DTindex:分布式时态索引技术
2013-12-13叶小平廖青云朱峰华
叶小平 ,周 畅,廖青云,朱峰华
(华南师范大学计算机学院,广东广州510631)
在计算机应用领域中是通过时态数据描述和处理客观事物发展变化.由于时态数据量巨大,通常采用基于外存的管理方式.目前,数据管理发展趋势是“万维网与数据库技术的进一步融合”[1],分布式数据管理成为应用和研究热点.分布式数据库(DDB)技术经历了2个发展阶段. 首先是第一代DDB,其基本研究方向是如何在分布式环境下实现单机数据库的各项基本功能(数据分布、事务管理和查询优化等);再就是新一代DDB,其主要研究方向是动态数据复制、缓存技术和基于网络的系统结构体系例如P2P 等[2]. 从应用实现角度考虑,通信开销和站点负载均衡是DDB 关注的重要环节.对整个系统而言,通信开销除依赖网络条件还依赖于数据管理功能配置,而站点工作负载均衡在相当程度上依赖于系统中数据分布.工作负载的均衡配置关系到分布式系统的可靠性(负载差距过大,最大负载站点可能就是出现故障的短板)和稳定性(负载失衡是导致系统不稳定的主要因素之一). 负载均衡应当不只是简单的数据量均分,主要是根据数据本身特征获取查询期望的均衡.
数据查询是数据处理的基本要求,时间本身特有性质如单向性(单调递增)、多维性(有效、事务和用户时间维等)和相互关系的复杂性(Allen 时间关系[3])等,使得时态数据不能按照关系数据模式处理.时态索引就成为实现查询的基本途径.据所掌握资料,现有基于外存时态索引主要有关于版本管理的事务时间索引[4-5]、关于有效时间的B+树索引[6]和关于双时态的R 树索引[7]等.时态数据的海量性和共享性适合于分布管理,但现有时态索引大都基于单机.本文采用不同于常规“代数”框架,引入“关系”建立基本数据结构,提出一种分布时态索引技术DTindex. DTindex 具MLPindex 和LPindex 两 级索引结构,可根据情况灵活配置,并按P2P 架构进行部署. 为有效实现DTindex,引入了“查询期望”概念,通过期望均衡实现工作负载均衡;同时,MLPindex 相对于LPindex 有2个以上数量级的差异,可根据需要在某个Slaver 中部署MLPindex 以作为Master,甚至每个Slaver 中都可同时部署MLPindex 和LPindex 以减少相应通信开销.
1 时态拟序数据结构
时态数据Td 可看作非时态数据D 与有效时间期间VT 构成的二元组Td = <D,VT >,VT =[VTs,VTe),VTs、VTe 分别表示VT 始点和终点(VTs ≤VTe). 设Γ 是时间期间集合. ∀uΓ,u =[VTs,VTe),在VTs-VTe 平面上,称P(u)=(VTs,VTe)为u 对应的(二维)时间点. 设P0= (min{VTs(P)},max{VTe(P)}),PΓ. 由P0开始得到P(Γ)深度优先序列记为S(Γ).
定义1 (时态拟序和线序划分)设E 是时态数据集合,E 上关系:Td1,Td2E,Td1Td2⇔VT(Td1)⊆VT(Td2),称“”是E 上满足自反性和传递性的时态拟序(temporal quasi-order).时态拟序集合Γ 中一个全序分枝称为线序分枝(Linear Order Branch,LOB). 设Σ 是Γ 上LOB 集合,若∀LOBi,LOBjLOP,i≠j,LOBi∩LOBj=∅,且∪LOB =Γ,称Σ 是Γ 上一个线序划分(linear order partition,LOP),并记为LOP(Γ).
算法1 (LOP 构建算法)设有深度优先序列S(Γ).
step1 由S (Γ)首元素u0始至ui0S(Γ),
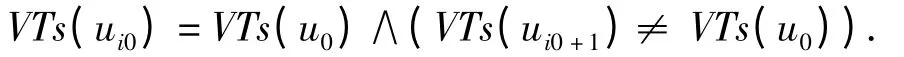
step2 由ui0始至ui1:VTe(ui1)= VTe(ui0)∧VTs(ui1)=min{VTs(uj)},其中,ujS(Γ)∧(∃ukS(Γ),VTs(uk)=VTs(uj)∧VTe(uk)<VTe(uj))
step3 由ui1始,继续“step1”和“step2”,直至umS(Γ),u'mS(Γ)使得VTe(u'm)<VTe(um),S(Γ)中由u0至um的子序列即是一个LOB1.
step4 由S(Γ)LOB1首元素始,继续step1~step3,得LOB2,…,直到S(Γ)=∅,即得LOP(Γ).
