基于相似性搜索的水利普查数据融合
2014-04-30王继民朱跃龙汪卫军李士进万定生
王继民 ,徐 波 ,朱跃龙 ,汪卫军 ,李士进 ,万定生
(1. 河海大学计算机与信息学院,江苏 南京 210098;2. 水利部发展研究中心,北京 100038;3. 南京市社会保险管理中心,江苏 南京 210017)
0 引言
第一次全国水利普查主要查清了中华人民共和国境内(未含香港、澳门特别行政区和台湾地区)的河流湖泊、水利工程、经济社会用水、河流湖泊治理保护、水土保持、水利行业能力建设、灌区及地下水等 8 大项基础信息,为加强水利基础设施建设与管理、实行最严格的水资源管理制度提供了科学权威的数据支撑。
水利单位是结合水利工程设施特性与行业发展规模等各类管理信息,分析水利单位与水利工程设施、资产、从业人员等发展状况的关键节点。因此,厘清水利单位,通过建立水利工程对象的工程管理单位与行业能力的水利单位之间的匹配关系,实现普查水利工程数据与行业能力数据融合,对科学研判水利管理能力和水平具有重要的意义。由于不同专业普查的填报范围规定不同、规范性要求存在差异,因此部分水利单位普查数据存在组织机构代码不完整、重复,不同专业填报的水利单位名称不能完全一致等问题,同时由于水利普查数据量大,直接通过人工方式建立匹配关系费时费力。
根据水利普查中水利单位信息的特点,提出自适应编辑距离相似度量,对传统编辑距离的 3 种操作(插入、删除和替换),设置不同权重,并采用启发式学习算法确定操作的权重向量。采用基于自适应编辑距离的 k-近邻搜索进行水利单位匹配,实现水利工程和行业能力数据融合。
1 自适应编辑距离
1.1 相关工作
水利普查数据中,不同来源的水利单位的相似匹配技术,主要通过单位名称进行相似查询,核心在于字符串的相似度量技术,目的是在字符串数据库中查找与给定字符串相似的字符串,查询对象是字符串。
设 S 代表全体被查询中文字符串数据库,大小为|S| = n,中文字符串 Si∈S,i = 0,1,2,...,n -1;查询字符串为 Q;ε 代表允许的最大误差;D ( ) 表示距离度量函数。按照中文字符串相似性查询结果划分,相似性查询包括以下 2 种:
1)ε 范围查询,给定 ε,在 S 中查询所有满足D(Q,Si)≤ ε 的相似字符串 Si(0 ≤ i ≤ n-1),或者子字符串(结果包括字符串序号 i 及子串的偏移位置);
2)k -近邻查询,在 S 中查询和 Q 最相似的前k 个字符串或子字符串(结果包括字符串序号 i 及子串的偏移位置)。
按照查询方式,相似性查询包括:
1)全字符串查询,查询字符串和被查询字符串进行整体匹配,判断是否相似;
2)子字符串查询,在较长的字符串中,找出与查询字符串相似的子字符串。
字符串相似性查询的核心是选择距离度量函数及子字符串查询中的的子字符串匹配方法,目前较具代表性的字符串相似度量有基于相同字词[1]、编辑距离[2]、向量空间[3]、语义词典[4]、统计关联[5]和语义依存[6]等方法。子字符串的匹配方法包括:动态规划、自动机、位并行和过滤等方法[7]。水利单位匹配关注的是全字符串的 k-近邻查询,即给定查询字符串 Q,在被查询字符串集中查询与 Q 最相似的前k 个字符串,核心是距离度量函数。
