基于跨场景推理的事件关系检测方法
2014-02-27杨雪蓉陈亚东王潇斌姚建民朱巧明
杨雪蓉,洪 宇,陈亚东,王潇斌,姚建民,朱巧明
(苏州大学 江苏省计算机信息处理重点实验室,江苏,苏州 215006)
1 引言
事件(Event)是由特定人、物、事在特定时间和特定地点相互作用的客观事实,事件关系是事件之间相互依存和关联的逻辑形式,具有客观性、事实性和规律性三种主要特性,如“因果”(Contingency)和“时序”(Temporal)关系等。事件关系能将离散于文本中的事件相连接,形成事件关系网络和事件发展的拓扑脉络。事件关系检测是以事件为主体元素的自然语言逻辑关系抽取,它能够有效辅助事件衍生、发展与变异信息的推理与预测。
目前针对事件关系检测的研究刚刚起步,由于不具有权威的任务定义、事件关系体系以及评测标准,相关探索尚不深入,相应方法也仅仅着眼于某一特定事件关系类型(如“因果”关系)的判定,不具有全面性和普适性。相较而言,自然语言处理领域中的篇章关系检测和篇章关系分析作为自然语言处理领域中一项重要的基础性研究,旨在同一篇章内部,判断相邻片段或跨度在一定范围内的两个片段之间的语义连接关系。
文本中的事件通过文字诉诸后,成为信息传播中可读可解的事件文体(也称“事件体”,本文统称“事件”)。从而,事件的描述必须遵循自然语言的行文规律,例如,篇章结构、篇章修辞、语法和文法等规律。篇章关系检测以论元(即完整的语义单元,如句子)为对象,建立了较为全面的任务体系,其蕴含的概念、关系体系和评价方法也具有普适性,能够有效应用于事件关系检测任务。因此,事件关系检测与篇章关系检测任务有着一定程度的领域交差性。然而,事件关系并不等同于篇章关系,篇章关系检测不能涵盖所有事件关系检测的关键问题。
(1) 篇章关系检测任务涉及短语、子句、句子等文本片段之间的语义关系研究,通过分析两两邻或跨度在一定范围内的两个论元的语义连接关系,构建文本篇章关系结构,进而深入理解篇章语义;而文本中的事件往往离散分布,从而只受话题框架约束,因此不属于篇章关系的研究范畴。
(2) 篇章关系检测往往可以利用句法、语义和语境的局部特征予以方法设计与实现,而事件关系则必须依赖大规模数据估计和挖掘广域的关联线索进行方法设计与实现。从而,事件关系检测需要一种有针对性的专属的任务和研究体系,而不能将篇章关系检测体系简单移植和并用。
本文针对事件关系检测任务,提出一种跨场景的事件关系检测方法。事件场景由能够用于描述该场景的一系列组成元素构成。跨场景的事件关系检测方法的核心思想认为: 相同或相似的事件场景,通过挖掘其特征,有助于事件关系类型的推理。因此,本文首先构建事件场景及其关系类型,利用事件场景的关系类型对事件关系类型进行推理。跨场景的事件关系检测方法需要首先解决如下两点问题: 1)事件场景的匹配方法。即给定待测“事件对”,如何从已知关系类型的“事件对”中,得到与待测“事件对”相同或相似事件场景的“事件对”。2)事件场景的先验关系类型。事件之间的关系类型通过事件场景的关系类型推理得到,因此需要首先获得事件场景的先验关系类型。针对第一点,本文采用基于FramNet[1]的框架语义为事件描述构造事件场景的特征空间,从而将事件场景的相似度转化为特征空间的相似度;针对第二点,本文借助显式连接词,挖掘包含显式连接词且毗邻的“事件对”,同时,将显式连接词触发的某一类事件关系类型作为该“事件对”的关系类型,例如,连接词“because(因为)”往往触发“Causal(因果)”关系类型,进而利用已知关系类型的毗邻“事件对”构建事件场景的先验关系类型。
同时,根据事件关系检测和篇章关系检测的任务的异同点,本文提出基于篇章关系分析的事件关系检测体系,该体系包括事件关系检测的任务定义、关系体系以及评价方法等。同时,根据定义的事件关系体系,以Frame-1.5的新闻语料为数据源,对其中已标注的事件进行事件关系类型的标注。
本文组织如下: 第2节介绍事件关系检测的相关工作;第3节给出事件关系检测任务定义;第4节分析本文方法的动机;第5节详细阐述基于跨场景的事件关系检测方法的方法;第6节介绍实验;第7节总结。
2 相关工作
