基于大数据挖掘的科技项目查重模型研究*
2014-03-14李善青宋立荣
李善青,赵 辉,宋立荣
基于大数据挖掘的科技项目查重模型研究*
李善青,赵 辉,宋立荣
科技项目查重是避免重复立项、重复建设的重要措施之一,目前缺乏行之有效的方法。文章提出基于大数据挖掘和多源信息整合的项目查重方法,以科技项目的基本信息、发表论文信息、关键词、负责人信息和承担机构等要素构建的大数据网络为研究对象,利用多源信息整合方法构建科技项目的相似度判别模型,并采用Hadoop框架实现海量数据的快速挖掘。文章介绍项目查重模型,重点讨论需要解决的关键问题,为解决项目查重问题提供一种全新的思路和方法。
大数据挖掘 多源信息整合 科技项目查重 Hadoop架构
0 引言
为推动科技创新,我国不断加大对科研的资助规模和强度,科技项目的数量和经费在近年均得到显著提升,形成多层次的国家科技计划资助体系。随之而来的重复立项问题日趋严重。据统计,我国科研项目重复率达40%,另外60%中与国外重复约占30%以上[1]。重复立项不仅造成科技资源的浪费,也导致恶性科研竞争,损害开拓创新的科研精神,对科技创新危害极大。早在2006年,科技部前部长徐冠华在《关于建设创新型国家的几个重要问题》讲话中指出,切实加强科技宏观统筹协调的重要举措之一就是“积极推动建立跨部门的科技项目数据库。针对科技项目立项中多头立项、重复立项的问题,推进科技项目共享数据库的建立,为解决重复问题提供必要的技术支撑”。各级科技计划主管部门对重复立项问题十分重视,研究了一些项目查重的方法和机制问题,取得了一定的进展,但总体效果并不明显。究其原因,主要在于以下3个方面:
(1)项目数量呈现逐年快速增长的态势。仅国家自然科学基金委员会2013年度资助的项目就达3.5万余项。数量庞大的项目为查重工作带来很大挑战。此外,基础科学研究具有创新性、不确定性、学科交叉融合等特点,不同学科领域的新观点、新概念和新知识不断涌现,科研项目管理人员需要越来越多的专业知识才能准确判断项目的相似性,这也给项目查重工作带来很大的困难。
(2)项目信息公开、共享和整合程度较低。科技计划的项目信息和实施情况主要分散掌握在各计划主管部门内部,对外开放和共享的程度低,各计划之间的项目信息无法进行有效整合。如国家自然科学基金在立项审查时只能在该基金资助的项目范围内进行重复性检测,而几乎无法与其他科技计划项目进行检测和查重。解决该问题的方法是在国家层面上建立统一的可对外公开的项目信息检索平台,实现项目信息的共享和整合。
(3)项目相似性判别方法单一。目前科研重复立项检测主要通过比对项目标题或者比对项目申请书的内容进行甄别。前者只是进行简单的关键词匹配,将项目标题中包含指定关键词集的项目定义为相似项目。一旦项目更换标题,该方法则会失效。后者能够较准确地发现相关/相似的项目,但算法实现难度较大,并且项目申请书因涉密或保护知识产权等原因一般不对外公开,很难从公开渠道获取这些信息。因此该方法只适用于在单个计划主管部门内部实现项目查重。
文献调研发现,国外没有项目查重的概念,但在数据挖掘、文档检索等方面的研究起步早,进行了大量的研究和探索,积累了丰富的经验和成熟的技术[2-5]。国内在方法研究方面起步晚,但有针对性地开展文本挖掘方法在科技项目管理中的应用研究。姜韶华[6]提出一种基于文本挖掘的科研项目管理原型系统,重点研究和解决科研项目文本的切分和特征建模等问题;左川[7]提出一种基于非分词技术解决科技项目查重问题的方法,该方法不需要对文本进行分词处理,利用频繁闭项集构造向量空间模型对项目申请书进行建模并计算相似度;方延风[8]提出将一种改进的TF-IDF方法用于科技项目查重,考虑了特征词的位置和长度两种因素;吴燕[9]提出一种基于层次聚类的科技项目分类和查重方法,在计算科技项目相似性时综合考虑了应用领域、研究内容和技术来源等因素;林明才等[10]提出一种改进的模糊聚类算法RM-FCM,在计算项目相似度时考虑了不同属性的特征项对科研项目的重要性;刘荫明等[11]从科技查新实践、地区和部门多头管理、科研论文所依托的基金项目数量等方面研究我国科研的重复立项现象,通过对科研项目的申报与审批流程进行分析,提出避免重复立项的具体措施。
