基于空间向量模型的先秦文献相似性研究
2014-03-21屈探春
屈探春
(南京师范大学 文学院,江苏 南京 210097)
基于空间向量模型的先秦文献相似性研究
屈探春
(南京师范大学 文学院,江苏 南京 210097)
本文基于空间向量模型,利用TF-IDF值,对《楚辞》、《公羊传》、《管子》、《谷梁传》、《国语》、《韩非子》、《老子》、《礼记》、《论语》、《吕氏春秋》、《孟子》、《墨子》、《商君书》、《诗经》、《孙子》、《武子》、《孝经》、《荀子》、《晏子春秋》、《仪礼》、《周礼》、《周易》、《庄子》、《尚书》和《左传》等二十五本先秦文献进行了相似度计算,通过分析文本的相似系数,考察文本间的相似程度和文献本身的特殊性。最终发现:部分文献用词较为封闭,用语风格独树一帜;部分文献用词则包容性,与其他文本的一致性较高。
先秦文献 相似性 向量空间模型 TF-IDF值
古汉语研究中,文本作者考证、著作年代探究等都是学者们的研究重点之一。他们常常从文本风格、用词特征等角度出发,通过比较同时期的同类作品或者寻找词语源流演变的轨迹等方法来探寻文献创作者,确定文献创作年代或判别文献真伪。这类研究中,古汉语研究者多依赖于文献典籍或考古文物等资料,以此为据作出相应的假设或者是论证已有假设。本文则主要利用自然语言处理中的相似度计算方法,通过计算文献间的相似系数来判断彼此间的相似程度。主要考察了《楚辞》、《公羊传》、《管子》、《谷梁传》、《国语》、《韩非子》、《老子》、《礼记》、《论语》、《吕氏春秋》、《孟子》、《墨子》、《商君书》、《诗经》、《孙子》、《武子》、《孝经》、《荀子》、《晏子春秋》、《仪礼》、《周礼》、《周易》、《庄子》、《尚书》、《左传》这二十五本文献,在统计各文本的词频、词长等基本数据的基础上,计算彼此间的相似系数,分析相似情况。
一、相似度计算与面向空间的向量模型
(一)相似性计算
相似度计算在中文信息处理中较常使用,它多服务于文本分类和文本聚类,同时也在某种程度上依赖于文本分类和聚类,常用的特征项选取方法--信息增益(IG)就需依先前预定的分类情况来计算。无论是文本分类还是文本聚类,都需用一定的特征项来表示文本,也就是所谓的文本表示,其中特征项的选择是基础。依据是否需要类别信息,特征选择可分为有监督和无监督两种,文本分类多采用有监督特征选择方法,而文本聚类则多采用无监督特征选择方法,当然也有很多学者为了达到更高的选择精度而尝试把类信息融入到文本聚类中,使用有监督学习方法中的信息增益来寻找文本中最具分类能力的特征运用于文本聚类。本文主要是对先秦二十五本文献进行聚类分析,在未预测各文本间的分类情况的基础上计算每两本文献间的相似性,将其与人们的主观归类进行比较,分析其差异。由于是在未知类信息的情况下进行的研究,所以主要通过无监督特征选择方法中的文档频率来控制特征项的选择,同时从传统的TF-IDF值出发,充分考虑古典文献的文本特征,通过实验选取合适的阀值进一步提取特征项,利用空间向量模型计算各文本间的相似度。