由于缺少公认的事件关系体系,目前针对事件关系的研究方法主要针对某种特定事件关系类型的判定进行研究[2-4],主要的挖掘方法分为模板匹配法和元素分析法。
模板匹配法
事件关系检测的主要方法之一是借助事件特征的模式匹配,例如,利用事件触发词的关系模式匹配,根据人工定义的模板,对文本中符合模板的事件关系进行抽取。 Chklovski[3]等首先定义6种时序关系: “similarity”(时序“相似”关系),“strength”(时序“加强”关系),“antonymy”(时序“相反”关系),“enablement”(时序“支持”关系), “happens”(时序“发生”关系)和“before”(时序“前”关系),再利用人工收集的LSP(Lexcial-Syntactic Pattern,即词-句匹配模板)抽取包含这6种时序关系的“事件对”,并将抽取的结果形成称为“VerbOcean”的知识库。人工定义的事件关系模板往往受数量限制,造成关系检测的低召回率问题。Pantel[4]通过Espresso算法进行自动模板的构建,算法首先给定少量关系实例,通过机器学习方法对现有模板进行迭代扩展,在一定程度上提高了模板匹配方法的召回率。
元素分析法
以事件元素为线索的研究大都继承了Harris[5]的分布假设。Harris假设指出,处在同一上下文环境中的词语具有相同或相似的含义。Lin[6]提出了一种结合Harris分布假设和建立依存树思想的无监督方法,称为DIRT算法。算法将所有事件构造成依存树形式,树中的每条路径表示一个事件,路径的节点表示事件中的词语,若两条路径的词语完全相同,则这两条路径所表示的事件相同或者相似。
3 任务定义
事件关系检测任务的目标在于实现事件间逻辑关系的自动检测。本节介绍事件、事件关系类型以及事件关系检测的任务定义。
3.1 事件
自动内容抽取(Automatic Content Extraction,简称ACE)任务将事件定义为由事件触发词和事件参与者组成,其中,事件的触发词能够描述一个事件的发生,以动词或者动名词为主;事件的参与信息为事件参与者,通常为名词。例如,事件Evt1:
(1) Evt1: “奥巴马击败麦凯恩”
事件Evt1中“击败”能够描述该事件的发生,因此,“击败”为该事件的触发词,则称Evt1为“击败”事件。事件Evt1中“奥巴马”和“麦凯恩”为“击败”事件的参与信息,即“击败”事件的参与者。
3.2 事件关系
事件关系表示事件与其相关事件之间相互依存和关联的逻辑形式,是事件之间固有的一种客观存在。然而,目前针对事件关系检测任务缺少公认的事件关系体系,本文将篇章关系体系与事件关系进行分析和对比,选取篇章关系体系中能够应用于离散“事件对”的篇章关系类型作为事件关系类型。同时,篇章关系与事件关系的差异性使得篇章关系不能描述完整的事件关系类型,因此,本文借助事件关系实例,人工总结事件关系类型,进一步对事件关系类型进行补充,确保事件关系体系的完整性,由此形成的事件关系体系如表1所示。
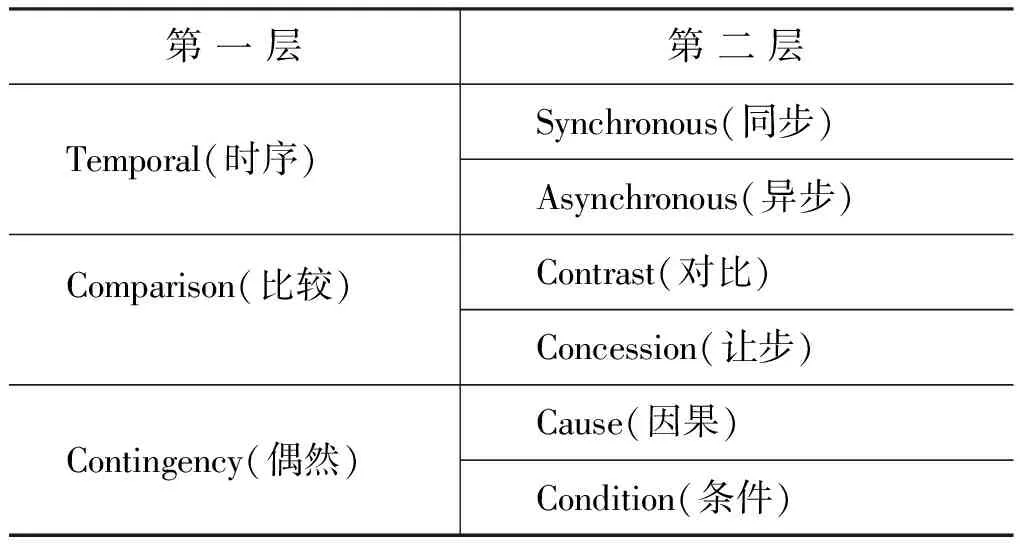
表1 事件关系体系

续表
表1定义的事件关系体系共分为两层,第一层包含四种主要关系类别: Temporal(时序)、Comparison(比较)、Contingency(偶然)、Expansion(扩展),第二层为以上四种关系类型的扩展,共有10种子类型。
3.3 事件关系检测
事件关系检测是一种针对“事件间存在何种逻辑关系类型”进行自动判定的深层事件关系判定任务。事件关系检测通过解析文本结构或语义特征,对文本中描述不同自然事件的文本片段(包括短语、子句、句子和段落)给出明确的语义关系或逻辑关系标签(如“因果”、“时序”、“扩展”和“对比”等)。该任务框架如图1所示,其中,该任务的输入为已知相关的两个事件,通过分析“事件对”的逻辑联系,输出该“相关事件对”的逻辑关系类型。

图1 事件关系检测任务框架
4 动机
本文借助篇章分析任务实现事件关系检测。本节介绍篇章分析任务,以及框架语义和借助框架语义构建事件场景的方法。
4.1 篇章分析
