基于ANTLR 的前端编译器若干关键问题的研究与实现
2013-12-06王海燕杨鹤标
王海燕,杨鹤标
(1.宿迁学院计算机科学系,江苏 宿迁223800;2.江苏大学计算机科学与通信工程学院,江苏 镇江212013)
0 引言
编译技术已广泛应用于编译器构造之外的其他领域,如程序分析、模型转换、语言处理等领域[1]。所有这些领域的应用,说明了编译技术的普遍性和重要性。为了简化编译技术的处理,用户通常将编译处理的工作分为前端编译和后端编译2个部分,前端编译完成语言源代码的分析,同时为后端编译提供必要的信息;后端编译则是在前端编译的基础上,完成代码生成及代码优化等工作。鉴于编译技术应用的普遍性和重要性,结合ANTLR构建编译器的优势,文章详细描述了以ANTLR作为编译器分析工具遇到的关键技术问题,并对此问题进行分析,给出了可行的解决方案。
1 ANTLR设计前端基础
1.1 ANLTR简介
ANTLR是语言识别器的一种,其前身是PCCTS。ANTLR接受EBNF[2]描述的规则,采用自顶向下的递归分析方法,是LL(*)分析方法的一种实现方式[3]。用户可以通过ANTLR提供的元语言完成各种源代码的文法描述,进而通过ANTLR解析所描述的文法,生成各种目标语言的源代码,如:C、C++、C#、Java、Python。目前,ANTLR是一个免费的、开放源代码的工具,已经在研究领域和商业领域得到了广泛的使用,与其他编译分析器相比,ANTLR的好处有[4]:(1)错误处理能力强,生成的代码为面向对象风格;(2)具有良好的可读性、便于调试;(3)异常错误处理的最小粒度可以得到具体的标号;(4)可以在文法定义的任何位置设置返回值和参数。
1.2 前端的整体结构
编译器前端的设计包含了词法分析和语法分析,通过词法、语法分析可以构造目标语言及抽象语法树,进而为后续的程序分析、模型转换、语言处理提供基础。前端的整体结构如图1所示。
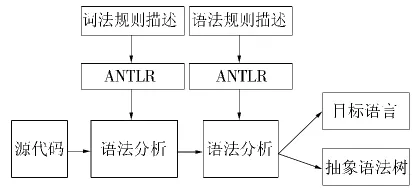
图1 前端结构
图1中词法规则描述、语法规则描述是ANTLR进行词法分析和语法分析的基础。显然无论是词法规则描述不正确,还是语法规则描述不正确,其结果都无法形成相应的分析器;此外,即使词法、语法各自的规则描述正确,能生成对应的词法分析器和语法分析器,但若是规则描述不恰当、不精简、不明确,则生成的代码必然存在质量低下等问题。因此,本文提出了基于ANTLR前端编译器的若干关键技术的解决方案。
2 关键技术
图1中的源代码代表了某种领域特定语言,即领域专用语言(domain specific language,DSL),这种语言的基本思想是“求专不求全”,不像通用目的语言那样目标范围涵盖一切软件问题,而是专门针对某一特定问题的计算机语言[5]。
对于这种语言的结构我们可以用文法来描述,文法无论对语言的设计还是对编译器的编写,至少在以下3个方面起着重要的作用:(1)文法给出了易于理解的、精确的语言结构的描述;(2)以文法为基础的语言,便于增加、修改、删除旧的语言结构;(3)有些类别的文法,可以自动生成高效的分析器。
文法(Grammar)通常可以表示为四元组:G(Z)=(Vn,Vt,S,P)。其中Vn 表示非终结符(定义对象的集合,如语法成分等);Vt表示终结符(字母表);S是非终结符,表示文法的开始符号;P是产生式的有限集合,即规则集。文法识别,常采用自顶向下的LL(K)分析方法和自底向上的LR分析方法。一般认为LL(K)分析方法较LR(K)分析方法便于被人们所接受和采用[6]。ANTLR最初采用的是LL(K)递归下降分析法,现已升级为LL(*)递归下降分析方法,该方法较之前的方法有了明显的改善,但无论采用LL(K)还是采用LL(*),递归下降法都是一种自上而下的分析模式,即从入口产生式开始分析,根据所分析的记号流表现形式,匹配不同的产生式。
2.1 左递归
如前所述升级版ANTLR采用的是LL(*)分析方法,而LL分析法是不支持左递归文法的。为此在制作文法时,用户首先要考虑的是怎样避免左递归。接下来,我们按照左递归存在的2种形式——直接左递归和间接左递归,进行分别讨论。
2.1.1 直接左递归