(二)面向空间的向量模型
计算对象相关度的常用模型主要有空间向量模型和集合运算模型等。由于后者的局限性比较大,所以常用向量空间模型来计算文档相似度。
向量空间模型是20世纪60年代由Salton等人提出的,该模型利用从文本中提取出的特征项的集合来概念化地表示整个文档,并且依据每个特征项在文档中的重要性来赋给不同的权重,也就是说一个未分类的文本就是一个由各个不同权重的特征项表示的向量,每个特征项代表向量中的一个维度,其中特征项既可以是文档中的词语也可以是短语还可以是单个的字。例如:假设存在一个文档D,它由t1,t2,t3……tn这样一些特征项组成,且各个特征项的权重分别为w1,w2,w3……wn,那么文档D就可以表示为D(t1,w1;t2,w2……tn,wn)。但需要注意的是,在空间向量模型中,各特征项必须是互异的,且假设各特征项之间不存在先后顺序。基于这两个条件,特征项t1,t2,t3……tn就可被简单地看作是一个n维的坐标系,而权重w1,w2,w3……wn则可看作是对应维度的坐标值,那么,一个文档便可以表示为一个n维的空间向量。D(w1,w2,w3……wn)就是该文本的空间向量模型,如右图。
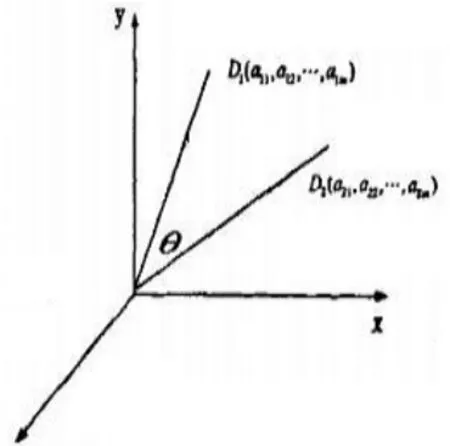
利用空间向量模型,文档的相似度可以通过向量间的相关程度来度量。假设任意两个文本D1和D2,那么这两个文本可以用向量D1(w11,w12……w1n)和D2(w21,w22……w2n)来表示。从上图可以看出,如果两个文档也就是两个向量之间关系越靠近,那么它们两者形成的夹角θ也就越小,相应的cosθ就越大。因而,可以利用两者夹角的余弦值来表示文本的相似系数:
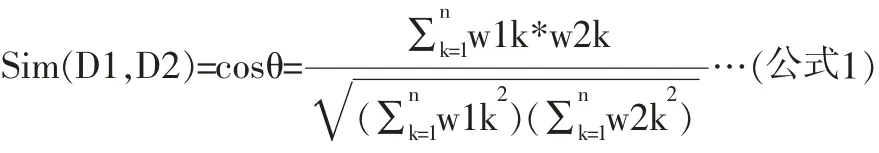
二、实验操作
本文利用上面所介绍的空间向量模型对先秦的二十五本文献进行了相似度计算,文本的原始资料来源于李斌等人的《Corpus-Based Statistics of Pre-Qin Chinese》一文,在实验过程中,我们首先对原始数据进行预处理,结合古代汉语的特点删除或者保留相应数据。在此基础上计算各词语的TF-IDF值,结合词语的文档、频率选取特征项。最后,根据特征项的权重计算文本相似度,制作图表。
(一)预处理