定义2 (基于LOB 时间数)设u =[VTs,VTe)LOB,LOBELOP,序号为no(LOB). u 基于LOB时间数(time number,TN)定义为TN(u,LOB)=no(LOB)×102r+VTe ×10r-VTs,其中r 是Γ 中所有时间期间中“最大”时间端点数的“位数”.
定理1 (时间数基本性质)①在LOB 内,u 和TN(u,LOB)之间的对应是1-1 映射. ②∀u,vLOB0,u≺v⇔TN(u,LOB)≤TN(v,LOB),LOB0是给定的序分枝.
证明略.
2 时态拟序数据结构
设时间期间集合Γ 上LOP = <LOB1…,LOBi,LOBi+1,…,LOBm>,vi= max LOBi. 对于集合{v1,…,vi,vi+1,…,vm},由在VTs-VTe 平面上最靠“左”的且VTe(vi0)最大的vi0开始构建. 在其上再按照“右优先”进行线序划分.得到的线序分支集合记为max(LOP),如图1 所示.
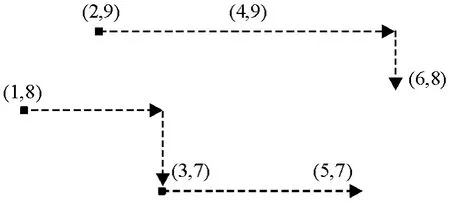
图1 “右优先”算法Figure 1 Right first algorithm
这样,在给定Γ 上可建立两级数据结构,一是Γ 上基于下优先的LOP 结构;二是LOP 上基于“右优先”算法的max(LOP)结构.由定理1,LOB 中元素与基于LOB 时间数等价,可使用基于时间数的B+树对Γ 进行索引.
定义3 (时态索引DTindex)分布时态索引DTindex(Γ)= <MLPindex(Γ),LPindex(Γ)>. 其中,①LPindex(Γ):基于B+树关于LOP 索引,结点结构<TN(u),LOB >(uLOB);②MLPindex(Γ):基于B+树关于max(LOP)索引,结点结构<TN(v),vs 所在LOB 编号>.
基于DTindex 查询过程如图2 所示.首先,通过MLPindex 查找可能查找结果的LOB 编号;再按照LOB 编号由MLPindex 得到查找结果而查找结果是整个LOB 或LOB 片段.其中,MLOP 是基于max(LOP)的线序划分.
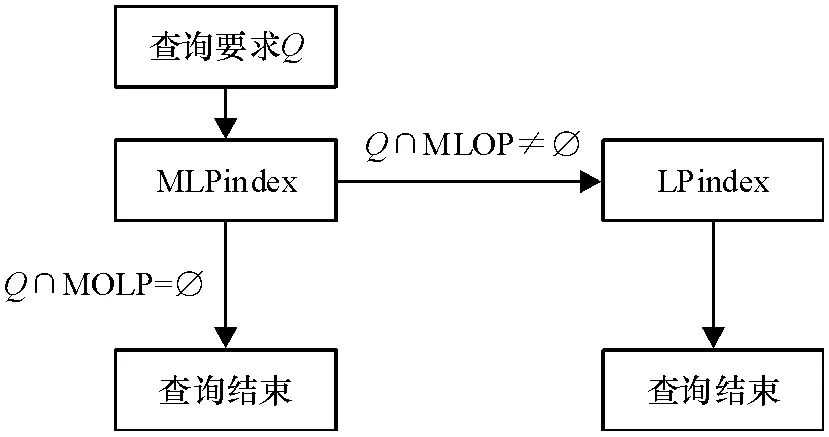
图2 基于DTindex(Γ)查询Figure 2 Queries based on DTindex(Γ)
例1 设有深度优先序列实例S(Γ)如图3 所示.
