一种基于Storm编程模型的迭代Topology方案
2014-01-05杜政颉郎福通
杜政颉, 王 鹏, 黄 焱, 郎福通
(1.成都信息工程学院软件工程学院并行计算实验室,四川成都610225;2.中国科学院成都计算机应用研究所,四川 成都 610041;3.中国科学院大学,北京 100049)
0 引言
大数据处理分为两类模式,一类是批处理模式,数据源为静态;一类是流处理模式,数据源为动态。批处理模式系统有Hadoop、Spark、Disco、HPCC等,流处理模式系统来自 Twitter的 Storm和来自 Yahoo的 S4系统[1]。MapReduce是Hadoop中被广泛应用的一种大数据处理模型,侧重于批处理,Topology是来自于Storm系统中的一种编程模型,侧重于流处理。
MapReduce无法解决具有迭代结构的应用程序,迭代结构程序在实际应用中很普遍,因此,有人基于MapReduce提出一种迭代MapReduce。文献[2]提出一种名为Twister的迭代MapReduce处理方案,文献[3]提出一种名为HaLoop的MapReduce迭代方案。
Storm是一款应用于实时流处理领域的大数据处理工具。在Storm中,Nathan Mar提出一种新的并行编程模型Topology。这种模型改进了MapReduce需要存储中间数据这一繁琐过程[2],采用类似于流水线作业方式的任务分解模型,侧重于处理动态数据源的任务,实时性更强。Storm编程模型与MapReduce一样,并没有考虑这种迭代结构应用程序的实现过程。对于这一缺陷,还没有人提出一种改进方案。因此,文中基于这种Topology编程模型,通过增加组件Receiver、IBolt、Checker组建迭代Topology,设计了一种新的可以解决迭代结构应用程序Topology模型,并对这种模型的新增组件和其对应的API进行了介绍和分析,在Storm系统架构基础上设计了一种迭代Topology的实现方案,描述了在这种实现方式下解决具有迭代结构程序的具体过程,并使用这种模型实现了K-Means算法,实例论证这种迭代模型的可行性。
1 问题描述
1.1 Storm编程模型思想
Storm编程模型原理[4]:一般任务都可以用流水线作业方式表现出来,其中的组件就相当于流水作业中的一个工人,不同的组件负责任务中不同的部分,一个组件处理完自己的工作即提交给下一个组件,直至整个任务处理完成。整个任务实现的过程可以用图1的Topology来表示。这种模型的一个突出特点:数据源可以静态可以动态,动态环境中它的表现更能体现出它的优势。一方面,这种模型采用消息传递方式交互数据,数据量相比于从磁盘获取要小,动态环境中,数据量动态读取,每次读取量小,很好满足了这种模型的特点;另一方面,这种模型是一种实时性处理模型,动态环境中更能够体现这种特点。所以,这种处理模型侧重于流处理。模型包含两类组件:Spout和Bolt,Spout组件负责读取数据源,Bolt组件负责实际的数据操作运算。组件在实现中有对应的API,Spout组件API为setSpout(),Bolt组件API为setBolt()。

图1 Storm Topology
1.2 Storm编程模型解决迭代时的不足
有许多并行算法内部都带有简单的迭代结构。这些算法大多分布在数据聚类、维度缩减、链接分析、机器学习和计算机视觉等领域。K-Means、确定性退火聚类、PageRank和SMACOF算法就是其中的例子。这种具有迭代结构的算法可以用以下公式来描述[3]:

其中,R0表示初始化时的结果,L表示一种不变的关系。这种公式表示的程序,只有当到达某检查点时才将终止运行。比如,迭代后的结果与前面结果相比已经不会出现变化就可以作为一个检查点,这也是很多优化算法迭代的检查点。
迭代程序的一个关键点是结果与输入具有相关性,上面的Topology中输出结果无法再次作为输入,所以这种迭代部分只能放入一个组件Bolt作为一个任务来处理,这样就增加了该组件的处理负载。对于低配置集群,这种高负载一方面导致整体系统效率降低,另一方面还有可能使节点失效。因此,下面设计一种具有迭代结构的Topology模型,在这种模型中,处理迭代结构程序时,就可以把迭代结构部分按照功能拆分开来,而不是把整个迭代部分放入一个组件中,使得这种模型处理迭代问题时更加灵活。
2 基于Storm模型设计的迭代方案
2.1 迭代Topology模型设计
基于Storm的基础编程模型,文中改进其Topology,增加了迭代模块,能够解决迭代类的问题,如图2所示。迭代Topology与之前Topology相比多了一个新拓扑:Iterator。Iterator负责处理具有迭代结构部分程序。里面同时包含了IBolt组件、迭代检查器Checker和外部数据源接收器Receiver。IBolt组件负责任务处理,迭代检查器负责判断迭代是否结束,外部数据接收器负责接收迭代器外部发来的数据。迭代Topology好比在流水线上的工人中增加一个迭代管理员,负责管理处理迭代任务的工人,并告诉他们什么时候进行迭代操作,什么时候结束迭代。
图2中描述的这种迭代模型看起来只能模仿Do-While循环模式,但While-Do或者Do-While在一定条件下可以互相转化,所以这种模型其实可以解决任何迭代问题。
迭代 Topology新增了 Receiver、IBolt、Checker 3个组件,通过新增的 3个API(setReceiver()、setIBolt()、setChecker())来实现。
(1)新增组件
Receiver组件:Receiver组件用来接收外部组件和内部迭代组件Checker组件发送来的消息。将接收到的消息进行排队处理后发往迭代开始的IBolt组件。Receiver组件一方面解决了Checker组件和Spout组件同时向IBolt组件发送消息的功能,另一方面也可以控制数据传入IBolt组件的速率。
IBolt组件:IBolt组件与Bolt组件一样,负责实际任务处理,但它处理的是需要迭代运算的任务,区别于非迭代功能的任务。
Checker组件:Checker组件是实现迭代过程的关键,迭代控制主要由它完成。主要功能是检查迭代处理是否结束。与其它组件不同的是,有两个发射口,一个是发往Receive组件,一个是发往外部Bolt组件。如果进入下次迭代,消息发往Receiver;如果迭代结束,消息发往外部Bolt组件。