古代文献多以单字词为主,但是也有多字词的存在。在此需要声明的是,本文以词为特征项,从词出发计算文本相似度。在对统计所得的原始资料进行处理时,我们充分考虑了古代汉语的语词特点,删去某些无用信息,保留相应的数据。
首先,去标点符号。由于现代人所使用的古代文献版本多为后人的注本,所以其中不免参杂了一些现在文本的信息。古代文本不存在标点,所以在预处理的过程中首先要将标点符号相关的数据资料删去,以避免处理过程中无关信息的干扰。
其次,保留相同语词的不同词形。古代汉语文本中存在许多同义异形词,对现代汉语而言这可能是一种用语不规范的问题,但是对古代汉语而言,同义异形词也反映了一定的文本风格,体现了作者的创作习性。同时,也是不同时代用词情况以及词语发展演变情况的映射。因而,在文本预处理的过程中,我们保留了不同的词形,把它们当作不同的条目来处理,例如:将“爲”和“為”列作两个条目。
再次,保留相同词形不同词性的词语。古代汉语中大量存在词类活用的现象,而在不同时期的不同文本中活用的情况不同,这也是古汉语不同时期语言演变的特点之一,所以,我们也将不同词性相同词形的语词分作不同的条目进行处理。如:将“食(n)”和“食(v)”作为两条词项。
(二)基于VSM的TF-IDF值计算
从统计特性的角度来看,判断词对于分类提供的信息量的大小主要有两条标准:(1)一类文章中出现频繁,而其他文章中出现不多的词提供较多的分类信息;(2)在多类文章中均出现频繁的词含有较少的信息量。上文已经提到利用权重来表示特征项在文本中的重要程度,并以此计算文档相似度,而权重的计算则要通过TF-IDF公式计算获得,TFIDF也正是在考虑了上述两条标准。TF-IDF的基本思想就是把一个文档分成两个部分,一部分是带有文本特征信息的,而另一部分则是不带或者基本不带文本分类信息的。各部分中所带的文本特征信息的多少以及该信息在文档中的重要性则是通过TF和IDF以TF*IDF的方式来衡量。其中,TF表示绝对词频,指一个词在某一篇文档中出现的频率,该频率越高,说明它区分文档的能力也就越强。IDF指的是倒排文档频度,利用公式计算,表示一个词在不同文档中出现的范围越广,它区分文档的能力就越低。利用TF-IDF公式可以寻找出频率不高但是区分能力很强的一些特征项。TF-IDF值计算公式如下:

本文在通过统计所获得的词频信息的基础上利用该公式对各文本中的每一个词语的TF-IDF值进行计算,为之后的特征选取以及相似度计算提供前提信息。
(三)特征项的选取
特征选取的主要作用是降维。在向量空间模型中,如果维数较大,也就是表示文本的特征项较多,那么不可避免会带来很大的噪声信息。而这些噪声信息不仅对于文本表示不起积极作用,更会增加机器处理的工作量。因而用特征项表示文档,不仅不会使重要的文本特征信息流失还可以达到减少机器处理的工作量的目的,从而提高效率。
