基于依存分析的离合触发词合法分离形式判定
2014-04-03李勇帆何炎祥
肖 升 ,李勇帆 ,何炎祥
XIAO Sheng1,2,LI Yongfan2,HE Yanxiang1
1.武汉大学 计算机学院,武汉 430079
2.湖南第一师范学院 信息科学与工程系,长沙 410205
1.School of Computer Science,Wuhan University,Wuhan 430079,China
2.Department of Information Science and Engineering,Hunan First Normal College,Changsha 410205,China
离合词是现代汉语中一类特殊的语法现象,说其特殊,是因为除原形外,其构词语素还会因插入、颠倒、省略而产生多种分离形式。由于离合词多为动词,因此在中文事件抽取中,表征事件的触发词也很可能是离合词,本文将这类触发词统称为离合触发词,例如:



例(1)~(14)中,下划线部分均为离合触发词“流血”的合法分离形式,它们与原形“流血”一样都能表征Injure(ACE2005)这类事件。不同的是,前12例在构词语素“流”和“血”之间插入成分后形成V+X+O结构,第13例将语素颠倒并插入成分后形成S+X+V结构,而第14例则省略语素后形成单V结构。由于已有事件抽取方法都将原形作为触发词检索的标准[1],因此想要完整地实现事件抽取,还必须准确判定离合触发词的合法分离形式。
现有语言学成果表明[2-10],离合词虽然数量众多,但所具有的合法分离形式却相对有限,加之在这些分离形式中,各成分间的句法关系清晰且稳定,因此找到一种可将句法关系转化为依存规则的分析方法就能使判定问题迎刃而解。
目前,在中文信息处理中已获成功应用的依存分析方法是获取依存规则的可信赖方法[11-14]。此方法生成的依存框架不仅能充分体现各成分间直接或间接的依存关系,还有助于将依存规则转化为判定规则。为此,本文提出一种基于依存分析的离合触发词合法分离形式判定算法(下文简称判定算法),以期实现离合触发词合法分离形式的自动判定。
1 依存分析
依存分析是构建在依存语法基础之上的句法分析方法。此方法能识别句子内部语法结构并由此突破语表匹配限制,其结果可为自然语言处理中的众多应用提供有力支持。
就中文信息处理的要求而言,哈工大社会计算与信息检索研究中心开发的中文依存句法分析系统较为成熟。该系统的核心是一个融合了词汇支配度的统计模型,该模型不仅能有效应对粗粒度的词性信息,还可以利用词汇支配度获取的结构信息来提高句法结构识别能力和避免非法结构生成[15]。
本课题组通过协议方式获取了“哈工大信息检索研究中心语言技术平台共享包(完整版)”,并对其中开源的依存句法分析模块进行了局部改写,最终形成了本文实验所用的依存句法分析系统。该系统将句子由一个线性序列转化为一棵依存分析树(哈德森树),树中词结点由依存弧联结,弧从支配词指向从属词,弧上标有符合汉语特征的24种依存关系:ATT(定中关系)、QUN(数量关系)、COO(并列关系)、APP(同位关系)、LAD(前附加关系)、RAD(后附加关系)、VOB(动宾关系)、POB(介宾关系)、SBV(主谓关系)、SIM(比拟关系)、HED(核心)、VV(连谓结构)、CNJ(关联结构)、MT(语态结构)、IS(独立结构)、ADV(状中结构)、CMP(动补结构)、DE(“的”字结构)、DI(“地”字结构)、DEI(“得”字结构)、BA(“把”字结构)、BEI(“被”字结构)、IC(独立分句)、DC(依存分句)。经本文系统处理后的句子如图1所示。
