大数据处理中非均匀存储访问技术研究
2013-09-30郭晓梅
郭晓梅
[摘要]目前,大数据的高性能处理日益重要,本文通过实验,对非均匀存储访问的各种情况进行了详细深入的研究,对访问时间差别进行了深入的分析,揭示了在非均匀存储访问系统中线程本地存储访问和远程存储访问的性能差异。发现了读写内存、不同访问距离等各种情况下线程内存访问的性能特点。得出了在线程调度中的重要结论,对应用程序在进行大数据处理的线程调度执行提出了重要的建议。
[关键词]大数据;非均匀存储访问;线程调度
[中图分类号]C37 [文献标识码]A [文章编号]1672-5158(2013)06-0031-02
引言
在当今时代,互联网迅猛发展,各行各业数据量猛增。数据种类繁多,数据量巨大,大数据时代来临。随着大数据的来临,大数据处理成为越来越有价值的工作,而大数据的高性能处理则至关重要。
目前大数据处理大都采用多处理器系统,而多处理器系统中的非均匀存储访问架构为进行大数据高性能处理的主流体系结构之一。
1 非均匀存储访问技术特点
1.1 多处理器系统模式
在多处理器系统中,比较流行的有三种模式,即对称多处理模式、大规模并行处理模式、非均匀存储访问模式。对称多处理模式是在一个主存上连接着两个或两个以上的处理器,这些处理器共享一个主存,也被称为均匀性存储访问系统。大规模并行处理模式是分布式存储器模式,可扩展性比较好,但是需要并行编程和并行编译,在软件系统构建上比较复杂,使用不便。非均匀存储访问架构是将若干个单元通过专门的互联设备联结在一起组成分布式和共享内存系统。每一个处理器可以访问自己单元的存储器,也可以访问其他单元的存储器,所有访存有远近、时延长短之分,称为非均匀存储访问。
1.2 非均匀存储访问架构的性能优势
非均匀存储访问架构的性能优势主要体现在以下几个方面:第一,非均匀存储访问处理器访问同一单元上的内存的速度比一般对称多处理模式超出一倍。第二,非均匀存储访问的突破性技术彻底摆脱了传统的超大总线对多处理结构的束缚,它大大增强单一操作系统可管理的处理器、内存和I/O插槽。最后,非均匀存储访问系统提供内存互联的硬件结构,这种技术可以开发新型动态的分区系统。系统分区可以允许系统管理员根据用户工作负荷的要求,简单地管理和使用CPU和内存资源,从而达到最高的资源利用率和最佳的性能。正因为以上的原因,非均匀存储访问架构得到越来越广泛的应用。
2 非均匀存储访问技术线程访问时间研究
非均匀存储访问系统的基本特征是具有多个CPU模块,每个CPU模块由多个核(如6个)组成,并且具有独立的本地内存、I/O槽口等。由于其节点之间可以通过互联模块进行连接和信息交互,因此每个CPU可以访问整个系统的内存。但是线程访问远近程存储器的时间是不一样的。
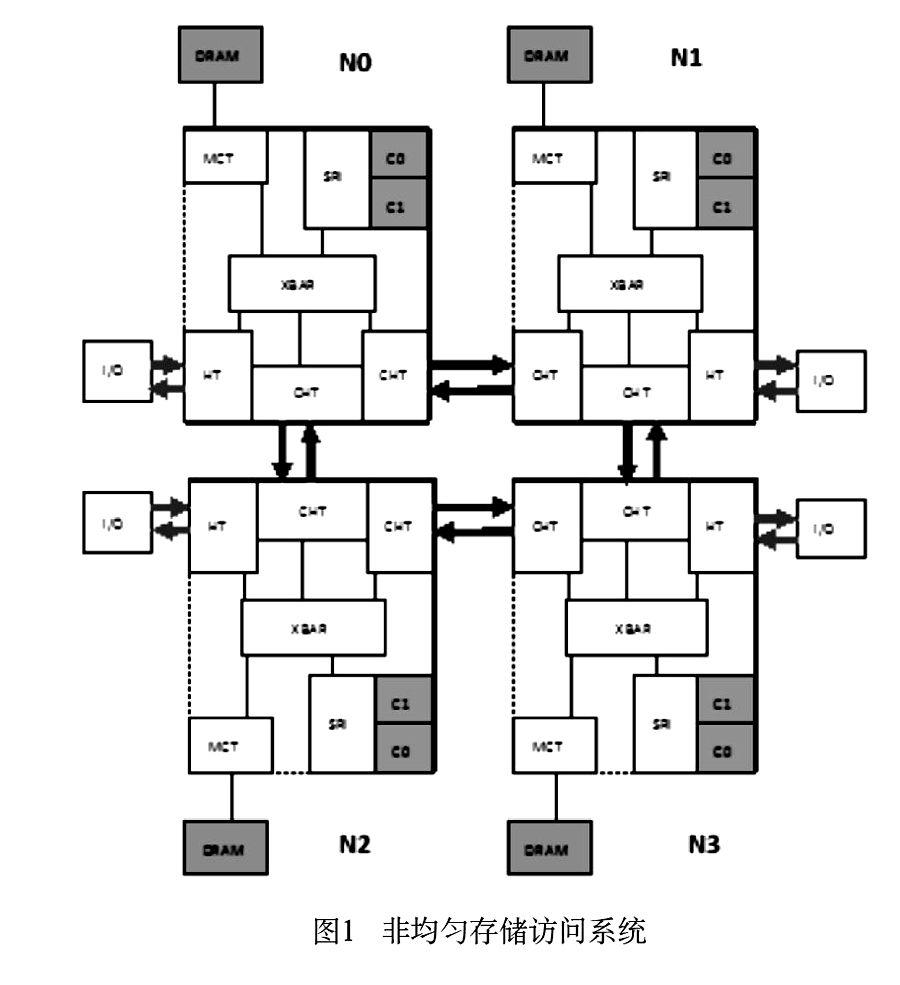
我们使用的非均匀存储访问系统是四个主频为2.2GHZ的双核AMD opteron多处理器,每个处理器有2x1GB DDR400 DRAM内存。如(图1)所示。四个处理器由coherent HyperTransport(相关性超传输)总线连接,每个处理器有一条双向HyperTransport(超传输)总线和I/O连接,两条双向相关性超传输总线分别和另外两个双核处理器连接。每个双向超传输总线的数据传输带宽为4 GB/s。系统有4个节点NO,N1,N2,N3。每个节点有自己的内存控制器(MCT),连接着本节点的内存。每个节点有2个核CO,c1,两个核连接着一个系统需求接口(sRI),系统中间有一个交叉设备XBar,SRI、内存控制器、各种各样的超传输总线都和XBar连接。
