基于网格的违规行为事件责任认定研究
2013-09-30张尚韬
张尚韬
(福建信息职业技术学院,福建福州350003)
网格[1]是由很多计算机组成的一个集成的计算与资源环境,或者说是一个计算资源池,它能够充分吸纳各种计算资源,并将其转化成一种随处可得的、标准的、可靠的和经济的计算能力,从而实现资源的全面连通.同时,可以把这个计算资源池形象地比作一个虚拟的超级计算机,让资源池内的所有计算机共同完成同一个任务.
违规行为事件的责任认定,传统手段是通过查阅系统操作日志、应用程序的操作日志、调用数据库的操作日志、审计其他设备的操作日志来反映正常操作行为和违规操作行为的责任认定问题.本文中涉及的违规行为事件责任认定主要是对网格环境中的违规行为,而这些违规行为主要记录在网格系统的日志文件中,但由于各种操作系统日志、Web服务器日志、数据库日志、主机性能数据和SNMP(Simple Network Management Protocol,简单网络管理协议)日志数量巨大,并且对于不同的协议将记录不同的信息,所以在很大程度上,这些分散的、凌乱的信息在工作中很难被有效地用来进行责任认定,也一直是整个信息安全建设中的一个软肋.因此,在对日志数据库中的日志信息进行违规事件责任认定之前,必须对日志信息进行相关的处理,生成适于事件责任认定的形式.
1 日志数据处理
日志文件通常包括:用户名、IP地址、请求的日期时间、事件ID、访问结果(成功、失败或错误)、客户浏览器类型/操作系统和文件大小等.日志数据处理就是对日志数据进行清理、过滤以及重新组合的过程.其目的是去除日志中对挖掘过程无用的属性及数据,并将日志数据转化为适合于违规行为事件责任认定的、可靠的、精确的数据.处理过程主要包括如下几个方面:
1)数据转换 将不同数据源的原始日志文件导入日志数据库;
2)数据精简 删除日志中与数据挖掘不相关的冗余项;
3)用户识别 将用户与操作行为相关联.
归纳常见日志文件格式,数据处理后的日志格式如表1所示.

表1 数据处理后的日志文件格式
表1中,日期、时间项记录了操作的准确时间,用户项记录了操作的主体,IP地址项记录了操作主机使用的IP地址,事件ID项记录了操作的内容(例如,表1中129表明报表服务器无法解密已加密的配置文件设置;681表明有人用未知的用户名进行了域登录尝试,或者用已知的用户名进行了登录域,但密码不正确;685表示账户名更改),类型项记录了该日志信息的类别(信息、警告、错误),备注项是可选项,用于对记录的日志进行补充说明(例如,在记录电子邮件日志时,可以在备注中表明目的IP地址、邮件主题等信息).
2 责任认定算法研究
对于网格环境中违规行为事件的责任认定,主要采用聚类分析算法对日志数据库中的日志信息进行聚类,然后运用关联规则算法,找出用户的正常/违规行为模式,将用户当前行为与正常/违规行为模式进行相似度比较,发现违规行为事件,进行责任认定.下面分别介绍2种算法.
2.1 日志聚类分析算法 聚类[2-3]是把整个数据库分成不同的群组,它要求群与群之间差别很明显,而同群之间的数据尽量相似.所谓类,通俗地说,就是指相似元素的集合.换句话说,如果将含有n个样本x1,x2,…,xn的数据集 X 聚集成 c个子类 X1,X2,…,Xc,则要求

聚类就是根据描述对象的属性值计算得出的相异度,将数据对象分组成为多个类或簇,在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大.聚类分析中用到的数据类型有:
1)数据矩阵[4-5]设有n个样品,每个样品测得p项指标(变量),原始资料矩阵为

