基于DPI的移动分组网络流量分析技术的研究与实现*
2014-03-12张艳荣张治中姜明志郑小平
张艳荣,张治中,姜明志,郑小平
(重庆邮电大学通信网与测试技术重点实验室 重庆 400065)
1 引言
2013年12月4日,工业和信息化部向三大运营商发放了LTE-TDD网络商用牌照,LTE正式在国内商用。由于LTE大带宽、高速率、低时延的特点,加之丰富的移动互联网内容,OTT势不可挡,运营商在传统的以语音为主的移动通信网络中的管道优势已经不复存在。对于运营商来说,其掌握的核心资源就是用户和用户注意力(即内容商提供的内容,运营商所谓的“流量”)的传输通道。为了避免被管道化和边缘化,获取与OTT内容商谈判的筹码,运营商必须发挥自己在资源上的优势,通过先进的网络技术和网络设备充分掌握网络和用户状况,有效地管理和控制网络,制定科学的网络发展计划,实现运营模式的转变[1]。
传统的流量分析都是基于传输层的端口号来区分不同业务的,通过识别这些端口号对业务流量进行分类和统计。然而,随着人们对移动互联网内容需求的急速增长,基于HTTP和P2P的小众业务占据了移动数据网络的绝大多数流量,基于端口号的业务识别技术无法识别这些小众业务。深度分组检测(deep packet inspection,DPI)技术是在传统的基于IP五元组(源IP地址、源端口号、目的地IP地址、目的地端口号和承载协议)的业务识别的基础上,对数据应用层进行进一步探测。采用DPI技术识别数据流业务,需建立流量特征库,通过采用模式匹配算法匹配特征库和待识别的数据流,匹配成功则将数据识别为对应的业务。对于HTTP数据流,其业务特征可能存在于URL、host、user-agent等信息中;对于基于P2P的应用,其业务特征一般都是数字型的,如基于TCP的微信消息数据分组,端口号为80或8080端口,第一个上行携带payload分组的前3个字节为“060104”,最后 4 个字节为“04010000”[2]。
DPI技术有着业务识别率高、原理简单等特点,但是DPI业务识别技术的关键在于强大的特征库,一方面,业务特征会随着应用升级和新业务加入发生变化,需要随时更新特征库,另一方面,对于一些加密或者特征不明显的业务,DPI技术就无法进行业务识别。深度流检测(deep flow inspection,DFI)技术就是一种可以和 DPI互补的技术。DFI是通过传输层宏观统计特性来分析业务流量。DFI技术不需要关心应用层的微观特征,而是通过对数据流的持续时间、上下行流量、报文长度等统计信息进行分析,识别应用类型。通过建立应用类型与报文数据流特征模型的对应关系,可以识别出数据流的应用类型[3]。
本文提出了一种基于DPI的流量分析系统,并引入DFI技术辅助业务识别,最大限度地发挥DPI和DFI技术的优点,同时合成xDR,用于业务统计优化,集流量统计与业务识别分析于一体。
2 基于DPI/DFI的流量监测方案
对移动数据业务进行流量分析,需从现网采集数据并预处理,包括简单的解码和基于端口号的协议识别,然后分别交付DPI业务识别和xDR合成。基于DFI技术的业务识别流程可以建立在xDR合成的基础上,通过以传输层数据分组合成xDR,统计数据流的上下行流量、传输时延、乱序分组数、重传分组数等信息,一方面可以作为网络数据业务优化的信息来源,另一方面可以为DFI识别提供识别上下文。基于DPI技术的流量分析系统的整体框架如图1所示,采用模块化的设计,将不同协议解码合成等封装成动态库/静态库,实现系统的低耦合性和高重用性,易于管理维护。