在非均匀存储访问系统中,内存需要可以来自于本节点的核,也可以通过超传输总线来自于其它节点的核。前者叫做本地访问,对内存的访问要求从核到SRI,到XBAR,再到MCT;后者叫做远程访问,内存访问要求的路线是从远程节点的核通过超传输总线到达XBAR,从XBAR再到MCT。每个节点的SRI、XBAR、MCT都有缓冲区,缓冲区用来存放需要传送的数据包。
在非均匀存储访问系统里,影响应用程序处理大数据的性能主要有以下几个方面:
①远程内存访问。处理器访问远程存储器的次数多少会直接影响一个应用程序的性能。提高非均匀存储访问系统性能的策略之一就是减少远程访问的次数。要尽可能地让进程在本节点执行。
②相互连接的超传输总线带宽的影响。
③内存竞争的影响。当许多处理器在同一时刻访问一个内存单元的时候就会出现内存竞争,内存竞争会增加内存响应时间,降低程序的执行效率。恰当的数据分配策略会减少内存竞争。
④内存带宽的影响。
⑤缓冲区影响。在非均匀存储访问多处理器系统中,缓冲区在性能上发挥着重要的作用。如果处理器在本地缓冲区中没有找到需要的数据,就会访问远程的存储器。
⑥系统中各种各样缓冲区可容纳缓冲队列长度的影响。
2.1 远近程内存访问的时间差别
线程本地存储器访问和远程存储器访问时间究竟有多大的差别呢?我们先用一个例子来研究远近程内存访问的时间差别。
我们得到处理器所记录的当前时间的方法是使用时钟周期数TSC的值乘以CPU的时钟周期cycle来得到。就是在每次处理器启动的时候把TSC的值清零,然后每个时钟周期TSC的值都加1,这样要得到代码执行的周期数就在一段固定代码执行前后分别读取TSC的值即可。用下列公式可以计算代码执行时间:
T=(TSC1-TSC2)·cycle
当线程运行和访问内存都在同一个节点时,就叫做本地访问或0-跳访问。当线程运行在一个节点,访问内存却在其他节点,就叫做远程访问。在远程访问中,如果线程运行的节点和内存访问的节点是彼此直接连接的,就叫做1-跳访问。如果线程运行的节点和内存访问的节点不是直接连接的,就叫做2-跳访问。如图1中,线程在节点0运行,则其对于节点1、2、3的访问即为远程存储器访问,对节点1、2的内存访问叫做1-跳访问,对节点3的内存访问叫做2-跳访问。
我们采取了一段串行程序使用一个线程向不同节点存储区域写入5M相同大小数据量的方法来测试访问的时间,并且,每次实验我们重复了2000次。统计结果表明,本地存储区域的访问时间是最短的,平均为2166μs;而对于远程存储区域的访问则需要较长的时间,其中1、2节点的访问时间平均达2445μs,而节点3,访问距离最远,访问时间也最长,平均达3032μS。
由此实验可见,在非均匀存储访问系统中,访问远程内存的速度要慢于访问本地内存的速度。在本例中,1-跳距离的存储访问时间是本地存储访问的1.13倍,2-跳距离的存储访问时间是本地存储访问的1.4倍。访问远程数据的距离越远,付出的时间代价越高。我们在应用程序中,尽量保持数据在节点内部访问。
2.2 单线程只读和只写远近程存储器的研究
如果对内存的访问为只读或只写,本地访问和远程访问时间有什么差别呢?我们用下面的例子来研究只读和只写访问远近程存储器的影响。
我们采取一段串行程序使用一个线程向不同节点存储区域分别连续读出和写入60M相同大小数据量,读写入的大小要远远大于缓冲区大小。线程运行在节点O的C0上。并且整个系统只有这一个线程运行。线程的数据访问分为以下几种:
*线程本地访问节点0内存。(0-跳)
