一种基于TCM-SVDD的样本类别标注方法
2014-02-07朱海潮崔立林
朱海潮,崔立林
1 海军工程大学 振动与噪声研究所,湖北武汉430033
2 海军工程大学 船舶振动噪声重点实验室,湖北武汉430033
0 引 言
船舶低速航行时的主要噪声源是机械噪声[1],因此,辨识其主要机械噪声源对于船舶噪声状态的动态管理及其控制非常重要。但由于全船机械噪声的测试不易进行,且费用昂贵,通常难以得到足够多的训练样本,因此是一个小样本条件下的模式识别问题。
小样本条件下的模式识别所面临的主要问题是:一方面,由于训练样本不充分,导致通过学习机器得到的分类器难以获得理想的泛化性能(Generalization Ability)[2],即该分类器可能对已有的样本能够取得很好的分类效果,但不能保证对陌生样本的辨别能力;另一方面,由于已有训练样本数据覆盖的模式类别较少,导致对新出现的故障模式无法进行有效识别。
国内外对于小样本问题早已开始研究[3],并引入了神经网络方法[4-6]。在现有方法中,增量学习是一条有效的途径,通过对实际情况下新出现的样本进行类别检测,将与现有小样本训练集同类的样本作为训练集的扩充,可逐步解决小样本问题。但在进行增量学习之前,必须对新增样本的类别进行有效识别,这可归结为一个异类样本的识别问题。针对异类样本的检测问题,美国哥伦比亚大学的Eskin 等提出的基于聚类的估计算法、改进的k 近邻方法以及one-class SVM 方法是其中具有影响力的3 种方法。但是,这些方法仍具有较高的误报率,并且由于计算量过大而导致其实用性不强。针对这些情况,文献[7]提出了一种新的基于TCM-KNN 算法的异类样本检测方法,并且通过引入遗传算法[8],对TCM-KNN 算法进行了改进,与上面给出的3 种常用方法相比,具有较高的检测率和较低的误报率。但该方法要穷尽未知样本的所有可能分类,加之最近邻分类器(KNN)自身的特点,导致该算法的计算量巨大,而且该方法对训练集的质量要求较高,如果训练集中混有异类样本,会极大地影响最终的异类样本检测结果。为了克服以上两个缺点,本文将提出一种新的TCM-SVDD 方法,并进行舱段模型试验,结果将表明,该方法能够快速、准确地识别异类模式样本,并且该方法对训练样本集中混有少量异类模式样本的情况不敏感。
1 支持向量数据描述算法简介
支持向量数据描述算法(Support Vector Data Description,SVDD)是近年来兴起的性能优越的单值分类法,是由Tax 和Duin[9]提出并发展起来的。它是通过正常样本的训练来寻找一个能包括全部或绝大部分正常样本的、具有最小体积的超球体,落在超球体外的新样本将被判断为异常样本。
假定一个目标集包含N 个目标样本{xi,i=1,2,...,N},SVDD 的基本思想是寻求一个最小容积的超球体,以使所有的(或者绝大多数)目标样本都包含在该球体内。由于目标集的样本分布有可能包含极少数极为偏远的样本,因此引入松弛因子ξi,允许部分数据点在球体以外,则超球体可以用式(1)表示:

式中:R 和a 分别为超球体的半径和球心;变量C控制错分样本的比例和算法复杂程度之间的折中;松弛因子ξi用于控制超球体以外数据点与球心的距离。目标集形成的约束条件为

于是,问题转换为在约束条件式(2)下求超球体的最小半径,这是一个二次优化问题。构造拉格朗日算式:

式中,拉格朗日乘子αi≥0,γi≥0。求偏导,得

根据约束条件式(4)重构式(3),可得

对式(5)求最小值得出最优解αi。对于αi不为0 的对象就称为支持向量,只用它们就可以进行超球体描述。一个测试点z 是否被接受为目标样本,只需要看测试点到超球体中心的距离是否小于半径R,即

式中,T 为转置符号。
式(6)用支持向量表示即为

在最优分类面中采用适当的满足Mercer 条件的内积核函数K(xi·xj)就可以实现从低维向高维空间的映射,从而实现某一低维空间的非线性问题向高维空间的线性问题转换,相应地,式(5)与式(7)分别变为式(8)和式(9):

