基于社区时空主题模型的微博社区发现方法
2014-02-10朱欣焰
段 炼,朱欣焰
(1. 广西师范学院北部湾环境演变与资源利用教育部重点实验室 南宁 530001; 2. 广西师范学院资源环境科学学院 南宁 530001;3. 武汉大学测绘遥感信息工程国家重点实验室 武汉 430079; 4. 武汉大学空天信息安全与可信计算教育部重点实验室 武汉 430079)
微博作为目前最具代表性的社交网络服务,逐渐成为一种重要的沟通工具和平台。由于其实时性高、流量大、内容覆盖面广,近年来,微博已经成为社会舆论、商业营销和城市功能的“传感器”。所谓社区,是指用户根据小世界特性聚集形成若干群体。发现微博中的社区,能更好地理解信息传播模式和用户交互模式群体演化规律,具有重大的学术和应用价值。微博社区主题表现为:属于该社区的用户所发表和转发微博的内容趋向于某(几)个特定的主题,如“体育”“科技”等。多个用户对某一主题的频繁讨论形成了针对该主题的用户社区。然而,大部分算法基于用户社会关系(如关注对象、好友)和微博消息转接应答(转帖,跟帖、评论)的疏密程度来发现社区,或基于聚类等模型进行网络分割以获取社区,忽略了社区的潜在主题特征。社区潜在主题表现为:属于该社区的用户所发表和转发微博的内容趋向于若干个特定的信息类别,如“体育”“科技”等,反映了用户在若干方面的兴趣倾向。而多个用户对某一主题的频繁讨论形成了针对该主题的用户社区。可见,社区主题与社区结构相互影响,特定主题的形成反映了某个社区的出现,而社区的出现促使了某些主题更加突出。在引入微博主题进行社区发现的研究中,文献[1]利用LDA[2]分析Tw itter中的用户同质性,挖掘活跃的微博用户群组,文献[3]基于用户间的互访类型和微博主题相似性进行社区发现,文献[4]利用主题模型获取社区主题,计算出用户隶属于某个社区的概率,文献[5]通过伯努利分布表达用户主题在时间上的分布。
此外,用户发送的微博主题与周边地理环境特征紧密相连[6]。如在东湖周边人们发的微博以“游览”主题为主,在武汉广场发的微博则以“购物”主题为主。可见,局部地理区域具有特定的经济文化,环境对微博主题具有较大影响。近年来,微博对地理位置标识的功能为研究时空环境与微博内容之间的关系提供了支撑。一般来说,两个用户访问相同地理区域的次数越多,这些局部地理区域社会环境对他们的吸引程度就越相似,表明他们社会生活模式或兴趣偏好越相似,则这两个用户越有可能属于同一社区;另一方面,属于同一社区的用户,由于他们具有相似的生活模式或兴趣偏好,则他们越倾向于访问相同的地理区域。此外,由于社会生活的作息规律、社会习俗等原因,不同时间段内用户关注的对象是不同的,造成微博在不同时间下表达不同的主题,因此发现微博主题随时间变化的特点,同样能提高对社区的识别能力。
由于主题模型对文本的强大建模能力和灵活的扩展机制,本文将扩展主题模型引入时空要素提高微博主题识别能力。在时空相关的主题模型中,已有研究将全局空间区域划分为若干地理区域,再依据落在地理区域内的微博获取该区域的主题。地理区域的划分方式主要有如下4种:规则格网[7]、辖区(如省界、区界等)[8-9]、不规则格网(如泰森多边形网)和自适应区域划分[6]。前3种方法固化了区域边界,不利于描述相似微博主题在空间上的转移;最后一种方式依据微博主题相似性和空间邻近性,利用二维高斯分布较好的表达了相似主题微博的空间覆盖范围。然而,已有自适应区域划分方法没有给出潜在地理区域空间范围的限制条件,易造成某些潜在地理区域覆盖的空间范围过大。如文献[7]采用二维高斯模型表达相似博客主题的潜在地理区域中,一些潜在地理区域跨越大半个美国,部分潜在地理区域间还相互重叠。这种情况造成区域内主题分布趋于背景主题分布,无法突出区域“特色”主题分布,失去在主题模型中引入空间要素的意义。同时,已有方法还需预先设定潜在地理区域数量,无法利用数据自身的特征自适应调整潜在地理区域范围和数量。此外,已有方法没有顾及用户对地理区域的选择偏好。
