基于词典的服务语义标注和匹配算法
2014-03-15钱海忠蔡莉莉
钱海忠,蔡莉莉
(1.金陵科技学院软件工程学院,江苏 南京 211169;2.中国传媒大学南广学院,江苏 南京 211172)
语义万维网[1]与万维网服务相结合,为实现语义万维网服务[2]的服务发现、匹配、调用及组合等功能的自动化提供了一条可行的路径,有关该方面的研究成果不断涌现。大多数研究成果借助本体技术,但是依赖于本体的算法也存在一些不足: 1) 要实现对万维网服务语义标注的前提条件是在因特网上有一个共同认知的领域本体库,这个前提难以做到;2) 本体库的构建需要知识工程领域专家的参与,是一件非常费时、费力的工程,不易于大规模自动化处理,同时隶属于不同领域本体库的概念,它们的语义相似性计算[3]还存在一定困难;3) 本体技术是面向专家级的而非普通级用户,这就要求服务提供商必需在本体专家指导下才能精确的发布服务,使用服务的用户也必需具有一定本体知识才能提交经过本体标注的服务请求文档,这样限制了服务的应用层面。
1 基于语义词典的服务语义标注
1.1 算法思想及基本概念
根据Tversky的模型[4],概念的特征属性是最能描述概念的本质,也是判别概念相似性最好依据。本文的算法依据该模型采用了描述概念特征的特征词集来描述概念的方式,概念之间的相似性则通过在语义词典上对特征词集的语义相似计算来判别。词对的语义相似性是一个主观性比较强的概念,本文所涉及的语义相似性是指词对能描述同一个概念的局部特征属性,因此下面给出本文提出的算法中几个相关定义。
定义1特征词。用来描述概念特征属性的词。对原子概念可能对应于一个特征词或一组同义的特征词,而对于复杂的概念则需要多个特征词分别描述其特征属性。其中特征词的作用相当于知网中的义原作用。
定义2特征词对语义相似性。如果存在两个特征词可以描述同一概念属性特征,则认为它们是在语义上相似。
本文算法依赖于具体的语义词典,不同的语义词典所采用的相似计算方法也会有所不同,如文献[5]是基于知网,而文献[6]是基于词网。相似程度是一个较为模糊的概念,在一般算法中都定义为0到1之间的实数,但是在本文提供的算法中,最终要转换为判断特征词对的数量,因此本文定义相似度取值为0或1,同时假定一个词与自身和空元素的语义相似度分别为1和0。为了叙述方便,表述为:

(1)
采用文献[12]的方法,计算表1中的3个特征词对,返回结果见表1。

表1 特征词相似度
假定给定一个阀值T,如果大于或等于T的词汇都是语义相似的,则公式(1)对表1中3个词对的返回值分别为1、1、0。
定义3特征词集。由两个或多个能够描述同一个概念或概念特征属性的词汇组成的集合,记为SpecialSet(SS)。
定义4特征词集的相似性。如果两个特征词集中的词两两构成词对,判别词对的语义相似性,当两个特征词集中语义相似的词对个数与两个集合所包含元素的个数之比值大于给定的阀值时,即认为两个特征词汇集在语义上是相似的。公式表述如下:
(2)
其中‖S‖表示集合S所含元素的个数;F(SSi,SSj)判别两个集合的相似性函数,阀值T是可调节参数,一般由统计经验值给出。如果分别用这两个特征词汇集各自描述一个原子概念或概念的某个特征,则可以认为这两个原子概念是等同的或是多个概念具有某个共同特征。
因为两个特征词汇集的元素个数可能各不相同,为了便于计算,参照文献[5]先对两个集合的元素构建好一一对应关系。两个特征词汇集相似度计算步骤如下:1) 计算两个集合的所有元素两两之间的相似度;2) 从所有的相似度值中选择最大的一个,将这个相似度值对应的两个元素对应起来,如果该值大于给定阀值,则计数一次;3) 分别从两个集合中删去那些已经建立对应关系的元素;4) 重复步骤2)和3),直到所有的元素都一一对应;5) 没有建立起对应关系的元素与空元素对应,不予计算;6) 利用公式(2)中分子项计算对应好的词汇对并予以统计个数,计算出两个集合的相似性。
1.2 万维网服务语义标注
本文主要是对万维网服务的功能特征属性采用特征词集来描述,对原子概念(原子类型)采用一个特征词汇集来描述;对于复杂概念(即复合类型)则首先对其进行分解成各个原子概念(原子类型),然后再逐一标注。在WSDL文件中,增加如下标签。标签①
例如有一个简单的万维网服务,它的功能是输入城市邮政编号,返回对应城市名。下面代码对于一个简单概念进行语义标注的一个WSDL文件语义标注节选片段。
如下面代码对于一个复杂概念进行语义标注的一个WSDL文件语义标注节选片段。
2 万维网服务的匹配算法
2.1 万维网服务匹配模型
匹配过程中如何判别两个概念(或属性)是否相等,一般通过语义计算服务描述信息。输入/输出参数通常采用本体中的概念(类)来标注,而前置约束和后置效应通常表示为逻辑公式,要满足服务所属的行业或面向的应用领域的规则(公理),但是通常情况下只判断逻辑表达式真与假。不同的服务描述方式会有不同服务匹配算法,但从功能角度上来看本质上相同。参照文献[7-8]的匹配标准,重新给出了以输入/输出参数这些功能属性为参考目标的服务匹配的几种标准,表示如下。
定义5精确匹配(exact)。
事业单位对于所有的活动都必须有预算机制,在活动执行过程中,财务部门要对财务人员和固定资产进行全面的管理,财务人员应当具备预测资产使用情况的能力,在实际的操作过程中,预测的资产使用会随着真实情况的不断变化而发生变化,也就是说,工作人员要加强对于所有事件的观察,防止因为管理上的疏忽而导致资产费用盲目的使用。为加强管理,事业单位可以增加一项机制:将财务人员对于事件的反应能力而做出的预算结果登记在册,进行月末划分等级,以此来鞭策财务人员。
请求服务的输入参数完全符合通告服务的输入请求,通告服务的输出参数完全符合请求服务的输出请求或通告服务的输出参数包含请求服务的输出参数。简记为


定义6嵌入匹配(plug in)。
请求服务的输入参数被包含于通告服务的输入参数,而通告服务的输出参数完全符合请求服务的输出请求或通告服务的输出参数包含请求服务的输出参数。简记为

定义7包含匹配(subsume)。
请求服务的输入参数包含于通告服务的输入参数,而通告服务的输出参数完全符合请求服务的输出请求或通告服务的输出参数包含请求服务的输出参数。简记为
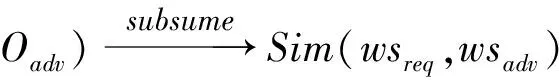
。
本章给出的匹配模型在(Oreq⊆Oadv)这个条件下,匹配结果都具有方向性,通告服务可作为请求服务的精确匹配,反之不成立。定义的3种匹配标准,从满足请求用户需求的角度来分析,精确匹配最强,包含匹配次之,最后是嵌入匹配。简记为exact>subsume>plugin。
2.2 万维网服务匹配方法
根据1.2节给出的输入/输出参数概念的语义标注方法和2.1节提出的万维网服务匹配模型,本节首先给出判别两个服务的输入/输出参数的语义相似性计算公式。
1) 判别服务输入参数相似度公式如下:

(3)

因为每个参数都会对应于一个特征词集,所以参照文献[5]计算集合元素相似性的方式进行计算,步骤如下。前5步参照特征词汇相似计算,步骤6):利用公式(3)中分子项计算对应好的参数对并予以统计个数,并计算出两个服务参数对相似个数,并分别与两个服务参数个数进行比较,比值为1,表明两个服务的输入参数一一对应;比值≤1,表明判别之后参数对个数少于给定的个数,属于包含或被包含关系;对于复合类型的参数,本文算法只标注到它的原子类型,因此计算过程,对复合类型先展开成原子类型参数,再做比较。
同理公式(3),下面分别给出判别两个万维网服务输出参数之间的关系以及输入与输出之间的关系。
2) 判别服务输出参数之间相似度公式如下:

(4)
3) 判断两个服务输入与输出之间的相似度公式,参照公式(4)对Iadv,Oreq计算。
3 实验与结果
本文通过开发工具eclipse3.2、JDK1.6以及axis2.0,搭建了一个万维网服务开发测试环境。实验1:通过对本文算法与传统基于关键词算法在查询精确方面的比较,说明该方法是否具备可行性。分别提交了多组查询请求,每组请求的万维网服务数量有所不同,分别计算每组的平均精确度,结果见图1。从图1中看出,本文算法的精确度明显优于传统基于关键词的查询算法。虽然测试的样本空间比较小,但是从中可以看出本文提出的方法具有一定的可行性,并且该方法在实际中简化了语义标注的复杂度,易于被普通用户所使用。

图1 算法与传统基于关键词算法性能比较Fig.1 The performances of the algorithm and the traditional algorithm
实验2:由于词网的应用较早,并且现有基于该语义词汇库的研究成果较多,为此对本文算法和基于词网的一些服务语义标注算法[9-10]进行了对比实验。实验中的词汇相似性算法采用与对比文献的相同算法。在不同规模注册服务数量下,同样提交了多组查询请求,每组请求查询的服务数量各不同,分别统计各算法的平均查询精确度,结果见图3。文献[9-10]的方法都是采用单个单词进行标注,准确度上要比本章提出的方法低,见图3。在最后两组实验中服务查询提交的请求文档中,有些概念只用少量的特征词来标注,此时它的精确度将会降低,这是该算法的一个不足之处。本章算法要分别计算特征词汇对的语义相似,进而来判断概念的相似性,因此算法花费的时间要比同类文献的算法多,结果见图3。

图2 算法与文献基于WordNet的算法精确度Fig.2 The accuracies of the three algorithms

图3 算法与文献算法查询时间耗费Fig.3 The query times of the three algorithms
4 结 语
本算法利用已经构建好的语义词典,以特征词集的相似性来近似描述概念之间的相似性。该算法符合人们描述事物的客观事实,容易被普通用户所掌握。实验结果也说明了算法具有一定有效性。
[1] Berners-Lee T,Hendler J,Lassila O.The Semantic Web[J].Scientific America,2001,284(5):34-43
[2] McIlraith S,Son T C,Zeng H.Semantic Web Services[J].IEEE Intelligent Systems & their Application,2001,16(2):46-53
[3] 杨梅.“化”缀词的语法和语义研究[J].金陵科技学院学报:社会科学版,2006,20(1):71-75
[4] Tversky A.Features of Similarity [J].Psychological Review,1977,84(4):327-252
[5] Liu Q,Li S J.Word Similarity Computing Based on Hownet[J].Computational Linguistics and Chinese Language Processing,2002(7):59-76
[6] Jutla D N,Veerasekaran D,Ding R.Trade-Offs in a Google Distance and a WordNet Hybrid for QoS-Enabled Web Services Composition[C].2012 IEEE Ninth International Conference on Services Computing (SCC),2012:312-319
[7] Paolucci M,Kawamura T,et al.Semantic Matching of Web Services Capabilities[C].Proceedings of the First International Semantic Web Conference on the Semantic Web,Sardinia,Italy,2002:333-347
[8] Lecue F,Leger A.Semantic Web Service Composition Based on a Closed World Assumption[C].ECOWS06,2006:233-242
[9] Kaijun Ren,Nong Xiao,Jinjun Chen.Building Quick Service Query List Using WordNet and Multiple Heterogeneous Ontologies toward More Realistic Service Composition[J].IEEE Transactions on Services Computing,2011,4(3):216-229
[10] Maher M,Hamza H S,Mohamed R M.Service Composition Recovery Using Formal Concept Analyst& Wordnet Similarity[C].IRI 2011,2011:123-138