上式中大写字母表示文法规则,小写字母表示词法符号。(1)式规则A的产生式有2个,分别是Aa和b。第一个产生式Aa,最左端包含了A,这是一个直接左递归;(2)式 A 产生bB;(3)式B产生aB和空集。(1)式经化解后,转化为(2)式和(3)式,消除了左递归。
2.1.2 间接左递归

化解步骤:
(1)首先转化为直接左递归式

(2)在步骤(1)基础之上,再用直接左递归转化为不含递归的产生式。
(3)经步骤(2)化解为:

间接左递归(4)、(5)两式经化解后,转化为(7)、(8)两式,同样也消除了左递归。
经过上述分析,无论是直接左递归还是间接左递归均可通过化解消除。我们把经化解消除后得到的产生式称之为尾递归(所谓尾递归形如:B->aB)。有了尾递归,借助ANTLR的元语言可以将其进一步改写,得到相应规则的文法描述。
2.2 算符的结合性
算符连接操作数构成最基本的表达式,无论是单目算符还是多目算符,算符都有其自身的结合性,算符的结合性不外乎左结合和右结合,接下来分别讨论2种结合性在ANTLR中的文法形式。
2.2.1 左结合
左结合,诸如算术运算符:+、-、*、/、%,关系运算符:>、<、==、!=。在LL识别器中,左结合算符通过指定重复匹配进行定义,形式如下:A->a((op)a)*。
2.2.2 右结合
右结合,诸如赋值运算符:=、+=、%=。a=b=c等价于a= (b=c)。在LL识别器中,右结合算符通过尾递归文法进行定义,形式如下:B->a op B。
2.3 算符的优先级
在LL文法识别器中,算符的优先级要通过文法的嵌套定义来体现。优先级低的算符要优先声明,相同优先级的算符可以在同一个规则中描述。形式如下:
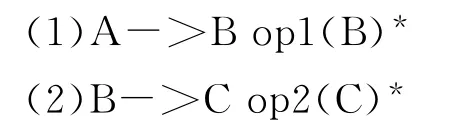
式中op1的优先级低于op2的优先级。
2.4 语法断言
ANTLR通过元语言定义文法规则,在进行文法分析时,它提供了语法预测和语义预测。这两种预测机制要求用户要事先设定向前看的K值,以用于匹配某一产生式。但有的时候,用户无法根据匹配的句子事先确定预测机制中的K值,此时用户可以不考虑K值的定义,选用ANTLR中提供的语法断言。ANTLR的语法断言可以处理复杂的语言结构,解决LL(*)预测中最多只能向前看K个符号的问题,如:
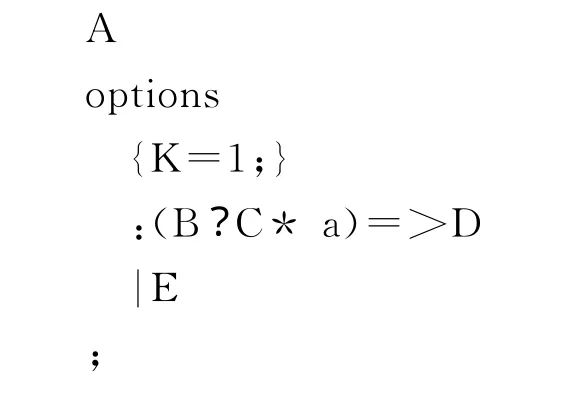
上述产生式中A、B、C、D代表文法规则,a代表某种词法符号,’=>’是语法断言推导符号,由于无法根据K值确定某一产生式,故令K=1。根据语法断言符号(’=>’)之前条件表达式,可以推导出产生式A。
从以上关键技术的研究可以看出:本文提出的解决方案,统一了文法的制作思想,无论应用于何种领域语言,该技术的研究都可以帮助用户快速有效地制作文法,实现基于ANTLR的编译器制作。接下来我们将此研究应用于实际领域语言,并以Java语言作为目标代码,实现了一次开发处处使用的便利。
3 实例分析
通过上述对编译器若干关键技术的研究,我们以类C为领域语言,Java为目标语言进行分析,抽取出部分类C语言的文法,如表1所示。