*线程远程访问节点1内存。(1-跳)
*线程远程访问节点2内存。(1-跳)
*线程远程访问节点3内存。(2-跳)
访问时间结果表明,随着访问距离的增加,读写访问的访问时间都增加了。每种情况,写访问的时间都大于读访问的时间,因为写操作会生产出更多的内存带宽负载。但是读写访问的访问时间都随着访问内存距离的增加而增加。
2.3 节点间和节点内线程调度访问研究
如果是多线程,通过节点调度多线程有以下几个制约因素:
*系统是否空闲,也就是系统有没有其它负载;
*多线程是否访问各自私有的数据。
*多线程是否访问共享的数据。
我们先来研究系统空闲下线程只访问本节点私有的数据。
我们使用2个线程进行写操作,每个线程都写)260M的数据,都访问本节点的内存。第一种方法是节点间调度,即一个线程在节点0的核0运行,另一个线程在节点1的核0运行;第二种方法是节点内调度,即2个线程分别在节点0的核0和核1上运行。比较两个线程运行的总时间。结果表明,节点间调度线程的执行时间比较少。
随后我们又使用8-CPU非均匀存储访问系统工作站(AMDOpteron 6168 1.9GHz processor,64G RAM,48 core,8节点,每个节点6个核)实验环境,使用6个线程进行写操作。都访问本节点内存,分上述两种情况,即第一种方法是节点间调度,每个线程分别在6个节点的核0运行,第二种方法是节点内调度,6个线程都在节点0的每个核运行。结果为,第一种情况执行时间比较少。
在非均匀存储访问系统中,在空闲执行环境下访问私有的数据,我们应尽量避免使用第二种情况来调度线程。从负载平衡的角度来说,如果某一个节点负载过多,而其他节点空闲,必然会导致一个节点内的资源产生竞争,从而影响应用程序的执行效率。
如果在空闲执行环境下,各线程之间的数据共享,我们使用2个线程和6个线程在2种环境下分别进行了测试。线程都访问本节点内存,第一种方法是节点间调度,一个线程在节点0的核0运行,另一个线程在节点1的核0运行;第二种方法是节点内调度,2个线程分别在节点0的核0和核1上运行。6个线程写60M数据的两种方法,第一种方法是节点间调度,每个线程分别在6个节点的核0运行,第二种方法是节点内调度,6个线程都在节点0的每个核运行。结果表明,在节点内调度线程的执行时间比较少。因为各线程之间数据共享,访问内存数据的距离越短,时间越少。所以我们在空闲环境下进行线程调度,各线程间数据共享,优先从节点内进行调度,一个节点调度为完毕,再从另一个节点进行调度。
对于上述实验,我们在系统有少量负载的情况下也做了相应的实验,取得了类似的结果。
由此可知,在非均匀存储访问系统中,在系统空闲的情况下,或者少量负载的情况下,对应用程序进行大数据处理提出如下建议:
*如果线程仅访问本节点私有的数据,优先从节点间调度线程;
*如果线程间数据共享,优先从节点内调度线程,一个节点饱和后再从另一个节点进行调度;
*如果线程需要访问的既有独立数据又有共享数据,但私有数据远远大于共享数据,优先从节点间调度线程。
3 结束语
当今,在互联网及各行各业都存在着大量数据需要高性能处理,本文通过实验对非均匀存储访问技术进行研究,发现了读写内存、不同访问距离等各种情况下线程内存访问的性能特点。得出了应用程序在线程调度中的重要结论,对大数据的高性能处理有重要的指导意义。
参考文献
[1]都志辉,高性能计算并行编程技术-MPI并行程序设计,清华大学出版社,2001
[2]郭静,祝永志,王延玲,基于MPI的动态负载平衡算法的研究[J]计算机技术与发展,2009(05)
