一种改进的本体概念语义相似度计算方法
2014-04-16吴星同陈中育
吴星同 翁 燕 朱 婷 陈中育
(浙江师范大学数理与信息工程学院,浙江 金华 321004)
1. 引言
目前,语义相似度的计算被广泛的应用于信息检索、语义Web、自然语言处理等领域。本体在语义相似度的计算中发挥着非常重要的作用。传统的基于本体的概念相似度的计算方法有3种[1-3]:一种是基于语义距离的方法,该方法的基本思想是利用本体结构层次的特点,通过概念之间的距离来量化,这种相似度计算方法比较简单、直观,但是它十分依赖本体的层次结构,本体层次结构构建的好坏直接影响到概念相似度的准确性[4];另外一种是基于信息论的方法,该方法是利用两个概念间最近的共同概念祖先的信息量来衡量语义相似度,在理论上更具有说服力一些,但是这个方法只能粗略地量化概念之间的语义相似度,不能更加细致地区分各个概念语义相似度值[5];最后一种方法是基于属性的方法,该方法就是通过判断两个概念之间的属性集来计算概念相似度的,并且要求对每个概念的属性进行详细而全面的描述,但是这样做的难度相当大。本文综合考虑了上述三种方法的优缺点,并且结合了本体所具有的特质,提出了一种改进的本体概念相似度计算方法,该计算方法在本体层次树结构的基础上,不仅考虑了语义距离、节点深度和节点密度,而且还把概念的有向边类型权重因素考虑进去,使得本体概念之间的语义相似度更加全面,计算结果也更加精确。
2. 本体概述
本体(Ontology)最先是在描述事物的本质的时候出现的,但是随着计算机在人工智能领域的不断发展,就被赋予了一个新的意义。在1998年Studer对本体的定义反映了本体的本质,并且得到了广泛的认可:共享概念模型的明确的形式化规范说明[6]。
一个简单的本体可以使用层次结构表示如图1:
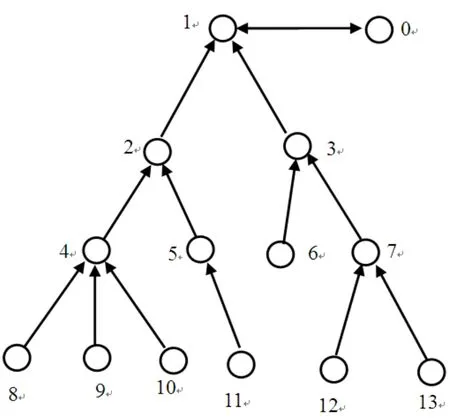
图1 一个简单的本体图
图1中的每个小圆圈代表的就是一个节点概念,每两个小圆圈节点之间的连线就代表着语义关系。自顶向下,概念的划分从大到小,每一层都是对上一层详细的划分,越往下,节点之间的相似度越大。
3. 概念相似度的描述
概念相似度一般来说有着两层意思,一种意思是代表概念之间的相关性,另外一种意思是代表了概念之间具有相似的性质。例如,概念“人工智能”与概念“机器人”的相似性非常高,但是“计算机软件”和“编程语言”,它们虽然没有很高的相似度,相关性却很高。概念相似性反映了概念之间的聚合的特点,而概念相关性反映了概念之间的组合特点[7]。在1998年,lin在信息学的基础上,详细地阐述了广泛意义上的概念相似性的定义,提出了四个相似性直觉,具体描述为:第一,两个概念之间的相似性与他们的共同点有关,如果它们具有较多的共同点,它们就具有较大的相似度;第二,如果两个概念之间显示出很大的差异性的话,那么就表明它们之间具有较小的相似性;第三,如果两个概念不存在差异点,换句话说就是如果两个概念相同的话,则具有最大的相似性;最后,两个概念之间也有可能只存在差异点,而不存在共同点,这样就表示两个概念属于互斥的概念,它们之间的相似性也比较小。
3.1 语义相似度的定义
当两个概念元素具有某些共同特征时,则定义它们是相似的,用sim(x,y)表示概念x,y之间的相似度,在形式上,相似度计算满足[8]:
(1)相似度的值为[0,1]区间中的一个实数,即sim(x,y)∈[0,1].
(2)如果两个对象是完全相似的,则相似度为1,即sim(x,y)=1当且仅当x=y.
(3)如果两个对象没有任何共同特征,那么相似度为0,即sim(x,y)=0.
(4)相似关系是对称的,即sim(x,y)=sim(y,x).
