基于DirectShow的视频实时校正系统设计
2014-02-13冯可,周军
冯 可,周 军
(上海交通大学上海市数字媒体处理与传输重点实验室,上海200240)
责任编辑:任健男
自2010年3D电影《阿凡达》上市以来,3D技术得到了极大的关注,对于3D技术相关的研究日益深入,3D节目的受众群体也日益广泛。随着3D技术的研究深入,观测的舒适度成为了一个非常重要的问题,它不仅影响着人们观看3D节目时的感受,更影响着观测者的身体健康。研究表明,有很多因素影响着3D视频的观测舒适度,其中双路视频中的垂直视差是极其重要的一项指标。
在实际的拍摄过程中,由于双视点相机摆放位置的不精确,拍摄得到的双路视频中存在垂直视差这类几何失真是无法避免的。为了消除立体视频中的几何失真导致的垂直视差,人们提出了各种摄像机标定和图像极线校正算法,不过这些算法多用于图像或者视频的后期处理,难以做到在拍摄的同时得到较好的结果。如果能够在拍摄的同时对所得到的视频序列进行处理,消除其垂直视差,不仅可以大大降低后期处理的难度和工作量,也将因校正后3D视频的舒适性质量提高而有效降低3D节目的制作门槛,从而促进3D产业的发展。
但随着1 080高清视频甚至4K视频的应用范围越来越广,图像极线校正算法的运算量越来越大,具体来讲,对于双路高清1 080 50i格式的输入,系统的处理速度要达到50 f/s(帧/秒),相应的吞吐量要达到3 Gbit/s,对于每一帧图像的极线校正时间需要控制在20 ms以内。另外在实时进行极线校正处理的同时,还应当能够实时地使拍摄人员观测到处理的结果,以进行及时的调整,包括更改校正的参数甚至直接调整相机的位置,这样才能提供更大的可操作性。
针对以上的研究需求和难点,使用传统的CPU架构尚无法完成实时校正处理。本文使用GPU并行架构完成了极线校正的过程,每帧的处理时间达到10 ms,实现了处理速度上的实时性;另外为了能够实时采集并输出处理结果,使用了DirectShow技术开发了用于3D高清视频极线校正的过滤器,从而达到了3D高清视频的实时采集、极线校正和输出。
1 系统的方案设计
1.1 系统的总体框图
根据引言所述,系统所需完成的三大需求为:实时获取双目视频流,根据预先设定好的参数对双目视频流进行高速的极线校正,将校正结果送至屏幕或采取其他的输出方式实时提供给用户观测。按照这三大需求,本文的高清视频实时极线校正系统的设计框图如图1所示,最终使用这个框图设计得到的系统将为这一整套流程提供一个完整的解决方案。

图1 高清视频实时极线校正系统框图
在该系统中,数据的整体流向为从左至右。首先由输入模块根据输入的设置,负责完成双目视频序列的实时采集获得双目序列,并将所得到的数据流向下游传输至校正模块;接下来由校正模块根据设置好的一对单应矩阵完成实时的极线校正功能,并将得到的结果数据流向下游传输至输出模块;输出模块根据输出的设置,将最终的结果展示到计算机屏幕、储存为相关文件或者通过SDI接口进行输出。
1.2 DirectShow简介
本系统涉及到了高带宽的多媒体流的采集、传输和处理,采用微软公司提供的DirectX软件开发包,可以大大降低开发难度,而且使程序在未来也可以得到兼容和支持。
DirectShow是DirectX家族的一个成员,是专门为在Windows平台上处理各种格式媒体文件的回放、音视频采集等高性能要求的多媒体应用的一种实现方案。Direct-Show系统的结构如图2所示,图中最大的一块就是DirectShow系统。虚线以下是Ring 0特权级别的硬件设备,虚线以上是Ring 3特权级别的应用层。DirectShow系统位于应用层,使用过滤器图表管理器来管理整个数据流的处理过程。参与数据处理的各个功能模块叫作过滤器(filter),各个过滤器在图表管理器中按一定的顺序连接成“流水线”协同工作。
1.3 数据的传输
在DirectShow中,模块将被实现为过滤器。每个过滤器都有自己的Pin,各个过滤器之间就是通过这些输入/输出Pin来连接。Pin的连接其实是双方使用的媒体类型的一个协商过程,而真实的数据传输单元叫作Media Sample。它也是一个COM组件,管理一块数据内存,由分配器来管理。
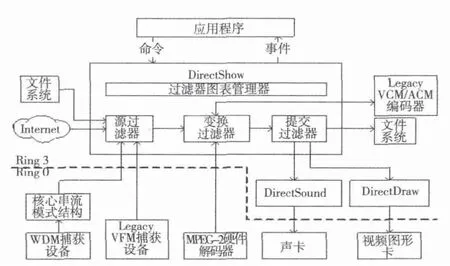
图2 DirectShow系统结构图[1]
数据传送的模式有两种,一种是推模式,另一种是拉模式。推模式常用于实时源的数据处理,每采集到一个Media Sample就将其向下游传输,而拉模式常用于文件源的数据处理,每当下游处理完一个Media Sample就从文件源获取数据。
2 输入/输出模块实现
2.1 输入模块流程
输入模块流程图如图3所示。在输入流程开始时,首先遍历所有的硬件输入设备;接下来由用户指定从哪个设备获得,并将指定源过滤器加入图表管理器;然后获得其支持的视频和音频输入格式,当用户选择了一个相应的视频格式之后,将这个源过滤器与AVI Decompressor过滤器相连,并从其X Form Out PIN获得向下游传输的视频数据;当用户选择了一个相应的音频格式之后,便可以直接从源过滤器的audio capture PIN获得向下游传输的音频数据。

