基于多示例学习的企业财务风险识别
2013-12-23陈媛媛熊诗文袁汉宁
陈媛媛,熊诗文,袁汉宁
(1.武汉理工大学 经济学院,湖北 武汉430070;2.武汉大学 国际软件学院,湖北 武汉430079)
我国上市公司80%以上存在企业财务危机隐患,如何客观评价上市公司的财务状况,尤其是识别可能出现财务风险的企业,对于投资者及时调整投资决策,监管层准确识别盲目融资企业,以及投资银行有效发掘潜在服务客户都具有重要的意义。
国内外学者关于企业财务风险的识别方法基本可归为两大类:传统统计模型和人工智能模型。传统统计模型往往由于依赖专家经验或需要大量样本限制了运用的有效性。而基于人工智能的企业财务风险预警模型[1]成为研究的热点,如丁德臣[2]构建了混合HOGA-SVM (hybrid orthogonal genetic algorithm-support vector machines)的财务风险预警模型;BOYACIOGLU[3]等利用神经网络、支持向量机和多元统计方法来判定银行财务失败;WU[4]等用实值遗传算法优化支持向量机的参数来识别破产等。
在人工智能模型中,企业财务风险识别往往是基于监督学习的方法如支持向量机、遗传算法和人工神经网络等。每个样本数据由单个时间点的企业财务风险预警指标表达。笔者将这种财务风险表达模型称为基于监督学习的财务风险表达模型。但在实际情况中,单个时间点的企业财务信息不能准确全面地反映企业的财务状况。
多示例学习是一种新的学习框架,其独特的性质为样本提供了一种更灵活、多样化的表达方法。笔者构建了一种基于多示例的企业财务信息表达模型,设计了基于多示例支持向量机的企业财务风险识别方法并将其应用于深沪两市上市公司的财务风险识别。
1 企业财务信息表达模型
1.1 基于监督学习的企业财务风险信息表达模型
基于监督学习的企业财务风险表达模型如图1(a)所示。基于监督学习的企业财务风险识别方法首先构建企业财务风险预警指标体系,利用特征提取技术抽取企业财务风险预警指标特征子集,再用抽取的企业财务风险预警指标对企业财务风险状况进行向量化表示,将每个企业财务风险状况表示为一个加权向量。企业财务风险状况由企业在某个时间点的财务风险特征向量X 表示,X=(X1,X2,…,Xn)T,其中n 表示财务特征向量的维度。
在该类表达模型中,企业财务风险状况的表达仅考虑了某特定时间点的企业财务风险信息,造成企业财务风险信息表达不完整,进而影响风险识别精度。一家经营良好的企业,其财务经营状况应在各个时间点都比较平稳,如果某个时间点出现较大的经营风险,则该企业存在财务风险隐患。因此基于监督学习的企业财务风险信息表达模型对企业财务状况数据利用不充分,表达不完整,容易造成风险信息的丢失。
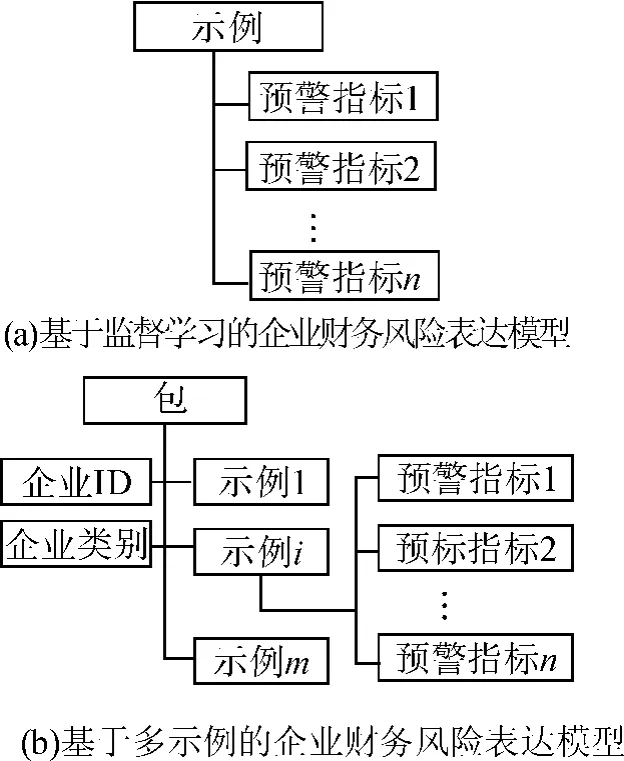
图1 企业财务风险表达模型
1.2 基于多示例的企业财务风险表达模型
多示例学习最先由DIETTERICH 等[5]在药物活性预测中提出,是一类特殊的机器学习任务。在多示例学习中,训练样本是由多个示例组成的包,包是有概念标记的,但示例本身却没有概念标记[6]。如果一个包中至少包含一个正示例,则该包是一个正包,否则为负包。
多示例学习的独特性质为企业财务风险信息的表达提供了一条新的途径。基于多示例的企业财务风险表达模型如图1(b)所示,每个包代表一个企业某时间段的财务风险状况,BAG=(X1,X2,…,Xm),其中m 为包中示例的个数。包中的每个示例Xi表示某特定时间点该企业的财务风险状况,由企业的该时间段财务特征向量表示,Xi=(xi1,xi2,…,xin)T,其中n 为财务特征向量的维度。