3.2 概念相似度计算模型
本体结构可以用层次树来表示,本文从语义距离、节点深度、节点的密度和有向边的类型这四个方面来全面具体地对概念相似度进行计算。
3.2.1 语义距离
设A和B是本体层次树中的两个概念,则这两个概念节点之间的最短距离定义为语义距离,记做:

其中,weighti表示连接概念节点A和B的最短路径上的第i条边的权值。在语言学研究的领域认为,两个概念节点的语义距离越大,它们之间的相似度就越小;相反,两个概念节点的语义距离越小,其相似度越大。考虑到语义距离对语义相似度的影响,以概念A和B为例,在得到语义距离以后,将语义距离转化为概念语义相似度:

3.2.2 节点深度
节点深度指的是概念节点与树根的最短路径所包括的边数,在本体的树状层次中,每一层都是对上层概念的细化,越到下层,概念的含义越具体。由此可见,在语义距离一样的情况下,两个节点的深度和越大,概念之间的相似度越大,反之亦然。概念节点深度对语义相似度的影响因子为:
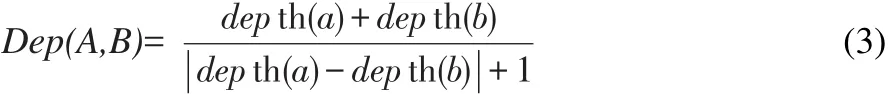
其中,depth(a)和depth(b)分别为概念a和b的节点深度。
3.2.3 节点的密度
在本体的层次结构中,概念的分类一般是从粗到细,从大到小的过程,越往下层本体树中的概念分类则越来越细。节点密度指的是两个概念公共节点的所有子节点的个数(包括孩子节点和孙子节点),一般来说,某个节点的直接子节点的数目越多,密度就越大,表明了概念被细化得越具体,其相似度越大,反之亦然。概念的节点密度对语义相似度的影响为:

其中,degree(Aanc)为2个概念节点最近祖先节点的度,即最近祖先节点的直接子节点的数量;degree(O)为本体树O的度,即本体树O中各节点度的最大值。
3.2.4 有向边的关系类型
在本体中,概念之间不是只有一种类型的关系,关系具有多样性,而在本文中我们只考虑继承关系、实例关系和同义关系着三种最主要的关系。而且不同类型之间的关系就决定了它们之间的概念相似度具有差异性。同义关系有向边两端的概念表示意思相同,即可以理解为两个概念是相同的,继承关系有向边的两端的概念是一个对另一个的细化,子概念虽包含了父概念的所有信息,但是子概念拥有自己不一样的信息,与父概念是不一样的。从以上分析来看,我们不能简单地将本体内的概念间有向关系边视为一样,同义关系的有向边应该比继承关系的边权重更大。关于有向边类型和权重的关系,可以表示如下:

其中Value(c,p)表示由子节点c和它的父节点p所构成的有向边的权重,该计算公式将不同的边类型转换为对应的数值。
如果在树状结构中两个概念的节点通过n条边连接,根据上述公式转化为对应数值后为v1,v2,…,vn,则连接这两个概
4. 改进后的概念相似度的计算公式
在传统的基于距离、基于信息内容和基于属性的基础上增加了节点深度、节点密度和有向边类型等对概念相似度影响结果的因素,使得计算结果更加准确,从而得出改进后的概念相似度计算方法:念节点之间的边的边类型对其相似度的贡献为
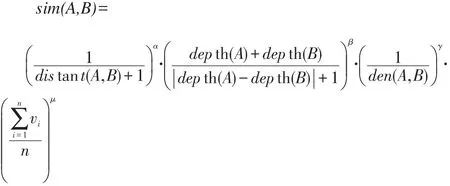
其中,α、β、γ、μ分别表示语义距离、节点深度、节点密度和有向边的关系类型对概念语义相似度影响的权重,且α+β+γ+μ=1。其中语义距离对概念语义相似度的计算结果影响比较大,所以α赋值要大一些,节点深度、密度和有向边类型的影响相对于语义距离要小一些,所以β、γ和μ的赋值比较小。
5. 实验
本文构造了一个“计算机科学本体”来进行实验,结合上述介绍的相似度的计算方法,最后通过java编程来实现概念相似度的计算。因为概念相似度的计算和其它的计算有所不同,所以现在还没有一个规范的专家系统级平台和规范的评估工具。评判一个相似度计算方法的有效性是通过观察实验所得出的概念相似度计算结果和人类的主观判断的吻合程度来实现的。如果吻合程度越高的话,就表明这种计算方法的效率就越高。“计算机科学”的部分领域本体图如图2所示:
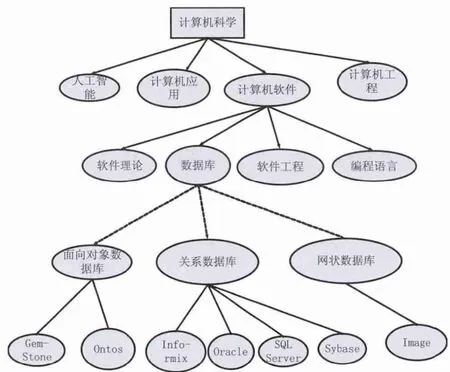