2 TCM-SVDD 方法
TCM 的目标是获得一般独立同分布假设下可用的置信测量,这恰好与Kolmogorov 算法随机性理论定义的随机检测(randomness test)紧密联系[10],该检测不可计算但可以进行近似,其结果称为P 值。P 值计算的基础是奇异测量(strangeness measure),奇异测量的结果称为奇异值。在实践中,TCM 将已知样本和未知样本排列构成样本序列,穷尽未知样本的所有可能分类,并对每种可能分类下的样本序列的随机性进行检测,然后根据P 值来估计未知样本属于不同类别的置信度,实现置信判断。目前,常用的检测函数是Saunders等[11]提出的P 典型性函数。
假设{(x1,y1),(x2,y2),…,(xm,ym)}是训练样本集,其中每一个样本包括数据xi和它的标签yi。因为本文只区分正常类样本和异常类样本,所以训练样本的标签满足y1=y2=…= ym=1,即全部为正常类。(xnew,y)为测试样本,其标签y 为未知。TCM-SVDD 方法的详细步骤如下:
第1 步:将训练样本和测试样本组成一个新的样本集{(x1,y1),(x2,y2),…,(xm,ym),(xnew,y)}。
第2 步:通过SVDD 方法计算样本集{(x1,y1),(x2,y2),…,(xm,ym),(xnew,y))}中每个样本的拉格朗日乘子αi,获得序列{α1,α2,…,αm,αnew}。
第3 步:每个样本的拉格朗日乘子αi表征了该样本的奇异程度,可以作为该样本的奇异值,因此得到各个样本的奇异值序列{α1,α2,…,αm,αnew}。
第4 步:使用Saunders 等提出的P 典型性函数计算测试样本xnew被归为正常类时的P 值,函数具体如下:

式中:#表示集合的基数;αnew为测试样本xnew的奇异值;αi为第i个训练样本的奇异值。
第5 步:判断样本正常与否。预先确定置信水平,例如,假设1- δ 为置信水平,0<δ <1,其中δ 被称为显著性水平。如果P(αnew)<δ,则测试样本被分为异常类样本;如果P(αnew)>δ,则测试样本被分为正常类样本。
3 试验研究
为了验证上述方法的可行性,采用1∶1 的双层壳体舱段模型进行试验,在模型内部布置电机、激振器和海水泵各1 台,设备布置如图1 所示。
试验测试系统采用的设备包括:B&K 1049 信号发生器、B&K 2707 功率放大器、B&K 4801T 激振器、B&K 3560D+PULSE 8.0 信号采集系统及PCB 352C33 ICP 型加速度计。
为了验证在较复杂工况下本文所提出方法的自动标注性能,在试验中将3 台设备全部开启,通过调整激振器激励电压模拟3 种工况模式,具体如表1 所示。

图1 试验场景图Fig.1 The experiment scene

表1 试验工况表Tab.1 List of experimental conditions
3.1 数据预处理
试验系统的分析频率为800 Hz,采样频率为800×2.56=2 048 Hz,采样时间为8 s,每类噪声源模式分别采集16 384 个采样点。以布置在壳体上的振动加速度测点采集的数据作为分析对象,随机选取其中连续的1 024 个采样点为一个样本。每类工况生成200 个样本。
对每个样本计算其功率谱,频率分辨率Δf=2 Hz,则每个样本可转化为一个400 维的特征向量。本文未对特征向量进行特征提取或特征选取的处理。
3.2 标注性能比较
通过工况2 模拟已有小样本数据模式,选取该工作状态下的10 个样本作为训练样本。从3 个工况中各选100 个样本组成测试样本集,比较3 种方法的自动标注性能:
1)常用的SVDD 算法;
2)TCM-KNN 算法;
3)本文提出的TCM-SVDD 算法。
针对TCM-KNN 和TCM-SVDD 算法,设置置信水平为95%。在TCM-KNN 方法中,最近邻参数k 从1~9 变化。自动标注结果和时间花费如表2所示。
其中,正确标注率表示对测试样本集中工况2 样本的正确识别率,错误标注率表示将测试样本集中工况1 和工况3 的样本标注为工况2 样本的比例。当最近邻参数k>4时,TCM-KNN 方法的结果基本没有变化,所以在表2 中没有列出k>4的计算结果。花费时间为在相同配置计算机上执行算法所需要的时间。