该模型认为企业的财务风险信息是时间段内多个时间点财务风险信息的综合。企业的财务风险状况由多示例学习中的包来表示,包中包含数目不固定的示例,各示例则代表特定时间点企业的财务风险状况。值得注意的是,由于包中的示例数目是不固定的和相互独立的,某个时间点财务风险信息的丢失或增加映射为包中示例的删除或增加,因此该表达模型允许某个时间点财务风险信息的丢失或增加。
多示例学习中的假设前提条件与企业财务风险识别问题的前提条件吻合。如果企业财务状况良好,则企业任意时间点的财务状况均良好(如果一个包的标记为负,则包中所有示例的标记均为负);如果企业财务状况出现危机,则至少有某个时间点的财务状况出现危机(如果一个包的标记为正,则包中至少有一个正示例)。因此该表达模型中,类别为正的企业代表出现财务风险的企业,类别为负的企业代表经营状况良好,未出现财务风险的企业。
综上所述,与传统的企业财务风险表达模型相比,基于多示例学习的企业财务风险表达模型具有以下特点:①多示例学习中包(企业财务风险状况)和示例(企业某时间点的财务状况)是一对多的映射关系,不仅适合描述企业财务状况,而且能较好地表达企业各时间点财务风险状况与企业该段时间财务风险的结构关系;②多示例学习中的假设前提条件与企业财务风险识别问题的前提条件吻合;③对财务数据中的噪声、模糊性和缺省具有较强的容忍。由于有包的前提假设条件(正包中至少有一个示例为正,负包中所有的示例都为负),多示例学习中的概念知识具有一定的模糊性和不确定性,学习模式具有一定的容错性[7]。
2 基于多示例的企业财务风险识别方法
由于多示例分类算法可以实现示例和包层次上的分类,因此基于多示例分类学习的风险识别算法,不仅可以通过示例层次上的分类实现某时间点企业财务风险的细粒度预警,还可以通过包层次上的分类实现企业财务风险粗粒度的预警[8]。
经典的多示例分类算法包括MARSON 的基于多样性密度的分类算法DD[9],ANDREWS等[10]的基于支持向量机的mi-SVM 算法,基于距离的citationKNN 等。根据有关学者的研究,使用SVM 进行破产危机和财务风险识别优于神经网络和统计方法。考虑到基于多示例的企业财务风险预警方法不仅要实现包层次上还要实现示例层次上概念标记的预测,多示例分类器选择mi-SVM 算法。采用有概念标记的样本训练mi-SVM 分类器,通过式(1)构造最优超平面,在保证正包中至少有一个示例在超平面上方的基础上,将正示例和负示例分开且两类示例间隔最大。
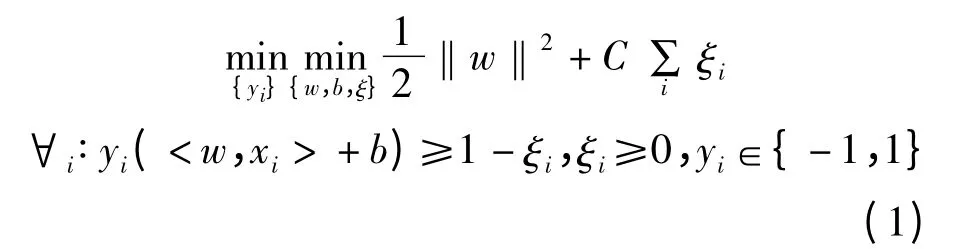
mi-SVM 算法不仅可以对新包进行判定也可以对新包中的示例进行判定。基于该算法的企业财务风险识别算法描述如下:
输入M 个企业的财务信息B,训练集T ={B1,B2,…,BM},B =(X1,X2,…,Xm),m 为时间点,其中Xi=(Xi1,Xi2,…,Xin)T,n 为公司财务信息特征向量维度。
输出测试集中所有包与示例的标签。
算法过程如下:
3 实验结果及分析
笔者采用来自现实世界的数据验证多示例学习在解决企业财务风险预警问题上的有效性。笔者将深沪两市A 股的ST 企业作为财务危机企业研究样本,数据来源于80 家ST 企业(企业状况以“1”表示,即为正包)和80 家正常企业(企业状况以“0”表示,即为负包)的56 个财务指标数据。基于常用财务预警模型中的56 个财务指标,如基本每股收益、每股净资产、销售净利率和资产负载率等,通过指标计算公式可得到26 个财务比率,构建企业的年度财务特征。采用属性评估方法CfsSubsetEval 和搜索算法Bestfirst 将所有数据集中的26 个属性特征抽取权重比例最高、预测能力最强的8 个属性特征Y2(摊薄每股收益)、Y3(每股净资产)、Y5(每股未分配利润)、Y9(营运资金占有率)、Y11(主营业务比率)、Y13(销售净利率)、Y25(总资产对数)、Y26(净资产)组成最优特征子集。实验中企业的每季度财务信息可以表示为一个26 维的特征向量X =(X1,X2,…,X26)T。包含m 个季度的企业财务信息的企业财务状况可以表示成一个含有m 个示例的包:Bag ={(x11,x12,…,x126)T,…,(xm1,xm2,…,xm26)T}。
