快速散列算法在智能移动代理中的应用
2013-11-26张小琴王晓辉
张小琴,王晓辉
(中南民族大学 图书馆,武汉430074)
在信息检索过程中,移动代理中的URL队列是最关键的数据结构,一般采用内存数据结构,如:采用链表来实现URL队列.而对于大规模的搜索引擎,将会有数十亿的URL待抓取,这种数据结构不能满足要求[1].于是,人们提出了使用内存数据库的方法存储URL,Berkeley DB[2]是应用较广的一种嵌入式数据库.在Berkeley DB嵌入式数据库中,将URL对应到同一个Key值的队列当中,这样会导致处理URL时,被放入到同一个线程中处理.那么,对于大大小小不同的站点会有很多不同的队列,大门户网站形成的队列会非常臃肿,而且多线程处理器不能充分发挥作用,使得线程池中大多数线程处于等待状态,而影响移动代理抓取速度[3].
针对上述问题,本文以 Heritrix[4,5]为架构,结合Berkeley DB嵌入式数据库,引入散列算法改进队列存储URL方式,将URL尽可能多地散列到不同的队列当中,即对应不同的Key值,使多线程处理器充分发挥其功能.
1 Heritrix与Berkeley DB连接实现
为了实现所需的抓取逻辑,在现有的Heritrix框架基础上对各个组件进行扩展.Heritrix的主要组织结构为:(1)抓取任务CrawlOrder类:该类是整个抓取工作的起点.一次抓取任务包括许多属性,建立一个任务的方式有很多种.(2)中央控制器 Crawl-Controller:该类决定抓取任务的开始和结束.Crawl-Controller的类结构如图 1 所示[6].(3)Frontier:一次抓取任务需要设定一个Frontier,以此来不断为其每个线程提供URL.Frontier类,是移动代理的核心类,为多线程处理提供链接.Heritrix采用多线程机制,提供了一个标准的线程池ToePool,用于管理所有的抓取线程.
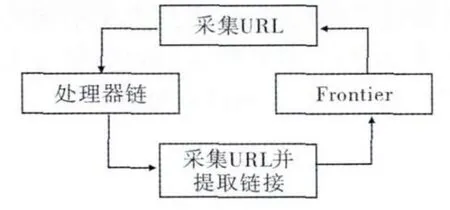
图1 Crawl-Controller的类结构Fig.1 Structure of Crawl-Controller
从Heritrix架构可以看到,一个链接在被处理之后,会得到新生成的链接,这些新链接被Frontier类中的schedule方法调用,将其加入到URL队列进行后续处理.但在进入队列之前,要在已经生成的一张HashMap中进行检查,查看该条链接是否已经被处理器链处理过.
Berkeley DB可以有效解决URL队列中的存放问题,Berkeley DB的事务子系统能够完成事务支持.对Berkeley DB的所有操作都是通过API接口函数完成.为了使用该数据库,在Heritrix中构造如下关键类:
1)BdbMutipleWorkQueues;
2)BdbWorkQueue;
3)BdbUriUniqFilter;
4)BdbFrontier.
这4个类中,前两个配合完成URL队列排队工作,后两者完成对等待进队的URL查重工作.移动代理利用上述4个类完成链接的处理工作,再经过URL处理链,实现一个移动代理完成捕获URL的全过程.
Heritrix使用Berkeley DB进行链接队列的构建,链接队列在进入BdbMultipleWorkQueue之前,赋予一个Key值,对应的链接和Key值捆绑之后成为一个队列.那么Key值作为链接队列的标识,它和URL之间存在一种必然内在联系.
为了克服Heritrix中的Key值策略存在的效率低缺陷,本文提出了一种基于散列算法的Key赋值策略,即通过把所有URL进入不同的队列,用字符串长短去转化Key值,这样不同长度URL的Key值不同.
2 散列算法在移动代理中实现
2.1 字符串散列函数
散列算法主要采用的是面对字符串的散列,通过散列算法将某一长度的字符串转换成散列值输出,这样的转换是一种压缩映射,可以大大减少URL在队列中等待的时间.对字符串的散列是根据其长度进行转换,不同的URL链接可能会由于长度相同得到同一Key值.按照散列函数Key=F(X),其中F()是单向的散列函数,X是任意长度的字符串链接,以二进制的形式存储在计算机中,Key是经过散列函数计算后得到的散列值[7].散列过程如图2所示.