为克服以上问题,本文构建社区时空主题模型(community spatio-temporal topic model, CS-TM),在主题模型中引入狄利克雷过程混合模型(dirichlet process m ixture model)[11],以自动生成不同覆盖范围地理区域和微博地理位置,并通过地理区域和社区两者微博主题的相互影响,提高微博社区的发现能力。
1 微博社区挖掘
1.1 微博要素构成
每条微博d表示为6个要素:d=(W,t,l,r,u,c)。其中,W表示该微博“词袋”模型;t表示微博发布时间;l表示微博发布的地理位置;r表示微博潜在地理区域;u表示微博用户;c代表用户所在社区。
1.2 空间和用户对微博主题的制约
微博中常常体现如“娱乐”“交通”“饮食”等话题,这些话题表达了大众用户的一种基本社会见识,称为背景主题,其多项式分布参数用0q表示。将全局空间划分为多个潜在地理区域。由聚集在潜在地理区域的微博主题共同产生区域-主题分布参数为rq。


1.3 社区和时间对微博主题的制约


1.4 空间、社区对微博词汇的制约
相同主题下用户在不同位置会使用不同的词汇。如同样是“交通”主题,在飞机场发出的词汇和在火车站发出的词汇就不同。因此,微博词汇受背景环境、潜在地理区域和社区影响,共同控制主题z下的词汇生成概率,基于稀疏增量式生成模型可得词汇w的多项式分布:

1.5 时空主题模型



图1 社区时空主题模型
1.6 时空主题模型参数计算
基于EM方法和Gibbs采样[10]估计时空主题模型的参数。
1) E步骤,对潜在变量采样。这里的潜在变量分别是微博d所在的潜在地理区域r、社区c和主题z:
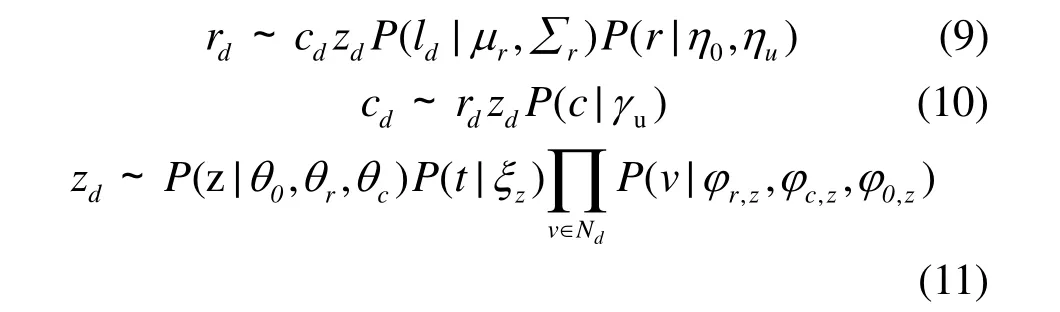
通过狄利克雷过程表示微博d位于某个已存在潜在地理区域rj或新潜在地理区域r¢的概率。因此,修改式(9),采用“Chinese restaurant”[11]的方式进行rd采样:
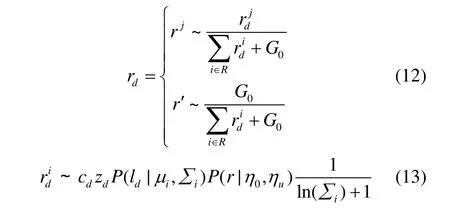
2) M步骤,固定各潜在因素,对模型的后验似然值最大化,获取模型参数。
更新代表潜在地理区域r的二维高斯分布参数:
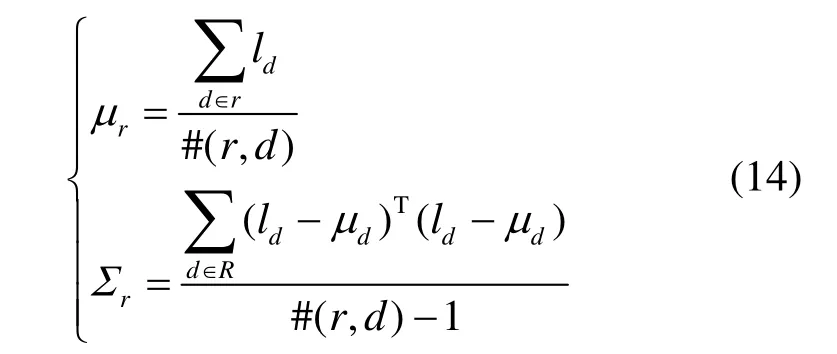
式中,#(r,d)表示r中微博总数;ld为微博地理坐标。
以下采用梯度下降法进行其他参数的迭代推理。
下式用于计算潜在地理区域分布参数的梯度值。其中,du,r表示用户u在区域r中所发微博数量;du表示用户u所发微博总数:

综上所述,在E步骤中,结合狄利克雷过程和模型中各参数,计算出微博主题、潜在地理区域和社区潜在因子;在M步骤中,通过梯度下降方法,得到模型中各个参数更新值。如此反复,直到模型各参数收敛。