其中,xij(i=1,…,n;j=1,…,p)为第i个样品的第j个指标的观测数据.第i个样品Xi为矩阵X的第i行所描述,所以任何2个样品Xk与Xi之间的相似性,可以通过矩阵X中的第k行与第i行的相似程度来刻画;任何2个变量xk与xi之间的相似性,可以通过第k列与第i列的相似程度来刻画.
2)相似性度量 对象间的相似性是基于对象间的距离来计算,最常用的距离度量方法是明氏(Minkowski)距离[6]、马氏(Mahalanobis)距离[7]、兰氏(Canberra)距离等.
3)相似系数 研究样品之间的关系,除了使用距离表示外,还有相似系数.顾名思义,相似系数是描写样品之间相似程度的量,常用的相似系数有夹角余弦和相关系数.
本文中对日志数据库中的日志信息进行聚类分析时采用的思路是:
给定一个有N条记录的数据集,将其构造成M个分组,每一个分组就代表一个聚类,M<N.而且这M个分组满足下列条件:
1)每一个分组至少包含一条数据纪录;
2)每一条数据纪录属于且仅属于一个分组;
3)对于给定的M,算法首先给出一个初始的分组方法,以后通过反复迭代的方法改变分组,使得每一次改进之后的分组方案都较前一次好.好的标准就是同一分组中的记录越近越好,而不同分组中的纪录越远越好,即各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开.
算法过程为:首先从日志数据库中选择M个有代表性的数据对象(访问模式、IP地址、用户名)作为初始聚类中心,而对于所剩下其他对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数(即迭代结果)开始收敛为止.
2.2 关联规则责任认定算法 关联规则[8-9]数据挖掘就是从大量的数据中挖掘出有价值的描述数据项之间相互联系的有关知识[10].关联规则相关定义为:
1)数据项与数据项集 设I={I1,I2,…,In}是n个不同项目的集合,Ik(k=1,…,n)称为数据项(I-tem),数据项的集合I称为数据项集(Item set),简称项集,其元素个数称为数据项集的长度,长度k的数据项集,简称k-项集(k-Item set).
2)事务 事务T(Transaction)是数据项集I上的一个子集,即T⊆I,每个事务均有一个惟一的标示符TID与之关联,那么二元组(TID,T)为数据库事务.一般情况下,简单表示为T,不同事物的全体构成了全体事务集D,即事务数据库.
3)关联规则 设I={I1,I2,…,In}是所有项的集合,D是一组事务集.D中的每个事务T是一个项的集合,并且满足T⊆I.如果项集合X⊆I且X⊆T,就称事务T包含X.则关联规则是下面形式的一种包含:X⇒Y,其中 X⊂I,Y⊂I,且 X∩Y= φ.
4)支持度 关联规则X⇒Y在事务集合D中成立,则具有支持度s,其中s是D中事务包含X∪Y的百分比,它等于D中同时包含X和Y的事务个数与D中包含X的事务个数之比,即概率P(X∪Y).

