Movement and behavior analysis using neural spike signals in CA1 of rat hippocampus
2013-12-20HyejinAnKyungjinYouMinwhanJungHyunchoolShin
Hyejin An, Kyungjin You, Minwhan Jung, Hyunchool Shin
(1. Department of Electronic Engineering, Soongsil University, Seoul 156-743, Korea; 2. Institute for Medical Sciences, Ajou University School of Medicine, Suwon 443-749, Korea)
Movement and behavior analysis using neural spike signals in CA1 of rat hippocampus
Hyejin An1, Kyungjin You1, Minwhan Jung2, Hyunchool Shin1
(1. Department of Electronic Engineering, Soongsil University, Seoul 156-743, Korea; 2. Institute for Medical Sciences, Ajou University School of Medicine, Suwon 443-749, Korea)
The hippocampus which lies in the temporal lobe plays an important role in spatial navigation, learning and memory. Several studies have been made on the place cell activity, spatial memory, prediction of future locations and various learning paradigms. However, there are no attempts which have focused on finding whether neurons which contribute largely to both spatial memory and learning about the reward exist. This paper proposes that there are neurons that can simultaneously engage in forming place memory and reward learning in a rat hippocampus's CA1 area. With a trained rat, a reward experiment was conducted in a modified 8-shaped maze with five stages, and utterance information was obtained from a CA1 neuron. The firing rate which is the count of spikes per unit time was calculated. The decoding was conducted with log-maximum likelihood estimation (Log-MLE) using Gaussian distribution model. Our outcomes provide evidence of neurons which play a part in spatial memory and learning regarding reward.
hippocampus; CA1; place cell; reward learning; spatial memory; Gaussian distribution; maximum likelihood estimation(MLE)
CLD number: Q189 Document code: A
0 Introduction
Recently, a great deal of research has been conducted on the hippocampus, which is located in the temporal lobe that is the part of cerebral cortex[1]. The functions of the hippocampus can be largely divided into learning and memory regarding places and works[2-4]. Memory regarding places[5], which is dealt with in this paper, is a function that determines a rat's location and explores places by using a place cell[6,7]. A place cell is a neuron that fires more strongly in a specific place than in other places, and this specific place is called a place field. This place field may be changed by the movement of an animal through the surrounding environment[8]and predict the future location of the animal for a short time period[9]. Mathew developed a system that classifies and predicts the behaviors of a rat via linear/quadratic discriminant analysis and K-means clustering[1].
The existing research on the hippocampus does not discover whether there exist the neurons that simultaneously conduct spatial memory and learning about reward because decoding regarding position or behavior is performed separately. In this paper, decoding based on position and behavior is performed separately, and merged position-behavior decoding is performed for the same neuron. For this process, the model is established with a Gaussian distribution by using the firing rate of neural signals and log-maximum likelihood estimation (Log-MLE). Based on this, we attempt to discover whether a certain neuron may simultaneously engage in place memory and reward learning.
1 Main research work
1.1 Experiment protocol
This experiment was conducted according to the protocol approved by the Ethics Review Committee on Animal Experiments at Ajou University Medical College. The rat used in the experiment was a Sprague Dawley rat (about 250-330 weeks old) obtained from Ajou University's Neural Engineering Department[10].
1.2 Experiment process
The rat was trained in a 65 cm×60 cm modified 8-shaped maze, in which the experiment was conducted. The rat can select its direction freely in each trial and be rewarded based on these selections. The possibility of reward within each session was the same. In this experiment, about 40 trials were made for each session, and a total of four sessions is 167 trials. Table 1 shows the possibilities of reward for four sessions.
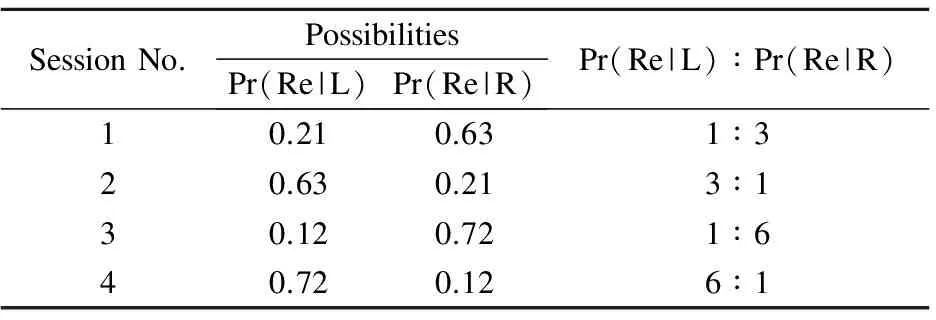
Table 1 Reward possibilities for four sessions
In Table 1, Pr(Re|L) is the reward possibility when the rat selected left, and Pr(Re|R) is the reward possibility when the rat selected right. When the reward possibilities of both directions are added up, the result is 0.84. Therefore, the cases occur in which there are no reward. The left and right reward possibilities differ in each session, but the sum remains the same.