1.2 带权重的编辑距离
编辑距离首先由 Levenshtein 提出,假设有 A 和B 2 个字符串,编辑距离定义为把 A 转换成 B 需要的最少删除(删除 A 中 1 个字符)、插入(在 A 中插入1 个字符)或替换(把 A 中某个字符替换成另一个字符)的次数。2 个字符串互相转换需要经过的步骤越多,编辑距离就越远,编辑距离的计算通常采用二维矩阵动态规划的方法。文献 [8]针对中西文混合字符串,采用了将汉字作为西文字符的等价单位计算编辑距离的方法,并从输入法的角度提出采用拼音和五笔编码计算编辑距离的方法,最后给出融合3 种编辑距离计算字符串相似度的算法。文献 [9]采用不同的带权重编辑距离实现中文组织机构简称和全名的匹配。
在原始编辑距离计算中,删除、插入和替换3 种操作的权重完全相同,然而,由于中文表述的特殊性,在组织机构名称中插入或者删除字词,有时候不会对名称的含义产生影响,而替换字词则可能会完全改变原字符串的含义。因此,可以对不同操作设定不同权重,以更加准确地度量字符串间的距离。实验表明,重新设定操作的权重可以在很大程度上提高编辑距离对水利单位匹配处理的适应性。表1 和 2 显示了在权重向量
1.3 启发式权重学习
不同数据集可能对编辑距离的 3 种操作具有不同的敏感性,因此,需要针对不同的数据集,动态调整编辑操作的权重以满足不同特征数据集的实际应用。
本文给出一种基于 k-近邻算法[10]的启发式权重学习算法。训练集包含训练查询集 T1和训练数据集T22 个字符串集。T1中每个字符串都和 T2中的唯一字符串匹配,并且已进行标记,若将 T2中的每个字符串视为一类标记,则基于数据挖掘中分类思想,可以认为 T1中的每个中文字符串所属类知。本文采用“留一法”[11]基于带权重的编辑距离和 k-近邻算法在 T2中搜索 T1字符串的最相似串,并以该最相似串作为匹配的串,计算整体的匹配错误率。不同的编辑操作权重向量计算得到的匹配错误率可能是不同的,对应错误率最低的权重向量将作为当前数据集的最优权重向量。
权重调整的策略为,将间隔 [0, 1]分割成 k 个等间距的子间隔,使用 <0, 0, 0> 作为权重向量起点进行匹配,逐步使用相邻的更大的权重替代,使用训练数据集的匹配错误率作为权重评估函数。在一些情况下,该方法可能产生冗余的权重向量。例如,假设 k =10,权重向量 <0.1, 0.1, 0.1> 和 <0.5, 0.5,0.5> 将产生相同的匹配错误率。因此,约定权重向量中各分量的和必须为 1,算法针对权重向量中的每个分量逐步从 0 按照 1/k 的步长递增到 1,并且只有各分量和为 1 的权重向量才用于评估匹配错误率。搜索最优编辑操作权重向量的过程如算法 1 所示。
算法 1. 寻找能够使字符串匹配性能最优的编辑操作权重向量
Algorithm 1. Searches for the weights that maximize the matching performance
参数:S 为训练字符串集,包括 T1和 T22 部分;

表1 传统编辑距离计算示例

表2 调整的编辑权重向量下编辑距离计算示例
d 为权重向量变化的步长(1/k)。
返回值:P 为最优的权重向量。