篇章分析的核心任务是判定“论元对”之间的语义或修辞关系。目前篇章关系分析分别针对显式篇章关系和隐式篇章关系进行研究,且显式篇章关系和隐式篇章关系分析的性能相差较大。
显式篇章关系可直接根据显式连接词推断篇章关系,并且能够取得较优的性能,相关研究对于显式篇章关系最终分类的精确率可达93%[7];而隐式篇章关系的分类性能则相对较低,隐式篇章关系检测的主体研究主要分为基于关系特征的机器学习方法和基于概率统计的方法[8-10]。显式篇章关系和隐式篇章关系分析的性能相差较大的原因在于,显式篇章关系以显式连接词为主要线索,借助连接词与篇章关系的一一映射,能够较精确地推断特定篇章关系,例如,PDTB关系样本库中,连接词“Because(因为)”指向“Contingency.Cause(偶然.因果)”关系的概率为100%。隐式篇章关系由于缺少显式连接词信息,相关研究通过结合句法、语义、相关领域知识等构建上下文信息,推断隐式“论元对”的逻辑关系。实验表明,篇章的上下文信息仍存在不确定性,这种上下文信息的不确定性、句子结构的复杂性以及语义关系的歧义性,使得目前针对隐式篇章关系研究的性能总体较差,因此,借助篇章关系分析检测事件关系,必须突破隐式篇章关系检测这一关键难点。
4.2 框架语义
本文采用FrameNet(框架语义)框架语义描述事件场景。FrameNet是由美国加州大学伯克利分校构建的基于框架语义学 (Frame Semantics)的词汇资源,对词语意义和句法结构研究提供一种理论框架,框架语义知识库通过框架描述单词的释义,即词语背后隐藏的概念结构和语义等信息。从而,框架语义能够形成特定场景(包括事件、状态、关系或实体)的概念表述。在框架语义知识库中,对句子的框架语义标注是一种类似于“谓词—论元”结构的“目标词—框架语义”(Target-Frame)结构。每个句子可能包含一个或多个“目标词—框架语义”结构,例如,例(2)描述的事件:
(2) Evt1 : “IreneleftSherlockinacomawiththeMickeyFinnaftergettingthecodeofthesafebox.”
(译文: “艾琳得到保险柜的密码后,利用混有麻醉的酒让夏洛克昏迷”)
通过框架语义的分析,能够得到如下“目标词—框架语义”结构: “MickeyFinn(混有麻醉的酒)—Drag(药物)”、“code(密码)—Message(信息)”和“safebox(保险箱)—Safebox(保险箱)”,同时,本文将事件中的框架语义的组合定义为该事件的事件场景。不同的事件描述存在相同的事件场景,例如,例(3)中描述的事件:
(3) Evt2: “Georgerememberedthebeautifulladyaskedhimaboutthecodeofthebankaccountafterdrinkingsomuchliquor.”
(译文: “乔治记得一位美丽的女士在他喝完很多酒之后询问他的银行密码”)
通过FrameNet解析,例(3)中的“liquor(酒)”同样触发了“Drag(药物)”框架语义,例(2)和例(3)中的其他“目标词—框架语义”结构如表2所示。

表2 例(2)和例(3)中“目标词-框架语义”结果
从表2中可以看出,尽管例(2)和(3)中描述不同的事件,但两个事件具有相同的框架语义,则认为两个事件描述了相同的事件场景。
4.3 事件场景
跨场景的事件关系检测方法的核心思想认为: 相同或相似的事件场景,通过挖掘其特征,有助于事件关系类型的推理。例如,有如下两个“事件对”:
(4)E1:Hewasshotbyaterrorist.
(译文: 他被恐怖分子击中了 )
E2:Heunfortunatelypassedaway.
(译文: 他不幸去世了)
(Relation=Contingency.Cause)
(关系=偶然.因果)
(5)E1:Bombswentoffattrainstations.
(译文: 炸弹在火车站爆炸了 )
E2:Manypeoplewerefeareddead.
(译文: 担心很多人死亡了 )
(Relation=? )
(关系=?)