表2 不同方法的检测准确性和时间花费比较结果Tab.2 Comparison of identification accuracy and time costs of different methods
因为对样本进行标注的目的是为了实现小样本训练集的扩容,所以需要错误标注率越小越好。从上表中可以看出:
1)本文提出的TCM-SVDD 的标注效果是3种方法中最好的,在保证没有错误标注的情况下,仍然能够将96%的工况2 样本标注出来,且时间开销较TCM-KNN 方法大大减少。究其原因,是SVDD 方法将问题转化为了不等式约束下二次函数寻优问题,其计算复杂度不再取决于空间维数,而是取决于样本数,尤其是样本中的支持向量数,这大大提高了运算速度,并且能够有效解决特征参数的高维问题。
2)最近邻参数k 的选取对TCM-KNN 方法有较大影响,在实际应用中,应该根据具体情况进行选择。
3.3 低信噪比情况检测结果
为测试不同信号干扰程度下TCM-SVDD 方法的性能,本文通过在采集的时域数据中人工加入白噪声来模拟实现不同的信噪比,并将其与SVDD 方法和TCM-KNN 方法进行比较。数据处理方式与3.1 节相同,正确标注率和错误标注率的定义与3.2 节相同。SNR=5,0,-5 dB 这3 种情形下的检测结果如表3 所示。

