基于在线社会网络的网络爬虫的研究和设计
2014-01-16黄蓝会
黄蓝会
(宝鸡文理学院 计算机系,陕西 宝鸡 721013)
互联网和移动通信技术的飞速发展,使得在线社会网络在全球的热度持续升温,大量用户吸引其中。据2012年1月CNNIC第29次“中国互联网络发展状况统计报告”指出[1],中国网民的互联网沟通交流方式发生明显变化,传统交流沟通类应用大幅下滑,而微博/社交网络等则快速崛起。据统计,全球2012年微博用户比2011年底增长了296%。2009年8月运行的新浪微博为中国在线社会网络的典型代表,到2012年注册用户已经超过3亿,峰值每秒发送32 312条消息,每天发布近8 000万条消息[2]。利用新浪微博上的用户和消息进行舆情分析,是当前分析微博的一个重要用途,企业可以从中发掘潜在客户,推广产品,政府可以了解民生动态,将谣言扼杀在萌芽状态,出台政策解决社会问题,所以,对于在线社会网络进入深入挖掘与分析具有重要的现实意义[3-4]。新浪微博中用户和消息众多,如何将这些数据采集到一起,则是信息挖掘和舆情分析的前期工作,本文设计一个爬虫系统,通过新浪微博开放的API接口采集数据。
1 新浪微博的特征
新浪微博于2009年8月28日开始运行,截至目前,新浪微博拥有3.5亿用户。新浪微博是一个类似于Twitter的微博系统。虽然其和Twitter在系统架构上类似,但是新浪微博又有一些自己的特征:1)新浪微博内容丰富,可以发送140以内的汉字,同时也可以发送含有图片、视频、音乐,多媒体形式的存在,满足了博友的表达需求,同时也有利于各种资源的传播;2)发布渠道多样,可以通过Web网页,电子邮件插件,特别是可以用手机发微博,没有发布工具的限制,微博用户可以随时随地的发布信息;3)信息传播零时差,多样化的信息接收渠道可以让用户在第一时间接收到消息,而其一键转发设置则让转发信息的过程实现零时差,同时,微博采取的是单向跟随的人际关系,用户不需要是双向的好友关系就可以任意的关注他人,这种模式可以使得信息以广播式的方式急速扩散[5]。
2 相关介绍
采集新浪微博的网络数据是分析微博拓扑特征的前提,本节介绍新浪微博的数据属性以及采集数据用到的API。
2.1 数据属性
新浪微博中存在两个网络:第一个网络是关系网络,节点是用户,边是用户之间的关注关系。第二个网络是信息传播网络,节点是用户,边是用户之间微博的转发和评论关系。数据可以分为两大类[6]:用户信息数据和微博信息数据。用户信息数据中主要的字段包括:用户UID、用户昵称、用户所在城市、粉丝数、关注数、微博数、注册时间、是否是微博认证用户、用户的在线状态、收藏数等等。微博信息数据主要的字段包括:微博作者信息、发布时间、微博ID、微博内容、评论数、转发数等等。
2.2 API介绍
2010年7月新浪微博开放其API接口,通过新浪微博登录后可以浏览资料,但由于服务器的性能和网络带宽的限制,新浪微博的API对请求次数设置了严格的限制,每个账户每小时可以访问150次,IP在一个小时内只能申请1000次,只要控制好调用API的频率,这个方法是获取新浪微博数据的比较简单的途径之一。
新浪微博开放平台的体系参考了Twitter,两者非常类似,包括接口、参数的定义,请求方式等等。如果熟悉Twitter的API,基本可以同样的适用到新浪微博开放平台上,同时新浪微博开放平台的文档技术部分的信息也可以同样适用于Twitter。到目前为止,新浪微博开放平台提供的API有如下几个接口:微博接口、评论接口、用户接口、关系接口、账号接口、收藏接口、话题接口、标签接口、注册接口、搜索接口、推荐接口、提醒接口、短链接口、公共服务接口、地理信息接口[5]。具体每一个接口的功能以及该接口下的API可参看新浪微博开放平台的API文档。
3 网络爬虫系统
本文设计的网络爬虫系统由两个模块组成,分别是模拟登录模块和爬取模块。图1给出了该爬虫模型。下面将具体介绍两个模块。
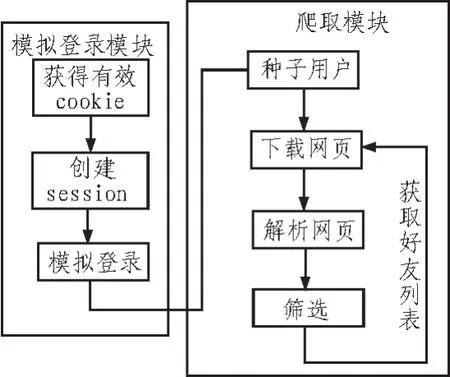