上述研究工作基本都是从项目申请书入手,对申请书进行分词或将其作为整体处理,然后提取特征向量,利用特征向量的相似度表示项目的相似度。一方面不同计划的申请书格式不同,学科领域差别较大,很难找到统一的描述模式;另一方面,项目申请书一般不对外公开,获取难度很大。因此,该方法适应于在单个计划内部进行项目查重,很难进行跨计划的项目查重。基于上述分析,本文采用一种全新的思路解决项目查重问题,首先收集项目的标题、项目所发表的论文、关键词、负责人和承担机构等要素的海量信息,构建与项目查重相关的大数据网络,为后续的分析和挖掘提供数据支撑;然后利用多源信息整合技术构建项目相似度模型,综合考虑项目的研究内容、负责人和承担单位3种因素以提高计算项目相似度的准确性和可靠性;最后采用Hadoop分布式处理技术加速项目相似度的计算过程,实现对海量数据的快速挖掘。
1 大数据挖掘
随着海量数据获取、存储与处理方法与技术的飞速发展,大数据时代来临,并对众多领域产生影响[12]。2007年计算机图灵奖得主Jim Gray在NRC-CSTB的演讲报告中提出科学研究的第四范式[13]—数据密集型科学研究,以协同化、网络化与数据驱动为其主要特征,在学术界引起很大关注。世界顶尖科学期刊《Nature》和《Science》分别推出专刊,围绕科学研究中的大数据问题展开专题讨论。美国政府于2012年3月29日发布的“大数据研究与发展计划”[14]更是将大数据的发展和研究提高到国家战略的层面,将其视为信息科学领域内继信息高速公路计划之后的又一重大发展战略。
大数据挖掘在近年发展迅速,基本思想是通过包括互联网在内的多种渠道收集研究对象的多维度数据,通过对海量数据的关联分析和数据挖掘,发现被研究对象的潜在行为模式或规律。大数据挖掘的经典应用有Google公司推出的“流感趋势预报服务”[15]和奥巴马竞选团队的“大数据选举”[16]。Google公司认为,用户搜索的关键词代表了他们的即时需求,通过对流感进行关键词建模,并对搜索这些关键词的海量用户进行跟踪分析,创建流感地图。“谷歌流感趋势”在测试过程中还显示出反应迅速的优势,甚至能够比疾病控制和预防中心提前1个星期到10天时间公布流感预报。美国总统奥巴马的竞选团队利用大数据驱动的分析和决策为其成功连任发挥巨大的作用,竞选团队创建了庞大的数据系统,将民调者、注资者、工作人员、消费者、社交媒体及“摇摆州”主要民主党投票人的信息进行关联及整合,然后通过大量的数据挖掘和模拟运算,对筹集竞选资金、竞选广告精准投放、模拟竞选等提供决策支持服务,取得了立竿见影的效果。
国内的学者也开展了相关研究。孟小峰等[17]对大数据管理的概念、技术和挑战等问题进行了系统化的梳理和总结;侯经川等[18]研究了大数据时代的数据引证问题,对其研究现状、最新进展和未来展望进行了深入的分析和讨论。总体来看,大数据挖掘的相关研究处于起步阶段,国内与国外差距还不大,这是我国在该领域追赶国际先进国家的重要机遇。利用大数据的思想解决科技项目查重问题是一个全新的研究课题,有重要的理论和实践意义。本文重点介绍基于大数据挖掘的项目查重模型,并探讨其中涉及的关键问题,为解决项目查重问题提供一种新的视角和方案。
2 项目查重模型
本文提出的项目查重方法的基本思路是从海量数据中挖掘出与项目查重紧密相关的研究内容、负责人和承担单位等信息,采用多源信息整合技术对上述信息进行整合并判定项目的相似度。为加速海量数据的挖掘,笔者采用Hadoop分布式技术提高项目查重的计算速度。项目查重的架构框图如图1所示,可分为任务解析、大数据文件、项目相似度判别模型、分布式调度和结果展示等5部分。任务解析模块在收到用户的查询请求后将其解析和翻译为机器可执行的指令,并提交给分布式调度模块执行;分布式调度模块负责利用Hadoop框架管理和调度计算机集群系统协同完成项目查重任务;大数据文件模块存储了与项目查重相关的海量数据,是该模型的数据基础;项目相似度判别模型通过综合关键词、负责人和承担单位等因素计算项目与查询条件的相似度;结果展示模块则通过可视化等手段将查询结果反馈给用户。

图1 项目查重的架构框图
本查重模型所处理的数据对象包括5类:项目信息、论文题录、关键词、负责人和承担单位。5种数据对象间存在网状的关联关系,如图2所示。通过对上述网状数据进行加工处理,提取出与项目查重密切相关的元数据描述:项目ID是项目的唯一标识,是实现各类数据之间关联的纽带;关键词集是一组用于描述项目研究内容的术语,是对研究内容的凝练和概括。该数据来源于两部分:一部分来自于项目标题,可通过自动切分词技术获取;另外一部分则来源于由项目资助所发表论文的关键词,可通过论文的资金资助信息建立项目ID与论文关键词的关联关系。由于项目数量和论文数量都十分庞大,关键词集的构建首先通过文本智能挖掘和抽取技术完成,然后辅以人工校验的方式保证数据的准确性;负责人信息则直接从项目信息数据库中抽取,但由于信息缺失,负责人身份的唯一性识别仍然是尚未得到有效解决的难题;承担单位信息也存在上述类似的问题,机构的更名、重组、简称全称混用等因素为设定承担单位的唯一性识别带来很大的困难。

