数据质量提高方案探究
2014-01-03苏小会葛宇洲
苏小会,葛宇洲
(西安工业大学计算机科学与工程学院,陕西西安,710021)
0 引言
数据是为反映客观世界而记录下来的可以鉴别的数字或符号,表现为数字、文字、图形、图像、声音等。数据是一种产品,作为产品的数据应该有质量。随着社会信息化不断发展,特别是在现在的大数据时代,数据质量问题不得不被认真考虑。
数据质量的概念有很多,一般认为数据质量是数据适合使用的程度,或者数据质量是数据满足特定用户期望的程度,这个概念的定义其实是站在用户的角度给出的,体现出了与使用数据有关的要求。数据质量问题涉及三种情形,第一种是数据格式问题,如数据丢失导致不完整、超出元数据范围导致数据无效等;第二种是业务逻辑问题,如由于数据库模式设计不够严谨而导致的数据之间逻辑矛盾、不正确、不合理等;第三种是数据源问题,如由于数据源分散、多次采集导致数据获取困难、语义失效、信息冗余等。如今大多数项目或系统中,数据质量问题被集中于数据预处理阶段解决,在整个项目进行过程中,缺乏对数据质量问题的持续关注。
因此在实际工作中,我们需要考虑和设计一种过程模型,对数据质量进行定义和评估,在每一个不同的过程或环节中,数据质量被定义为产品、服务、系统或者程序的一套基本特征去迎合有关各方的需要和期望,总之,数据质量代表了各方的契合点,应该用有效并可以反复执行的过程模型来评估和提高数据质量。
1 数据质量提高方案
1.1 戴明环理论
凡是涉及到质量问题的评估和管理,都离不开戴明环。戴明环又叫PDCA 循环,PDCA 是英文单词Plan(策划)、Do(实施)、Check(检查)和Act(处置)的首字母,PDCA 循环就是按照这一顺序进行质量管理,并且循环不止的反复进行下去的科学程序。PDCA 循环是美国质量管理专家休哈特博士率先提出,由戴明学习采纳、宣传,获得普及,因此也被称为“戴明环”。
1.2 数据生命周期