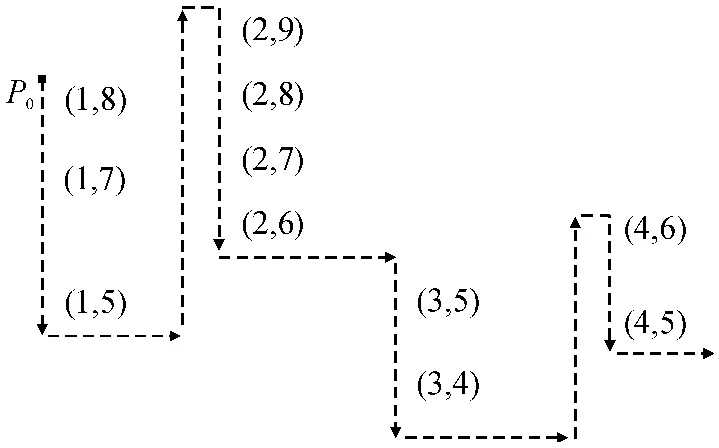
图3 深度优先序列S(Γ)Figure 3 Depth first sequence S(Γ)
此时,对于S(Γ)= <[1,8),[1,7),[1,5),[3,5),[3,4),[2,9),[2,8),[2,7),[2,6),[4,6),[4,5)>,算法1 实现如图4 所示,由此得到LOP=(LOB1,LOB2):LOB1= <[1,8),[1,7),[1,5),[3,5),[3,4)>,LOB2= <[2,9),[2,8),[2,7),[2,6),[4,6),[4,5)>. 此时v1=max(LOB1)=[1,8),v2=max(LOB2)=[2,9),由此得到MLOP=([2,9),[1,8)).由此构建的DTindex(Γ)如图5所示.

图4 下优先算法实现Figure 4 The implementation of down first algorithm
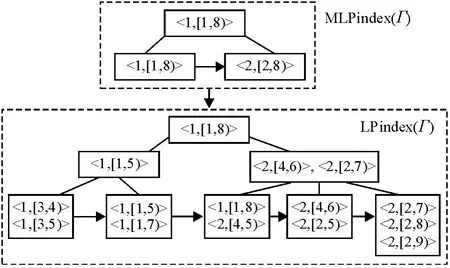
图5 DTindex(Γ)Figure 5 DTindex(Γ)
设Q0=[2,4),由MLOP(Γ)得Q0=[2,4)⊆[2,9),Q0=[2,4)∩[1,8)≠∅,因此得到编号为1和2 的LOB 都有可能的结果.进入LPindex(Γ),由(1,(2,5))得结果<1,(1,5)>,<1,(1,8)>,<1,(1,8)>;由(1,(2,6))得结果<2,(2,7)>,<2,(2,8)>,<2,(2,9)>. 最终查询结果集合为{<1,(1,5)>,<1,(1,8)>,<1,(1,8)>;<2,(2,7)>,<2,(2,8)>,<2,(2,9)>}.
3 DTindex 分布式实现
3.1 基于查询期望的数据分布
一个“好”的分布式系统其站点资源通常均衡,均衡的站点资源应当与均衡的工作负载相匹配. 数据在各个站点的均衡配置不只是数据量平均分割.设LOP={LOB1,LOB2,…,LOBm},最小时间端点为0,最大为MAXT,此时至多只有S = (MAXT +1)(MAXT+2)/2个时间期间.
定义4 (时间期间的查询概率)对Γ 中VT =[VTs,VTe),所有被包含在VT 中的时间期间都在如图6 所示的带阴影的三角形区域Δ(VT)内. 因此,只有当查询期间Q0Δ(VT)时,VT 是查询结果,即Δ(VT)是查询中VT 所发挥作用的区域. 如以Δ(VT)表示其中包含VT个数,定义VT 查询概率为P(VT)=Δ(VT)/S=(VTe-VTs)2/2S.
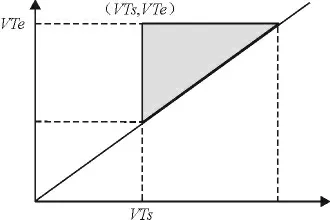
图6 时间期间VT 的的查询概率Figure 6 The query probability on time period VT
定义5 (线序划分的数学期望)设随机变量X(VT)∶X(VT)=1 如果VT 是查询结果;X(VT)=0如果VT 不是查询结果. 此时,X(VT)数学期望E(X(VT))= P(VT). 给 定LOB 中 被 查 询 到个 数N(LOB)=Σ X(VTi),VTiLOB,N(LOB)数学期望E(N(LOB))定义为E(N(LOB))=Σ E(X(VTi))=Σ P(VTi).给定LOP,对其中LOBi计算E(N(LOBi)),则数学期望EN(LOP)定义为EN(LOP)=Σ E(N(LOBi)).
算法2 (基于查询期望分割算法)将LOP 分配到n个站点.首先,设有EN(LOP),计算站点应分配数据的数学期望δ(EN(LOP),n)=EN(LOP)/n.其次,设LOP ={LOB1,LOB2,…,LOBm},依次对各站点分配数据,当第1个站点分配数据的数学期望达到或接近δ(EN(LOP),n)时停止,接着第2 站点,…,直至最后.