se ← sd ← ∞ {se 为最小的错误率,sd 为最优权重向量下查询字符串距离匹配字符串的平均编辑距离。}

while (i >= 0) ∧ (w[i]+ d > 1) {判断是否还有分量可以增加}

在算法 1 中,假设 d = 0.5,即 k = 2,算法将产生如表3 所示的权重向量,并使用 evaluate_error函数评估每个权重向量对应的匹配错误率;evaluate_distance 函数计算查询字符串到最近邻的平均编辑距离 dist,在匹配错误率相同时,算法优先选择最小平均距离对应的权重向量。
2 实验
2.1 实验数据及方法
为了验证自适应编辑距离算法,进行了相关实验。数据来自第一次全国水利普查,选择 2 个省的部分市级水利普查数据中水利工程的管理单位信息,去掉未填记录,通过利用组织机构代码、原始编辑距离进行相似及人工匹配的方式,建立水利工程管理单位信息项和行业能力单位的匹配,并从匹配后的记录中各随机选择 2000 条记录用于实验。由于各省独立开展普查工作,因此数据具有独立性。实验中,针对每个省,以 500 条为步长,随机选择记录作为每步的实验数据,选择测试数据的 30% 作为训练数据,计算最优权重向量,剩余 70% 作为测试数据,计算匹配准确率。

表3 算法 1 产生的有效权重向量(k = 2)
2.2 实验结果
图1 显示随着选择的样本数据的变化,基于原始和自适应编辑距离的匹配准确率的变化情况。基于原始编辑距离直接匹配算法,在数据量较小时,匹配准确率较高,但是随着数据量的增加,准确率降低;基于自适应编辑距离算法的匹配方法,匹配准确率可以达到 80%~85% 之间,由于水利普查数据的数据量巨大,采用此算法进行水利工程和行业能力数据融合可以大大提高工作效率。
3 水利普查数据融合
3.1 水利普查数据融合框架


图1 匹配准确率分析
数据融合就是利用计算机技术将来自多个传感器或多源的观测信息进行分析、综合处理,从而得出决策和估计任务所需的信息的处理过程。水利工程与行业能力普查数据融合就是通过相似性搜索建立行业能力普查单位与水利工程管理单位的一致匹配,实现水利工程和行业能力普查数据的有效衔接,为分析水利发展现状,制定水利及经济社会发展规划等提供支撑。水利工程与行业能力普查数据融合的框架如图 2 所示。首先对行业能力普查和水利工程管理单位名称进行分级处理,提取单位名称中的行政区划信息,建立精简的单位名称;然后利用启发式权重学习得到最优的权重向量;最后利用组织机构代码和单位名称进行名称相似搜索,并结合人工识别,实现水利单位匹配。
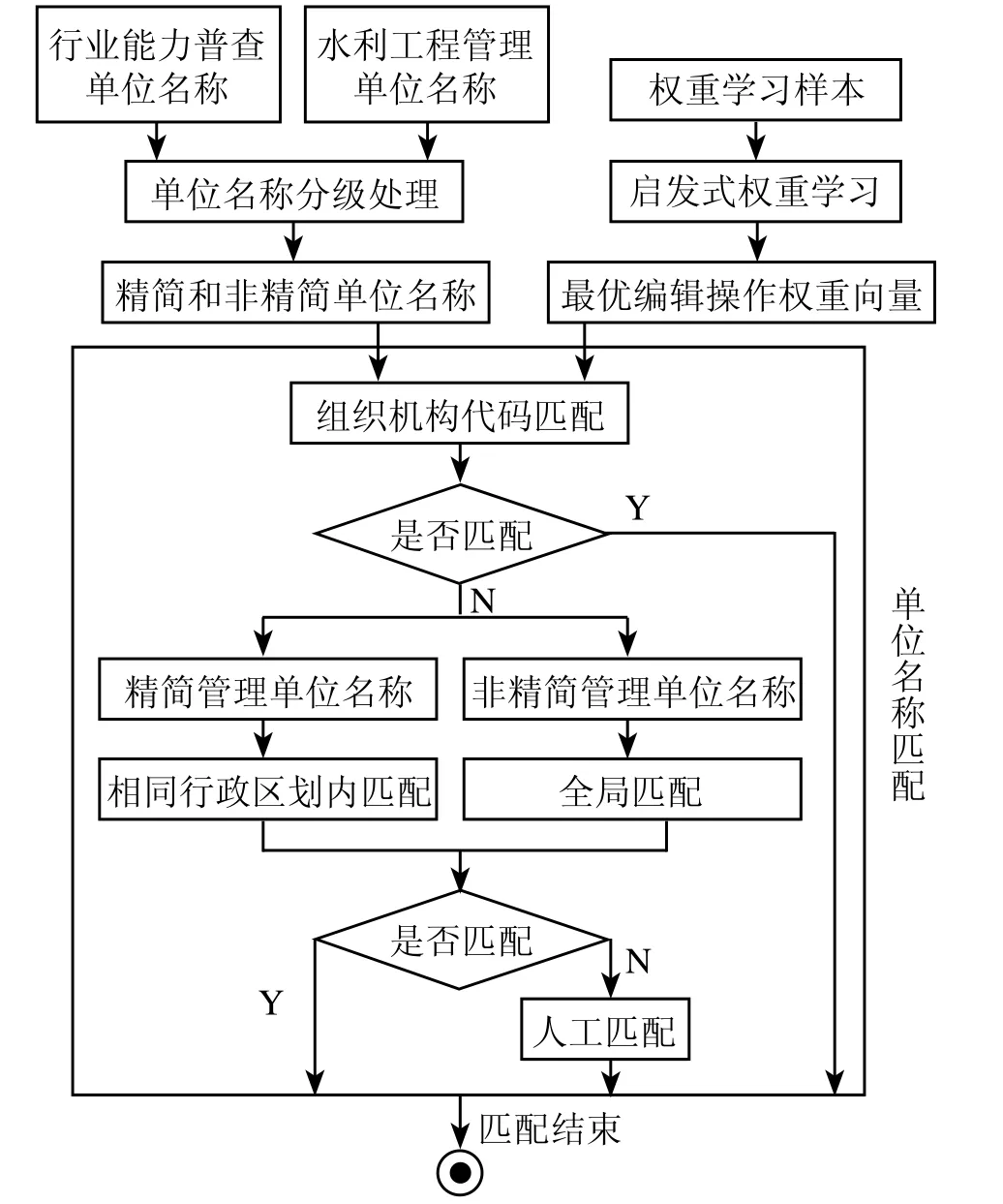
图2 水利工程与行业能力数据融合框架
3.2 单位名称分级
单位名称分级处理是将填报的原始单位名称分解成图 3 所示格式。

图3 单位名称分解
部分单位名称包含行政地名信息,如“宿州市埇桥区解集乡水利工作站”,包含所在市和区的信息,由于普查对象是按照“在地原则”填报的,填报的水利单位名称可能忽略了所在行政地名信息,如写成“解集水利站”,若直接对两者进行相似性匹配,编辑距离较大,容易造成匹配失败。提取单位名称中的行政地名信息,构建分级单位名称,缩小匹配范围将有助于提高匹配的正确率。如,将“宿州市埇桥区解集乡水利工作站”分解成“江苏省”+“宿州市”+“埇桥区”+“解集乡水利工作站”,在相同省市县区域内利用“解集水利站”和“解集乡水利工作站”进行字符串相似性查询,得到的编辑距离变小,容易得到正确的结果。