本文的处理对象是古代汉语文本,其本身具有较大的特殊性,所以在特征项选取时,不仅仅要考虑除去噪声和降低维度,另一重要任务是使文本之间词例的频度达到平衡,不能产生过大的差距,如果差距过大势必会影响文本之间的相似性程度。为了选取最佳特征项,我们充分考虑了各文本的特殊用语特点,针对这些特征进行多重选择,并依据某些文本的语言特色,特殊对待个别文本,进行特殊化处理。主要的筛选步骤如下:
首先,将计算得到的TF-IDF值为0的词语去除。与现代汉语相同,分布较广或者涵盖所有文本的特征对某一特定文本的代表性不高,所具有的文本信息也相对匮乏,对该文本与其他文本的区分度或者相似度的贡献值较低,所以在选取特征项时不加考虑。
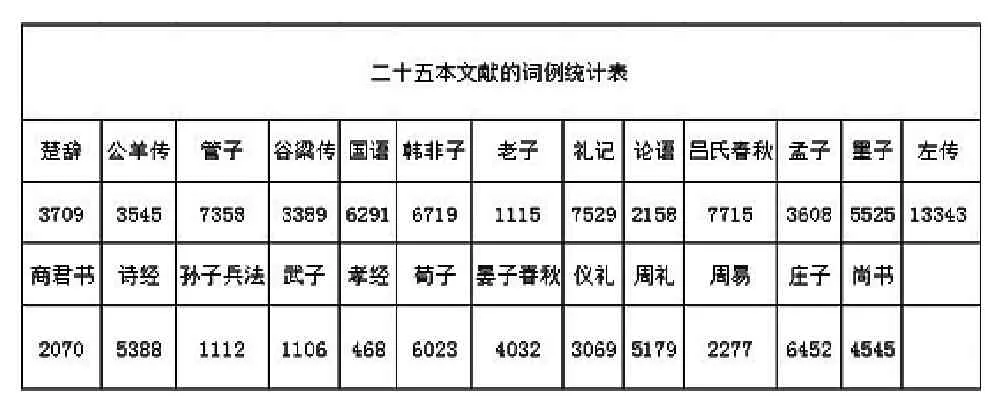
其次,仍从TF-IDF值出发,依据二十五本文献的词语频度以及彼此间词例数量的差异程度选取阀值,根据阀值删除对文本表示贡献度较小的语词,使各文本的特征项数量达到平衡。经实验表明,将阀值定为TF-IDF值等于0.00005时,效果最佳。如下面的“二十五本文献词频表”所示,未经筛选之前(已经过预处理),各文本的词语个数差异较大,其中《孝经》总共包含468个词例,而《左传》则达到了13343个,两者差距较大,即使删去TF-IDF值为0共同词例也无法真正达到平衡。
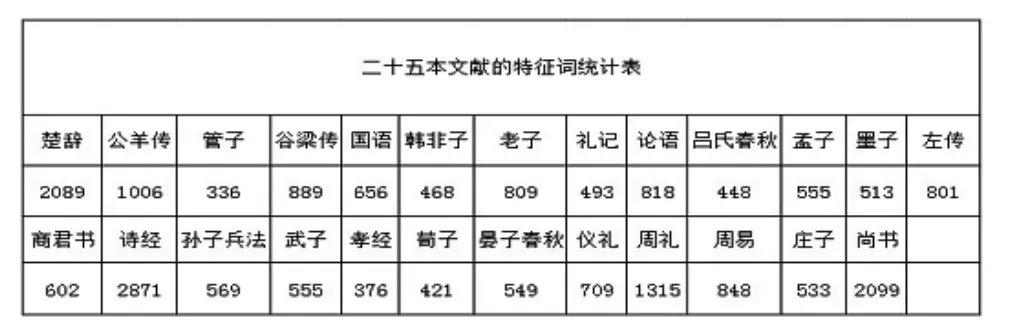
相比之下,以wij=0.00005为阀值进行筛选之后,所得结果中,各文本的词例个数的差距显著下降。如下面的“二十五本文献的特征词统计表”所示,《孝经》的特征词数量为376个,相比未筛选数据减少了92个;而《左传》的特征词数量为801个,比未进行筛选时减少了12542个,所降维度较大,经处理后,两者差距明显缩小。就整体而言,筛选后的数据差异幅度较小,80%的词例的频度在300850之间,仅有两例的词频达到了2000以上。
除了为了使各词例的出现频度达到均衡之外,将各文本的降维阀值设定为0.00005的原因还在于,降维前后文本间相似度的改变程度十分微小,不会对文本间的相似性关系的挖掘产生不利影响。以《公羊传》和《礼记》为例,两者在未降维之前相似度为0.0749,经降维处理之后相似度变为0.0786。而《庄子》和《韩非子》在未降维之前的相似度为0.1875,经降维之后为0.1845。两者都只有很微小的改变,这种改变并不会对文本间的相似性产生重大影响。
(四)文本相似度计算
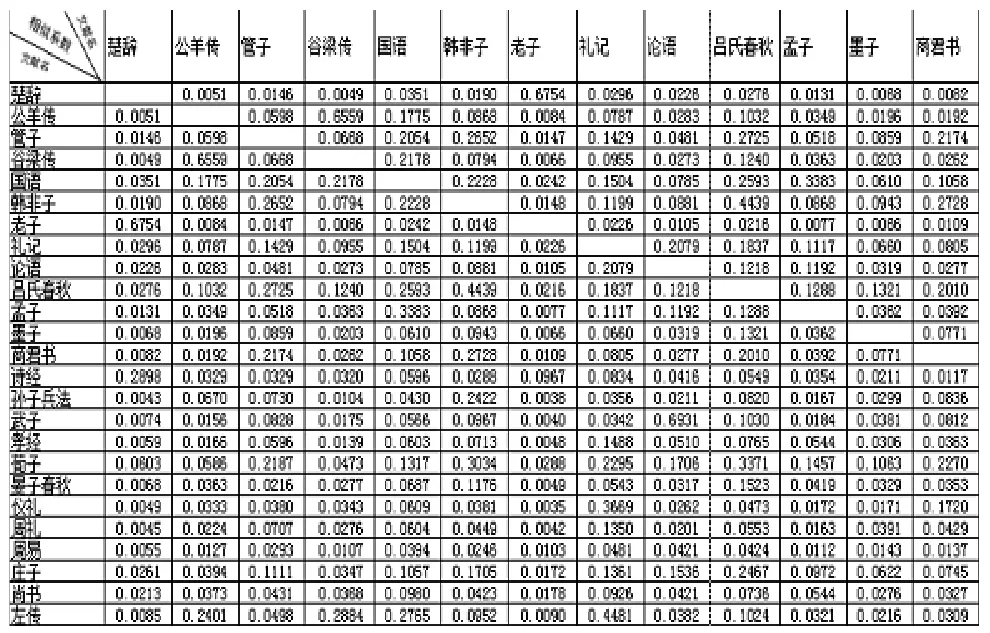
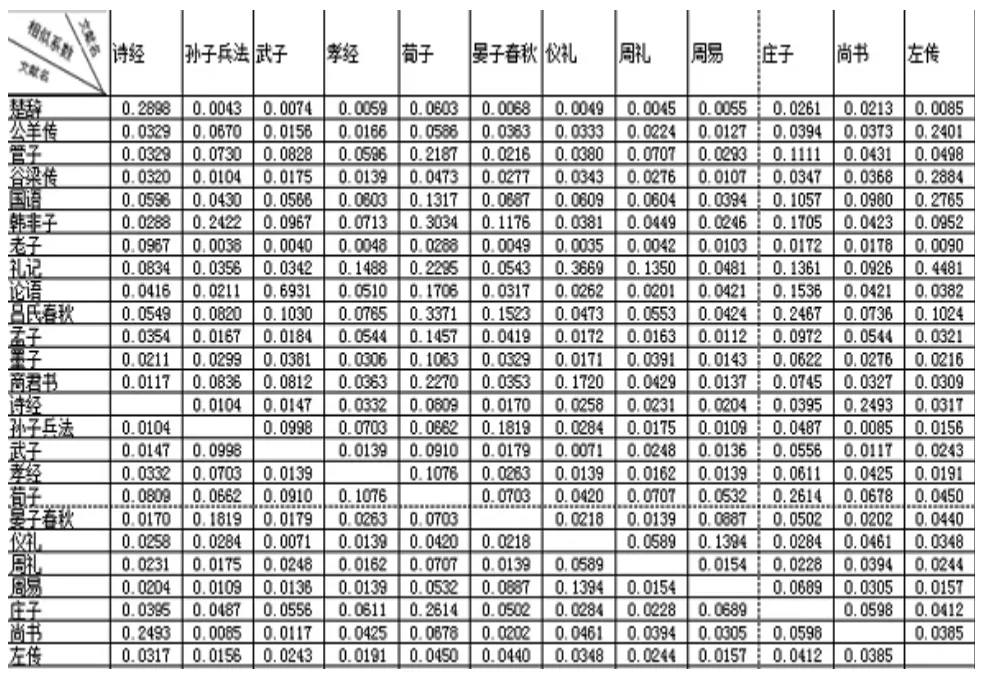