图1 网络爬虫模型Fig.1 Model of crawler
3.1 模拟登录模块
由于一般的浏览器提供了自动获取并保持用户访问某网站时产生的cookie,创建相应的session,所以用户在第一次通过浏览器进入新浪微博时需要登录,但之后一段时间就可以不需要再登录,直接进入系统。目前新浪微博服务器无法对一段普通的计算机程序的访问创建相应的session,因此,为了方便网页爬虫模块的实现,我们采用新浪微博模拟登录方法来解决。
为了实现对新浪微博的模拟登录,首先要获得一个可以使用的cookie,实验中利用chrome浏览器直接可以获得用户登录某网站的cookie,之后就可以创建session,从而实现模拟登录。数据采集人员在模拟登录之后,就可以采用点击微博页面的方法去启动程序了。
3.2 爬取模块
Web1.0网页的获取是通过网络爬虫实现的。网络爬虫的工作流程是通过设定种子URL作为入口地址,程序按照一定的爬行策略获取每一个URL对应的网页内容,然后解析网页内容,从中提取出链接的URL作为下一次爬行的种子,依次循环,直到满足爬行结束的条件。
在本系统中,首先选用合适的种子用户开始爬取数据,爬行策略基本上和Web1.0的爬行策略相同,不同的是新浪微博的网页爬虫是根据用户之间的关系向外爬行的,不能像Web1.0根据链出网页URL进行爬行,在新浪微博中,我们采用从一个给定的种子用户,通过关注改用户的关注列表,依次获得关注列表中的每一个人的关注列表,这样一层一层的向外扩展。
下载微博网页可以和下载普通网页一样,通过网页URL定位到该网页后利用JAVA程序提供的下载网页的函数,该函数会打开一个数据流,执行完后整个网页内容会以字符串的形式保存下来。
解析网页通常是制定一个页面解析规则,由于新浪微博相同种类的页面的编码规则一样,所以采用将HTML网页转化为标准的DOM树结构的方法,可以将页面解析出来供后续筛选用。采用这个方法的原来是程序员在编写HTML网页时很多标签不是成对出现的,所以直接利用HTML解析网页信息比较困难,而标准的DOM树结构利用Xpath可以很方便的定位存放数据的DOM节点位置,抽取该节点的内容。所以,采用标准的DOM树结构可以很方便的解析网页。
筛选用户信息实际上是一个数据去重操作,在Web1.0网页爬虫中去重的方法很多,可以用C++或者JAVA语音提供的现成的HashMap数据结构,但是这种去重策略不能满足大规模的网页爬行,如果网页数量很大,HashMap<string,blooean>所占内存会很大。本文设计一个针对新浪微博用户信息数据获取过程的过滤算法。根据新浪微博为每一个注册用户分配的64位整数随机ID号,以其作为二进制向量的下标查找,如果小标的对应值为1,证明已经获取过该ID的用户信息,否则说明这个用户信息还没有被获取过。当需要开辟一个40亿的二进制数组的时候,所需内存为470M,一般的PC机都能承受。JAVA提供的数据结构bitmap,实际是一个bit数组,利用其可以代替二进制向量,初始化时大小不能超过2147483648,以此将用户ID号分为4个区间分别用一个过滤器处理。
具体的过滤算法如下:
Boolean WEIBO_ID_FILTER(ID)
if(ID> FOURTH_INTERVAL)Then
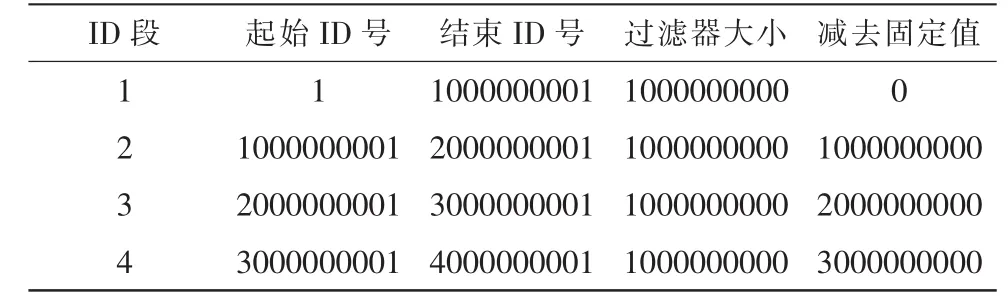
表1 新浪微博媒体用户ID分段过滤Tab.1 Subsition filtration of user ID in Sina wicroblog
Long newID←ID-FOURTH_INTERVAL
if(FOURTH_FILTER[newID]为 0)
Then FOURTH_FILTER[newID]置1
return true
Else return false
EndIf
EndIf
if(ID> THIRD_INTERVAL)Then
Long newID←ID-THIRD_INTERVAL
if(THIRD_FILTER[newID]为 0)
