基于Spark平台的NetFlow流量分析系统
2014-02-28丁圣勇闵世武樊勇兵
丁圣勇,闵世武,樊勇兵
(中国电信股份有限公司广东研究院 广州510630)
1 引言
NetFlow是由Cisco(思科)公司在1996年开发的内置于Cisco IOS的一种网络协议,目的是收集IP流量信息和监控网络的使用情况。NetFlow被广泛应用于Cisco的路由器和交换机中,类似技术也得到Juniper、华为等公司生产的路由器的支持,是网络规划、运营和优化的重要依据。从路由器中发送出来的NetFlow记录核心属性包括源地址、目标地址、IP地址类型、源端口号、目标端口号、报文大小,本文中的NetFlow泛指能够支持类似功能的网络协议。
对于一个骨干网络,为了统计流量模式,需要在所有边缘路由器入口开启NetFlow采集,导致NetFlow系统每天需要处理数十TB甚至上百TB的原始记录,并且随着网络规模的不断扩张,系统需要具有接近线性的扩展能力。目前大型网络一般使用第三方流量分析系统,这类系统多采用私有分布式架构支持大规模处理,通过将采集器和分析器分离实现容量扩展。由于价格昂贵,这类系统在网络持续扩容时面临较大的成本压力,此外,开放性也相对较低,客户很难实现特定的分析需求。
另一方面,伴随着大数据技术的快速发展,新的分布式平台为处理大规模NetFlow数据提供了契机,尤其是Spark技术的出现,大规模数据处理在通用服务器集群上能够达到准实时的性能。本文提出了一种基于Spark平台的大规模NetFlow处理系统,通过实验表明,该系统具有很强的扩展能力,性能显著优于Hadoop MapReduce计算平台。
2 Spark技术介绍
Apache Spark是由UC Berkeley开源的类MapReduce新一代大数据分析框架,拥有Hadoop MapReduce的所有优点,与MapReduce不同的是,Spark将计算的中间结果数据持久地存储在内存中,通过减少磁盘I/O,使后续的数据运算效率更高。Spark的这种架构设计尤其适合于机器学习、交互式数据分析等应用,这些应用都需要重复地利用计算的中间数据。在Spark和Hadoop的性能基准测试对比中,运行基于内存的logistic regression,在迭代次数相同的情况下,Spark的性能超出Hadoop MapReduce 100倍以上。
Spark在设计上参考了Hadoop MapReduce,完全和Hadoop生态系统相兼容,如Spark底层的数据持久化部分就完全重用了Hadoop的文件系统,Spark也可以运行在Hadoop Yarn资源管理系统上。从大数据生态系统的发展来看,Spark的出现不是对以Hadoop为中心的大数据生态系统的取代,而是补充,更多的是深耕于MapReduce不适用的应用领域(如机器学习、流式计算、实时计算、交互式数据挖掘等)。但Spark又不局限于MapReduce简单的编程范式,Spark立足于内存计算,同时在上层支持图计算、迭代式计算、流式计算、内存SQL等多种计算范式,因此相对于MapReduce更具有通用性。
为了支持在多次迭代计算过程中重复利用内存数据集,Spark在借鉴传统分布式共享内存思想的基础上,提出了一种新的数据抽象模型RDD(resilient distributed dataset),RDD是只读、支持容错、可分区的内存分布式数据集,可以一部分或者全部缓存在集群内存中,以便在多次计算过程中重用。用户可以显式控制RDD的分区、物化、缓存策略等,同时RDD提供了一套丰富的编程接口,供用户操作。RDD是Spark分布式计算的核心,Spark的所有计算模式都必须围绕RDD进行。
3 基于Spark的NetFlow流量分析
NetFlow作为一种通用的数据报文格式,是典型的结构化数据,随着运营商网络的扩容与升级,NetFlow数据的生成速率和数据规模都出现了大规模的增长,NetFlow的数据分析是天然的大数据处理。典型的NetFlow解决方案是使流量采集系统和流量分析系统相分离,本文只讨论流量分析系统。
一种大规模的处理方法是使用MapReduce(以下简称MR)方案。在该方案中,当需要对NetFlow数据进行多维度、多次数的统计时,需要编写多个MR任务,这些任务被分别提交到集群上,以串行或者并行方式执行,任务之间无法共享内存数据,数据需要反复在内存和磁盘之间转移,导致MR分析任务有性能低、分析时延长、内存占用大等缺点。
Spark的出现有效地解决了MR执行过程中,中间数据不能缓存在内存中的问题。在基于Spark的分析系统中,NetFlow流量数据只需要从磁盘加载到内存一次,即可在该缓存数据上进行多维度、多次数的分析和查询,通过减少磁盘I/O,提高了分析性能,降低了分析时延,特别适合于NetFlow这种生成速率快、数据规模大的应用场景。
4 基于Spark的NetFlow流量分析系统架构