1999 年,Larry 在《Improving Data Warehouse and Business Information Quality》讨论了一种通用资源生命周期,包含管理任何资源所需要的流程,文中将资源生命周期定义为五个阶段,分别是规划、获取、维护、应用和报废。例如对于资金来说,把它视为金融资源需要规划金融资源,进行预算,通过银行贷款或抛售股票来获取金融资源,通过支付利息或者股息来维护金融资源,通过购买其他资源来应用金融资源,当还清贷款或者回购股票后,资金作为金融资源生命周期就完结了。同样对于目前大量的数据来说,把其视为数据资源,为了从数据资源中获益需要规划数据资源,我们可以依照Larry 的思想定义数据资源生命周期,数据资源生命周期,是指从数据的需求规划开始,生产、获得、被存储和利用,到消失或不再有利用价值、不再被传播的一系列过程。
数据资源的生命周期模型如图1 所示。图1 呈现了数据生命周期的各个阶段,这种生命周期不是线性过程而是反复迭代的。
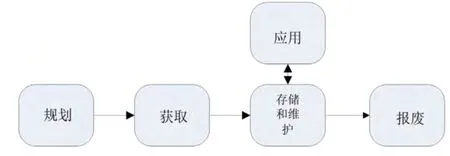
图1 数据生命周期示意图Fig1 Data Life Cycle
任意一组数据的规划,获取,维护,应用,报废都有很多种方法,而事实上,同样的数据也可能存储在多个地方。现实世界中对于数据的处理往往是单一的,只在某一环节进行的,因此针对数据生命周期的每个阶段,设计一种循环反复的数据质量提高方案是非常有益的。
1.3 数据质量提高方案
提高数据质量常常被看成是一次性的工作,有人会说“我的项目里已经校正过数据了”,即使人们意识到数据质量工作需要持续关注,但由于缺乏系统的认识,造成数据质量工作随时间进展逐渐淡化,这也是很多应用程序开发项目出现数据质量问题的原因,一旦进入实践生产,就无法保持项目所需数据质量,因此本文在戴明环理论和数据生命周期思想的基础上总结出一种数据质量提高方案。
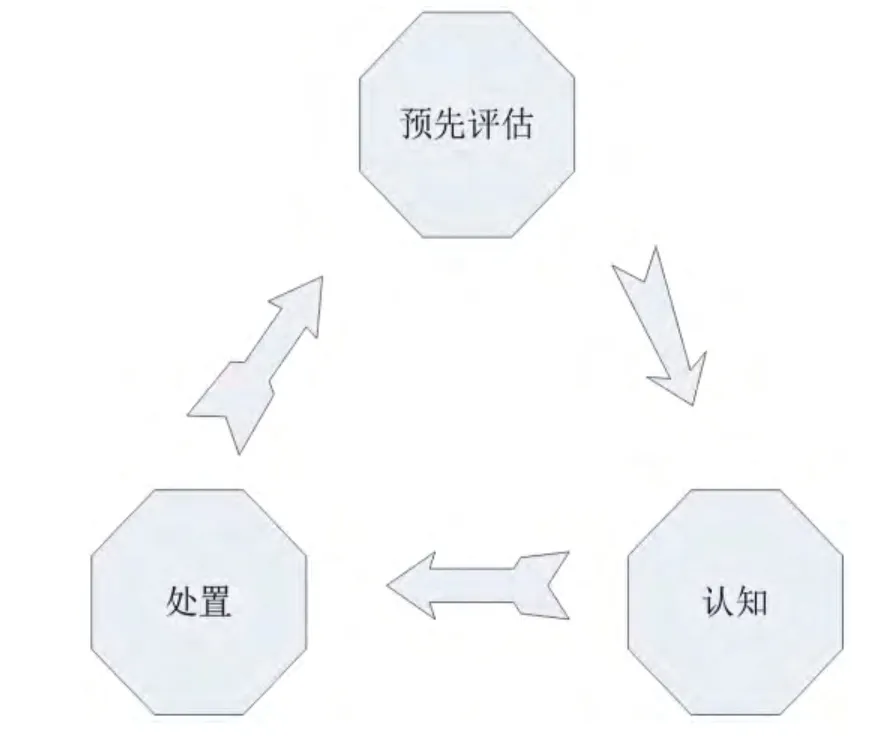
图2 数据质量提高方案示意图Fig2 the improvement plan of data quality
如图2 所示,该方案分为预先评估,认知,处置三个顶层步骤,每一个顶层步骤中都包含了具体细化的工作。
在预先评估中,首先应该做的是分析数据环境。这一工作需要收集,汇总分析关于当前项目的数据环境信息,定义项目业务的需求和方法,为业务问题相关的数据提供资料,制定获得数据的初步方案,并要弄清楚待处理问题的相关协议,文件,以及它们和数据质量的关系,这些工作主要通过一些访谈,预研究,沟通协调完成。无论涉及到哪种类型的数据质量工作,都要避免在不了解基本环境的情况下直接抽取和分析数据,否则往往需要进行重复劳动,效率低下。