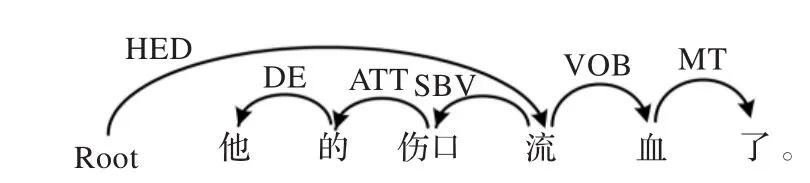
图1 依存分析实例
从图1可以看出,依存分析树具有如下特征:
(1)每条依存弧联结一个支配词和一个从属词;一个词在充当从属词的同时,还可以充当另一个词的支配词;一个词只能充当一次从属词,却可充当多次支配词(如“流”)。
(2)句子的中心结点通常就是句子的核心谓词(如本例中的“流”),此结点只有从属词而没有支配词(Root是遍历树所需的根结点,并非原句成分,不能充当中心结点)。
(3)依存框架中没有非终结点,没有短语结构树中的“扁平结构(flat structure)”,有的是两个词的直接关联,这无疑将有利于细粒度的词汇化表达[15]。
2 判定规则
虽然现有语言学成果已对离合词的合法分离形式及其成因进行了阐述[2-10],但由于缺乏机器应用背景,这些成果都难以直接运用于离合触发词合法分离形式的自动判定。依存分析是经长期实践后被证明能运用于计算机的句法分析形式,课题组通过将其与现有语言学成果结合,形成了如下6条适用于自动判定的判定规则:
规则1(动态助词规则)若三元语法序列MSVF+WDA+MSVS满足:
(1)MSVF、MSVS分别为某离合词的第1、2语素且两者存在VOB或CMP依存。
(2)WDA是动态助词且WDA∈{“着”,“了”,“过”}。
(3)MSVF与WDA存在MT依存。
则MSVF+WDA+MSVS是离合词MSVFMSVS插入动态助词后形成的合法分离形式。该规则的实例如图2所示。
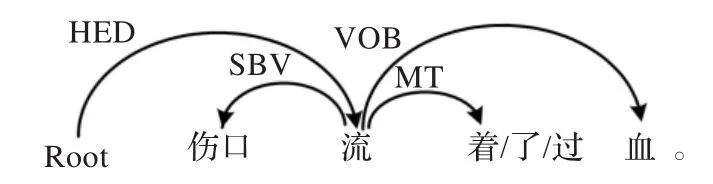
图2 动态助词规则实例
图2显示的例句中,“流”和“血”分别是离合词“流血”的第1、2语素且两者存在VOB依存;“流”与动态助词“着/了/过”之间存在MT依存,因此“流着/了/过血”是“流血”的合法分离形式。
规则2(定补规则)若三元语法序列MSVF+WAC+MSVS满足:
(1)MSVF、MSVS分别为某离合词的第1、2语素且两者存在VOB或CMP依存。
(2)WAC是MSVS的定语且两者存在ATT依存,或WAC是MSVF的补语且两者存在CMP依存。
则MSVF+WAC+MSVS是离合词MSVFMSVS插入定语或补语后形成的合法分离形式。该规则的实例如图3和图4所示。
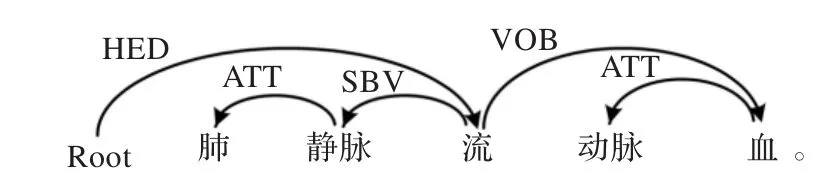
图3 定语规则实例

图4 补语规则实例
图3和图4显示的例句中,“流”和“血”分别是离合词“流血”的第1、2语素且两者存在VOB依存;“动脉”是“血”的定语且两者存在ATT依存;“完”是“流”的补语且两者存在CMP依存,因此“流动脉血”和“流完血”均是“流血”的合法分离形式。
规则3(动助定补规则)若四元语法序列MSVF+WDA+WAC+MSVS、MSVF+WAC+WDA+MSVS或五元语法序列MSVF+WAC+WDA+WAC+MSVS满足:
(1)MSVF、MSVS分别为某离合词的第1、2语素且两者存在VOB或CMP依存。
(2)WDA是动态助词且WDA∈{“着”,“了”,“过”}。
(3)MSVF与WDA存在MT依存。
(4)WAC是MSVS的定语且两者存在ATT依存,或WAC是MSVF的补语且两者存在CMP依存。
则上述三种语法序列均是离合词MSVFMSVS插入动态助词和定、补语后形成的合法分离形式。该规则的实例如图5至图9所示。
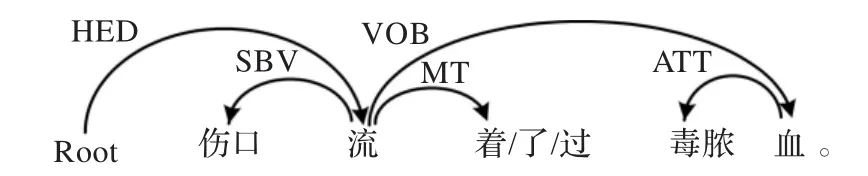
图5 四元动助定语规则实例

图6 四元补语动助规则实例
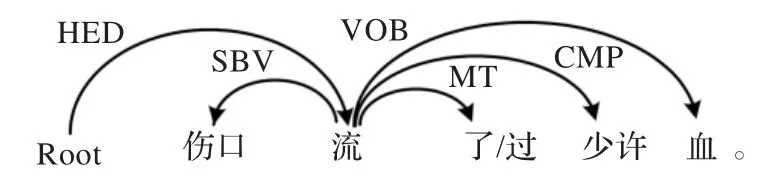
图7 四元动助补语规则实例
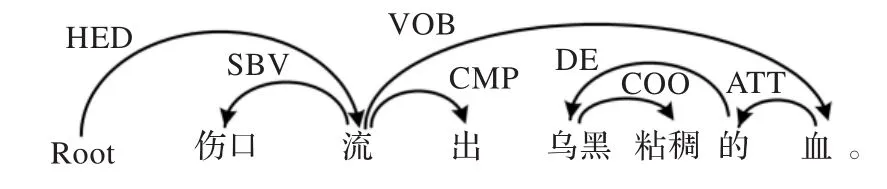
图8 四元定补规则实例

图9 五元动助定补规则实例
图5至图9显示的例句中,“流”和“血”分别是离合词“流血”的第1、2语素且两者存在VOB依存;“流”与动态助词“着/了/过”之间存在 MT 依存;“毒脓”和“乌黑粘稠的”都是“血”的定语且存在 ATT 依存;“出”、“少许”是“流”的补语且存在CMP依存,因此“流着/了/过毒脓血”、“流出了血”、“流了/过少许血”、“流出乌黑粘稠的血”、“流出了乌黑粘稠的血”都是“流血”的合法分离形式。
规则4(叠用规则)若三元语法序列MSVF+M'SVF+MSVS或四元语法序列MSVF+M'SVF+WAC+MSVS、MSVF+WN+M'SVF+MSVS或五元语法序列MSVF+WN+M'SVF+WAC+MSVS满足:
(1)M'SVF=MSVF且两者存在VV依存。
(2)MSVF、MSVS分别为某离合词的第1、2语素且M'SVF与MSVS间存在VOB或CMP依存。
(3)WAC是MSVS的定语且两者存在ATT依存。
(4)WN∈{“没”,“不”}且与M′SVF间存在ADV依存。
则上述四种语法序列均是离合词MSVFMSVS第一语素叠用及插入定、状语后形成的合法分离形式。该规则的实例如图10至图13所示。

图10 三元叠用规则实例

图11 四元叠用定语规则实例

图12 四元叠用状语规则实例

图13 五元叠用规则实例
图10至图13显示的例句中,第2个“流”是第1个“流”的叠用且两者存在VV依存;第1个“流”和“血”分别是离合词“流血”的第1、2语素且第2个“流”与“血”之间存在VOB依存;“毒脓”是“血”的定语且两者存在ATT依存;“不/没”是第2个“流”的状语且两者存在ADV依存,因此“流流血”、“流流毒脓血”、“流不/没血”、“流不/没毒脓血”都是“流血”的合法分离形式。
规则5(颠倒规则)若三元语法序列MSVS+WAD+MSVF满足:
(1)MSVS、MSVF分别为某离合词的第2、1语素且两者存在SBV依存。
(2)WAD是MSVF的状语且两者存在ADV依存。
则MSVS+WAD+MSVF是离合词MSVFMSVS颠倒并插入状语后形成的合法分离形式。该规则的实例如图14所示。

图14 颠倒规则实例
图14显示的例句中,“血”和“流”分别是离合词“流血”的第2、1语素且两者存在SBV依存;“再不”和“泉涌般”是“流”的状语且两者存在ADV依存,因此“血再不泉涌般流”是“流血”的合法分离形式。