最终按照用户u属于各社区的概率ug值的高低,即可将用户划分到不同社区中。社区间可相互重叠,即一个用户可属于多个社区,因此,取ug的top-k(一般k=3)个概率最大gu,c所对应的社区c作为候选集合,假设共有个社区,设定阈值将的社区c作为用户u隶属的社区。
2 实 验
2.1 数据预处理和模型参数设置
实验使用的服务器配置为Intel(四核,3.1G)酷睿i53450,8 GB内存,装载Windows Server 2008操作系统。利用新浪微博API,基于用户好友和关注对象爬取微博后,经过去噪处理得到80 492条微博和9 264个用户。主题模型的超参数a0、ac、ar统一设为50/Z,0b、cb、rb统一设为0.005,Ou、ur均设定为0.5。
2.2 社区主题
设微博数据集的主题数量|Z|为60,社区数量|C|为20,基于同一社区内各用户主题和词汇获得社区的主题-词汇分布。选择其中5个社区及与其相关度最高的前10个词汇,每个社区下词汇出现的概率列在该词汇右边,如表1所示,表中可明显发现,同一社区的词汇具有显著的语义相似性,不同社区的词汇含义相差显著,如社区1的词汇主要表达科技和体育主题,社区2主要表达社会和工作主题,社区3主要表达购物、饮食主题,社区4主要表达生活、娱乐等主题,社区5主要表达工作、学习等。

表1 5个社区及与其相关度最高的10个词汇
2.3 实验结果和分析
本文提出的时空主题模型(CS-TM)与DCTM[1]和LDA[2]进行比较,其中,DCTM与CS-TM的社区确定方式相同;基于LDA的社区发现是通过主题分布进行k-means聚类。每个聚类簇即为社区。
本文利用社区内外链接比[5]反映社区-内用户交互程度,采用社区内用户间主题分布的KL距离(kullback-leibler)来衡量社区用户主题的相似性。社区内外链接比为:
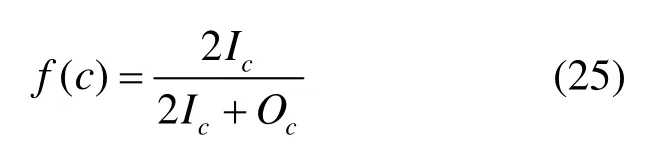
式中,Ic为社区c内用户间的链接数量,链接数量通过用户的好友、关注和跟帖数量获取;Oc为社区c内用户与社区c外用户的链接数量。f(c)越大,表明社区内用户较社区外用户的联系越密切;反之,表明社区内用户的联系并不紧密。图2显示了3种方法在不同社区数量情况下的平均社区内外链接比。随着社区数量的增加,各模型获取的平均社区内外链接比上升,社区涉及的微博内容范围逐渐缩小,用户间的联系频率提高。
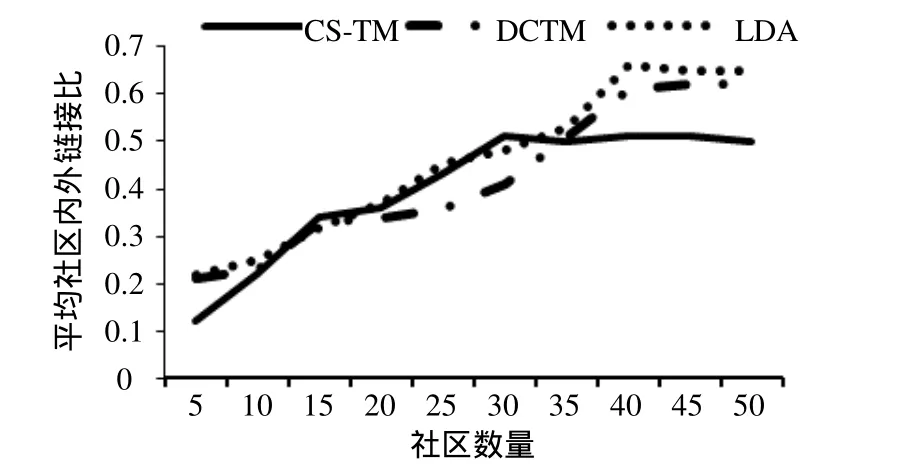
图2 3种方法的社区内外链接比
然而,在社区数量为5~35时,3种方法的平均社区内外链接比类似,但DCTM稍低;在社区数量超过35后,CS-TM的平均社区链接度较LDA和DCTM都要低。这表明本文方法获取的社区内用户的联系程度不如LDA方法和DCTM方法所获取的紧密。分析发现,CS-TM所获取的社区中包含的主题分布聚焦性强,即社区中的用户所发微博大都集中在若干特定主题,相对而言,LDA和DCTM划分出的社区,微博涉及的主题类型比较分散。这反映了主题聚焦的用户间,总体上相互交流较少;反之,一个人所发微博的主题类型越多,其对外交流越频繁。在社区数量超过40后,各方法得到的平均社区内外链接比趋于稳定。以上实验体现了微博中专业人员(或兴趣极少的用户)之间的交流不够紧密,而具有大众性和社会性主题的微博在用户间传播广泛。本文方法能发现那些兴趣类型少但兴趣类似的用户,如果应用于“用户推荐”,则能精准提高这一类用户之间的交流程度。