其中,已知例(4)中描述的两个事件为“偶然.因果”关系类型。若仅考虑上述事件描述的篇章修辞、语法和文法等规律,难以利用例(4)的信息推理例(5)中“事件对”的关系类型。本文提出的跨场景的事件关系检测方法首先判断例(4)中的“事件对”描述了“袭击”场景和“死亡”事件场景,若定义例(4)中的事件关系类型“关系=偶然.因果”为“袭击—死亡”场景的关系类型,由于例(5)同样描述了“袭击”场景和“死亡”事件场景,将事件场景的关系类型作为该“事件对”的关系类型,则推理得到例(5)中“事件对”的关系类型为“关系=偶然.因果”类型。
5 基于跨场景推理的事件关系检测方法
本文致力于探究一种基于跨场景推理的事件关系检测方法,其核心思想是: 具有相同事件场景的事件对,往往具有相同的事件关系类型。该方法分为三个主要部分: 显式“事件对”的挖掘、事件场景关系类型映射以及事件关系判定。
另外,本文进一步提出一种事件场景向量的事件场景构建方法作为比较。
5.1 显式事件对的挖掘
本文首先通过连接词,从大规模语言学资源(Gigaword)中挖掘包含连接词的事件对,事件对的挖掘必须满足如下规则:
“PreGram+,connective+PostGram”
其中,“PreGram”为前置论元,“connective”为连接词,“PostGram”为后置论元。通过连接词挖掘得到的“事件对”的关系类型,有该显式连接词唯一指定。PDTB中共定义182个连接词,而这些连接词与关系类型并非一一对应,为了实现“事件对”及其关系类型的精准抽取,本文仅仅选取PDTB中的Golden连接词。Golden连接词指该连接词在篇章中指向某一关系类型的概率较高。本文针对PDTB中连接词的分布,统计了各连接词指向某一关系类型的概率,如表3所示。
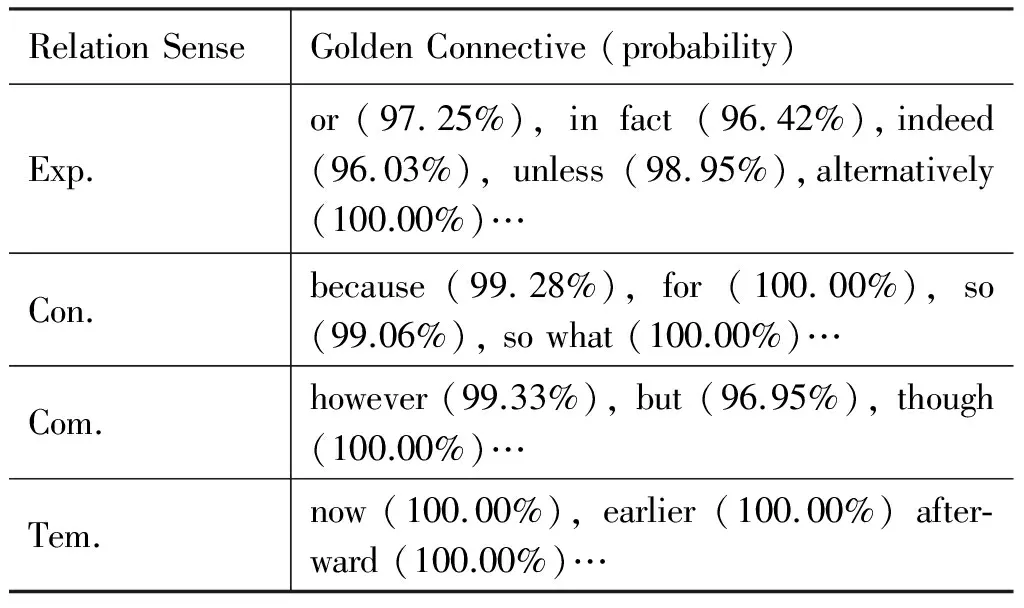
表3 PDTB中连接词的分布,统计了各连接词指向某一关系类型的概率
表3显式各连接词在四种篇章关系类型中出现的概率,例如,连接词“alternatively(选择地)”指向“Expansion(扩展)”关系类型的概率为100%。本文仅选取指向某一关系类型概率大于80%的连接词作为Golden连接词。同时,将Golden连接词指向概率最大的关系类型,作为该Golden连接词的先验关系类型。进而将Golden连接词的先验关系类型作为通过Golden连接词挖掘得到的事件对的关系类型。
5.2 事件场景关系类型映射
本文对Golden连接词挖掘得到的“事件对”,进一步分析其包含的框架语义,利用框架语义构建“事件对”的“事件场景对”。同时,借助显式连接词对篇章关系的映射,构建“事件场景对”中两两框架语义与关系类型的映射,即“框架语义对-关系”,最终“框架语义对”的关系类型由大规模样本中的极大似然关系估计,方法细节如下:
Step1: 利用SEMAFOR*http://www.ark.cs.cmu.edu/SEMAFOR工具分析“事件对”中的框架语义。例如,前置论元通过分析得到框架语义集合FrameSet1: {Frame11,Frame12, …,Frame1m};前置论元通过分析得到框架语义集合FrameSet2: {Frame21,Frame22, …,Frame2n};