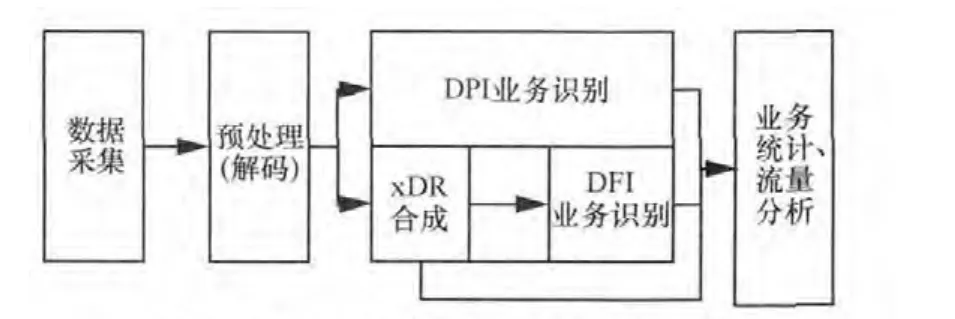
图1 基于DPI技术的流量分析系统框架
2.1 数据预处理模块设计方案
在DPI业务识别和xDR合成之前,首先要将采集过来的原始数据进行预处理。将原始的二进制数据流转换成具有逻辑意义的数据结构,为业务识别和xDR合成提供上下文环境。预处理的主要任务就是解码,本文的解码分为详细解码和简单解码。详细解码是逐字节地解释数据流;简单解码则根据需求,只从数据流中读出关心的内容。本文的预处理方案是封装详细解码为基础解码静态库,协议栈解码器依次调用各个详细解码接口解码。解码器采用依据协议栈从底层到上层逐层解码的方法,解码完本层协议数据后,如有上层业务数据单元(service data unit,SDU),根据上层数据类型,调用相应的基础解码接口,直到无上层SDU[4]。
解码的目的是为DPI和xDR合成提供具有逻辑意义的结构化信息,在交付识别和合成前,需要对数据流进行简单的分类。移动数据网络的用户数据一般以TCP/UDP为传输层,因此可以根据第1节所述的基于端口号的业务识别方法,将数据流粗略地分为以下几大类:HTTP业务、FTP 业 务 、DNS 业 务 、E-mail (POP3、SMTP)业 务 、MMS(WTP、WSP)业务、RTSP业务和除此之外的通用业务,包括如即时通信、P2P业务等。
解码完成后,需要对数据进行DPI业务识别和xDR合成,对于 FTP、DNS、E-mail、RTSP 和 MMS 数据,在这里是不需要进一步进行业务识别的,但是所有业务都需要进行合成xDR,供业务分析和优化使用。下面详细说明这两部分的原理和实现。
2.2 DPI业务识别
基于DPI的业务识别技术的关键在于建立一个全面准确的业务特征库。然而由于LTE网络数据量巨大,加之匹配算法的复杂度较高,对服务器的压力也非常大。这里采用和DFI类似的处理方法,通过一种自学习的机制,大大降低了业务数据和特征库匹配的次数。自学习的主要方法是将已经识别出的应用类型和该应用数据的IP五元组添加到统计表中,在识别数据时,先匹配统计表,无法匹配统计表的数据才通过DPI匹配特征库。流程如图2所示。
DPI业务识别统计表是一个以IP五元组为关键字key,以业务类型(包括应用类型、服务类型、客户端类型等信息以及应用统计信息等)为散列值(value)的散列表。本表有自学习的功能,能够将通过DPI特征库匹配到的业务信息,通过IP五元组学习到表中,为以后相同业务数据省去大量匹配所占用的资源。同时,对于一部分常见应用,比如咪咕音乐,其应用数据的层三IP地址为218.200.160.29:80或218.200.160.30:80。为了提高识别率,将这些已知IP三元组的应用也配置以IP三元组为关键字key、以业务类型为value的散列表,提供业务识别的快速查询。对于从以上两个散列表中都无法查询到应用类型的数据,才通过特征库进行匹配识别。

图2 DPI业务识别流程
建立特征库是DPI业务识别的关键。特征库是一个包括了应用类型信息、服务端口号、特征值、层三IP地址等信息的可配数据库。特征值根据类型可以分为数字型特征和字符型特征,根据出现的位置可以分为host key、refer key、URL key、user-agent key、承载层 key 等。匹配时,根据特征值的优先级从高到底的级别依次匹配特征值和相应字段。识别统计结果表存盘,入库后供应用层查询。