KL距离用以衡量相同事件空间里的两个概率分布的差异情况。KL距离越小,表明社区内用户主题相似度越高,反之,社区内用户的兴趣差异越大,则社区形成的可能性越低。由于,KL距离不具有对称性,因此基于KL距离的对称平滑版本——Jensen-Shannon(JS)距离表达社区c内用户间的平均KL距离:

式中,u为用户,每个用户的主题由其所发微博主题表示;|c|表示社区c内的用户数量。3种方法得到的平均社区KL距离如图3所示。随着社区数量的增加,社区内用户兴趣相似性逐渐增强,3种方法的社区平均KL距离逐渐降低,但同样由于CS-TM引入的时空信息增强了微博主题获取的正确性,提高了社区内主题相似程度。LDA中,每个用户仅属于同一个社区,但由于LDA对微博主题获取准确率较低,类似语义的词汇被划分到不同主题中,造成处于同一社区的主题较为分散,同一社区内的用户主题差异性较大。DCTM对微博主题的识别能力较LDA要高。因此,其构建的社区中,用户间的主题较LDA更为相似。随着社区数量的增加,3种方法得到的社区平均KL距离的区域平稳。
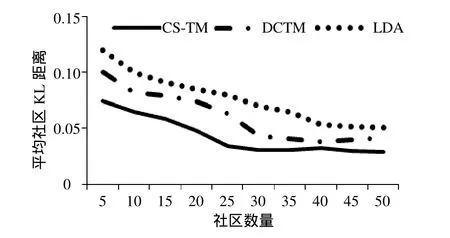
图3 3种方法的社区内平均KL距离
可见,由CS-TM模型生成的社区,其内部用户主题相似性高,社区间区分度良好。
3 结 语
本文将地理区域、社区和连续时态要素引入主题模型,综合考虑了用户对社区及潜在地理区域的偏好,利用Dirichlet process mixture model自适应划分潜在地理区域,弥补了以往方法中单个潜在地理区域范围过大和主题分散的不足;同时,揭示了社区与具有特定社会功能地理区域间的互动关系。最终通过实验验证了该方法对社区发现的有效性。今后将引入用户间的链接信息,进一步提高微博主题提取和微博社区发现的性能。
[1] WENG Jian-shu, LIM E P, JIANG Jing, et al. Tw itter rank:finding topic-sensitive in fluential tw itterers[C]//Proc of the 3rd ACM International Conference on Web Search and Data M ining. New York: ACM, 2010.
[2] BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003,3(1): 993-1022.
[3] 闫光辉, 舒昕, 马志程, 等. 基于主题和链接分析的微博社区发现算法[J]. 计算机应用研究, 2013, 30(7): 1953-1957.
YAN Guang-hui, SHU Xin, MA Zhi-cheng, et al.Community discovery for microblog based on topic and link analysis[J]. Application Research of Computers, 2013, 30(7):1953-1957.
[4] YIN Zhi-jun, CAO Liang-liang, GU Quan-quan, et al.Latent community topic analysis: integration of community discovery w ith topic modeling[J]. ACM Transactions on Intelligent Systems and Technology, 2012, 3(4): 63-84.