Step2: 将FrameSet1和FrameSet2中的框架语义两两组合,形成“框架语义对”: {Frame1i,Frame2j}i=1, …,m,j=1, …,n. 其中,“框架语义对”的关系类型为该“事件对”中显式连接词对应的关系类型;
Step3: 对由Gigaword挖掘得到“事件对”,进行Step1到Step2操作。
由以上步骤得到的“框架语义对”存在多种关系类型映射,为了实现“框架语义对-关系”的一一映射,本文对每个“框架语义对”进行极大似然关系的概率估计。给定“框架语义对”及其在各个关系类型的概率分布P(r),选取分布概率最高的关系类型,作为该“框架语义对”的极大似然关系,如式(1)所示。
(1)
r∈{Syn,Asy,Cont,…,Ins}
其中,nr为“框架语义对”指向关系类型r出现的次数,N为“框架语义对”指向所有关系类型的次数。“框架语义对”的极大似然关系作为该“框架语义对”的先验关系类型。
5.3 事件关系判定
本文利用“事件场景”的关系类型对事件关系进行推理。针对待测“事件对”,同样利用框架语义构建其“事件场景对”,进而将已获得的“事件场景对”的先验关系类型,作为该“事件对”的关系类型。具体步骤如下:
Step1针对每一个待测“事件对”,分析其包含的框架语义,分别得到事件event1的框架语义集合FrameSet1: {Frame11,Frame12, …,Frame1m} ,以及事件event2的框架语义集合FrameSet2: {Frame21,Frame22, …,Frame2n};
Step2将FrameSet1和FrameSet2中的框架语义两两组合,形成“框架语义对”;
Step3利用“框架语义对”的关系类型推理事件场景的关系类型,一个“事件场景对”包含多个“框架语义对”,将所有“框架语义对”指向出现次数最多的关系类型,作为该“事件场景对”的关系类型;
Step4“事件场景对”的关系类型将作为“事件对”的关系类型。
同一事件场景可以概括不同的事件描述,而这些不同的事件均为相同的事件类型。事件场景并非孤立,它们之间存在逻辑关联性,因此事件场景能为事件关系分析和推理提供重要线索。本文重复利用事件场景的关系,推理事件之间的关系类型。
5.4 事件场景向量
为了与上述方法进行比较,本文同时提出一种事件场景向量的事件场景构建方法。该方法包括两部分: 事件场景向量的构建以及事件关系类型预测。
该方法首先构建事件场景的场景向量。针对5.1中挖掘得到的“事件对”以及待测“事件对”,通过SEMAFOR分析其包含的框架语义集合,将该集合中的框架语义表示成空间向量,将该向量作为事件的场景向量,各维度将作为该场景向量的组成成分。每个“事件对”形成 “事件场景对”。将待测“事件对”与挖掘得到的“事件对”样本进行相似度匹配,其中相似度的计算为“事件场景向量”间的cosine值,匹配过程如图2所示。
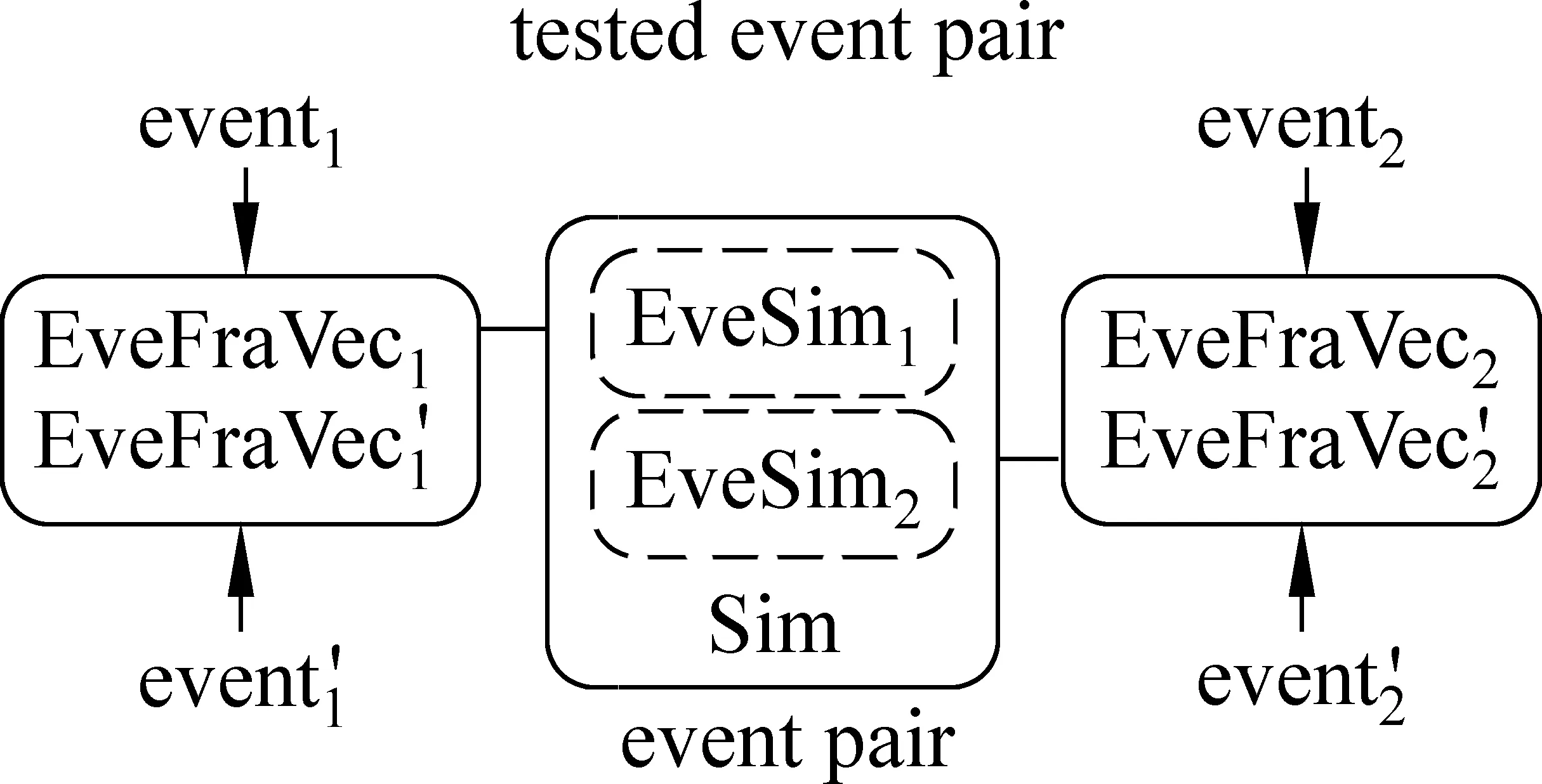