The experiment process consists of five stages: Delay(D), Go(G), Approach(A), Reward(Rw) and Return(Rt), as shown in Fig.1. The durations of the stages are as follows: 2.0±0.0 s (D), 1.2±1.0 s (G), 1.1±0.3 s (A), 9.4±5.9 s (Rw), and 4.6±3.6 s (Rt). The average duration of the reward stage differs according to the existence and non-existence of a reward. This stage took 13.3±3.9 s in the trial with a reward, and it took 3.4±2.1 s in the trial without a reward.
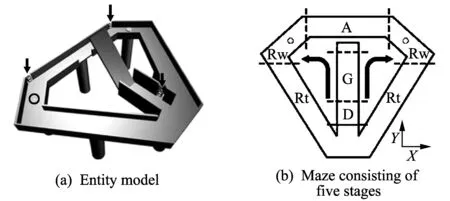
Fig.1 Two-armed bandit task
Fig.1 shows a two-armed bandit task. The width of the path is 8 cm, the height of the wall is 3 cm, and the bridge in the center does not have a wall. In Fig.1(a), the arrow denotes photobeam detectors and the disc (solenoid) represents the reward, where water is dispensed. Fig.1(b) shows the maze consisting of five stages: D, G, A, Rw and Rt. The dotted lines differentiate the stages, and the full lines denote the delay stage and the starting point of the trial. The circle in Fig.1(b) also represents the reward, and the arrows show the directions of the rat's progression[10].
Fig.2 shows the spikes that occurred during the experiment. The horizontal axis represents time (min), and the vertical axis represents 23 neurons. The gray section of Fig.2(a) is the section in which the actual experiment was conducted. Fig.2(b) shows the experimental result in specific section (20-21 min) of Fig.2(a).
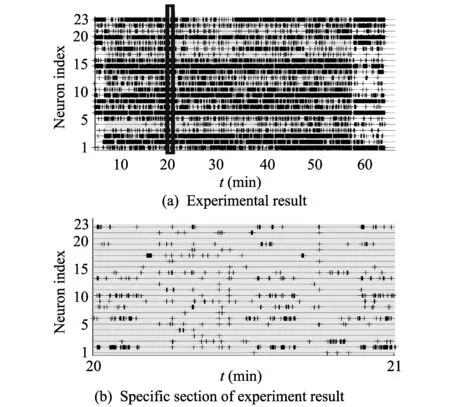
Fig.2 Plot of spiker rasters
1.3 Theory analysis
Through this experiment, the firing rate during each stage can be calculated for every trial. In this paper, the unit time was set at 1 s, and only the firing information from the starting points of D(2 s), G(1 s), A(1 s), Rw(2 s) and Rt(2 s) stages was used.
Under the assumption that the firing rate of the neurons obtained from the hippocampus of the rat follows a Gaussian distribution, using the mean and standard deviation of the firing rate obtained from the experimental data, the probability density function (PDF) can be expressed as
Firstly, every trial is differentiated in terms of the selection of directions (right or left) and the existence or non-existence of a reward (reward or no reward), and then, using the firing rate, trial average (μn(k)) and trial standard deviation (σn(k)) can be calculated. When the standard deviation is zero, a value very close to zero can be used.
Fig.3 shows Gaussian model. The horizontal axis is the firing rate (spike/s), and the vertical axis is probability. The bin size is 0.5 spike/s. Fig.3(a) represents the Gaussian model of neuron 15 regarding the selection of direction. Fig.3(b) represents the Gaussian model of neuron 3 regarding the existence or non-existence of a reward (the neuron index was arbitrarily designated).