3.2 基于C/S 部署
设系统具有n个站点.在C/S 架构下按照算法2将LOP(Γ)分割成LOP(Γ1),…,LOP(Γn),分别在Slaver1,…,Slavern建立LPindex(Γ1)和LPindex(Γ2);再按照LOP 在Master 机建立MLPindex(Γ),输入查询Q0后,通过MLPindex(Γ)得到可能的LOB 编号,由LOP 在Slave1,…,Slaven分布情况,将相应LOB编号和Q0发送相关站点Ti.最终,Master 将各个Ti结果整合后输出.作为一种C/S 架构,P2P 中每个站点具信息交换和服务功能,可作为Master 接收查询请求分配查询事务,也可作为Slave 执行应用程序.在DTindex 中,MLPindex 和LPindex 数据规模相差2个数量级以上,Master 主要是确定具有能查询结果LOB 编号并将其发送到相应Slaver,同时整合各Slave 查询结果. 将MLPindex 部署到每台Slaver,将某网络条件较佳Slaver 作为相应Master 以减少通信开销.
本文仿真环境为3 台PC 机和1 台交换机组成的100 Mbps 的以太网.实验数据为随机生成1 千万个无重复的时间区间,并按照算法1 产生LOB.这些LOB 组成的LOP 按照算法2 被分割为3个子LOP1、LOP2和LOP3.随机生成750个查询区间Q0并将其分为5 组,各组个数分别为50,100,150,200,250.3 台PC 都运行Slaver,装载LOP1、LOP2和LOP3并部署LPindex,用Slaver1 运行Master 并部署MLPindex.系统关于每组查询时间开销为Master 分配查询直到输出结果花费时间总和,如图7 所示.
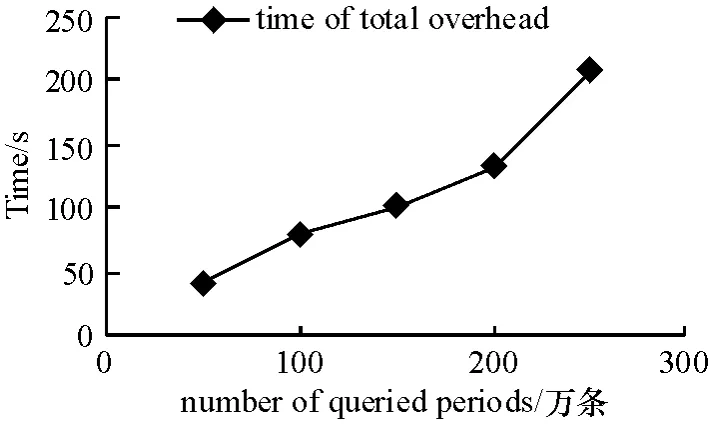
图7 Master 查询过程时间开销Figure 7 The time overhead of Master
Slaver 时间开销为由Master 接收查询执行到返回结构至Master 的通信时间. 如图8~图10 所示,两辅机站点工作负载基本均衡,呈线性增长.
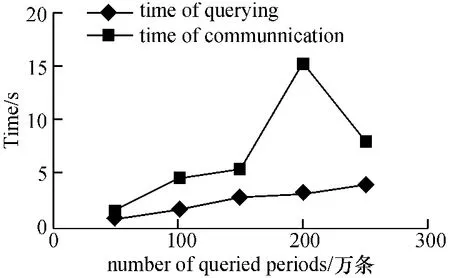
图8 Slaver1 工作过程的时间开销Figure 8 The time overhead of Slaver1
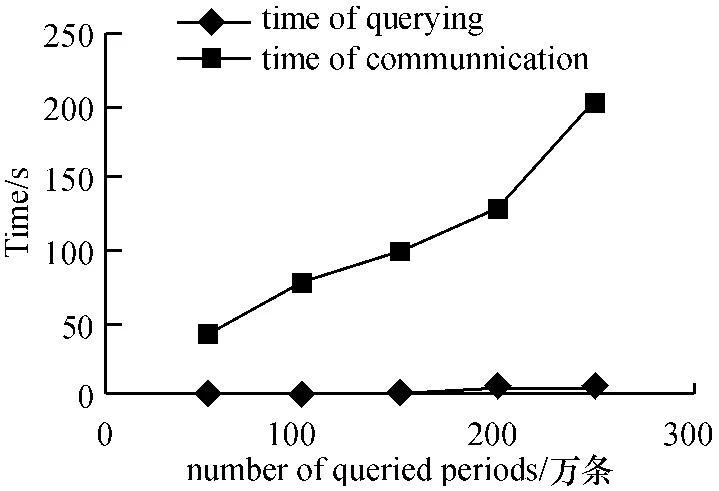
图9 Slaver2 工作过程的时间开销Figure 9 The time overhead of Slaver 2
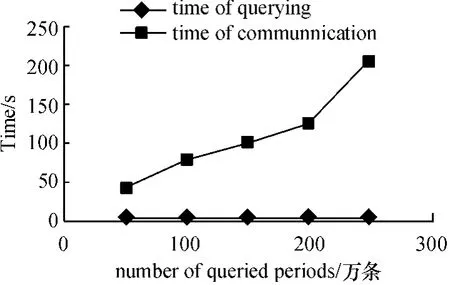
图10 Slaver3 工作过程的时间开销Figure 10 The time overhead of Slaver 3
3.3 基于P2P 部署策略
P2P 部署的一个基本问题是在网络中如何选取主站点Master.LOB 的基于“查询期望”是本文索引分布式扩展的基本要素,因此也可用来作为Master选取的基本参数.