规则6(省略规则)若句群S1,S2满足:
(1)MSVF、MSVS分别为某离合词的第1、2语素且两者存在VOB或CMP依存。
(2)S1中包含离合词MSVFMSVS或规则1-5认定的MSVFMSVS的合法分离形式。
(3)S2由 MSVF或 MSVF+WDA构成,其中 WDA是动态助词且WDA∈{“着”,“了”,“过”}。
则MSVF是离合词MSVFMSVS的合法分离形式。
例如,在句群“流不流血?流。”中,由于第1个句子中包含“流血”的合法分离形式“流不流血”(叠用规则),因此第2个句子中的“流”可被认定为“流血”的合法分离形式。同理,在句群“血还流吗?流。”和“流血了吗?流了。”中,第2个句子中的“流”也可被认定为“流血”的合法分离形式。
规则1~规则6都是可信规则,它们组成的规则系统囊括了离合词合法分离形式所有可能产生的依存关系,因此可以保证判定的完整性。若依次运用规则1~规则6均无法判定某语法序列为某离合词的合法分离形式,则可以判定该语法序列不是此离合词的合法分离形式。例如,在“伤口一直流着带血的水。”中,由于“流”与“血”间既不存在VOB、CMP也不存在SBV依存,因此语法序列“流着带血”显然无法满足规则1~规则6的判定条件,因此该语法序列肯定不是离合词“流血”的合法分离形式。同理,在“眼睛充满血后不停流眼泪。”中,“血后不停流”也不是“流血”的合法分离形式。当然,语言学中并无绝对规则,因此可信规则也必定存在反例,但这些反例不应成为反对运用规则方法进行离合触发词合法分离形式判定的理由,下一步需要做的是围绕判定规则来实现判定算法。
3 判定算法流程
离合触发词合法分离形式的判定算法流程如图15所示。
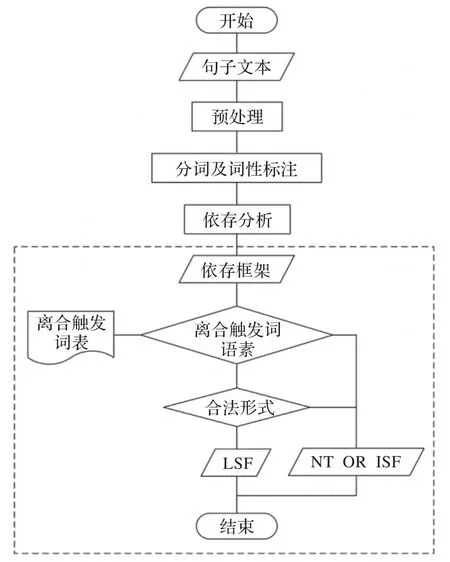
图15 判定算法流程图
从图15不难看出,判定算法将在预处理、分词及词性标注、依存句法分析之后被执行(虚线方框标识部分)。
判定算法的第1步是对依存分析产生的句子依存框架进行储存。由于分词后句中词的个数确切,因此本文在算法实现时选用静态链表作为存储结构。链表结点记录了8种与词相关的信息,其中数据域6种:词形、词性、从属词、支配词、从属关系和支配关系;指针域2种:从属词结点和支配词结点;结点(含根结点)的初始化由函数InitNode()完成,数据域输入由PutInformation()完成;链表结点个数就是分词后句中词的个数。此步骤在实现时首先借助词形匹配定位每个词的从属词结点和支配词结点,然后通过指针互指使具有依存关系的词结点互联,最后链入根结点并由此完成对依存框架的树状储存。
判定算法的第2步是候选词语序列识别,所谓候选词语序列是指依存框架中完整包含离合触发词语素的词语序列。此步骤需要通过与储存在文件中的离合触发词表进行比对才能完成,若识别成功则进入下一步判断,若不成功则输出NT(No Trigger),判定算法就此结束。