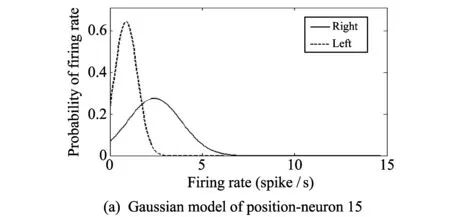

Fig.3 Gaussian models of firing rates
After the application of Gaussian model, the selection of direction and the existence or non-existence of reward are estimated via Log-MLE, which is calculates the most appropriate estimated value for the parameter. Every trial is classified according to the selection of direction or the existence or non-existence of a reward. In this study, the total number of trials is 167, the number of trials for the right direction is 84, the number of trials for the left direction is 83, the number of trials with a reward is 100, and the number of trials with no reward is 67. The total trials are divided in half and categorized into training data and test data. The training data is used for Gaussian modeling, and the test data is employed in determining the reverse inference of the selection of a direction or the existence or non-existence of a reward through Log-MLE. In this case, the PFD of k can be expressed as
and if each neuron is probabilistically independent, the likelihood function with this value as the maximum value can be denoted as
The logarithm of the above formula was taken in order to simplify the necessary differential calculus and expression of a wide range of likelihood values.
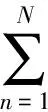
2 Decoding experiments and results
The three types of decoding experiments are conducted in this paper, which include position decoding, behavior decoding and merged position-behavior decoding, and the experimental results are shown in Fig.4.
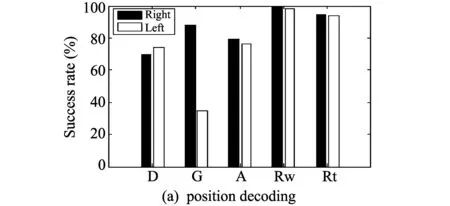
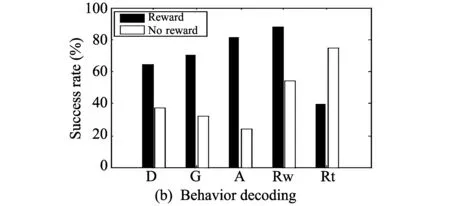
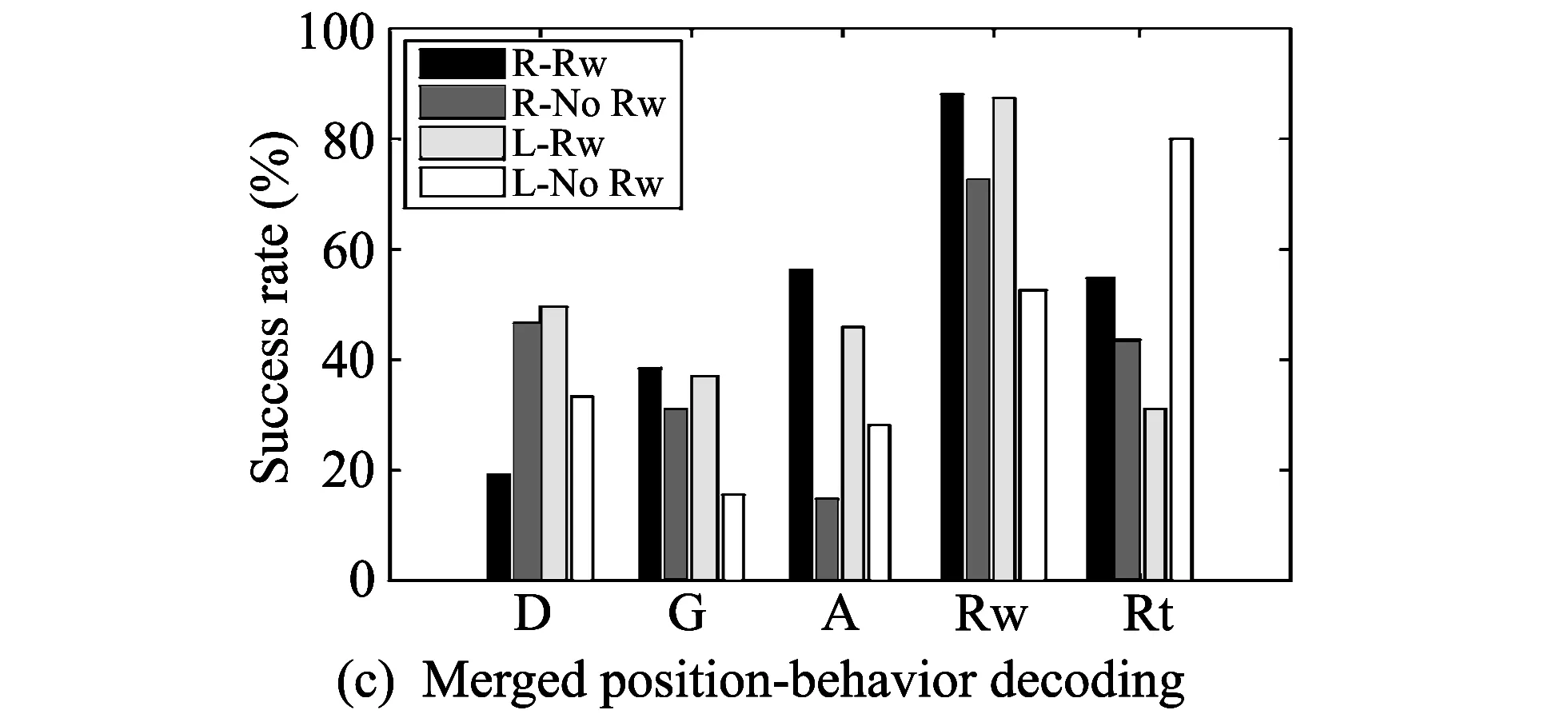
Fig.4 Results of three decoding experiments
Position decoding classifies and infers all trials into right and left only. Fig.4(a) shows the success rates of position decoding. The black color (Right) is an estimation of trials in which the rat goes to the right direction, and the white color (Left) is an estimation of trials in which the rat goes to the left direction. According to the eyperimental results, the success rates of Rw and Rt stages are high. In Rw suage, the success rate of right is 99.67% and that of left is 98.07%. And in Rt stage, the success rate of right is 94.88% and that of left is 94.24%.
As for behavior decoding, all trials are classified according to only the existence or non-existence of a reward and are inferred. Fig.4(b) shows the success rates of behavior decoding. The black color (Reward) is an estimation of the trials with a reward, and the white color (No reward) is an estimation of trials without a reward. During Rw stage, the success rate of reward is 87.66% and that of no reward is 54.27%. In the remaining four stages, except for this stage, performance is low.