基于Spark的NetFlow数据分析数据流图如图1所示。NetFlow以文本记录的形式保存在HDFS上,Spark计算引擎调用textFile方法从HDFS上加载NetFlow数据到集群内存中,并将NetFlow数据转换为HadoopRDD[string]的形式。然后即可调用RDD上的编程接口如map、filter、reduce、join等,对NetFlow数据进行多维度统计分析。由于RDD的只读特性,每次对RDD的操作都会生成新的RDD,整个分析流程便形成如图1中所示的“管道”。计算过程中,可以根据需要对任意RDD通过调用persist的方法将该RDD缓存在集群内存中,以便后续基于该RDD的分析效率更高。对于不再需要的RDD,调用unpersist方法即可将该RDD从集群内存中清除,释放该RDD占用的内存空间。分析完成后,对于包含结果数据的RDD调用saveAsTextFile方法可将结果RDD中的数据持久化地存储到HDFS上。
上述NetFlow分析任务在Spark集群上运行时的图解如图2所示。整个分析任务由一个全局的用户driver程序、机器主节点上的master和若干集群从节点上的worker共同组成。提交到集群的driver程序和master进行通信,master内的DAGScheduler根据分析任务的具体情况对RDD上的计算过程划分阶段,如图1中分成了阶段1和阶段2。划分完阶段后,master内的taskScheduler将这些阶段包装成task的形式调度到worker上运行,worker在运行任务时需要和driver保持通信,以进行一些数据汇总的操作。在连续的多个分析任务运行过程中,RDD始终保持在worker的内存中,因此分析任务的执行速度很快、效率更高。
5 实验验证
本实验以基于Hadoop的应用构成统计为例,对比Spark和MapReduce在实际运行过程中的性能。应用构成统计根据应用的目标端口号对流量数据进行分类,统计不同类型应用流量的大小和占比情况。分别使用MR的编程接口和Spark的编程接口编写统计分析作业,并将作业代码打包上传到集群上执行。集群配置情况见表1。在集群上同时搭建Hadoop 2.2和Spark 1.0分布式环境,选择其中一台服务器作为Hadoop和Spark的主节点,其他7台服务器作为从节点。

表1 集群配置
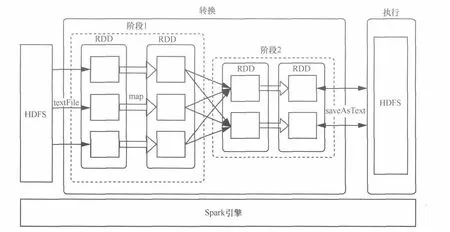
图1 NetFlow分析流图
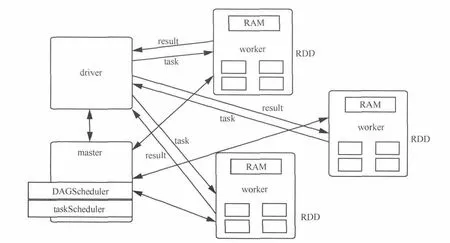
图2 NetFlow分析运行图
通过调整输入数据量的规模大小,测试MR和Spark作业的完成时间,性能对比结果如图3所示。从图3中可以看到,在输入数据规模相同的情况下,Spark作业的完成时间比MR更少,而且随着数据量的增大,Spark的性能超出了Hadoop 2倍以上。通过分析Spark和MR运行原理,可知Spark将HDFS上的数据抽象成RDD,并在计算过程中缓存在计算节点的内存中,加快了计算速度。同时Spark由于RDD的引入,每个节点上的计算任务以多线程的方式执行,相对于MapReduce为每个任务启动单独的Java虚拟机,效率更高。因此可知,在同等条件下Spark的计算性能要明显优于MapReduce。

图3 Spark和MapReduce性能对比
6 结束语
本文在研究Spark大数据平台基本原理的基础上,结合NetFlow数据规模大、生成速度快等特征,提出了使用Spark大数据平台对NetFlow数据进行统计分析的基本方法,并在具体的实验中对比了Spark和MapReduce在NetFlow数据处理上的性能差异。验证了Spark在NetFlow数据分析方面相对MapReduce,处理速度更快,效率更高。
1 White T.Hadoop:the Definitive Guide.O’Reilly Media Inc,2012
2 Zaharia M,Chowdhury M,Das T,et al.Resilient distributed datasets:a fault-tolerant abstraction for in-memory cluster computing.Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation,San Jose,CA,USA,2012
3 Rossi D,Silvio V.Fine-grained traffic classification with NetFlow data.Proceedings of the 6th International Wireless Communications and Mobile Computing Conference,Shenzhen,China,2010