[5] LI Dai-feng, DING Ying, SHUAI Xin, et al. Adding community and dynamic to topic models[J]. Journal of Informetrics, 2012, 6(2): 237-253.
[6] YIN Zhi-jun, CAO Liang-liang, HAN Jia-wei, et al.Geographical topic discovery and comparison[C]//The 20th international conference on World Wide Web(WWW). New York, USA: [s.n.], 2011.
[7] EISENSTEIN J, O’Connor B, SM ITH N A, et al. A latent variable model for geographic lexical variation[C]//The 20th Conference on Empirical Methods in Natural Language Processing. M IT, Massachusetts, USA: Association for Computational Linguistics, 2010.
[8] SIZOV S. GeoFolk. Latent spatial semantics in web 2.0 social media[C]//The 3rd International Conference on Web Search and Data M ining(WSDM). New York, USA: ACM,2010.
[9] MEI Qiao-zhu, Liu Chao, SU Hang. A probabilistic approach to spatiotemporal theme pattern m ining on weblogs[C]//The 15th international conference on World Wide Web(WWW). Edinburgh, Scotland: ACM, 2006.
[10] GRIFFITHS T L, STEYVERS M. Finding scientific topics[C]//Proceedings of the National Academy of Sciences (NAS), USA: [s.n.], 2004.
[11] BLEI D M, GRIFFITHS T L, JORDAN M I. The nested chinese restaurant process and bayesian nonparametric inference of topic hierarchies[J]. Journal of the ACM, 2010,57(2): 111-142.
[12] EISENSTEIN J, AHMED A, XING E P. Sparse additive generative models of text[C]//The 28th International Conference on Machine Learning(ICML). New York, USA:ACM, 2011.
编 辑 叶 芳