表1 规则的描述
表1较多地给出了语法产生式,词法产生式仅给出了一个。这样做的原因是:语法分析是编译程序的核心部分,它是以识别符号序列是否为给定的句子为目的的。接下来一一说明表中的含义:序号为1第1行的产生式是词法产生式,变量(IDENTIFIER)规则的定义有效地避免了左递归;序号为2第2行的产生式(external_declaration)指出了类C包含了函数定义与函数声明2个部分,在该产生式的后面紧跟着K 值的设置(K=1),external_declaration产生式可以推导出函数定义和函数声明2种路径,利用ANTLR的语法断言有效地解决了输入语句匹配哪一条路径的问题,提高了设置K值的灵活性;序号为3第3行的产生式指出了函数定义(function_definition)包含了:函数存储类别,函数名,函数的参数及复合语句组成等;序号为4第4行的产生式指出了参数列表(paramDeclList)可以有0个或多个参数组成,从参数的定义可以看出:函数的参数是左结合顺序,即求值顺序是自左向右;序号为5第5行包含了2个产生式:equalityExpr和comparisonExpr,产生式comparisonExpr被嵌套在equalityExpr产生式之中,解决了关系运算符优先级的问题。通过分析可以看出类C程序由若干函数声明和函数定义组成。
依据上述文法定义,借助antlrwork工具,最终生成了词法、语法分析器,形成了目标语言代码。当然还可以借助ANTLR提供的树编译器形成抽象语法树,即本文的研究不仅是构造编译器前端的基础,也为程序分析(如代码相似度检测)、模型转换、语言处理提供了一种新途径。
4 结语
在研究分析器自动生成工具ANTLR的基础上,构建编译器的前端设计,通过关键技术的研究,解决了ANTLR作为编译器前端设计的若干关键技术问题。本文创新点:以ANTLR作为工具分析编译器的构造,解决了相关技术问题;在语法分析过程中以Java语言作为目标语言,该设计操作简单,具有良好的扩展性和实用性。
[1]Alfred V Aho,Monica S Lam,Ravi Sethi,et al.Compilers:Principles,Techniques,and Tools[M].2nd Edition.Lodon:Pearson Education,Inc,2006.
[2]Lars Marius Garshol.BNF and EBNF:What are they and how do they work[OL].http://www.garshol.priv.no/download/text/bnf.html,2008-08-22.
[3]Terence Parr.ANTLR history[OL].http://www.antlr.org/history.html,2012-11-15.
[4]刘三献.基于ANTLR的Gaussian词法分析器和语法分析器的分析与设计[D].兰州:兰州大学,2009.10-15.
[5]黄华.多领域统一建模语言分析器研究与实现[D].武汉:华中科技大学,2005.20-25.
[6]潘旭,康慕宁.基于ANTLR的试卷识别和导入系统的研究[J].电子设计工程,2011,19(7):45-49.