图2 迭代Topology
(2)新增组件API
setReceiver():构造1个接收器,2个参数,参数1设定接收器名,参数2设定并行数目;
setIBolt():构造1个迭代处理组件,3个参数,参数1设定迭代处理组件名,参数2设定要处理的任务,参数3设定并行数目;
setChecker():构造1个迭代检查器,4个参数,参数1设定迭代检查器名,参数2设定消息接收器名,参数3设定迭代检查器任务,参数4设定并行数目;
2.2 迭代Topology模型的实现
图3为Storm中实现Topology模型的一种架构[4]。该架构由3个进程组成:Nimbus进程为主进程,负责接收客户端提交的代码,并将代码序列化,为客户机分发任务;Zookeeper进程负责Nimbus进程和Supervisor进程之间的消息协同工作;Supervisor进程负责接收任务并执行任务,将任务结果返回给用户。
实现这种迭代Topology,仍然延用Storm系统基础架构,需要改变的是系统的调度策略、组件类型。一个完整迭代任务执行过程如下:
(1)Nimbus进程接收客户端提交过来的具有迭代结构的Topology,然后将每个组件序列化,并分发任务到Supervisor;
(2)Supervisor接收分发的任务并开始执行;
(3)Spout组件发射一条消息到迭代消息接收器Receiver,消息接收器将消息进行排队,按照先来先服务策略,把消息发往第一个要开始迭代操作的组件IBolt;
(4)IBolt组件处理完自己的任务,根据用户设定,决定任务结果是发往Checker组件还是发往下一个IBolt组件;
(5)Checker组件根据接收到的消息和用户定义的检查点决定是否继续迭代操作,如果迭代完成则将消息发往外部Bolt组件,否则,将消息发往Receiver组件开始下一次循环操作。