由每个站点中存储的所有LOB 得到该站点的“查询期望”,选取“查询期望”值最大的站点作为Master,具体选定过程通过扩展“选举环”[8]算法实现.
在逻辑上,各个站点看做是沿环排列(如图11 所示).第i个站点存储LOB 集合标识为<EN(LOPi),i >,其中EN(LOPi)为该站点的“查询期望”.

图11 选举环算法Figure 11 Algorithm of election rings
首先,每个站点都为“选举”中非参加者. 随机地由一个或多个站点开始一次选举,发起选举站点将自身标记为参加者,并将标识放入一个选举消息发送至下一个站点.
其次,当某个站点收到选举消息时,比较接受标识和自身标识.如果到达的标识较大,就将消息转发给下一个站点;如果到达标识较小,自身又非参加者,则把消息里标识替换为自身标识并转发消息,而当自身已是参加者,则不转发消息,只转发一个选举消息,进程把自己标记为参加者.如果收到的标识是接受者自己,则该站点标识最大,成为Master. 当选进程将自己标记为非参加者并向下一个进程发送一个当选消息,将其标识放入消息.
最后,当站点收到一个站点消息,它将自己标记为非参加者,并记录消息里标识为当选站点,并将消息转发到下一个进程;如果它已经是Master,则终止消息发送.
4 结束语
本文提出了基于查询期望均衡的数据分布算法,通过分布式站点的负载平衡增强系统的稳定性与可靠性;另外,研究DTindex 的P2P 部署策略以减少系统通信开销和提升系统效率. 由于DTindex 具数学支撑,看可作为一种时间数据处理框架,适用时态对象、XML 和移动对象数据等.DTindex 具增量式更新机制,可实现时间数据的动态复制,相关课题将另文讨论.
[1]孟小峰,周龙骧,王珊.数据库技术发展趋势[J].软件学报,2004,15(12):1822-1836.
[2]STEPHANOS A T,SPINLLIS D. A survey of peer to peer content distribution technology[J]. ACM Comput Surv,2004,36(1):315-371.
[3]ALLEN J F. Maintaining knowledge about temporal intervals[J].Commun ACM,1983,26(11):832-843.
[4]MORO M M,TSOTRAS V J. Transaction-time indexing[R]∥Temporal Database Entries for the Springer Encyclopedia of Database Systems,Time Center Technical Report TR-90,New York:Springer,2008.
[5]LOMET D,HONG M,NEHME R,et al. Transaction time indexing with version compression[J]. Proceedings of the VLDB Endowment,2008,1(1):870-881.
[6]NASCIMENTO M,DUNHAM M.Indexing valid time database via B+-tree:The MAP21 approch[R]∥Technical Report CSE-97-08,Dallas,USA:School of Engineering and Applied Sciences,Southern Methodist University,1997.
[7]BLIUJUTE R,JENSEN C S,SALTENIS S,et al. Lightweight indexing of bitemporal data[C]∥Proceedings of the 12th International Conference on Scientific and Statistical Database Management.Berlin:IEEE Computer Society,2000:125-138.
[8]COULOURIS G,DOLLIMORE J,KINDBERG T. 分布式系统概念与设计[M].3 版. 金蓓弘,译. 北京:机械工业出版社,2004.