文本相似度是表示两个或者多个文本之间的匹配程度的一个度量参数,相似度越大,说明文本相似程度越高,反之越低。本文利用上述所述的方法筛选得出的特征项来表示文本,根据各特征项在不同文本中的权重,用公式(2)分别计算每两个文本之间的相似系数,所得的具体参数如下表。
三、实验结果和分析
实验的对象是先秦二十五本文献,各文献所属类别不同,部分差异较大,若暂不考虑古汉语研究中对这二十五本文献所持的观点,仅从本文相似度计算所得的数据来观察,我们发现了这样一些特点和文本间的相关关系。
首先,各文本相似性差异较大,部分文本只与某一个或者两个文本相似度较大,与其他文本的相关性很小,如:《老子》、《公羊传》、《谷梁传》和《楚辞》等,其中《老子》和《楚辞》仅彼此间相似度较高,与其他文本的相似度接近于0,值得注意的是,和其他文本的相似系数相比,《老子》和《楚辞》同《诗经》的相似系数都要高一些。另有一部分文本则恰恰与此相反,它们约与一半以上的文本较为相似,只与少数文本有较大差异,如:《庄子》、《韩非子》、《管子》等。还有一部分文本是与其他文本也有一定的相关度,但是尤以某一本较为突出,如:《武子》与《论语》,《尚书》与《诗经》,《周易》与《仪礼》等。
其次,本文是通过词频来计算相似性的,所以相似系数在某种程度上反映的是各文本在用语方面的相关性。那么,从用词角度来讲,部分文本的语言较具特色,如《老子》,它几乎只与《楚辞》和《诗经》相关,可见其用词风格的独树一帜。虽然在内容和思想方面,《老子》和《楚辞》、《诗经》大相径庭,但是在用语上两者却又较为相似,这可能与《老子》一书多采用四字格、三字格等较为精炼的语句且多用对偶形式有关,这与《楚辞》的体式非常相似。二十五本文献中,除了用词特殊的文本之外,也有具有很大包容性的文本,可以说某些文本的用词是兼容并包的,它们与大部分文本相似,如:《商君书》、《荀子》等。这一方面说明在本文分析的二十五本文献中,与该文本用语相似的文本较多,另一方面也说明了,该文本的用语较为通俗,为许多其他作品所共有。如《吕氏春秋》这一本百科全书式的著作,内容包含甚广,且由吕不韦众多门客的作品编辑而成,这势必会使其在用语和言语分格上呈现兼容并包的特点,这就使得其与其他各类题材的文本有较大的相似性。
最后,通过分析各文本的相似度关系折线图,会发现词语包容性较小的文本,与其相关的文本数量也相对有限且与不同文本比较所得的相似系数差异也较大,因而聚类相对容易。通过对相似文本较少的文本的分析,我们发现可对其作如下归类:《公羊传》和《谷梁传》同属一类,它们与《左传》的语言风格最为接近。《楚辞》和《老子》可归为一类,两者与《诗经》具有很大的共同点,但是《诗经》一书中又融合了较多其他文本的特点,与《老子》的相似度不是特别高,而《楚辞》与《诗经》却具有很大相似性,所以三种可归为同一类,其中《老子》又存在着某种特殊的差异性。《武子》与《论语》同属一类,两者与其他文本的相似程度都较低。