图3 Storm框架
3 迭代Topology模型模拟实现K-Means算法
K-Means算法是数据挖掘中应用广泛的数据聚类算法,算法程序结构包含了迭代处理部分,这种具有迭代结构的算法很多,为了验证迭代Topology模型的可行性,文中选用比较典型并且为大家熟知的K-Means算法来实现。
K-Means算法的核心思想[5]是找出K个聚类中心c1,c2,…,ck,使每个数据点xi和与其最近的聚类中心cv的平方距离和被最小化(该平方距离和被称为偏差D)。对n个样本进行聚类的过程如下:
(1)初始化:随机指定k个聚类中心(c1,c2,…,ck);
(2)重复下面过程直到D收敛:
①分配xi:对每个样本xi,找到离它最近的聚类中心cv,并将其分配到cv所标明类;
②修正cv:对每一个cv移动到其标明的类中心;
药士道:“此人之前乃是假死,盖因体力透支严重,精神高度紧绷,再加之外伤失血过多,导致身体机能衰竭。如今能重新恢复气息,实数罕见。容我为她配些养神滋补的草药,至于她能不能彻底醒过来,还要看她自身的造化了。”
因此,在迭代 Topology模型上设计K-Means算法的Topology可以由图4表示。
该Topology中,Spout组件为spout,Receiver组件为receiver,Checker组件为checker,IBolt处理组件包括caldistance和move,Bolt组件为writeResult,K-Means算法在迭代Topology上的实现过程的具体描述如图5所示。
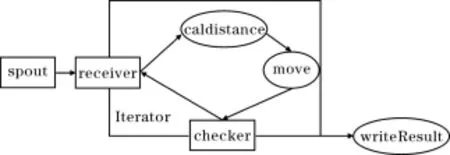
图4 K-Means算法的迭代Topology
该实现采用5个点作为点群,选取2个种子点,图5描述了这种归类的大致过程,具体实现过程如下:
(1)spout组件随机产生5个点作为点群,随机产生2个点作为基点,然后将点群和基点作为数据输入发往receiver组件;
(2)receiver组件接收到输入后把输入数据发往迭代开始组件caldistance,该组件用来计算基点与各个点群之间的距离;
(3)caldistance将计算完后的距离以及点群和基点位置发往move组件,move组件根据距离计算出点群中心,并将基点移动到点群中心,将移动后的基点与点群作为数据输入发往checker组件;
(4)checker组件将第一次接收到的数据与初始化的基点相比较,比较完后将接收到的基点代替初始化的基点作为下一次比较的对象,初始化的基点位置一般为(0,0),因此第一次比较必然要进行迭代处理,所以checker组件将接收到的点群和基点发往receiver,然后开始第二次重复处理过程;
下面是构建K-Means迭代Topology的主要模拟实现代码段:
TopologyBuilder builder=new TopologyBuilder();
builder.setSpout(“spout” ,new RandomProducePoints(5,2),2);
builder.setReceiver(“receiver” ,4);
builder.setIBolt(“caldistance” ,new calDistance(2),2).shufflegrouping(“ receiver”);
builder.setIBolt(“move”,new MovetoCenter(),2).shufflegrouping(“caldistance”);
builder.setChecker(“checker” ,”receiver” ,new checkChanges(),2).shufflegrouping(“move”);
builder.setBolt(“writeResult”,new writeResult(),1).shufflegrouping(“checker”);
以上代码都是模拟仿真Storm系统中实现Topology的代码来表述的。TopologyBuilder类是构建一个Topology图需要的类,类中包含了设置各种组件的方法,一个应用的Topology就是通过这个类来实现的,组件中的参数主要有4类:组件名;组件任务;接收消息的方式;并行数目。接受消息有6种分组方式:随机分组、字段分组、全部分组、全局分组、无分组、直接分组,示例中都为随机分组。随机分组有一个参数,这个参数指定接受消息的组件名。随机分组的意思就是随机接受组件发送来的消息。例如,组件move有4个线程在同时工作,组件caldistance有5个线程同时工作,move随机接收caldistance发送来的消息,就表示move的任意一个线程接受caldistance任意线程计算完后的结果。并行数目,指共同执行该组件任务的线程数目。并行数目都需要用户根据任务情况来设置。示例中receiver采用4个线程,writeResult采用1个线程,其它的都是2个线程。receiver线程数目为4,因为它既要接收spout的消息还要接收checker的消息。

图5 迭代 Topology实现K-Means算法过程
4 结束语
迭代 Topology在Storm Topology原型基础上增加了 Receiver、IBolt、Checker组件,Receiver和Checker组件与IBolt组件连接组成了一个具有迭代功能的Topology图,使用这种迭代Topology图成功解决了具有迭代功能的K-Means算法,这种方案因为是在以前基础上添加组件完成,所以就很好保留了原Topology的特点。这种迭代Topology在实现方式上,保留了Storm基础架构,只是调整了主进程的调度策略和组件类型,实现上降低了后续开发难度。
致谢:感谢成都市科技局创新发展战略研究项目(11RKYB016ZF)对本文的资助
[1] 孟小峰,慈祥.大数据管理:概念,技术与挑战[J].计算机研究与发展,2013,50(1):146-169.
[2] Ekanayake J,Li H,Zhang B,et al.Twister:a runtime for iterative mapreduce[C].Proceedingsof the 19th ACM International Symposium on High Performance Distributed Computing.ACM,2010:810-818.
[3] Bu Y,Howe B,Balazinska M,et al.HaLoop:Efficient iterative data processing on large clusters[J].Proceedings of the VLDB Endowment,2010,3(1-2):285-296.
[4] Storm-wiki.[EB/OL].http://github.com/nathanmarz/storm/wiki/,2013-06-10.
[5] 孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61.
[6] Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[7] Neumeyer L,Robbins B,Nair A,et al.S4:Distributed stream computing platform[C].Data Mining Workshops(ICDMW),2010 IEEE International Conference on.IEEE,2010:170-177.
[8] Cherniack M,Balakrishnan H,Balazinska M,et al.Scalable Distributed Stream Processing[C].CIDR.2003,3:257-268.
[9] Nathanmarz-blog[EB/OL].http://nathanmarz.com/.2013-07-10.
[10] Storm-berkeley[EB/OL].storm-berkeley.pdf.2013-09-01.
[11] 张建萍,刘希玉.基于聚类分析的K-means算法研究及应用[J].计算机应用研究,2007,24(5):166-168.
[12] 邓华锋,刘云生,肖迎元.分布式数据流处理系统的动态负载平衡技术[J].计算机科学,2007,34(7):120-123.
[13] 亓开元,赵卓峰,房俊,等.针对高速数据流的大规模数据实时处理方法[J].计算机学报,2012,35(3):477-490.
[14] Getting Started with Storm[EB/OL].Getting Started with Storm.pdf.2013-08-18.
[15] S4 vs Storm[EB/OL].s4vStorm.pdf.2013-08-08.