表3 不同信噪比条件下检测结果Tab.3 Test results of different SNR
不难发现,随着信噪比的降低,3 种方法的检测准确率均出现了下降,尤其是当SNR=-5 dB时,此时白噪声信号的能量已超过真实信号能量,真实信号已完全湮没在白噪声信号中,而此时TCM-SVDD 方法的正确标注率仍能达到86%,错误标注率为5%,明显优于SVDD 方法和TCM-KNN 方法。
3.4 训练样本中混有非目标类样本的检测结果
以工况1 模拟目标类样本,工况3 模拟非目标类样本。从工况1 中选取50 个样本与工况3 中的9 个样本共同组成训练样本集,模拟训练样本集中存在非目标类样本的情况。从工况1 和工况3中各选取100 个样本组成测试样本集,分别用TCM-SVDD 方法和TCM-KNN 方法进行自动标注。通过表2 可知,对于TCM-KNN 方法,当最近邻参数k=4 时错误标注率为0,所以取k=4 且置信水平设为95%。当训练集中包含工况3 的样本个数从0~9 变化时,对测试集样本中目标类样本的准确标识率结果如图2 所示。
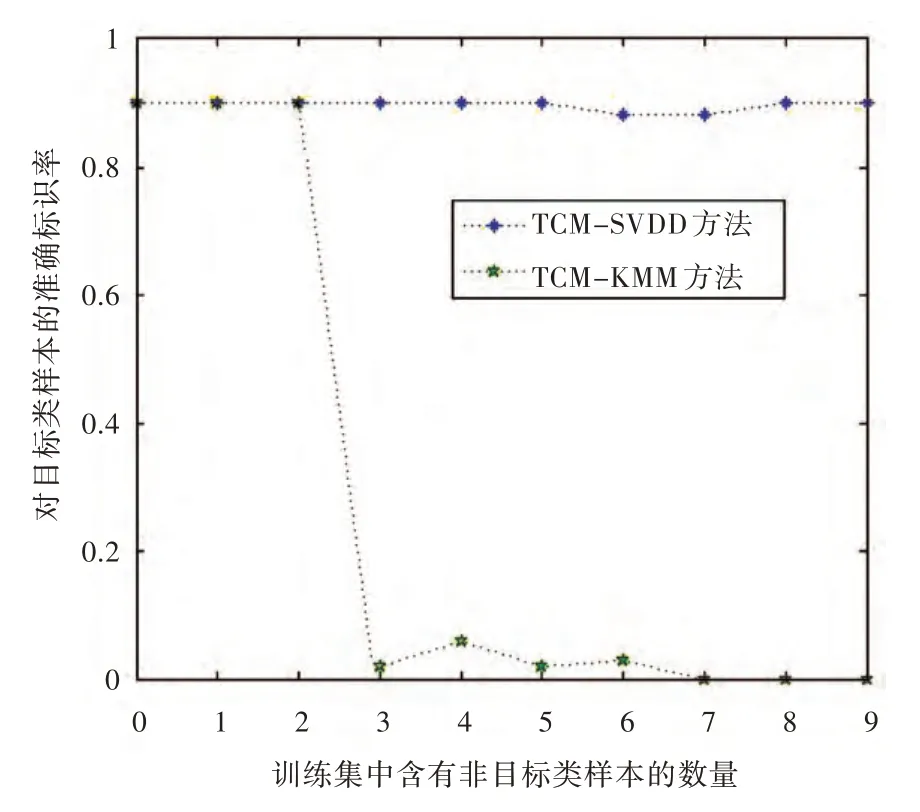
图2 训练集中非目标类样本数量对标识准确率的影响结果Fig.2 Influence of the number of non-objective samples in the training set on the label right rate
从图2 中可以看出,TCM-KNN 方法对于训练集中包含非目标类样本的情况非常敏感,当训练集中混合的非目标类样本个数小于参数k 时,该方法能够对测试样本集中的目标样本进行有效标注,但当训练集中非目标类样本的数量接近或大于参数k 时,TCM-KNN 方法将得到错误的标注结果。而本文提出的TCM-SVDD 方法在这种情况下仍能够保持较好的性能,说明本文方法对训练集质量的鲁棒性较好。
4 结 论
本文提出了一种新的异类样本检测方法,舱段模型试验验证了该方法的可行性。试验结果表明:
1)本文提出的TCM-SVDD 方法在样本类别标注准确率和时间花费方面优于常用的TCM-KNN 和SVDD 方法,在低信噪比情况下仍能取得较好的结果。
2)TCM-KNN 方法是求解待检测样本与训练样本集中最近邻样本的距离,作为奇异值的表征,如果训练样本集中含有异类样本,该方法将无法得到正确的结果;而TCM-SVDD 方法对训练样本集质量的鲁棒性更好,当训练集中含有少量异类样本时,也可以获得很好的效果。
3)由于本文方法引入了直推置信机理论,在保证对异类样本检测准确性可控的情况下(通过合理设定置信水平1-δ 进行控制),本文方法可自动完成异类样本的检测,有效降低了对人工干预进行异类样本标注的需求。
[1]吴国清,李靖,陈耀明,等. 舰船噪声识别(Ⅰ)——总体框架、线谱分析和提取[J]. 声学学报,1998,23(5):394-400.WU Guoqing,LI Jing,CHEN Yaoming,et al. Ship ra⁃diated-noise recognition(Ⅰ)—the overall framework,analysis and extraction of line-spectrum[J]. Acta Acustica,1998,23(5):394-400.
[2]CHAPELLE O,VAPNIK V,BENGIO Y. Model selec⁃tion for small sample regression[J]. Machine Learn⁃ing,2002,48(1/3):9-23.
[3]RAUDYS S J,JAIN A K. Small sample size effects in statistical pattern recognition:recommendations for practitioners[J]. IEEE Transactions on Pattern Analy⁃sis and Machine Intelligence,1991,13(3):252-264.
[4]HAMAMOTO Y,UCHIMURA S,KANAOKA T,et al. Evaluation of artificial neural network classifiers in small sample size situations[C]//Proceedings of 1993 International Joint Conference on Neural Networks(IJCNN' 93-Nagoya),1993:1731-1735.
[5]UEDA N,NAKANO R. Estimating expected error rates of neural network classifiers in small sample size situations:a comparison of cross-validation and boot⁃strap[C]// Proceedings of IEEE International Confer⁃ence on Neural Networks,1995:101-104.
[6]TWOMEY J M,SMITH A E. Bias and variance of vali⁃dation methods for function approximation neural net⁃works under conditions of sparse data[J]. Systems,Man,and Cybernetics,Part C:IEEE Transactions on Applications and Reviews,1998,28(3):417-430.
[7]LI Y,FANG B X,GUO L,et al. A network anomaly detection method based on transduction scheme[J].Journal of Software,2007,18(10):2595-2604.
[8]李洋,方滨兴,郭莉,等.基于TCM-KNN 和遗传算法的网络异常检测技术[J]. 通信学报,2007,28(12):48-52.LI Yang,FANG Binxing,GUO Li,et al. Network anomaly detection based on TCM-KNN and genetic al⁃gorithm[J]. Journal on Communications,2007,28(12):48-52.
[9]TAX D M J,DUIN R P W. Support vector domain de⁃scription[J]. Pattern Recognition Letters,1999,20(11):1191-1199.
[10]VOVK V,GAMMERMAN A,SAUNDERS C. Ma⁃chine-learning applications of algorithmic randomness[C]//Proceedings of the Sixteenth International Con⁃ference on Machine Learning(ICML-1999). Bled,Slovenia,1999:444-453.
[11]SAUNDERS C,GAMMERMAN A,VOVK V. Com⁃putationally efficient transductive machines[C]//Algo⁃rithmic Learning Theory. Springer Berlin Heidelberg,2000:325-337.
