数据挖掘在通信行业精确营销中的应用
2014-05-12师江波
师江波
(昆明理工大学信息与自动化学院,云南昆明650051)
随着4G时代的来临,通信行业即将获得更广阔的发展空间和潜力,在实际的生产运营过程中,数据业务收入已经逐渐跃居收入第二,仅次于语音收入,因此数据业务得到了运营商越来越多的关注,而数据业务的营销依然停留在传统的营销方式,如通过调查资料、客服外呼营销等方式,属于一种普遍撒网式的营销,这种营销方式成本高,周期长,客户真正的响应率低。
用户对数据业务的使用都或多或少的与用户消费行为以及用户背景信息有关联,而数据挖掘技术就可以找到这种联系,发现其中的规律。由此本文以彩铃为例,利用决策树算法对该数据业务的精确营销进行指导,通过挖掘当前彩铃用户特征,即具有什么行为特点的人可能会开通彩铃,进而锁定彩铃营销的潜在客户群,再对预测名单内的用户进行主动营销,降低了营销成本,提高了营销的响应率。
1 相关知识
决策树很擅长处理非数值型数据,免去了很多数据预处理工作。常用的算法有CHAID、CART、Quest和C5.0,本文采用目前较成熟的C5.0算法。C5.0是经典的决策树算法,相比CART树只能生成二叉树来说,C5.0算法可生成多分支的决策树,目标变量即为分类变量,最后可以生成树状图或者规则集。C5.0根据能够带来最大信息增益的字段拆分样本,第一次拆分确定的样本子集随后再次拆分,通常是根据另一个字段进行拆分,其中数值型字段被划分成区间,字符型字段被组织成集合,这一过程重复进行直到样本子集不能再被拆分为止。最后,重新检验最低层次的拆分,支持的事例数过少或者支持的概率较低的样本子集(即决策树叶子)将被剔除或者修剪。
决策树用样本的属性作为节点,用属性的取值作为分支的树结构,是利用信息论原理对大量样本的属性进行分析和归纳而产生的。
信息论中的信息熵H(U):信息量的数学期望,是信源发出信息前的平均不确定性,也称先验熵;

设S是一个样本集合,目标变量C有k个分类,freq(Ci,S)表示S中属于Ci类的样本数,|S|表示样本集合S的样本数。则集合S的信息熵定义为:
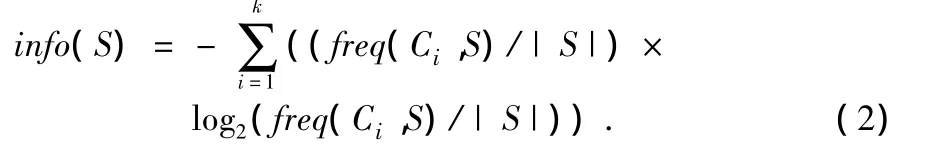
2 彩铃客户预测
利用决策树算法,将彩铃客户消费属性和客户背景属性一起作为决策树的输入属性,将彩铃用户和非彩铃用户按照某种比例组合作为预测的训练数据。决策树算法是一种“有指导”的归纳学习,通过大量数据的学习归纳出预测规则集,即我们要研究的问题是:什么样的人可能是潜在的彩铃客户,而什么样的人可能不是潜在的彩铃客户。
2.1 输入属性
决策树的输入属性由两部分组成,一部分是对彩铃消费产生较大影响的客户消费行为属性,如:区内时长、区间时长、国内普通长途时长、国内IP长途时长等;另一部分是客户基本信息,包括年龄、性别、套餐、是否市区等。将两部分信息整合在一起作为彩铃预测的输入属性,属性列表如表1(表中简列出部分属性)所示,其中“是否彩铃用户”,是输出属性,即预测的目标属性值。
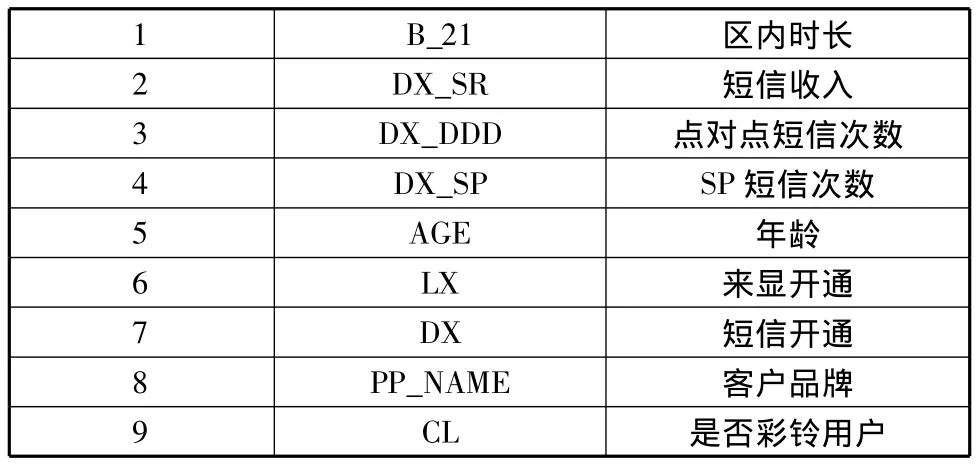
表1 部分属性值
2.2 训练集
从彩铃目标客户中随机抽取其中3 545名客户进行分析,再在非彩铃用户中随机抽取9倍的数据共同组成数据训练集,总共有35 450个用户。数据处理流程如图1。