DPI业务识别的技术核心就是匹配算法,通常DPI采用正则表达式匹配特征值与数据流。特征字符串匹配也称关键词匹配,它研究从大量数据中快速匹配多个关键词(多个模式)的技术。基于DPI的特征匹配业务识别的特点是需要处理的数据量大,待匹配的关键词集合大,这些对多关键词匹配算法的处理能力提出了更高的要求。常见的匹配算法包括Aho-Corasick算法、AC-BM算法等,而正则表达式的描述有 NFA (non-deterministic finite automata)与DFA(deterministic finite automata)两种方式。通过前人大量的研究已经证明,采用DFA方式比采用NFA方式具有更强的处理能力与计算性能。因此,本文采用DFA算法匹配特征值与数据流。DFA算法较为复杂,具体算法实现参考文献[5]。
2.3 xDR合成及DFI业务识别
xDR包括详细记录CDR和事务详细记录TDR。xDR能够反映出一次信令/数据流程的全部过程。信令面xDR是进行网络优化和网络故障快速定位的基础,数据面xDR是进行移动数据网络流量统计和分析的基础。在本文的方案中,xDR也是基于DFI业务识别的必要步骤,通过xDR合成统计传输流的宏观特性,如上下行流量、持续时间、上下行分组数、响应时间等。这些统计信息是进行DFI合成的必备上下文环境。
2.3.1 xDR合成方案
xDR合成的任务是关联属于同一个流程的所有消息。对于数据业务合成,有两个关键点:一是关联哪些消息;二是如何关联这些消息[6]。
对于第一个关键点,传统的业务合成方法是对应用层消息进行关联。这样的xDR是不能反映出一次HTTP传输的全部信息的,尤其是对应用数据的统计特性所获甚少。因此根据xDR的统计需求,本文提出一种基于完整传输流的xDR合成方案。对于基于TCP的应用,以TCP 3次握手消息(tcp_syn)作为xDR合成的起点,以 TCP重置消息(tcp_rst)或超时作为xDR结束消息。
xDR合成的第二个关键点,就是如何关联属于同一个流程的消息。在本方案中,采用了散列的方法关联消息,主要是将网络中的消息按照传输流进行归类。采用散列算法完成查找功能。利用合成关键信息key作为散列表的关键字,并通过关键字key值和这些消息联系到一起,再现一次数据传输流的详细过程。因此,关键字key值的选取,将影响到xDR合成的效率和关联的准确性。
对于用户应用数据流,属于同一个传输流程的消息,应该有相同的IP五元组信息。因此,本文xDR合成方案选择源IP地址、目的地IP地址、源端口号、目的地端口号作为消息关联参数。通过这4个字段,可以唯一确定网络上的一个数据传输流。特殊的,由于DNS不是基于传输流的应用层协议,完整的DNS流程只有请求和响应消息,因此DNS需要额外增加DNS事务ID(Tid)作为消息的关联参数。
xDR合成状态分为创建、更新和结束:对于一条数据,首先查找处于更新状态中的xDR,xDR未创建,则由xDR创建消息触发创建xDR。对于非xDR创建消息,需要更新统计信息,并且xDR结束消息触发结束xDR操作,更新当前xDR,从合成xDR列表中移除。具体的合成流程如图3所示。为了提高核查效率,本文采用散列算法的思想,先建立key值和待关联的合成xDR的存储地址的映射关系H(key),使每个key对应唯一的存储地址。通过映射关系找到key对应的xDR,进行xDR的建立、修改和删除操作。