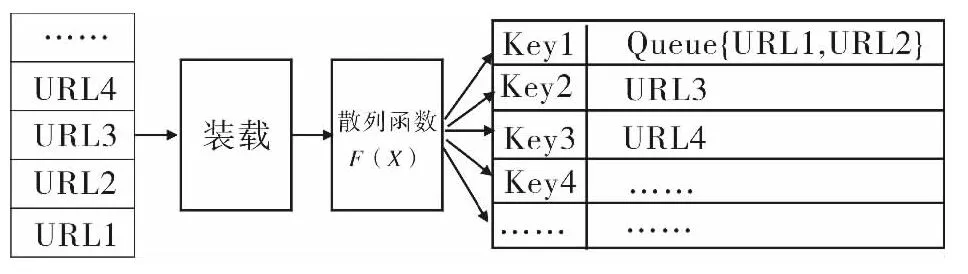
图2 散列过程示意图Fig.2 Process of hashing
图2直观反映了对URL的散列过程,对于字符字节长度相同的URL,经过散列函数的计算之后得到相同的Key值,会出现在一个队列中,不同长度的Key值不一样,形成一一对应关系.这样形成的数据访问结构,通过散列之后,数据会被快速定位.考虑到既要满足数据存储的速度,又要减少散列函数本身会造成的数据冲突,需要一种具有负载均衡效果好的散列函数.经典的散列函数有:ELFHash函数、BKDRHash函数和 SDBMHash函数.其中,BKDRHash带有种子因子的散列函数,其执行效率更高.因此,本文在改进移动代理队列时,采用BKDRHash 函数对字符串进行散列[8,9].
2.2 散列过程
通过改写QueueAssignmentPolicy类,并将其中的getClassKey()方法覆盖,这个方法的需求参数是一个链接字符串对象,而字符串散列函数正好就是根据链接对象返回一个值.实现流程如图3所示.
具体实现过程为:在移动代理的链接制造工厂类中,新建一个BKDRHashQueueAssignPolicy类,这个类继承自QueueAssignmentPolicy类,将改写的散列函数的参数返回值指向getClassKey的目的地址,之后在AbstractFrontier类中将该策略的方法加入一条 BKDRHashQueueAssignPolicy.class.getName()方法;最后在Heritrix的属性配置中设置,添加该条策略,使其生效.

图3 散列函数实现流程Fig.3 Hash function processing flow
3 系统测试及评估
3.1 测试环境
本文是在JAVA平台Eclipse 3.3上进行设计开发,软件环境包括 Windows XP SP3,开发工具Eclipse和Tomcat,性能比较开发工具Jfree.
移动代理启动之前,进行移动代理抓取参数的设置,在Heritrix抓取网页时,通过这些属性域控制移动代理.在Jobs选项卡中,设置移动代理抓取的种子集合,选取了国内5个知名度和访问流量比较高的网站作为测试对象.在Seeds表中输入http://www.sina.com.cn/、http://www.sohu.com/、http://www.163.com/、http://www.qq.com/ 、http://www.xinhuanet.com/五大门户网站的地址.
对Max-Byte-Download设置为0,即对抓取速度不作限制,Max-Toe-Thread设置为1000,在 Version项中需要替换为Heritrix当前的版本信息,其它的选项都保持默认.
3.2 实验结果与分析
在移动代理完成任务之后,本文对Logs选项中数据进行分析,Logs表中记录了非常丰富的数据信息,crawler.log 记录了时间、状态码等.prigress.log报表记录每一条抓取的时间、存在的队列、下载的速度、每秒钟抓取的链接数,以及抓取的最大深度等等信息.在Totals栏中记录了移动代理当前运行的负载情况,并统计了队列的长度和线程数量等信息.
本文通过大量实验取平均值的方法,对改进前后的移动代理的性能进行统计分析.在每次任务完成后,统计Logs表中的数据,然后清洗本次的抓取记录,重新设置抓取参数,启动任务,反复进行移动代理速度的数据统计,去掉差异化较大的数据,将剩余数据计算得出平均值,在得到大量平均的数据之后对结果进行对比分析.图4表示的是改进前后的移动代理队列在单位时间内对URL的抓取速度.

图4 抓取URL的速度比较Fig.4 Comparison of snatching URL rate
从图4可以看出,在移动代理对处理的初级阶段,性能并没有得到明显的提升,在经过一段URL进队之后,队列中的URL越来越多,这个时间点之后,添加散列算法的移动代理的性能开始明显提升.直到对队列所有的数据处理完成之后,速度再次回到零,完成一次完整的抓取任务.
本文又从移动代理的活跃线程数方面进行数据的对比分析,移动代理Heritrix在默认情况下,采取了HostPolicy策略,这样的结果导致移动代理在处理一个主站点下的URL时,只有单个线程工作,更多的线程都处于等待状态,并不能充分发挥多线程处理器的优势,移动代理抓取性能低下.图5是对添加散列算法前后,移动代理在实际运行中活跃线程数的统计.