In the merged position-behavior decoding, all trials are divided into four kinds: trials in which the rat goes to the right direction and receives a reward, those in which the rat goes to the right direction but does not receive a reward, those in which the rat goes to the left direction and receives a reward, and those in which the rat goes to the left direction but does not receive a reward, and then decoding is conducted. Fig.4(c) shows the success rates of the merged position-behavior decoding. The black color (R-Rw) represents trials in which the rat goes to the right direction and receives a reward, the dark gray color (R-no Rw) represents trials in which the rat goes to the right direction and does not receive a reward, the light gray color represents trials in which the rat goes to the left direction and receives a reward, and the white color represents trials in which the rat goes to the left direction and does not receive a reward. In Rw stage, the success rate of R-Rw is 88.48%, that of R-no Rw is 73.00%, that of L-Rw is 87.68%, and that of L-no Rw is 52.58%. The success rates of the other stages are low.
3 Discussion and conclusion
Using a Gaussian distribution, this paper models the neural firing information generated when a reward is given according to a rat's selection of right or left. Then, position decoding, behavior decoding and merged position-behavior decoding are carried out for each position and behavior.
In position decoding, the success rates of right and left during the reward stage and the return stage are high. In A stage, the division between the left and the right begins to be created in the two-armed bandit task, and the success rates are relatively high when compared to D stage and G stage, but overall, it is difficult to say that the success rates are high. In addition, during G stage, performance does not differ much, even though the path is not divided into right and left, and in terms of position decoding, this stage has no meaning.
In terms of behavior decoding, the success rates of estimating reward at Rw stage are high. There are many cases in which no-reward trials are classified as reward trials. This is because in the modeling distribution, the probability values of the reward distribution overlapping with the no-reward distribution of certain neurons are higher.
In terms of merged position-behavior decoding, the success rates of all behavior and position estimations (R-Rw, L-Rw) are high when the rat receives a reward. However, when the rat does not receive a reward, this form of decoding shows poor performance in terms of behaviors. In the case of a failure in estimation, much like the case of behavior decoding, the incorrect classification of no reward as reward is more frequent than the incorrect classification of reward as no reward. The remaining four stages, except for the reward stage, show low success rates.