图2 大数据构建的示意图

图3 相似度判别模型
项目的相似度判别模型分别计算研究内容、负责人和承担单位3方面的相似度,并对上述结果进行加权整合得到项目最终的相似度。其中,项目的研究内容由一组关键词进行描述,因此其相似性转化为检索词集合与项目关键词集合之间的相似性。项目负责人和承担单位存在的重复性直接通过检索词匹配的方式计算,即两个项目的负责人或承担单位相同,则存在重复立项问题的可能性较高。三个维度的匹配度计算完成后,通过加权的方式进行整合,最终得到与检索条件匹配度由高到低排序的项目集合。
本模型解决的是大数据场景下的项目查重问题,要在短时间内完成对海量数据的检索,需要借助于分布式计算技术。笔者采用Hadoop框架完成项目查重任务的分布式处理,其原理如图4所示。JobTracker是管理者的角色,负责任务的拆分和调度,维持与TaskTracker通讯并记录其最新状态信息。TaskTracker是工人的角色,负责具体子任务的执行,从指定的位置读取待处理的数据,完成任务后保存中间结果,并向JobTracker提交状态更新。子任务的类型有两种:Map操作和Reduce操作。Map操作处理相应的片段数据,即对指定片段计算项目的相似度,并保存中间结果。Reduce操作则对中间结果进行收集和合并,即对指定的项目集合完成相似度的加权计算,得到最终的判别结果。
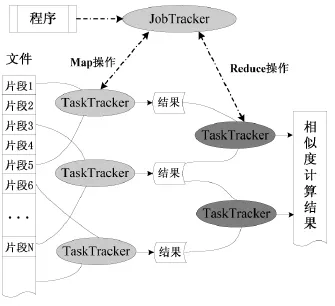
图4 Hadoop分布式调度原理
3 讨论
本文从大数据挖掘的角度提出了一种全新、可行的项目查重模型,能够解决目前项目查重的诸多难题。然而,该方法涉及海量数据的采集、加工、关联和挖掘等内容,需要建立规范的工作机制和采用智能的挖掘技术以保证查重方法的切实可行。下面将重点介绍该模型需要解决的几个关键问题:
(1)海量数据的采集和加工需要建立一系列的标准和规范来保证数据的准确性。处理的数据涉及项目信息、论文题录、关键词、负责人和承担单位等,数据量庞大,种类较多,且没有固定的格式,因此,需要建立一套规范的工作机制,并严格按照指定的标准对数据进行加工和处理。此外,由于数据量巨大,需要大量的人力和财力作为支撑。
(2)数据的标识、描述和关联机制问题。数据标识解决数据的唯一性标志问题,目前在如何解决负责人、承担单位的唯一标识上仍存在很大的困难;数据描述用于揭示数据的内容/属性,需要对5种数据对象建立统一的元数据标准;关联机制则重点解决不同类型数据之间的关联关系问题,如项目与发表论文如何建立准确的对应关系等。
(3)研究文本智能抽取技术是处理海量数据必不可少的手段之一。该技术主要用于解决关键词集的自动生成问题:一方面,针对科技项目标题的特点设计针对性的切分词技术,自动从项目标题中抽取关键词;另一方面,从论文题录的项目资助信息中自动抽取项目编号,建立项目与论文的关联关系,并将论文的关键词自动加入到项目的关键词集合中。关键词集构建的准确与否直接关系到项目查重效果的优劣。
(4)大数据挖掘需要处理海量的数据,为提高项目查重的速度,需要分布式的处理架构对海量数据进行检索和挖掘。Hadoop是一套通用的技术框架,应用到项目查重场景中需要根据业务逻辑进行适应性改造。如何将项目查重的业务逻辑设计为分布式处理模式,并尽可能提高查重效率是需要解决的关键问题。
4 结语
本文提出一种基于大数据挖掘的项目查重方法,利用大数据挖掘和多源信息整合等技术解决项目查重问题。该方法提供了一种全新的思路和方法,是对现有项目查重方法的促进,具有重要的理论意义与应用价值。基于该模型构建切实可用的查重系统需要解决一系列关键的机制问题和技术问题,包括建立海量数据采集和加工标准;构建数据的标识、描述和关联机制;研究文本智能抽取技术和改进Hadoop框架以适应项目查重的业务需求等。
[1]张金玲,黄长,陈如好,等.深化科技查新工作 扩展社会化服务[J].图书馆论坛,2011(5):122-124,137.