合成xDR的关键是统计传输流的宏观特性,包括上下行流量、上下行IP分组数、上下行TCP乱序分组数、上下行重传报文数、上下行分片数、第一个HTTP响应分组时延、最后一个HTTP内容分组的时延,最后一个ACK确认分组的时延等信息。这些统计信息一方面是移动分组网数据业务管理和优化的基本信息,通过业务使用持续时间、业务连接间隔、上下行速率等方面分析流量业务模型。另一方面,这些数据流的宏观统计信息,将会作为DFI业务识别的上下文,详见第2.3.2节。
2.3.2 DFI业务识别方案
鉴于DPI技术识别准确度高、不适用于P2P业务和加密数据的特点,DFI技术是对DPI技术的很好的补充。DFI技术基于会话连接或数据流一系列流量的行为特征,建立流量特征模型,通过分析会话连接流的分组长度、连接速率、传输字节量等信息来与流量模型对比,从而识别应用程序类型[7]。
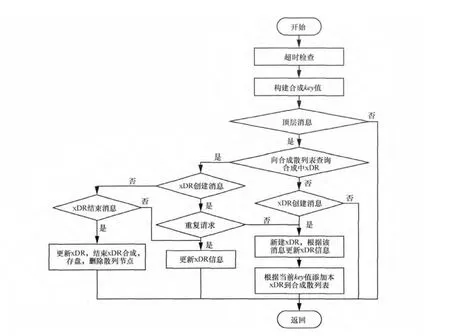
图3 业务xDR合成流程
DFI业务识别技术的关键是建立应用流量特征模型。本方案利用机器学习的方法根据不同业务流量间的差异进行流量分类模型的建立,生成流量分类器;流量分类器根据xDR合成统计出的流量特征对流量进行分类,识别数据流业务类型。总体过程如图4所示。
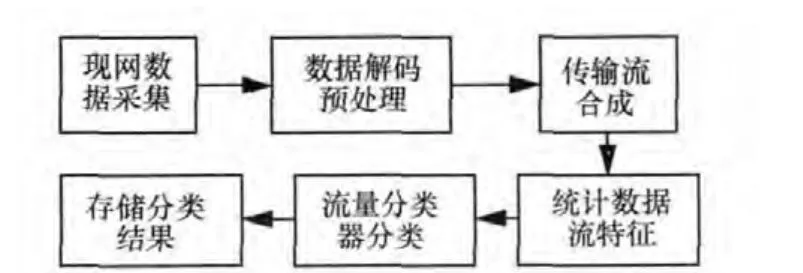
图4 DFI业务识别流
DFI业务识别技术的关键在于通过机器学习监督学习的方法建立一个完整的业务流量特征模型,即流量分类器。分类器的建立过程如图5所示。
数据预处理主要是数据流宏观特征提取,采用第2.3.1节所述的数据关联方法即可提取样本数据流的统计数据。然后需要进行特征选择,特征选择是指对预处理模块统计出来的数据进行去除冗余的操作。经过筛选的数据,就可以进入学习模块,开始学习。这里选择精确度较高的C4.5决策树算法作为机器学习算法[8],它是一种贪心算法,实现过程不在这里敷述。分类器经过准确性测试后,可以根据数据流的统计特性对数据流进行流量分类。为上层应用对业务识别和统计数据入库方便,DFI识别的结果一样存储为业务统计表的格式。
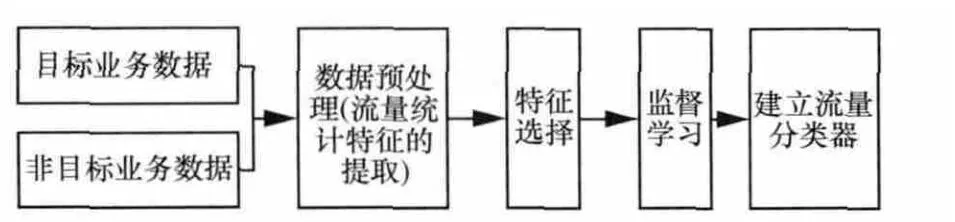
图5 流量分类器的建立
3 流量分析
本文方案首先将采集卡从相关的网络接口采集数据通过汇聚设备将数据汇聚到数据处理局域网,数据处理服务器接收数据后对数据进行解码、xDR合成和业务识别统计处理,分别将原始数据、xDR和业务识别统计出表,存储在数据存储服务器,并入库到数据库服务器;应用服务器从数据存储服务器和数据库服务器获取数据,进行再次处理,供业务优化和决策参考。但是,和传统的业务监测分析系统相比,本方案改进了处理流程,增加了业务识别功能。下面对传统监测方案和本方案进行比较。
传统监测方案主要是解码和合成,在数据处理服务器端完成消息的解码合成工作,应用层通过套接字(socket)接口查询处理结果,处理结果通过二进制文件存在本地处理网络。业务xDR合成基于应用层消息,传统合成的仅关联带有应用层消息头的消息,图6所示为一个HTTP请求xDR,该xDR仅包含了HTTP请求和HTTP响应消息,xDR结构体中亦没有统计信息,对于流量分析统计和业务优化的意义较小。相同数据在基于本方案的系统下运行结果如图7所示。本方案结合了流量分析技术的特点和要求,xDR采用CSV文件格式保存并写入数据库服务器,上层应用通过数据库读取结果再处理。