判定算法的第3步是合法分离形式判定,即根据判定规则1~规则6判定第2步确定的候选词语序列是否为某离合触发词的合法分离形式。此步骤在实现时依次扫描储存在静态链表中的词结点,若某两个词结点的词形分别与某离合触发词的第1、2语素匹配,则调用判定规则1~规则4对两结点间的语法序列进行判定;若某两个词结点的词形分别与某离合触发词的第2、1语素匹配,则调用判定规则5对两结点间的语法序列进行判定;若某词结点的词形与某离合触发词的第1语素匹配,且其后无与第2语素匹配的词结点,则调用判定规则6对其进行判定;当某语法序列已被判定为合法时,为提高算法效率,不再调用其他规则而直接终止本次判定。若判定直接终止,则表明该候选词语序列是某离合触发词的合法分离形式,输出LSF(Legal Separation Form);若判定未直接终止,则表明该候选词语序列不是某离合触发词的合法分离形式,输出ISF(Illegal Separation Form)。无论最终输出LSF还是ISF,判定算法都将到此结束。
判定算法的实现不仅使判定规则在机器中得以运用,也为后期基于真实文本的语料测试扫清了障碍。
4 实验及其分析
为测试判定算法的效率,课题组开展了基于语料库的半自动化实验,实验沿用ACE2005定义的测试事件,测试事件的离合触发词表经如下两步生成:
(1)通过协议方式获取哈工大社会计算与信息检索研究中心研发的《同义词词林扩展版》(共77343条),从中选取与测试事件相关的触发词组成候选触发词表(共1584条),选词时既要利用词林对同义词和近义词的扩展来尽可能完整地收录触发词,也要注意排除下列3类触发词的干扰:
①关联事件触发词。例如,恋爱是婚姻的关联事件,但恋爱不等于结婚,因此“谈爱”、“相恋”等关联事件触发词不应被当做婚姻事件触发词收录。
②衍生事件触发词。例如,祭奠是死亡的衍生事件,虽然有祭奠一定意味着有死亡,但两者的行事主体并不相同,因此“吊唁”、“奔丧”等衍生事件触发词不能被收录。
③引申事件触发词。例如,除教学事件外,“下课”还可引申表征辞职事件(如“球队主帅被迫下课。”),因此“下课”是辞职事件的引申事件触发词。但目前计算机还不能有效识别引申义,因此引申事件触发词应被排除在外。
(2)将获业界认可的《现代汉语离合词用法词典》的离合词表(共4029条)与候选触发词表作比对,取两者交集为测试事件的离合触发词表(共277条),该词表如表1所示。
从表1可以看出,在ACE2005定义的8大类33小类测试事件中,除Charge-Indict和Extradite外,其他31小类都涉及离合触发词,这充分印证,离合触发词是中文事件抽取中不可回避的问题。此外,就表1中离合触发词的语法用途而言,13条联合型中的10条及2条偏正型可作为动宾型使用(如“游1次行”、“上过3次诉”等),联合型中剩余的 3 条(“倒卖”、“盗卖”、“租用”)可作为动补型使用,因此,本文基于动宾和动补关系制定的判定规则不仅简洁而且可靠。
实验所用的测试语料库同样以协议方式从哈工大社会计算与信息检索研究中心获得,库名为《汉语依存树库》。该语料库是提升哈工大依存句法分析系统效率的基础,将它作为测试语料库,对以哈工大系统为内核的本文实验系统而言,显然可以最大限度地减少因依存分析错误而带来的负面影响。同时,该语料库中的语料均属新闻文体,事件在此文体中的表达清晰规范,因文体引发的分析错误可被大大降低。该语料库以XML格式储存,占储空间16.7 MB;按句子标号sent id统计,其语料规模为9999句。
本文实验用准确率(Precision)、召回率(recall)和F值(F-Measure)来测试判定算法的效率,其中:
(1)Precision=机器正确判定的离合触发词合法分离形式数目(简称机器正确判定数)/机器判定的离合触发词合法分离形式数目(简称机器判定数)。
(2)recall=机器正确判定数/人工判定的离合触发词合法分离形式数目(简称人工判定数)。
(3)F-Measure=(2×precision×recall)/(precision+recall)。
为采集效率测试所需的数据,本实验完成了如下3步:
(1)在解析、检索、去噪等预处理之后,逐句对语料进行人工排查,确定其中共有2974个句子包含离合触发词,离合触发词总数为3146条,在这3146条离合触发词中有2267条(即人工判定数)产生了合法分离形式,比例达72.1%。
(2)调用判定算法对语料进行机器分析,结果显示,语料中共有2435个离合触发词的合法分离形式(即机器判定数)。
(3)对机器判定数进行人工核查,确定其中共有2002个确为离合触发词的合法分离形式表(即机器正确判定数)。
将上述数据代入相应公式计算得Precision=82.2%、recall=88.3%、F-Measure=85.1%,这说明,本文判定算法能在较高召回率的前提下获得不错的准确率。若进一步考察合法分离形式在8大类测试事件中的分布(如表2所示)。

表1 测试事件的离合触发词表1)

表2 离合触发词合法分离形式在测试事件中的分布 条
离合触发词的合法分离形式在不同事件类别中的分布并不均衡,若以人工判定数为标准计算,则有的分布密集,如Transaction类事件中,离合触发词产生合法分离形式的平均值高达18.6个/条;有的分布适中,如Conflict、Life、Contact、Justice、Personnel类事件中,平均值为5.1~8.5个/条;有的分布稀疏,如Business、Movement类事件中,平均值仅为2.2~2.6个/条;如果去除Business、Movement这2类可能引发数据稀疏的数据后重新计算,Precision=82.4% 、recall=88.7% 、F-Measure=85.4% ,比去除前略有提高,可见,本文的判定算法不仅高效而且可靠,已基本具备应用潜质。
此外,机器判定过程中的下列错误也值得关注:
(1)分词错误;此类错误会影响离合触发词合法分离形式的识别。例如,将“包龙图 /梦断 /金蝉 /案。”错误地切分为“包龙图 /梦 /断 /金蝉 /案。”就会将“断金蝉案”误认为是“断案(Convict)”的合法分离形式。又如,将“空调 /开 /一小会 /关 /一小会 /浪费 /电。”错误地切分为“空调 /开 /一 /小会 /关 /一 /小会 /浪费/电。”会将“开一小会”误认为是“开会(Meeting)”的合法分离形式。
(2)语义错误;此类错误将影响离合触发词合法分离形式的统计。例如,将“热得要人命”、“胸口挂着大红花”中的“要人命”和“挂着大红花”分别误认为是“要命(Die)”和“挂花(Injure)”的合法分离形式都将影响时间式计数。
