗时的类SQL语句。为纵向对比不同规模的查询集之间的效率差异,实验从规模较大的语句集中随机抽取小规模数量的查询语句并构建成一个新的语句集合。
4.1 覆盖率分析
覆盖率分析目的在于分析回归查询集中公共部分所占的百分比。图4横向比较显示,相同类型的回归查询集有大致相同的公共部分覆盖率。纵向比较显示,不同规模的查询集均有近30%的公共部分可以复用,并且随着语句数量的增长,本文系统在一定限度内能检测到更高的公共部分覆盖率。
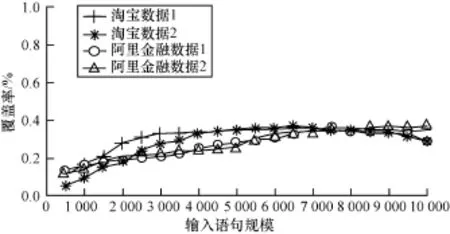
图4 覆盖率分析
以图4中包含2 000条SQL语句的查询集为例,经过特征值索引方法,这些语句被拆分为7 515个查询层次,每个查询层次抽取为一个特征向量并依此计算为特征值。即一个查询语句平均包含4个查询层次,这说明这些查询语句通常比较复杂和耗时。实验数据显示,该集合在索引表中有2 631个重复特征值,即说明公共部分的覆盖率在31.24%。其中,单个索引重复的最大次数为72次。结果表明,该特征值索引方法针对回归查询集的公共部分检测具有极高的效率。
4.2 可扩展性分析
可扩展性分析的目的在于分析本文系统在查询语句集不断增长的情况下的性能。通过特征值索引表的初始化时间来度量本文系统的可扩展性。本文系统利用MapReduce框架并行处理上万条查询语句,重复进行实验并记录不同规模的语句集耗费的平均时间。
图5表明不同规模的查询语句集构建特征值索引表的时间缓慢增长。其主要原因是随着语句集规模的增加,查询语句长尾的出现概率不断增加,从而导致执行时间缓慢增长。剔除个别查询语句的长尾现象,结果表明本文系统随查询语句集规模的增长有着良好的可扩展性。

图5 可扩展性分析
4.3 优化性能分析
优化性能分析的目的在于度量本文系统在时间维度上的优化效益。此外,将本文系统与传统的Hive系统进行对比实验,并着重探讨了不同语句类型的加速比。
为模拟回归查询集场景,实验中使用一个包含5 000条语句的查询语句集,每次都新加入近1%的查询语句。实验重复进行100次,对本文系统和Hive系统的执行时间进行比较,如图6所示。

图6 LSShare与Hadoop/Hive系统优化性能对比
从图6中可以得到以下结论:(1)随着运行迭代次数的增加,本文系统针对固定查询语句集的查询速度将逐渐加快。而Hive系统的运行时间则随迭代次数的增加基本恒定。这意味着基于反馈机制的系统优化效益将随着迭代次数的增加逐渐均摊到整个查询集上。(2)当迭代次数较少时,本文系统的执行时间较高。反之,当迭代次数较多时本文系统的执行效率将远超Hive。实验结果表明,在均摊分析意义上LSShare性能优于Hive。
图7针对不同类型的查询语句进行对比,发现查询语句中最有优化价值的是包含“UNION”或“JOIN”结构的复杂子查询。本文系统通过复用其中的公共部分能够节约大概20% ~50%的执行时间。