提取行政区划信息时,按照从左到右的顺序逐一加字成词的方法,如针对“江苏省南京市”,先取“江”字在行政区划数据库中比较核对,若是未登录行政区划,则依次加 1 个字并进行比对,即核查“江苏”是否为已登录行政区划,若为,则判定其为 1 个地名,否则,继续逐一加字进行匹配核查,直到超出最大长度。若碰见“省”、“自治区”、“市”、“州”、“区”、“县”、“旗”等地名“后缀词”,则将此后缀词归为紧挨着前面的地名,将核查出的行政区划名从单位名称中去除,在剩余部分中继续提取下级行政区划名,最低只提取到县级。
部分单位名称不包含行政区划信息,如“黄河水利委员会”,还有些单位名称由于进行了简写,无法解析出分级行政区划,这些单位名称可直接保留其原始填报名称,称为非精简单位名称。
3.3 启发式编辑距离权重学习
选择部分水利普查数据(如 1 个省)作为权重学习数据,对水利单位名称进行分级处理,编辑操作权重向量设定为<1.0, 1.0, 1.0>,按照图 2 中“单位名称匹配”的流程完成水利单位匹配,最后,将成功匹配的水利单位名称作为权重学习样本,基于算法 1 进行权重学习。
3.4 单位名称相似搜索及匹配
经过分级处理的单位名称包括精简和非精简单位名称 2 种,根据普查的“在地原则”,名称包含行政区划信息的单位一般在其名称所包含的行政区划内填报,而名称不包含行政区划信息的单位则无法根据名称确定其填报的行政区划,因此针对 2 种不同的单位名称可以采用不同的处理流程。在单位名称 k-近邻查询中,水利工程管理单位名称组成查询字符串集 Q,行业能力普查单位名称组成查询字符串集 S。进行单位名称匹配时,优先利用组织机构代码进行匹配,然后采用单位名称匹配。
首先利用组织机构代码进行精确匹配,将匹配失败,或组织机构代码未填的单位,利用单位名称,采用相似性搜索进行匹配;针对精简管理单位名称,到 S 中提取与管理单位在同一行政区划内的普查单位名称作为被查询子集,在子集中进行字符串的 k-近邻查询,结合人工识别匹配的单位;针对非精简的管理单位名称,无法判断填报的行政区划,直接将 S 作为被查询集进行 k-近邻查询,结合人工识别匹配的单位名称。为了提高匹配的准确性,可以先以水利工程所在的省或市行政区划内的行业能力普查单位名作为被查询子集进行单位名匹配,若匹配失败,则使用全国的行业能力普查单位名进行匹配。
4 结语
实验证明,对编辑距离的各操作设置不同的权重,可以更加准确地实现字符串的相似性匹配。提出的自适应编辑距离,采用启发式权重学习方法,获得面向具体数据集的最优操作权重向量,并给出基于自适应编辑距离相似性查询的第一次全国水利普查数据融合的处理流程,启发式权重学习和评价采用有监督学习策略,进一步的工作将研究基于半监督和无监督的权重学习和评价方法,提高自适应编辑距离适用性。