[2]H.Zhang,T.Chow,A multi-level matching method with hybrid similarity for document retrieval[J],Expert Systems with Applications,2012,39(3):2710-2719.
[3]J.Reid,M.Lalmas,K.Finesilver,M.Hertzum,Best entry points for structured document retrieval—Part II:Types,usage and effectiveness[J],Information Processing&Management,2006,42(1):89-105.
[4]J.Reid,M.Lalmas,K.Finesilver,M.Hertzum,Best entry points for structured document retrieval—Part I:Characteristics[J],Information Processing& Management,2006,42(1):74-88.
[5]P.Kalczynski,A.Chou,Temporal Document Retrieval Model for business news archives[J], Information Processing&Management,2005,41(3):635-650.
[6]姜韶华.科研项目管理中文本挖掘方法研究及应用[D].大连:大连理工大学,2006.
[7]左川.基于非分词技术的科技项目查重研究与实现[D].重庆:重庆大学,2010.
[8]方延风.科技项目查重中特征词TF-IDF值计算方法的改进[J].情报探索,2012(1):1-3.
[9]吴燕.基于层次聚类的科技项目分类与查重研究[D].天津:天津财经大学,2008.
[10]林明才,康耀红,张诚一.基于科研立项管理应用的模糊C均值算法研究[J].计算机工程与设计,2010,31(7):1570-1572.
[11]刘荫明,张福俊,刘谦.浅析科研管理之避免重复立项[J].科技管理研究,2010(21):198-200.
[12]L.Steve.The age of big data[N/OL].The New York Times.(2012-02-12)[2013-03-06].http://www. nytimes.com/2012/02/12/sunday-review/big-datasimpact-in-the-world.html.
[13]H.Tony,T.Stewart,T.Kirstin.The fourth paradigm:Data-intensive scientific discovery[M].Redmond,WA:Microsoft Research,2009:19-33.
[14]Fact Sheet:Big Data Across the Federal Government [EB/OL].(2012-03-29)[2013-03-06].http://www. whitehouse.gov/sites/default/files/microsites/ostp/big_ data_fact_sheet_final.pdf.
[15]Google Flu Trends.[EB/OL].http://www.google. org/flutrends.
[16]M.Scherer.Inside the Secret World of the Data Crunchers WhoHelpedObamaWin.[EB/OL].(2012-11-07)[2013-03-06].http://swampland.time. com/2012/11/07/inside-the-secret-world-of-quants -and-data-crunchers-who-helped-obama-win/.
[17]孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(1):146-169.
[18]侯经川,方静怡.数据引证研究:进展与展望[J].中国图书馆学报,2013(1):112-118.
Study on Detection Model of Similar Scientific Project Based on Big Data Mining
LI Shan-qing,ZHAO Hui,SONG Li-rong
Checking out similar project is very important to avoid repetition in project approval.However,there is no way to find out similar project effectively for the moment.This paper proposes a novel method of detecting scientific projects similitude based on big data mining and multi-source information integration.Using that method,the authors studied the huge data network consisting of the information about the project,published papers,experts and institutions,as well as the keywords;built up a detection model of project similitude by integrating multi-source information;and adopted the Hadoop to speed up big data mining.This paper presents the detection model of project similitude and its key issues;in hope of providing brand-new thinking and methods for detecting similar projects in scientific project management.
big data mining;multi-source information integration;similarity detection for scientific projects;Hadoop architecture
格式 李善青,赵辉,宋立荣.基于大数据挖掘的科技项目查重模型研究[J].图书馆论坛,2014(2):78-83.
李善青(1981-),男,博士,中国科学技术信息研究所助理研究员;赵辉(1971-),女,硕士,中国科学技术信息研究所副研究馆员;宋立荣(1971-),男,博士,中国科学技术信息研究所高级工程师。
2013-07-26
*本文系中国科学技术信息研究所科研项目预研基金“面向重复立项检测的多源信息整合机制研究”(项目编号:YY201214),国家自然科学基金项目“大数据挖掘在科技项目查重中的应用研究”(项目编号:71303223),国家社会科学基金项目“网络环境下科技信息资源建设中的质量元数据及评估应用研究”(项目编号:12BTQ016) 研究成果之一