图2 “事件场景向量”匹配
其中,EveFraVec1为前置事件的“事件场景向量”,EveFraVec2为后置事件的“事件场景向量”,分别得到前置事件的相似度EveSim1和后置事件的相似度EveSim2,将两个相似度值进行合并,合并后的值为该“事件场景对”的相似度,相似度合并如式(2)所示。
(2)
其中,分子为两个相似度之和,同时,为了平衡两个相似度的值,将相似度之和除以两个相似度的差值,为确保分母的值不为0,采用相似度差值的指数形式。
通过待测“事件对”与样本“事件对”的相似度计算,选取与待测“事件对”相似度最高的样本“事件对”作为待测“事件对”的平行“事件对”,该平行“事件对”的关系类型即为待测“事件对”的关系类型。
6 实验与结果
本节介绍实验设置,包括本文的语料标注、评价方法以及实验系统。同时介绍本文的实验结果及对结果的分析。
6.1 实验设置
本文选取FrameNet-1.5中的新闻语料作为标注数据集,标注人员对每篇新闻中描述的事件以及事件间的关系类型进行标注。该数据集由两名具有一定领域知识的标注人员进行标注。同时,本文利用Kappa值对标注结果的可用性进行评价,最终标注的Kappa值为0.78。
本文共标注了828个事件以及968个“事件对”及其关系类型,其中出现次数最多的关系类型为“Expansion.List(扩展.并列)”。标注的“事件对”及其关系类型的分布情况如表4所示。本文采用Accuracy值作为评价方法,其计算公式如式(3)所示。
(3)
该评测方法早期应用于二元分类精度的评测。例如,需要评价“事件对”是否为“Expansion”类型,其中,All为待测“事件对”的总个数,TruePositve为本身具有“Expansion”关系且系统判定其具有“Expansion”关 系 的“事 件 对”个 数;TrueNegative
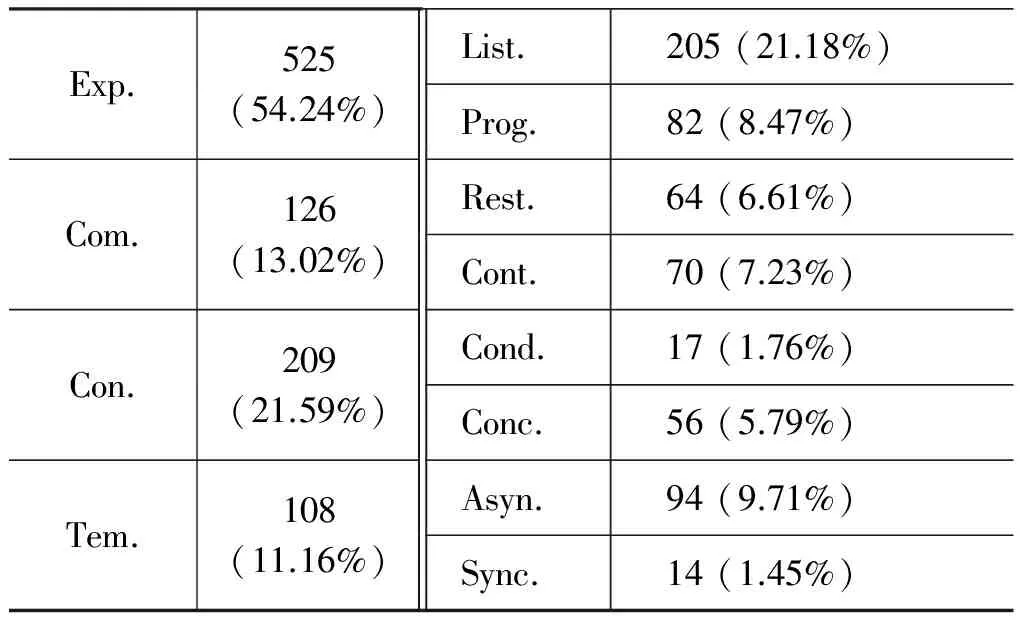
表4 标注的关系类型的分布
为本身不具有“Expansion”关系且系统未判定其具有“Expansion”关系的“事件对”个数。当该评测方法用于多元关系评价时,将TrueNegative设置为恒定值0,只检验每个待测“事件对”是否判定为正确的关系,即只计算TruePositve指标与All 的比值。本文首先定义了三个实验系统:
• System1(Baseline): 该系统遵循5.1至5.3中的事件场景构建方法,区别在于,构建事件场景并非使用框架语义,而直接将事件描述中的词汇作为特征,构建事件场景。
• System2: 遵循5.1至5.3中利用“框架语义对”的事件场景构建方法。
• System3: 遵循5.4中利用“事件场景向量”的事件场景构建方法。
然而,待测“事件对”中的关系分布与从Gigaword中挖掘得到的“事件对”中的关系类型分布不一致,为了使两者的分布情况相同,本文采用重采样技术,扩展挖掘得到的“事件对”中关系类 型 较 小 的“事件对”,使得两者的关系类型分布情况相同。因此,本文又扩展了两类系统:
• System4: 在System2方法的基础上,增加重采样技术。