为了评价提出的模型和方法的有效性,在参数任意给定的情况下,笔者将基于监督学习的企业财务风险识别方法与基于多示例学习的风险识别方法进行比较。试验分为两个部分,分别分析数据完整情况和不完整情况下两类识别模型的性能。
实验中基于监督学习的风险识别算法采用SVM 的改进算法SMO(sequential minimal optimization),基于多示例学习的风险识别算法采用mi-SVM 的改进算法mi-SMO。实验采用10 次10折交叉计算判定的准确性,在数据完整情况下,每个季度的财务数据完整,基于多示例的企业财务风险表达模型中包的示例个数固定,每个示例代表某季度的企业财务信息。基于监督学习的企业财务风险表达模型中企业财务风险状况由企业在这段时间内的财务风险特征平均向量表示。
按一定比例(10%,20%,30%,40%)随机删除若干个企业若干季度的财务数据,可以得到不完整的财务信息。在这种数据信息不完整情况下,基于多示例的企业财务风险表达模型中包的示例个数会根据数据的删除情况减少。基于监督学习的企业财务风险表达模型中,首先采用数据填充技术(取属性的平均值)填充数据,再取这段时间内财务风险特征平均向量表示企业财务风险状况。实验结果如表1(前与后分别表示属性简约前后的结果,表中数字均为百分数)和图2 所示。
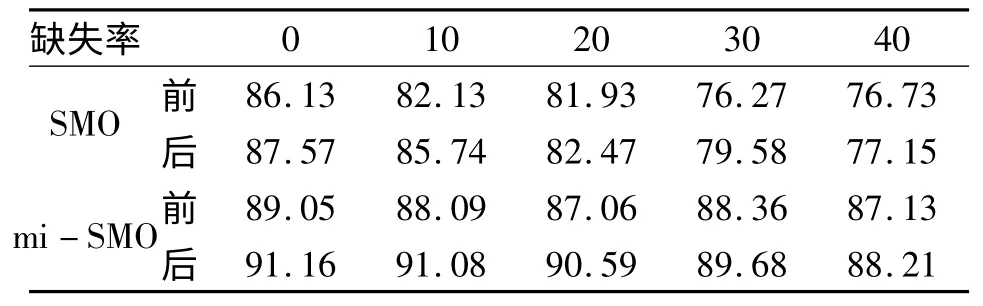
表1 不同方法风险识别准确率比较 %
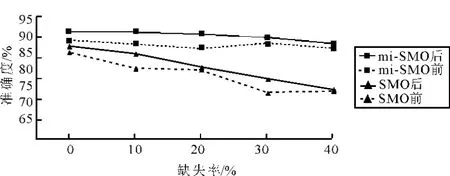
图2 不同方法风险识别准确度比较
从以上实验结果可知,通过属性选择后,基于SMO 和mi-SMO 算法的风险识别模型精度在数据信息完整和缺失的情况下均有不同程度的提升,但属性的个数相对于属性选择前减少了近2/3。正如财务分析领域的由5 个主要财务指标组成的Z-Score 模型和6 变量F 模型,找到具有最大影响力的指标,对于公司摆脱财务危机或者维持财务正常具有极其重要的意义。图2 所示为属性选择前后的准确度变化趋势。
从图2 可以看出,由于考虑了多个时间点的财务信息,无论是在数据信息完备还是缺失的情况下,基于mi-SMO 的企业财务风险识别算法的准确率均高于基于SMO 的企业财务风险识别算法,如在数据信息完备的条件下,基于mi-SMO企业财务风险的识别精度在属性删减前后比基于SMO 的算法高出2.92%和3.59%。
通过图2,还可以发现随着数据缺失率的增加,基于mi-SMO 的企业财务风险识别算法的精度下降幅度要远远低于基于SMO 的财务风险识别算法。如从数据完备到数据缺失40%,基于mi-SMO 的企业财务风险识别算法的精度在属性删减前后仅下降了1.92%和2.95%,而基于SMO 的企业财务风险识别算法的精度则下降了9.4%和10.42%。
4 结论
以多示例学习为理论基础建立的企业财务信息表达模型,从包的角度重新表示一个企业的财务状况,以每个示例表示企业某年度的财务数据,可以有效地避免因某时间点的财务数据缺失带来的问题,甚至还可以随意选取存在的任意年度的数据示例分析企业的财务风险状况。与传统的财务风险识别方法相比,基于多示例学习的企业财务风险表达模型更为灵活,且具有更高的准确率。