图7 不同类型的查询语句优化性能对比
5 结束语
本文提出了特征值索引方法来解决回归查询集中的 MQO问题。结合 SQL语句重写技术,在Alibaba的云计算平台上实现了该优化系统。实验结果表明,该优化系统简单高效。今后将通过改进特征值定义以识别更多的公共部分,使得该优化系统更智能化和自动化,并将其扩展应用到其他分布式系统中。
[1] Sellis T K.Multiple-query Optimization[J].ACM Trans.on Database System,1988,13(1):23-52.
[2] Sellis T K,Ghosh S.On the Multiple-query Optimization Problem[J].IEEE Trans.on Knowledge and Data Engineering,1990,2(2):262-266.
[3] Shim K,Sellis T K,Nau D.Improvements on a Heuristic Algorithm for Multiple-query Optimization[J].Data and Knowledge Engineering,1994,12(2):197-222.
[4] Roy P,Seshadri S,Sudarshan S,et al.Efficient and Extensible Algorithms for Multi Query Optimization [J].ACM SIGMOD Record,2000,29(2):249-260.
[5] Cosar A,Lim E P,Srivastava J.Multiple Query Optimization with Depth-firstBranch-and-bound and Dynamic Query Ordering[C]//Proceedings of the 2nd International Conference on Information and Knowledge Management.New York,USA:ACM Press,1993:433-438.
[6] Bayir M A,Toroslu I H,Cosar A.Genetic Algorithm for the Multiple-query Optimization Problem[J].IEEE Trans.on Systems,Man,and Cybernetics,2007,37(1): 147-153.
[7] Nykiel T,Potamias M,MishraC,etal.MRShare: Sharing Across Multiple Queries in MapReduce[J]. Proceedings of the VLDB Endowment,2010,3(1/2): 494-505.
[8] Elghandour I,Aboulnaga A.Restore:Reusing Results of MapReduce Jobs[J].Proceedings of the VLDB Endowment,2012,5(6):586-597.
[9] Herodotou H,Lim H,Luo G,et al.Starfish:A Selftuning System for Big Data Analytics[C]//Proceedings of the 5th Biennial Conference on Innovative Data Systems Research.Asilomar,USA:[s.n.],2011: 261-272.
[10] Bruno N,Agarwal S,Kandula S,et al.Recurring Job Optimization in Scope[C]//Proceedings of 2012 ACM SIGMOD International Conference on Management of Data.New York,USA:ACM Press,2012:805-806.
[11] Lee R,Luo T,Huai Y,et al.YSmart:Yet Another SQL-to-MapReduce Translator[C]//Proceedings of the 31st InternationalConference on Distributed Computing Systems.Washington D.C.,USA:IEEE Computer Society,2011:25-36.
[12] Dean J,Ghemawat S.MapReduce:Simplified Data Processing on Large Clusters[J].Communications of the ACM,2008,51(1):107-113.
[13] Kalnis P,Papadias D.Multi-query Optimization for Online Analytical Processing[J].Information Systems, 2003,28(5):457-473.
[14] Bruno N,Agarwal S,Kandula S,et al.Recurring Job Optimization in Scope[C]//Proceedings of 2012 ACM SIGMOD International Conference on Management of Data.New York,USA:ACM Press,2012:805-806.
编辑 陆燕菲
Multiple Query Optimization System Based on Cloud Computing
GE Xing1,SHEN Yao1,XU Chang-liang2
(1.Department of Computer Science and Engineering,Shanghai Jiaotong University,Shanghai 200240,China;
2.Alibaba Cloud Computing Co.,Ltd.,Hangzhou 310099,China)
In routine massive data analysis queries,the CPU/IO intensive analysis queries are complex and timeconsuming,but share common components.It is challenging to detect,share and reuse the common components among thousands of SQL-like queries.Aiming at these problems,this paper proposes the signature-index approach and implements the LSShare system to solve the Multiple Query Optimization(MQO)problem in the cloud with a recurring query set.It generates signatures for each query based on Abstract Syntax Tree(AST).Then it makes a simple but efficient index for further identifying and sharing common components of multiple queries combined with SQL-rewriting techniques.LSShare system gradually optimizes regression query set in the cloud computing scene as the superposition of run number.Experimental results demonstrate,the system is superior to the traditional query optimization in share equally,and it can save nearly a third of the execution time.
cloud computing;Multiple Query Optimization(MQO);query processing;subexpression identification; massive data processing;recurring query set
1000-3428(2014)09-0046-05
A
TP311.13
10.3969/j.issn.1000-3428.2014.09.010
国家“863”计划基金资助重大项目“以支撑电子商务为主的网络操作系统研制”(2011AA01A202)。
葛 星(1987-),男,硕士研究生,主研方向:云计算,分布式计算;沈 耀(通讯作者),副教授;徐常亮,博士。
2013-09-25
2013-11-11E-mail:gexing111@126.com