• System5: 在System3方法的基础上,增加重采样技术。
6.2 实验结果及分析
表5为以上五个系统针对事件关系检测结果的性能,包括四个大类及十个小类的Accuracy值:
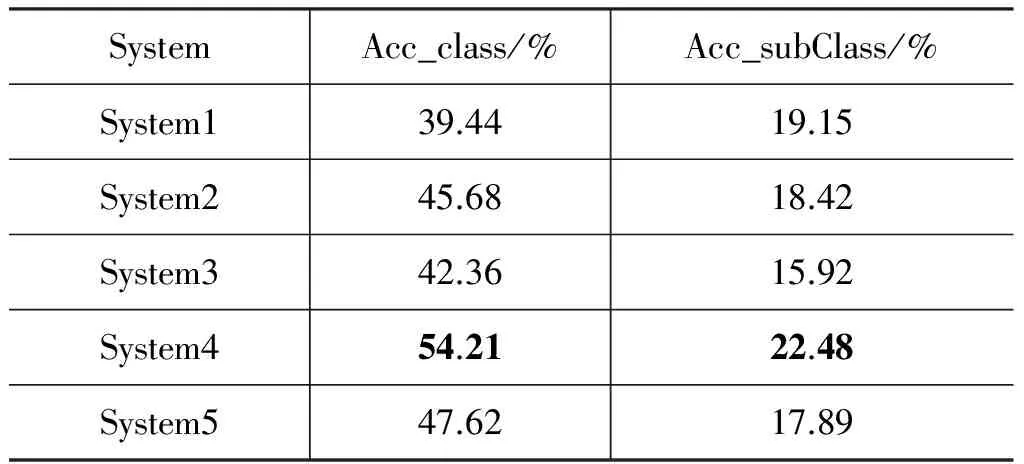
表5 系统的Accuracy
表5显示,System1采用的使用事件描述中词汇作为特征的方法得到的性能最低,System2和System3采用事件场景作为特征的方法高于System1的方法,同时,采用重采样的方法对结果的精确率也有所提高,其中System4相对于System2在四大类的结果提高了8.53%,十小类的结果最高提高了4.06%;System5相对于System3在四大类的结果提高了5.26%,十小类的结果最高提高了1.97%。System3的性能最高。
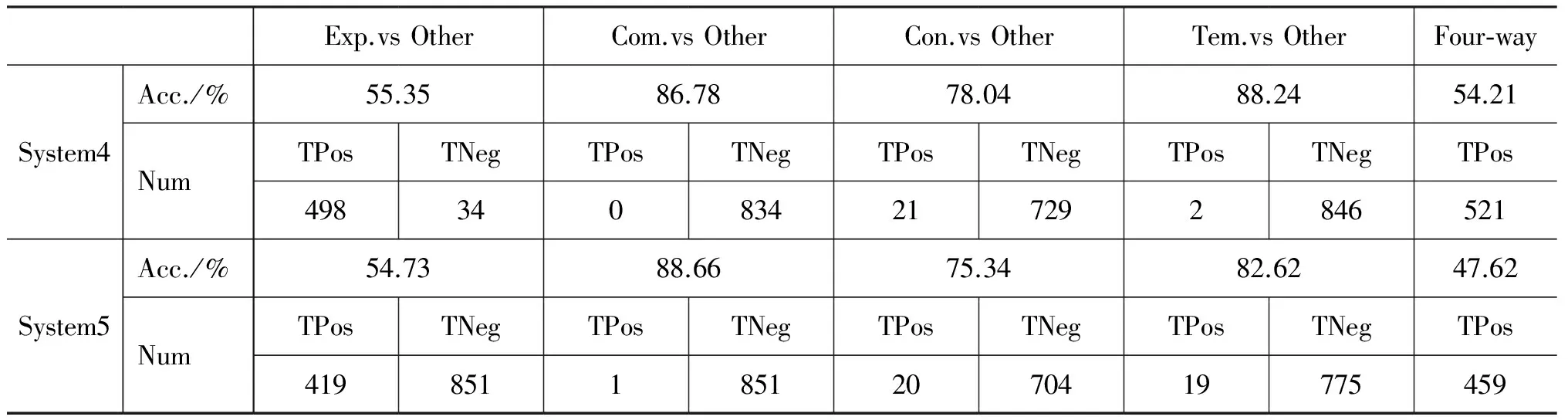
表6 System4和System5针对每一大类的Accuracy及识别个数
本文进一步分析System4和System5针对每一类事件关系类型的识别性能。表6显式System4和System5分别对每一大类的精确率,以及正确识别的个数(Num),包括正确识别为目标类型的个数(TPos)和正确识别为非目标类型的个数(TNeg)。
表7为System4和System5分别对每一小类的精确率,以及正确识别的个数,从表中可以看出,本文的方法针对小类别的检测效果较差,体现了事件关系检测任务仍然比较难,需要更进一步的研究。

表7 System4和System5针对每一小类的Accuracy及识别个数
7 总结
本文首次针对事件关系检测研究建立了一套研究体系,包括任务定义、关系体系划分、语料采集与标注、评价方法等。同时,提出了一种跨场景推理的事件关系检测方法,该方法构建事件的事件场景,以此作为特征,实现事件的逻辑关系检测。实验结果显示,构建事件场景的方法优于直接采用文本特征的方法。今后的工作在于,根据事件场景元素的重要程度,为场景元素设置程度,从而更准确地描绘事件的场景特征。
[1] C J Fillmore, C Johnson, M Petruck. Background to FrameNet[J]. International Journal of Lexicography,2003,16(3): 235-250.
[2] C Hashimoto, K Torisawa, J Kloetzer, et al. Toward Future Scenario Generation: Extracting Event Causality Exploiting Semantic Relation, Context, and Association Features[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Baltimore, 2014.