图3 输入模块流程图
2.2 输出模块流程
输出模块流程图如图4所示,输出模块根据用户所选择的输出位置,相应地向过滤器图表中加入文件写入过滤器、视频渲染过滤器(一般默认为VMR9)和设备渲染过滤器。在过滤器添加好之后,将上游校正模块处理过的视频流和由输入模块直接传出的音频流接入即可将最终的数据传送至用户所期望的输出位置。

图4 输出模块流程图
2.3 实现中的细节
需要把设备输入的YUV格式数据高速转换为易于处理的RGB格式,DirectShow已经提供了一个具有该功能的过滤器AVI Decompressor,该过滤器可以向下游的过滤器提供RGB格式的Sample数据,利于进行处理。
在枚举设备接口时调用的PopulateDeviceControl()函数中,可以得到计算机所提供的所有连接设备的接口,每一个接口都可以获得其连接设备的名字,默认情况的名字是以16进制的代码显示,例如{Device-17CCA71BECD7-11D0-B908-00A0C9223196},这样的名字对用户并不友好,可以通过pPropBag->Read(L"FriendlyName",&varName,0)语句,来使显示的名字为用户友好的名字,例如显示为WDM Capture Device。
除了按照流程编写程序,还应加入组件初始化,注册到活动对象表,以及相应的对象销毁和内存释放过程。注册到活动对象表可通过AddGraphToRot(m_pGraph,&m_ROTRegister)语句来实现,注册之后才可以在微软提供的Graphedit软件中使用Connect to Remote Graph来观测当前的链路状况,方便进行调试。
2.4 同步性保证
既然涉及到了多媒体视频的处理,就一定要解决同步问题,在本系统中涉及到两种同步问题:一是单路序列的音视频同步,二是双目序列之间的视频同步。如果双路序列不同步,校正的结果也就失去了意义。
DirectShow系统已经提供了解决方案,就是利用过滤器图表的参考时钟,可以直接把单路序列的音视频同步,让双目序列所在的两条链路使用同一个参考时钟便可以解决双目序列之间的视频同步。
3 校正模块实现
3.1 极线校正的相关原理
3D视频极线校正的目的是消除左右视频中的垂直视差,从而消除垂直视差引起的不舒适感,传统的视频极线校正过程可以分为有相机标定的方法和无相机标定的方法。
在无相机标定方法中使用文献[2-3]中的误匹配剔除算法,再利用LM优化获得左右视频分别的单应矩阵,并利用这一对矩阵分别对左视频和右视频的每一帧进行投影变换,从而得到极线校正后的图像。
校正的基本公式为

利用式(1)进行校正需要反向填充,首先求校正矩阵H的逆,然后利用公式
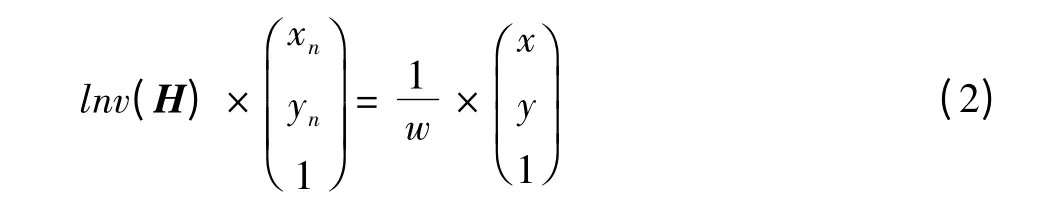
3.2 校正流程
校正处理模块接受上游传送而来的视频流,并对每一帧图像进行校正处理,再将其向下游传输,其内部的算法流程图如图5所示。首先检查输入PIN传入的数据格式是否符合要求,如果不符合将给出提示,否则解析帧头信息获得图像的大小和色度信息,从而选择适当的校正函数进行调用。