[1] 郑茂.我国上市公司财务风险预警模型的构建及实证分析[J].金融论坛,2003,8(10):38-42.
[2] 丁德臣.混合HOGA-SVM 财务风险预警模型实证研究[J].管理工程学报,2011,25(2):37-44.[3] BOYACIOGLU M A,KARA Y,BAYKAN K.Predicting bank financial failures using neural networks,support vector machines and multivariate statistical methods:acomparative analysis in the sample of savings deposit insurance fund (SDIF)transferred banks in Turkey[J].Expert Systems with Applications,2009,36(2):3355-3366.
[4] WU C H,TZENG G H,GOO Y J,et al.A real-valued genetic algorithm to optimize the parameters of support vector machine for predicting bankruptcy[J]. Expert Systems with Applications,2007,34(2):397-408.
[5] DIETTERICH T G,LATHROP R H,LOZANO-PEREZ T.Solving the multiple instance problem with axis-parallel rectangles[J]. Artificial Intelligence,1997,89(1):31-71.
[6] ZHOU Z H. Multi-instance learning from supervised view[J]. Journal of Computer Science and Technology,2006,21(5):800-809.
[7] ZHOU Z H,YU Y. Ensembling local learners through multimodal perturbation[J]. IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics,2005,35(4):725-735.
[8] ZAFRA A,ROMERO C,VENTURA S.Multiple instance learning for classifying students in learning management systems[J]. Expert Systems with Applications,2011,38(12):15020-15031.
[9] WANG J,ZUCKER J D.Solving multiple-instance problem:a lazy learning approach[C]// ICML-00. San Francisco:[s.n.],2000:1067-1076.
[10] ANDREWS S,TSOCHANTARIDIS I,HOFMANN T.Support vector machines for multiple-instance learning[J]. Advances in Neural Information Processing Systems,2002(15):561-568.