[3] TChklovski, P Pantel. Global path-based refinement of noisy graphs applied to verb semantics[C]//Proceedings of Toward Future Scenario Generation: Extracting Event Causality Exploiting Semantic Relation, Context, and Association Features, Jeju Island, Korea, 2005: 792-803.
[4] PPantel, M Pennacchiotti. Espresso: leveraging generic patterns for automatically harvesting semantic relations[C]//Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the ACL, Sydney, Australia, 2006: 113-120.
[5] Z S Harris. Mathematical Structure of Language[M]. New York, 1968.
[6] D Lin, P Pantel. Discovery of Inference Rules from Text[C]//Proceedings of the 7th ACM SIGKDD, San Francisco, California, USA, 2001: 323-328.
[7] E Pitler, M Raghupathy, H Mehta, et al. Easily identifiable discourse relations[C]//Proceedings of the 22nd International Conference on the COLING, 2008: 87-90
[8] E Pitler, M Raghupathy, H Mehta, et al. Easily identifiable discourse relations[C]//Proceeding of the 22nd International Conference on Computational Linguistics (COLING 2008), Posters, Manchester, UK, 2008: 87-90.
[9] The Penn Discourse Treebank 2.0 Annotation Manual, 2007
[10] Y Hong, X P Zhou, T T Che, et al. Cross-Argument Inference for Implicit Discourse Relation recognition[C]//Proceedings of the 21st ACM International Conference on Information and Knowledge Management(CIKM 2012),2012: 295-304.