本方案的xDR统计出表结果如图8所示,选中行为该xDR的出表文件的统计部分截图。与图6对比可知,本方案xDR出表文件统计了上下行流量、上下行IP分组数、上下行乱序/重传分组数、响应时延(第一个内容分组、最后一个内容分组和最后一个ACK分组时延)和host、URL等信息,全面地统计了数据流的微观内容和宏观特性,这些数据将是流量统计和网络业务优化的基础。
传统的监测系统主要针对的是信令数据,对于业务数据没有进行详细的业务识别和深度分组监测,无法满足运营商对业务精细化识别与统计的需求。因此,本方案引入DPI/DFI技术对流量进行深度识别和分析,结果形成出表文件入库,供应用层再开发。图9所示为业务识别出表文件的一段。文件中,C列和D列分别表示数据的应用主类型号和子类型号,K 列和 L列为 host和 URL,M、N、O、P列分别为上行分组数、上行流量、下行分组数和下行流量。图中方框标识的两行的host字段中分别包含微信 (主类型1:即时通信,子类型 9)特征“weixin.qq.com”和豌豆荚(主类型 7:应用市场,子类型 8)特征“.wandoujia.com"。通过excel统计,可知主类型为1(即时通信)和15(应用商店)的业务占据了绝大多数流量;进一步统计可发现,微信数据分组在数量上占据整个网络较大份额(197/581)。
4 结束语

图6 一个传统的HTTP请求xDR

图7 一个基于本方案的HTTP请求xDR

图8 xDR结构出表CSV文件(部分)

图9 业务识别出表文件截图(部分)
随着4G网络商用拉开序幕,数据业务的分析和优化将是运营商面临的重要举措。本文基于传统的信令监测系统架构,在其基础上添加了基于DPI业务识别技术,用于业务识别与统计;设计了一种基于传输层数据流的xDR合成方案,并在xDR合成工程中统计数据流的宏观统计特性,使得合成xDR不仅能够用于传统的业务优化和流量统计,也能通过DFI业务识别技术识别P2P业务和音视频相关应用。DFI业务识别和DPI业务识别在技术上优势互补,本文将合成xDR的统计特性进一步用于DFI业务识别,DFI业务识别作为对DPI业务识别的一种补充,提高了系统的业务识别率。经过现网数据测试,本方案能够很好地对移动分组网进行业务xDR合成和流量识别统计,具有较高的处理效率和识别准确性。
1 罗忆祖.DPI技术助力运营商精细化运营.电信网技术,2009(1):22~24
2 叶文晨,汪敏,陈云寰等.一种联合DPI和DFI的网络流量检测方法.计算机工程,2011(10):102~107
3 蒋文龙.基于DPI技术的P2P流量监控系统的研究与设计.北京邮电大学硕士学位论文,2013
4 李娟,雒江涛.用户感知智能分析系统Abis接口信令监测的研究.电信科学,2012(9):58~62
5 刘胤.深度包检测技术的研究与设计.贵州大学硕士学位论文,2008
6 马陈泽.移动核心网优化分析系统——Gn接口信令处理模块的研究与开发.重庆邮电大学硕士学位论文,2011
7 桑寅,孟少卿,鹿凯宁.基于DPI和机器学习方法传输层检测的P2P流量识别模型.电子测量技术,2011(10):45~48
8 李国平,王勇,陶晓玲.基于DPI和机器学习的网络流量分类方法.桂林电子科技大学学报,2012,32(2):140~144