图1 数据处理流程
图中,数据预处理是指数据训练集通过汇总变换等方法处理成满足属性列表的所需信息;预处理后,计算所有属性的条件熵、信息熵、信息增益,根据这些数值进一步计算出属性的信息增益率以便完成决策树的构造。决策树的各部分是:
根:数据训练集;
枝:分类的判定条件;
叶:分好的各个类;
最后使用IF-THEN语句表达规则集。
2.3 判断规则集
A={B}
A:B的集合,为根;
B:包括所有的训练数据。
从根到叶子节点都有一条路径,这条路径就是一条“规则”:
IF A中的任一元素b同属于同一个决策类则创建一个叶子 ;终止
ELSE 选择特征C={C1,C2,C3,……Cn};判定节点
由此产生预测彩铃开通的17条规则,(括号内数字代表支持该规则的实例数)。这里列举前几个,其它类似。规则1开通彩铃(329)if 区内时长 <=12
and区间时长 <=57
and增值收入 >3.440
and增值收入 <=8.960
and客户品牌in["个人客户""家庭客户"]
and客户消费额 >18.490 and客户消费额 <=26.290
and工作日时长 >4.600 and市区郊县 =郊县
and年龄 >22 and年龄 <=49
and开通短信 =是and联系人数 <=25
then开通彩铃
规则2开通彩铃(63)
if国内IP长途时长 >1 and市区郊县 =郊县
and年龄 <=37 and开通短信 =是and性别 =女and漫游次数 <=1 and联系人数 <=10
then开通彩铃
我们可以从各规则中出现的属性来判断哪些属性对彩铃的开通有显著的影响。分析这17个规则发现,频繁出现的属性有:年龄、性别、联系人数、短信是否开通、点对点次数、漫游次数、区内时长、忙时时长、增值收入、客户消费额等。
例如规则3,彩铃开通的客户包括这样一类人:IP长途时长大于1,37岁以下,开通短信,性别是男性,联系人数24个的郊县人群,支持这条规则的客户有316个。
从规则看,客户的年龄、性别、联系人数、短信功能在预测彩铃规则中起着重要的作用;进而可以分类出什么类型的人可能开通彩铃,什么类型的人不可能开通。
3 预测评估
评估环境:在Windows server 2003操作系统下,使用Microsoft SQL Server 2005作为数据库平台;SPSS Clementine数据挖掘软件作为分析工具。
3.1 预测结果的评估
我们从两方面的指标来评价,一是预测覆盖率,二是预测命中率,如表2所示。其中A代表实际不开通,预测也不开通的用户,B代表实际不开通而预测开通的用户,C代表实际开通而预测不开通的用户,D代表实际开通预测也开通的用户。

表2 预测数据的覆盖率和命中率
覆盖率F:实际开通预测也开通的用户在所有实际开通用户中的占比。

命中率M:实际开通、预测也开通的用户在所有预测为开通的用户中的占比。
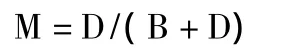
利用SPSS Clementine的分析节点对预测效果进行评估,输入数据为未参与预测的70%样本数据。跟踪观察结果如表3。

表3 预测结果跟踪检验
经过规则集的判别后得到图2的结果,总体正确率为89.57%,符合矩阵中行表示实际值,列表示预测值,0表示未开通彩铃,1表示开通彩铃,我们从符合矩阵中看到,预测开通彩铃实际开通的用户为606个,实际开通但预测不开通的用户有1885个,实际不开通但预测开通彩铃的用户为699个,实际不开通预测也不开通彩铃的有21 585个。根据上文对预测命中率和预测覆盖率的定义,计算出覆盖率为24.3%,命中率为46.4%,通俗的理解这个结果就是,用一半的准确率预测出四分之一的彩铃用户。预测效果基本满意。
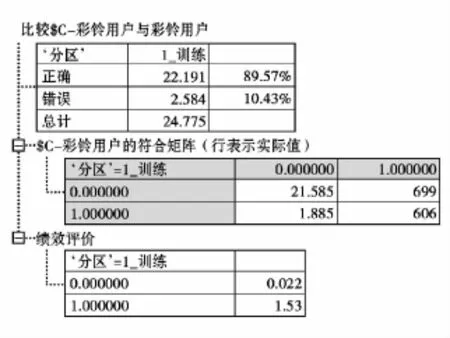
图2 节点分析
3.2 预测结果的跟踪检验
我们跟踪观察预测名单内的客户在今后几个月时间内的彩铃“自然开通率”(即非主动营销开通率),通过判断“自然开通率”来评价在实际环境中的应用价值。
几个月后累计开通数为5 366,达到全部开通数的50%,但预测名单数却只有37 059,只占全部总数的25%,如果这个结果是主动营销的结果,那么预测分类让营销人员用25%的时间做了50%的工作。这就是精确营销的意义和实际价值所在。
4 结论
通过对真实数据的追踪观察结果表明,在真实的预测环境中能将预测准确率保持在较高的自然准确率。今后的工作包括:引进交叉销售的理论,利用关联规则等技术对彩铃用户进行分析,在不同的产品间以及不同的业务间进行交叉销售模式的营销;使其能更有效地运用于电信的其它业务领域,真正用于主动营销指导中。
[1]Abdi Kerim,Chi ZX,Zhang CT.Data Warehouse Optimization Based on Multi-agents Jisuanji Jicheng Zhizao Xitong/Computer Integrated Manufacturing Systems[J].CIMS,2006,9(8):671 -673+697.
[2]曹忠升,薛梅艳.基于决策树的软件分类方法[J].计算机工程.2008(1):56-58.
[3]师江波,胡建华.基于数据挖掘的电信客户流失预测分析[J].山西电子技术,2009(1):50-52.
[4]师江波.客户细分在电信彩铃营销中的应用[D].昆明:昆明理工大学,2009.