接下来是确定数据的规范,数据规范主要包括数据模型,数据标准,业务规则等。数据模型是数据结构,数据操作,数据约束的统称,是数据库中的形式构架。数据标准是数据中表,字段等命名的规则,录入的规则,使用时要遵循的标准等。业务规则是指在项目使用该数据的时期内,数据应该何时以及如何被处理的声明。数据规范的确定是一步重要工作,很多时候是通过数据模型的建立或定义数据库中的元数据来完成的。一个良好的数据模型,能够在恰当的细节层反应与项目相关的问题,呈现整个系统的范围,描述数据,实体和关联关系。元数据是关于数据库的数据,指在数据库建立过程中所产生的有关数据源的定义,目标定义,转换规则等相关的关键数据,可以说是描述数据的数据。同时元数据还包含对于数据含义的商业信息,所有这些信息都应当妥善构建,并很好地管理。为数据库的发展和使用提供便利。元数据的管理是初始阶段控制数据质量的重要方法,元数据管理主要有元数据的添加、删除、修改属性等维护功能;元数据之间关系的建立、删除和跟踪等关系维护功能;进行元数据发布流程管理,可以更好地管理和追踪元数据的生命周期;元数据自身质量核查、元数据查询、元数据统计、元数据使用情况分析、元数据变更等功能。
完成了预先评估的工作,就要进入下面的认知阶段,认知阶段要进行的工作与评估息息相关。预先评估阶段建立了数据规范,分析了背景问题,认知阶段就要确定所需衡量的数据质量维度。维度本身是一种数学概念,是在一定前提下描述一个数学对象所需要的参数的个数,这里的维度是可以理解为一种视角,而不是一个固定的数字参数,是一个判断、说明、评价和确定一个事物的多方位、多角度、多层次的条件和概念。国内外关于数据质量维度的研究比较广泛,划分也比较细致,总结起来,数据质量的维度主要有以下几个方面:数据完整性,数据重复性,数据准确性,数据一致性,数据及时性等等。数据完整性是指数据的存在,内容结构和其它基本特征是否符合元数据标准,是否有缺失。数据重复性是指对存在于系统内或者系统之间的特殊字符或数据集意外重复的测量标准。数据准确性是指数据内容是否被按照精确度要求来描述。