图2 “计算机科学本体”领域的部分本体图
本文采集了30个(相关领域的学者和研究生)关于这些概念相似度的主观判断的数据,通过求这30个数据的平均值,表1中显示的是计算所得出的结果和人们主观判断的结果比较的表格(表1):
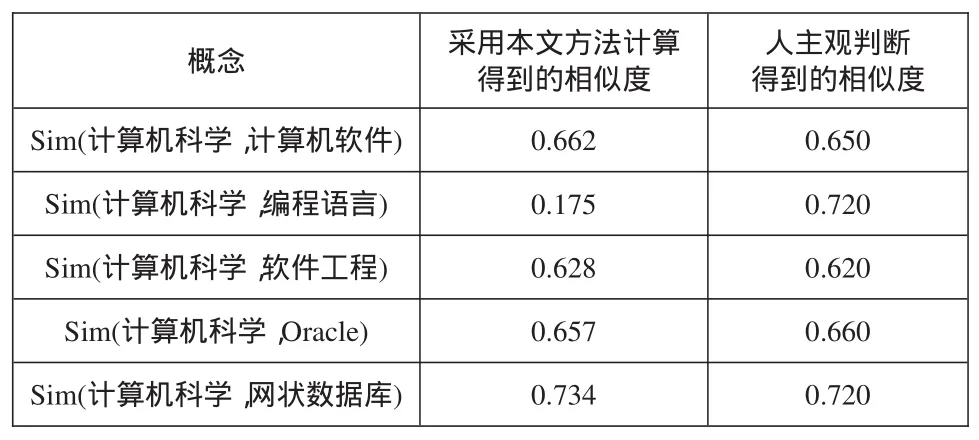
表1 实验结果表(部分)
基于上述表格得出的结论,我们可以通过引入兼容度(compact)这个概念,把计算结果和专家的主观判断对比,从而得出兼容度的值。如果计算结果所得的compact比较大(接近1,0<compact<1),表明和专家判断所得出的吻合度比较高,反之亦然。最后得出二者的兼容度为86.6%,由此可以看出本文计算所得出的两个概念的相似度和人类主观判断的吻合度较高,该方法是行之有效的。
6. 结束语
本文在传统的基于本体的概念语义相似度算法的基础上,把传统的基于信息论算法和基于语义距离的算法的优点进行了集成,这样的好处是既解决了信息论方法语义不确定性的问题,又使得基于语义距离的计算结果更加精确。同时把节点密度、节点深度和有向边的类型这几个影响因素考虑进去,进一步改善了概念相似度算法。从上述的实验结果可以看出,本文的算法和专家主观的经验判断吻合度比较高,使得搜索引擎的查全率和准确度有了一定的提升。
[1]Olivier Steichen,Christel Daniel-Le Bozec.Computation of SemanticSimilarity Within an Ontology of Breast Pathology to Assist Inter- observerConsensus[J].Computers in Biology and Medicine,2005(4):1-21.
[2]Gan K W,Wong P W.Annotation Information Structures in ChineseTexts Using How Net[C]//Second Chinese Language Processing Workshop.Hong Kong: [s.n.], 2000:85-92.
[3]Budan Itsky A,Hirst G.Evaluating Word Net- based Measures ofLexical Semantic Relatedness[J].Computational Linguistics,2004(1):1-49.
[4]Cross V.Fuzzy Semantic Distance Measures Between Onto LogicalConcepts[C]//Processing NAFIPS'04: IEEE Annual Meeting of the FuzzyInformation. Washington DC: IEEE Press, 2004:635-640.
[5]Dela Escalera A, Moreno L E,Sal Ichsm A. Road Traffic Sign Detectionand Classification[J].IEEE Transactions on Indus-trial Electronics,1997,44(6):848-859.
[6]Grnber T R.A Translation Approach to Portable Ontology Specifications[J].Knowledge Acquisition: 1993, 5(2):199-220.
[7]李鹏,陶兰,王弼佐.一种改进的本体语义相似度计算及其应用[J].计算机工程与设计,2007,28,(01):227-229.
[8]李玲.面向流程诊断的企业知识相似度匹配工具研究与开发[D].哈尔滨:哈尔滨工业大学,2006.
[9]杨立,左春,王裕国.基于语义距离的K-最近邻分类方法[J].软件学报,2005,16,(12):2054-2062.