图5 校正模块流程图
校正函数由GPU实现,调用函数时将数据传输至GPU,进行并行处理,再将处理好的结果传输回主机端。最后加入相应的帧头信息,向下游传输。
3.3 GPU算法的实现细节
GPU有着良好的并行计算能力,已经在很多领域有应用[4-5],例如全息影像、语音识别等。对于高清视频的极线校正过程,GPU的架构尤其适用,因为每个坐标映射及插值计算过程完全相同且与其他过程无关,非常利于通过并行来获得巨大的加速比。本文采用的是NVIDIA公司的CUDA架构,它利用多个流处理器分块(block)执行运算任务,每个块中也可以同时开启多个线程(thread)。通过Host主机端调用在Device上运行的Kernel函数,程序会按照设置好的Grid,Block,Thread数目进行并行运算。
用GPU实现实时极线校正算法,其核心函数的实现形式和调用形式分别为:
__global__void warpKernel(uchar*src,uchar*dest,double*parameter)
dim3 blocks(60,34),threads(32,32);
warpKernel<<<blocks,threads>>>(dev_imgL,dev_resultL,dev_leftM);
在实现过程中,要注意以下几个细节:
1)为了使GPU的运算效率达到最高,在核函数内部尽量减少分支判断的次数。
2)因为要处理的src和dest均是图像,可以视为二维的数组,于是使用cudaMallocPitch()代替cudaMalloc()来执行间距分配。由于硬件中的间距对齐限制,在显存和内存之间复制这块内存区域将会略微提高效率。
3)因为CUDA模型中每个流处理器可以同时处理8个线程,为了充分利用资源,创建32的倍数个线程。
3.4 过滤器实现细节
要想在过滤器中使用GPU,需要先编写好Kernel函数并编译,并在过滤器的实现文件中用extern C声明,之后便可以直接在Transform核心函数中,调用声明好的cudaTest函数:
extern"C"void cudaTest(uchar*src,uchar*dst,uchar*dev_imgL,int rows,int cols,uchar*dev_resultL,double*dev_leftM);
要想使用自己编写的过滤器,可以通过将该过滤器导出成dll形式的方式来实现。但在实现中,没有必要非要以COM组件的形式使用过滤器,可以直接实例化一个过滤器,并手工添加引用计数,然后获取IBaseFilter接口并通过该接口对编写的过滤器进行操作,部分代码如下:
CRectFilter*pFLeft=new CRectFilter();
pFLeft->AddRef();
pFLeft->SetParameters(RectHomoL,1080,1920,1);
hr=pFLeft->QueryInterface(IID_IBaseFilter,reinterpret_cast<void**>(&pRectLeft));
hr=m_pGraph->AddFilter(pRectLeft,L"My Rectification Left");
4 实验结果
首先,利用GPU并行进行实时校正的结果如图6所示,从上方牌匾处的“交通”二字以及石狮子的头部可以看出,垂直视差得到了有效的消除。

图6 校正前后的红青立体图对比
极线校正所需的时间数据如图7所示,多核CPU的效率远远落后于GPU,NVIDIA Quadro K4000显卡对于1 080视频帧的处理时间(包括内存与显存之间传输图像数据的时间)为7 ms,处理帧的速度为140帧/秒(f/s),比CPU提速了20倍,达到了实时的速度要求。但在显存和内存各缓存一帧的数据,所以实际上的处理和播放延时为2帧。
最终利用编写好的极线校正过滤器来实现高清视频的实时校正和播放的过滤器图表如图8所示,其中视频数据流由采集卡传入,经过AVI Decompressor后由YUV422格式转变为RGB24格式,再经由实现的Rectification过滤器最终提供给屏幕进行输出显示,最终的播放丢帧数为0,达到了预期效果,开发用于3D高清视频极线校正的过滤器,从而实现了3D高清视频的实时采集、极线校正和输出。
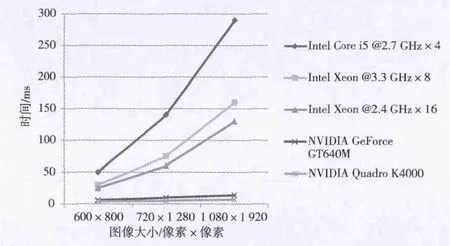
图7 极线校正所需时间图

图8 利用实时极线校正过滤器播放视频的过滤器图表
[1]陆其明.DirectShow开发指南[M].北京:清华大学出版社,2003.
[2]YAO D,ZHOU J,XUE Z.Homography matrix genetic consensus estimation algorithm[C]//Proc.IEEE ICALIP.[S.l.]:IEEE Press,2011:1139-1143.
[3]姚达,周军,薛质.计算机视觉中强鲁棒性的遗传一致性估计[J].计算机工程,2011,37(20):183-185.
[4]郑专,安平,张秋闻,等.基于GPU加速的深度图像绘制[J].电视技术,2012,36(11):11-14.
[5]仇德元.GPGPU编程技术——从GLSL、CUDA到OpenCL[M].北京:机械工艺出版社,2011.