数据一致性,就是当多个用户试图同时访问一个数据库,它们的事务同时使用相同的数据时,可能会发生丢失更新、未确定的相关性、不一致的分析等。数据及时性是指数据的生命周期是否符合项目需求的时间段。在不同的领域还有更多的数据质量维度划分,这里就不再一一赘述。研究数据质量维度应该注意一个方面,就是在一个项目中该维度的评估是否可行或者代价过大,如果评估该质量维度很难实现,也就没有评估的必要了。
接下来是确定产生数据质量问题的原因和提出具体改进方法。根据以上的分析评估就可以确定产生数据质量问题的原因,现实的情况是一个问题通常都有多个原因,因此要需要对产生的原因进行优先级划分,以便更好的处理问题,比如产生问题的原因是开发工具的问题,还是信息采集的问题,还是人为造成的问题等等。有了具体原因,才能制定改进的方法,工具问题,能否由更新工具来改善,人为问题,是否应该进行更好的沟通和责任划分来改善等等。
完成前两个阶段工作之后就要进入处置阶段。处置阶段主要要做两方面工作,纠正当前错误数据和预防未来错误数据,这里的“错误”是一个广义概念,即不符合质量需求的数据。纠正当前数据错误和预防未来数据错误都要应用到具体算法,目前大多数数据质量分析处理方法也都是在做这些工作。比如在数据缺失的情况下通常使用回归分析的方法进行填补,在有大量数据冗余的情况下使用固有或非固有频率的数据归约算法进行筛选,还有利用数据清洗工具进行识别和合并重复记录等等。数据的纠正和预防其实都是对已有原始数据的大规模更新,这些变更应该进行详细的归档记录,更新的结果也应该及时与技术团队或相关数据利益者进行沟通,这样有助于随时检查可能发生的问题。这种变更的复杂性和时间性也需要慎重考虑,毕竟,数据质量分析工作是为其它后续的挖掘工作做准备。
2 应用举例
本文采用西安市交通信息中的浮动车GPS 数据作为示例。浮动车是指安装有GPS 发送装置,在道路上运行的车辆,大多数为公交车或出租车。
首先是对浮动车GPS 数据进行预先评估。现代交通服务信息的核心是对交通参数的检测,传统检测法如感应线圈检测等都属于固定检测,已经很难满足交通服务的需求,随着全球卫星定位系统的应用,浮动车技术已经渐渐成为现代交通参数检测的主流,一般用于车辆轨迹描绘和拥堵分析等。通过调查研究,我们可以总结GPS 数据有以下特点:
①GPS 数据覆盖的面积较大,可以对多个路段的交通状况进行监控。
②定位精度较高,能够进行实时信息的交互。
③浮动车产生的GPS 数据量样本极大,多数发送装置的频率可达到1 秒钟发送一次。
接下来是针对GPS 原始数据进行分析,GPS 原始数据如下表所示。
从该表可以看出,GPS 浮动车数据有车辆编号,GPS 时间,经度数据,纬度数据,方向角五种主要数据项,有的浮动车数据还包含瞬时速度,行驶距离等,基本数据质量的分析清洗应从GPS浮动车数据的这五个属性展开。而与具体应用需求相关的GPS 数据,还需要有具体的算法进行筛选。
第三步是根据前面的分析设计具体的数据筛选算法选取符合需求的数据。
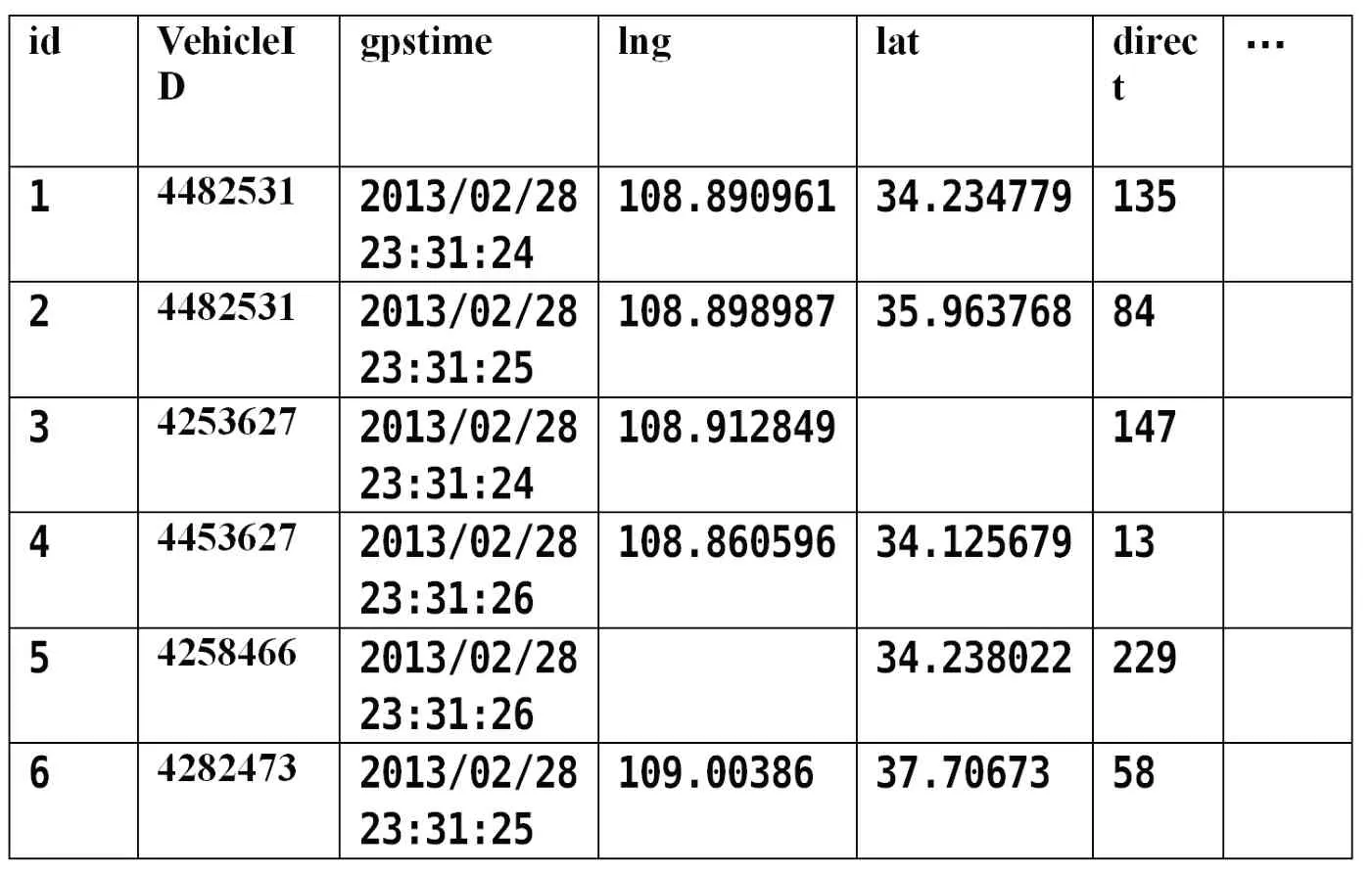
表1 原始数据Chart1 original data
VehicleID 表示车辆ID 编号,每个浮动车应该有唯一编号,本文中,车辆编号为7 位正整数,且该数据不能为空。gpstime表示GPS 定位时刻,该数据不能为空,时间为24 小时制,数据格式应该符合yyyy/mm/dd hh:mm:ss,精确到秒。lng 表示GPS 定位的经度信息,该数据不能为空,取值范围为0-180 的东经经度,要求精确到小数点后6 位。lat 表示GPS 定位的纬度信息,该数据不能为空,取值范围为0-90 的北纬纬度,要求精确到小数点后6 位。direct 表示车辆运行的方向角,该数据不能为空,取值范围为0-360 的正整数。
有些原始数据缺乏车辆行驶速度,在进行拥堵分析时需要计算车辆在某点的瞬时速度或某路段的平均速度,在进行某车辆轨迹绘制时,并不要求大量样本数据,因此需要按照一定得归约方法来选取数据,比如将GPS 发送装置的固有频率从1 秒扩大到10 秒来筛选,也可以选取车辆行驶方向角发生较大偏转时的数据作为记录点,最后将该车辆发送的GPS 数据按时间顺序排列。经过筛选后的数据如表2
经过分析筛选后的数据可以用于进一步的交通信息挖掘,为城市交通服务提供更准确的依据。
3 小结