[1]Nirenburg S, Domashnev C, Grannes D J. Two approaches of matching in example-based machine translation[C]//Proceedings of the 5th International Conference on Theoretical and Methodological Issues in Machine Translation (TMI-93),.1993: 47-57.
[2]Ristad E S, Yianilos P N. Learing string-edit distance[J].IEEE PAMI, 1998, 20 (5): 522-532.
[3]Salton G, Wong A, Yang Chungshu. A vector space model for automatic indexing[J]. Communications of the ACM,1995,18 (11): 613-620.
[4]LI Sujian, ZHANG Jian, HUANG Xiong, et al. Semantic computation in Chinese question-answering system [J]. J.Comput. Sci. & Technol, 2002, 17 (6): 933-939.
[5]Chatterjee N. A statistical approach for similarity measurement between sentences for EBMT[C]//Proceedings of Symposium on Translation Support System. Washington:IEEE Computer Society, 1999: 15-17.
[6]李彬,刘挺,秦兵,等. 基于语义依存的汉语句子相似度计算[J]. 计算机应用研究,2003, 20 (12): 15-17.
[7]范立新. 改进的中文近似字符串匹配算法[J]. 计算机工程与应用,2006, 42 (34): 172-174.
[8]黄林晟,邓志鸿,唐世渭,等. 基于编辑距离的中文组织机构名简称-全称匹配算法[J]. 山东大学学报:理学版,2012, 47 (5): 43-48.
[9]刁兴春,谭明超,曹建军. 一种融合多种编辑距离的字符串相似度计算方法[J]. 计算机应用研究,2010, 27 (12):4523-4527.
[10]F.Fábris, I.Drago, F.M.Varejão. A multi-measure nearest neighbor algorithm for time series classification[C]//Proceedings of the 11th Ibero-American Conference on AI(IBERAMIA '08). Berlin:Springer-Verlag, 2008: 153-162.
[11]Evgeniou T, Pontil M, Elisseeff A. Leave one out error,stability, and generalization of voting combinations of classifiers[J]. Machine Learning, 2004, 55(1): 71-97.