Then THIRD_FILTER[newID]置1
return true
Else return false
EndIf
EndIf
if(ID> SECOND_INTERVAL) Then
Long newID←ID-SECOND_INTERVAL
If(SECOND_FILTER[newID]为 0)
Then SECOND_FILTER[newID]置1
return true
Else return false
EndIf
EndIf
if(ID> FIRST_INTERVAL) Then
Long newID←ID-FIRST_INTERVAL
If(FIRST_FILTER[newID]为 0)
Then FIRST_FILTER[newID]置1
return true
Else return false
EndIf
EndIf
4 实验结果与分析
服务器的软件环境:
操作系统:Windows Server 2003 R2;
数据库:MySQL Server 5.0.1;
服务器的数据采集模块;.NET 3.5;
数据分发服务器:JDK 1.6,Eclipse 3.5;
数据采集模块:Visual Studio 2005;
开发语言:C#,Java
本实验主要是比较布隆过滤器和本文采用的过滤算法的效率。利用从1到100000000个不同的数字和10万个重复数字作为实验数据,用布隆过滤器和本文的过滤算法对1亿个不同数字和10万个重复数字分别进行过滤去重。

表2 1亿个不同数字的过滤效果Tab.2 Filtering result about one bilion different digital
从表2可以看出,本文采用的过滤算法明显高于布隆过滤器。因为布隆过滤器要将待过滤元素映射到8个值后再去查找二进制向量。本文用的过滤算法不用映射直接去查找。

表3 10万相同数字的过滤效果Tab.3 Filtering result about ten million same digital
从表3可以看出,两种过滤算法对于重复数据都可以检测到。
5 结束语
中国新浪微博的迅猛发展已经影响到我们的方方面面,从中收集用户资料进行舆情分析是目前很多专家学者开始的一个新课题,其中收集用户资料则是这项研究的基础,只有采集到足够数量的数据,分析才有意义。本文设计了一个网络爬虫系统,利用新浪微博的API爬取用户资料,实验证明,该方法在较短的时间内能收集到较多用户资料,达到较为满意的效果。
[1]CNNIC.第29次中国互联网络发展状况调查统计报告[R].北京:中国互联网络信息中心,2012.
[2]高戈坤.新浪微博用户数再创新高[J].通信世界,2012(2):10-11.GAO Ge-kun.Sina micro-blog user number to a new high[J].Communication Word Weekly,2012(2):10-11.
[3]林旺群.基于带权图的层次化社区并行计算[J].方法.软件学报,2012,6(23):1517-1530.LIN Wang-qun.Paraller computing hierachical community approach based on weighted-graph[J].Journal of Software,2012,6(23):1517-1530.
[4]刘兴亮.微博的传播机制及未来发展思考 [J].新闻与写作,2010(1):43-46.LIU Xing-liang.Thinking about communication mechanism micro-blog and future development[J].News and Writing,2010(1):43-46.
[5]王亮.微博媒体的信息传播分析[D].哈尔滨:哈尔滨工业大学,2012.
[6]郭正彪.大尺度在线社会网络结构严谨[D].武汉:华中科技大学,2012.