本文的研究,为数据质量分析提供了一种与具体业务无关的流程方法,将认识数据质量的概念框架与提高数据质量的技术结合起来,在不同的领域,都可以结合具体算法进行应用。现今的时代是大数据的时代,更加强调的是数据信息的获取和分析,而不是创造数据,而数据质量分析控制,也不再是由IT 部门单独能够胜任的,需要各学科的人才,充分利用各类信息数据和方法策略来完成,数据质量问题的挑战,也从逐渐从技术层面上向思维方式层面拓展,这也是数据质量分析的魅力所在。
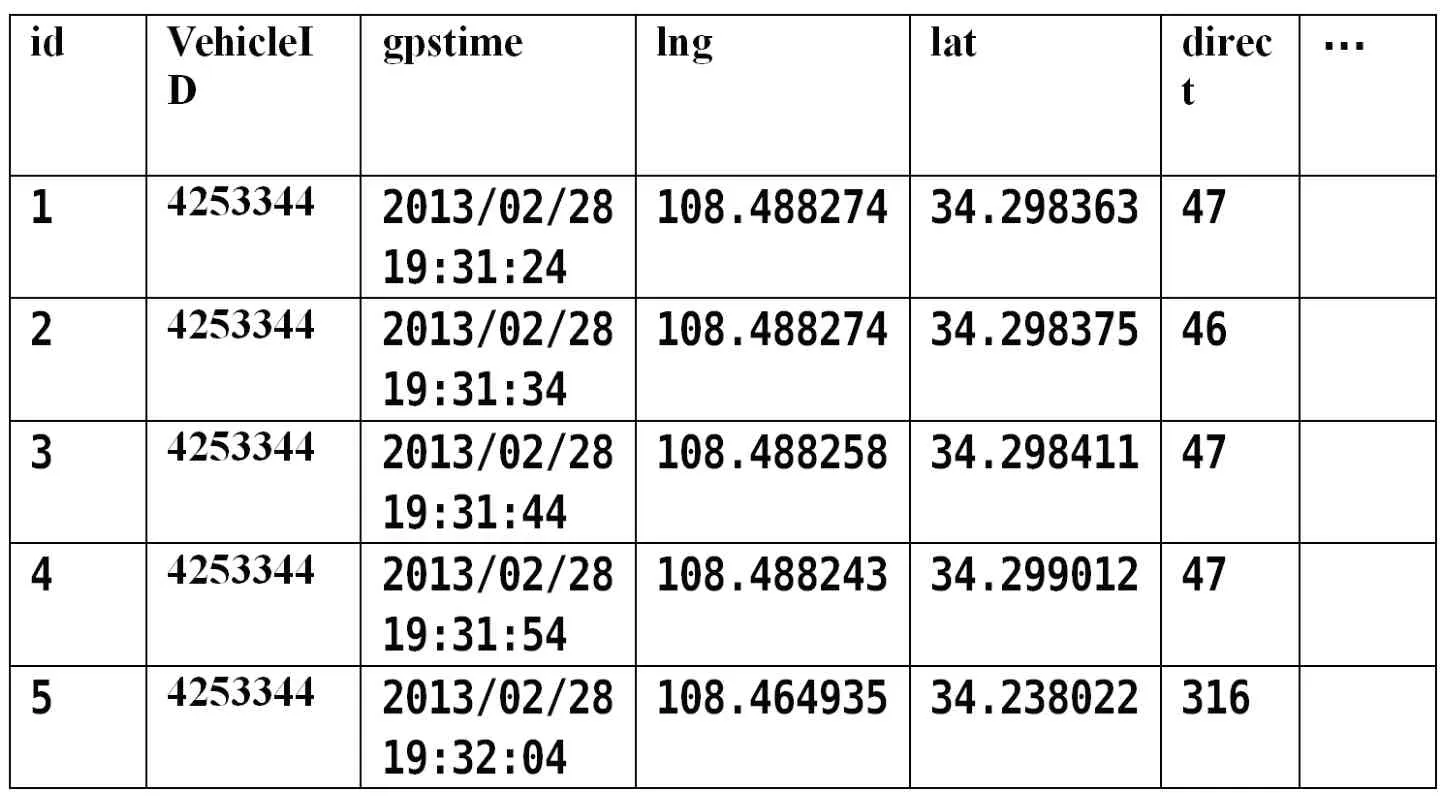
表2 改进后的数据Chart2 improved data
[1] Monge A,Elkan C.An efficient domain-independent algorithm for detecting approximately duplicate database records[C].In:Proceedings of the ACM- SIGM OD Workshop on Research Issues on Know ledge Discovery and Data Mining,Tucson, AZ,1997
[2] Huang K-T,Lee YW,Wang RY.Quality information and knowledge management.New Jersey:Prentice Hall, 1998
[3] Kahn BK,Strong DM.Product and Service Performance Model for Information Quality:An Update.IQ 1998.
[4] Aebi D, Perrochon L.Towards improving data quality [C].In:Proc.of the International Conference on Information Systems and Management of Data,1993.
[5] Larry.Improving Data Warehouse and Business Information Quality.In:Springer:1999:200-209.
[6] 刘慧,刘敏,韩兵。基于维度的信息系统数据质量评估指标体系研究。信息系统工程,2010(6):102-105
