基于SPCE061A的实时语音识别门禁系统设计
2013-11-10刘诚杰
邵 晨,刘诚杰,邓 琛
(上海工程技术大学 电子电气工程学院,上海201620)
随着社会的发展,无论在企业还是民宅中,人们对门禁系统的使用越来越广泛。然而传统门禁无法满足各种使用场合的复杂性和智能性,于是综合应用语音识别、指纹识别、虹膜识别、红外感应等最新生物识别技术的门禁系统广泛吸引了人们的注意,并将逐步成为门禁系统发展的主流与趋势[1]。
本文提出了基于高性价比的凌阳SPCE061A单片机,以16位的μ′nSP为主控芯片,通过添加部分外围元件,即可搭建一个经济的、功能相对完善的智能实时语音门禁系统。该系统具有成本低、功耗低等优点,是一种安全有效、有市场价值的门禁系统解决方案。
1 语音识别的基本原理
语音识别技术就是对不同说话人的不同说话内容进行准确的识别,其本质是属于模式识别的范畴。系统原理框图如图1所示。从图中可以看出,识别结果的正确与否与模式匹配息息相关。计算机首先从特定人处取得语音信号并训练制作成语音的特征模型库。当系统需要进行语音识别时,对新输入的语音信号进行分析,抽取其语音特征参数。通过与语音系统中所储存的特征模型进行对比,在一些特定的搜索和匹配策略下寻找最优的匹配模板。通过查表系统就能给出语音识别的结果。其主要步骤分为:预处理、特征参数提取、语音的训练与识别。

图1 语音识别系统原理框图
在进行语音的预处理以及特征参数的提取之后,就要运用某种识别方法辨识出测试的说话人,说话人识别算法部分是整个说话人识别处理流程中最核心的一环,直接决定着系统的识别性能[2]。主要任务是将预处理后的所有需要辨识的语音信号进行特征参数的提取,经过训练形成参考模板库,然后将某个特定的需要识别的说话人的语音以同样的方法得到其测试模板,最后用此模板与库中的模板进行模式匹配,以达到识别的目的。常用的识别算法有矢量量化 VQ(Vector Quantization)、动态时间规整法 DTW(Dynamic Time Warping)、隐马可夫模型 HMM(Hidden Markov Model)和人工神经网络ANN(Artificial Neural Networks)等[3]。
2 语音门禁系统硬件设计
图2为系统总体的硬件设计框图,系统主控制模块以凌阳SPCE061A单片机为核心部件,麦克风输入模块采集语音声波信号转换为模拟电压信号,采样调理电路对电信号进行滤波,去除噪声干扰。通过单片机自带的AD采集模块实现对说话人识别确认的功能。输出部分采用两路输出的形式。一路输出为扬声器模块,可以语音播报识别的结果信息;另一路输出为电子门锁驱动模块,驱动门锁的开合。

图2 硬件结构框图
凌阳SPCE061A单片机内部含有语音识别相关的函数,通过代码的编写,能够完成语音录制、语音采集、语音播放以及语音识别等任务。本系统在使用时可无需任何按键,在任意时刻录入口令,口令不匹配时,扬声器返回报错信息;口令匹配时,扬声器返回正确信息,门锁开启。
3 系统软件设计
3.1 识别算法与优化
常见的语音识别算法有 HMM、VQ、DTW等[4]。由于本项目只针对短时语音(语音长度1.3 s),经过比对分析,决定采用动态规整(Dynamic Time Wrapping)算法[5]进行语音模板的匹配,这是因为DTW算法简单、计算量小,特别适用于特定人孤立词的短时语音识别。
DTW是将时间规整和距离测度计算结合起来的一种非线性规整技术[6]:
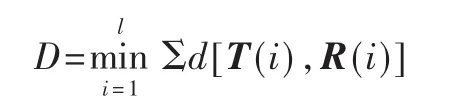
其中,D为处于最优时间规整情况下两矢量的距离;d[T(i),R(i)]是第 i帧测试矢量 T(i)和第 j帧模板矢量R(j)之间的距离测试。
由于传统固定端点的DTW算法对语音起始点和终止点的判断会存在较大的误差,所以需要对原算法作适当的优化来解决这个问题。模板语音的所有帧和待识别语音的所有帧之间的相互距离构成一个m×n的距离矩阵,记为 Dm×n,而另有一个矩阵存放每一个阶段最优化的结果,记为 Gm×n。 改进后的 DTW 算法以 g(m×n)为两发音的总距离。放宽了端点对其限制后,算法选用d(1,i)和d(i,1)(1≤i≤w)中的最小值作为起点。在 d(m,i)、d(i,1)(n-w≤i≤n)和 g(j,n)(m-w≤j≤m)之间选一个最小值作为总距离,实现了起始点和终止点的变化。从而减小说话人不同时期发音长短、语速变化对识别精度带来的影响[7]。
3.2 软件流程
本系统软件的开发使用了凌阳公司的μ′nSP IDE集成开发平台,这个高效的开发环境支持汇编与C语言的混合编写,还支持编译、链接等功能,集成了调试和实时分析等实用功能,为开发提供了便利。
语音识别门禁系统的软件总体流程如图3所示。本程序分为3个模块,分别为中断模块、训练模块和识别模块。

图3 语音识别门禁系统流程图
首先获取语音信息,经过模数转换、预加重、自动增益等处理后根据中断类别进入训练或者识别模块。训练模块将经过处理的语音信号通过特征提取,存入语音特征模型库。而识别模块通过改进识别算法将输入语音信号的特征与训练后语音特征模型库进行对比分析。
4 试验结果与结论
本文实现的基于SPCE061A的实时语音识别门禁系统具有识别特定人条件下短时语音的功能。样机经过测试,对特定人进行语音采样和辨识训练后,对100次语音输入访问测试,正确通过为93次,识别率达到93%;样本有效但拒绝访问请求7次,拒识率为7%,达到了预期的设计要求。
[1]黎育红.基于语音识别技术的门禁系统的研究[J].电子技术应用,2006,32(12):88-91.
[2]赵力.语音信号处理[M].北京:机械工业出版社,2005.
[3]胡文静.基于SPCE061A语音识别门禁系统实现的研究[J].计算技术与自动化,2011,30(2):111-114.
[4]宋大杰.基于DTW的说话人识别及其在DSP上的实现[D].江西:东华理工大学,2012.
[5]蒋晔.基于短语音和信道变化的说话人识别研究[D].江苏:南京理工大学,2013.
[6]白瑜.语音信号特征参数的提取[J].科技传播,2011,12(24):228-229.
[7]姚烨豪.基于语音识别和RFID技术的智能门禁系统研究[J].科技信息,2012(2):31-32.