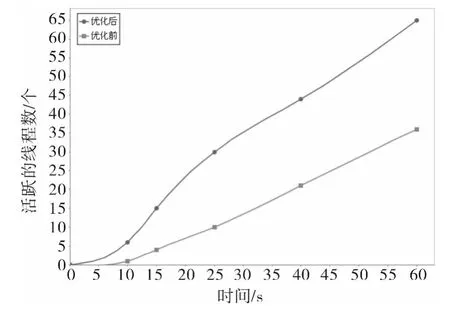
图5 活跃线程数比较Fig.5 Comparison of activity thread number
最后,在相同时间点对改进前后下载速度进行统计、分析,数据对比如图6所示.
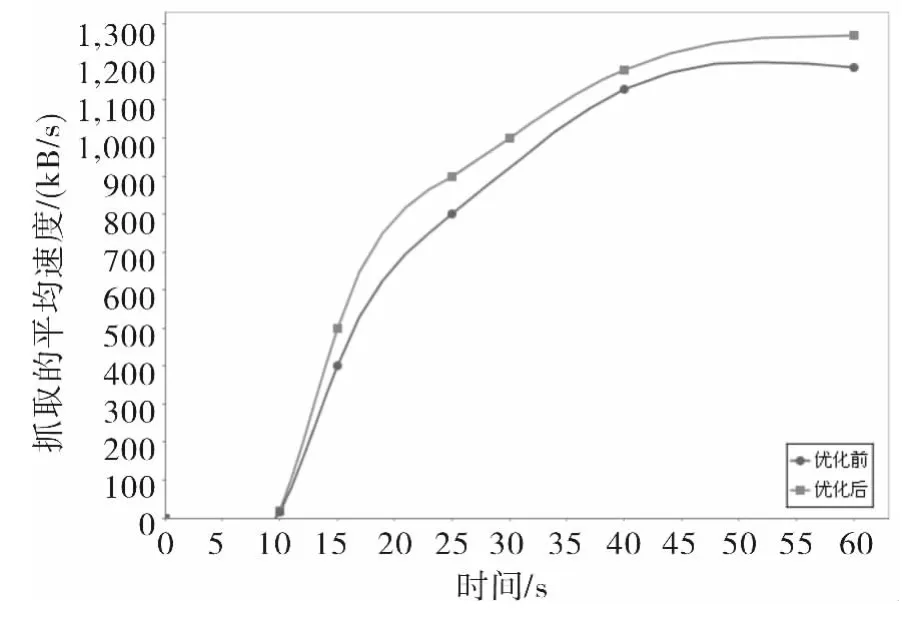
图6 下载速度比较Fig.6 Comparison of download speed
从图6可以看出,移动代理在抓取任务的初始阶段,处理速度并不明显,这一阶段是移动代理在对种子集合的分析定位,找到相应的资源站点,而在获取相应的资源之后,速度开始上升,由于加入散列算法之后的移动代理在处理URL方面更有优势,所以在整体的下载速度上更优.
4 结语
本文运用散列算法对Heritrix的队列处理机制进行了改进,通过大量实验分析可以看出,改进后的移动代理在抓取URL的平均速度、活跃线程数和整体的下载速度等方面都表现出了更好的性能,并适应于同一域名的主站点和不同域名的主站点.
[1]Sivasubramanian S,Pierre G,van Steen M,et al.Analysis of caching and replication strategies for Web applications[J].IEEE Internet Computing,2007,11(1):60-66.
[2]Ye Dan,Wang Yiming.Distributed processing of mass cognitive information based on cognitive engine framework[C]//BMEI.International Conference on BioMedical Engineering and Informatics.Guangzhou:IEEE,2012:1446-1450.
[3]Belkin N J.Grand challenges for information retrieval[J].SIGIR Forum,2008,42(1):47-54.
[4]张俊林.搜索引擎核心技术详解[M].北京:电子工业出版社,2012.
[5]Chen Jianxia,Wu Wei,Wang Chunzhi.A mobile phone information search engine based on Heritrix and Lucene[C]//ICCSE.The 7th International Conference on Computer Science & Education.Melbourne:IEEE,2012:1602-1604.
[6]李 刚,宋 伟.征服Ajax+Lucene构建搜索引擎[M].北京:人民邮电出版社,2006.
[7]Shen Haiying,Li Ze.A scalable and mobility-resilient data search system forlarge-scale mobile wireless networks[J].IEEE Transactionson Paralleland Distributed Systems,2013,24(6):1-11.
[8]邱 哲,符滔滔.开发自己的搜索引擎——Lucene 2.0+Heritrix[M].北京:人民邮电出版社,2010.
[9]Wu Guanlong,Kuo Yinshi.Scalable mobile video retrieval with sparse projection learning and Pseudo label mining[J].IEEE Multimedia,2013,20(7):1-12.