(3)依存分析错误;该错误将会影响离合触发词合法分离形式的判定。例如,在“《星辰》创内刊发行量新高。”中的“创”应和“新高”之间存在动宾依存,但如果将其与“内刊”之间错误地分析为动宾依存,则会导致“创内刊”被误判为“创刊(Start-Org)”的合法分离形式;又如,在“治污办强化地板厂环保意识。”中“强化”应和“意识”之间存在动宾依存,但如果将其与“地板”之间错误地分析为定中依存,则会导致“办强化地板厂”被误判为“办厂(Start-Org)”的合法分离形式。
上述问题显然难以通过句法层面的依存分析全面解决,因此如何拓展语义层面的依存分析必将成为提升判定算法效率的主要后继问题[16]。
5 结束语
作为一种基于规则的判定方法,规则在本文方法中所起的作用至关重要。由于研究对象相对封闭,课题组从已有语言学成果中人工提取了判定所需的依存规则,实验结果表明,这些规则的作用令人满意。可以预见,随着语言学研究的逐渐深入,语言学成果将日益丰富,越来越多可靠的新规则将被挖掘并被纳入规则库,基于规则方法的效率也将有机会获得进一步提升。但与此同时,还必须清楚地意识到,人工方法虽然有效但耗时费力,当研究对象扩大到一定范围时,单纯的人工方法已不可能穷尽所需规则,因此,如何在人工方法的基础上引入机器学习方法,并借此提高依存规则的提取效率将是后期值得着重研究的问题。
[1]肖升,何炎祥.基于动词论元结构的中文事件抽取方法[J].计算机科学,2012,39(5):161-164.
[2]马玉蕾,陶明忠.构式语法视角下的离合词[J].当代外语研究,2012,3(6):14-18.
[3]周清艳.特殊“V个N”结构对VN的选择和制约条件分析[J].世界汉语教学,2012,26(1):85-93.
[4]蔡淑美.“X+V+Y+的+O”的事件结构及句法、语义限制[J].语言科学,2011,10(4):375-384.
[5]王海峰.基于语料库的现代汉语离合词语义特征考察[J].河北师范大学学报:哲学社会科学版,2010,33(1):96-100.
[6]王海峰.现代汉语离合词离析现象语体分布特征考察[J].语言文字应用,2009,18(3):81-89.
[7]王海峰.离合词离析形式A×B的构式特征[J].汉语学习,2009,30(1):31-35.
[8]李春玲.离合词研究综述[J].沈阳师范大学学报:社会科学版,2008,32(1):127-130.
[9]任海波,王刚.基于语料库的现代汉语离合词形式分析[J].语言科学,2005,4(6):75-87.
[10]饶勤.动宾式离合词配价的再认识[J].语言教学与研究,2001,23(4):57-63.
[11]肖升,何炎祥,李勇帆.基于依存分析的中文时间表达式类型判定[J].计算机应用,2013,33(6):1582-1586.
[12]孙艳,周学广,付伟.基于依存关联分析的情感词扩展[J].北京邮电大学学报,2012,35(5):90-93.
[13]王素格,吴苏红.基于依存关系的旅游景点评论的特征—观点对抽取[J].中文信息学报,2012,26(3):116-121.
[14]付剑锋,刘宗田,付雪峰,等.基于依存分析的事件识别[J].计算机科学,2009,36(11):217-219.
[15]刘挺,马金山,李生.基于词汇支配度的汉语依存分析模型[J].软件学报,2006,17(9):1876-1883.
[16]肖升,何炎祥.事件超图模型及类型识别[J].中文信息学报,2013,27(1):30-38.