During Rw stage, both position decoding (right, left) and behavior decoding show high success rates when the rat receives a reward. In the merged position-behavior decoding, as decribed above, when positions are bound and the rat receives a reward, the success rates are quite high. The neurons used for the three types of decoding are the same, therefore, it can be said that there are neurons that engage in both spatial memory and learning among them.
Through the two experimental results of this paper (position decoding and reward decoding), it can be known that the success rates during the no reward stage are much lower than those during the reward stage. Accordingly, research on the characteristics of neuron firing that may occur when the rat does not receive a reward is considered necessary.
[1] Mathew J, Sahoo L, Saha G. A system for behavior prediction based on neural signals. Neurocomputing, 2012, 97: 214-222.
[2] Scoville W B, Milner B. Loss of recent memory after bilateral hippocampal lesions. Journal of Neurology, Neurosurg and Psychiatry, 1957, 20(1): 11-21.
[3] Gruart A, Mu†oz M D, Delgado-García J M. Involvement of the CA3-CA1 synapse in the acquisition of associative learning in behaving mice. The Journal of Neuroscience, 2006, 26(4): 1077-1087.
[4] Bear M F, Connors B W, Paradiso M A. Neuroscience exploring the brain. 3rd ed. Lippincott Williams and Wilkins, USA, 2007: 743-751.
[5] Moser M B, Moser E I. Distributed encoding and retrieval of spatial memory in the hippocampus. The Journal of Neuroscience, 1998, 18(18): 7535-7542.
[6] Brown E N, Frank L M, Tang D, et al. A statistical paradigm for neural spike train decoding applied to position prediction from ensemble firing patterns of rat hippocampal place cells. The Journal of Neuroscience, 1988, 18(18): 7411-7425.
[7] Liaw J S, Berger T W. Dynamic synapse: a new concept of neural representation and computation. Hippocampus, 1996, 6(6): 591-600. [doi:10.1002/(SICI)1098-1063]
[8] Barbieri R, Frank L M, Quirk M C, et al. A time-dependent analysis of spatial information encoding in the rat hippocampus. Neurocomputing, 2000, 32/33: 629-635.
[9] Muller R U, Kubie J L. The firing of hippocampal place cells predicts the future position of freely, moving, rate. The Journal of Neuroscience, 1989, 9(12): 4101-4110.
[10] Kim H, Sul J H, Huh N, et al. Role of striatum in updating values of chosen actions. The Journal of Neuroscience, 2009, 29(47): 14701-14712.
date: 2013-06-16
The MSIP (Ministry of Science, ICT & Future Planning), Korea, under the ITRC (Information Technology Research Center) support program (NIPA-2013-H0301-13-2006) supervised by the NIPA (National IT Industry Promotion Agency); The Brain Research Program through the National Research Foundation of Korea funded by the Ministry of Science, ICT & Future Planning (2011-0019212)
Hyunchool Shin (shinhc@ssu.ac.kr)
1674-8042(2013)04-0392-05
10.3969/j.issn.1674-8042.2013.04.019

JournalofMeasurementScienceandInstrumentationISSN1674⁃8042,QuarterlyWelcomeContributionstoJMSI(onlinesubmission:http://mc03.manuscriptcentral.com/jmsi)(http://xuebao.nuc.edu.cn)(jmsi@nuc.edu.cn)※ JMSIaimstobuildahigh⁃levelacademicplatformtoexchangecreativeandinnovativeachievementsintheareasofmeasurementscienceandinstrumentationforrelatedresearcherssuchasscientists,en⁃gineersandgraduatestudents,etc.※ JMSIcoversbasicprinciples,technologiesandinstrumentationofmeasurementandcontrolrelatingtosuchsubjectsasMechanics,ElectricalandElectronicEngineering,Magnetics,Optics,Chemis⁃try,Biology,andsoon.※ JMSIhasbeencoveredbyUPD,CNKIandCOJ.※ JMSIhasbeencoveredbyCA,AJ,IC,EBSCO,UPD,CNKI,COJandCSTJ.
杂志排行

Journal of Measurement Science and Instrumentation的其它文章
- A CAWL handler for context-aware composite workflow services
- Synthesis and cost estimation of ethylene oxide process using PRO/II
- Efficient model building in active appearance model for rotated face
- Preparation and characterization of TiO2-SiO2-Fe3O4 core-shell powders in nano scale
- Changes in hippocampal neural response by external reward
- 3D obstacle detection of indoor mobile robots by floor detection and rejection