四、结语
本文运用中文信息处理中常用的相似度计算方法对《楚辞》、《公羊传》、《管子》、《谷梁传》、《国语》、《韩非子》、《老子》、《礼记》、《论语》、《吕氏春秋》、《孟子》、《墨子》、《商君书》、《诗经》、《孙子》、《武子》、《孝经》、《荀子》、《晏子春秋》、《仪礼》、《周礼》、《周易》、《庄子》、《尚书》、《左传》等二十五本先秦文献进行了相似系数计算,通过分析计算所得的数据发现了这些文献在用语等方面存在的特点。其中,部分文献的用词较为封闭,用语风格独树一帜,如《老子》、《楚辞》等;而部分文献用词具有包容性,与较多的文本存在一致性,相似度较高。
[1]严莉莉,张燕平.基于类信息的文本聚类中特征选择算法[J].计算机工程与应用,2007,43(12):4.
[2]Xia Tian,Du Yi.Improve VSM Text Classification by Title Vector Based Document Representation Method[A].in The 6th International Conference on Computer Science & Education(第六届国际计算机新科技与教育学术会议ICCSE 2011)论文集[C].2011.
[3]宗成庆.统计自然语言处理[M],北京市:清华大学出版社,2008.
[4]Li Bin,Xi Ning,Feng Minxuan,Chen Xiaohe.Corpus-Based Statistics of Pre-Qin Chinese[J].in Chinese Lexical Semantics,Ji,D.,Xiao,G.,Editors,Springer Berlin Heidelberg,2013:145-153.
[5]Xiahui Pan,Jiajun Cheng,Youqing Xia,Xin Zhang,Hui Wang.Which Feature is Better?TFIDF Feature or Topic Feature in Text Clustering[A].Multimedia Information Networking and Security(MINES),2012 Fourth International Conference on,2012:425-428.
[6]李连,朱爱红,苏涛.一种改进的基于向量空间文本相似度算法的研究与实现[J].计算机应用与软件,2012,29(2).