5)置信度 规则X⇒Y在事务D中的置信度c为D中包含X的事务个数与D中同时包含X和Y的事务个数之比,即条件概率P(X|Y).即

在关联规则R中,R=X⇒Y,R的支持度s,置信度c成立的条件是

6)频繁项集 如果项集U={u1,u2,…,um}出现的概率大于最小支持基数min_sup,即满足最小支持度阈值,则称它为频繁项集(Frequent Item set),频繁k-项集的集合通常记为Lk.
关联规则挖掘是数据挖掘最常用的方法,为了发现有意义的关联规则,需要给定2个阈值,分别是最小支持度和最小置信度,关联规则的目标是对给定的一个事务数据库D,求出所有满足最小支持度min_sup和最小置信度min_conf的关联规则.关联规则的查找可以分为以下步骤:
1)找出频繁项集 根据最小支持度min_sup,找出所有具有超出最小支持度的项集;
2)利用频繁项集找出所需的关联规则 由给定的最小置信度min_conf,在每个最大频繁项集中,寻找置信度不小于min_conf的关联规则.
本文中关联规则的提取是在聚类分析的基础上完成的,将经过聚类分析后产生的日志信息分组并进行关联规则提取,找出每一组中存在的关联规则,然后将发现的关联规则存入规则库中.以此,总结出用户正常行为模式/违规行为模式,同时,通过关联规则方法的处理,可以把发现的正常行为模式/违规行为模式转化成新的规则,并添加到规则库中,使得规则集合不断完善,如此将各种审计数据转换成规则集合中的新规则,既避免了人工设置新规则的繁琐和人为不确定因素,又避免了数据量过大对原始规则集合不完善性的冲击.此后,将当前行为模式与关联规则提取后生成的正常行为模式/违规行为模式进行相似度算法比较,便可以判断当前行为是否是违规行为,如果是违规行为事件就对其进行记录和跟踪,以作为责任认定的依据.
3 违规行为事件责任认定
本文提出了2种方法来对日志数据库中记录的信息进行违规事件责任认定,一是采用规则库的方法发现存在的违规行为事件,二是采用关联规则的方法发现潜在的违规行为事件.
3.1 已知违规行为事件责任认定 对于已知违规行为事件的责任认定采用基于规则库审计的方法.该方法需要知道违规行为的具体知识,将已知的违规行为进行特征提取,把这些特征用脚本语言等方法进行描述后放入规则库中.当进行责任认定时,将收集到的当前行为日志信息与这些规则进行某种比较和匹配(表达式、关键字等),如果与规则库中的规则一致,则可以判断出该行为为违规行为事件,从而发现违规行为,并对此违规行为事件进行记录和跟踪,为事后的责任认定进行取证.这种方法与某些杀毒软件、防火墙的技术思路相似,检测的准确率也相当高,可以通过简单的比较匹配方法过滤大量的不相关数据信息,但是其不足之处在于规则库中记录的规则一般只针对已知的违规行为,当出现新的违规行为时,容易产生漏报现象[11].
3.2 潜在违规行为事件责任认定 为了解决基于规则库的方法容易产生漏报现象的问题,笔者采用了基于关联规则的方法发现潜在的违规行为事件.该方法主要包括正常行为模式建立和违规行为事件判断2个过程.正常行为模式的建立要求一个“纯净”的网格环境,该环境中系统在不受任何违规行为攻击的情况下运行,以此对产生的“纯净”日志信息采用聚类分析和关联规则数据挖掘算法进行审计,提取正常行为特征,生成正常行为模式,然后将用户当前行为与正常行为模式采用相似度算法进行比较,如果偏差较大,则说明该行为具有违规的可能.
相似度算法采用加权的方式将当前行为模式与正常行为模式进行比较,加权的值设定在[0~1],如果两者比较的值越接近1,则说明2种行为模式越相似.与此同时,设定一个可以接受的相似度值,如果加权值超过该设定值,则认为该行为模式为正常行为,如果小于该值则认为该行为具有潜在违规可能.用表达式可以描述为

其中,CRj表示关联规则Rj的置信度.
采用关联规则和相似度算法将当前行为模式与正常行为模式进行对比,当结果超过设定范围的时候,就认为这些行为具有潜在的违规行为,这样既解决了对未知违规行为的判定,又避免了漏报问题的发生.
表2是日志数据库中的部分日志信息经过统一格式处理后,采用简单的明氏(Minkowski)距离聚类分析算法计算后生成的日志信息表格,其聚类中心是用户名xx,然后对其进行关联规则数据挖掘,生成关联规则,提取正常行为模式,并将当前行为模式与正常行为模式进行相似度比较,判断违规行为事件,进行责任认定.

表2 聚类分析后的部分日志信息
为了便于统计,将日期与时间项简化记录为A(08:00:00~12:00:00)、P(12:00:00~18:00:00)、E(18:00:00~08:00:00),因为只是统计上午、下午、晚上,所以日期省略;IP地址简化记录为P1(192.168.3.1)、P2(192.168.3.11),事件 ID项简化记录为 I1(528)、I2(530)、I3(540);备注项简化记录为 F(失败)、S(成功),则经过扫描产生候选集C1如下.

A P E P1 P2 I1 I2 I3F S 8 0 3 7 3 5 2 3 2 8
设最小支持度min_sup=20%,则产生候选集L1如下.

A E P1 P2 I1 I3S 8 3 7 3 5 3 8
同理,产生候选集L2,L3如下,其中S还是表示成功.

(A,P1) (A,I1) (A,I3) (A,S) (P1,I1) (P1,I3) (P1,S) (I1,S) (I3,S)7 4 3 7 5 3 7 5 3(A,P1,I1)(A,P1,I3)(A,P1,S)(A,I1,S)(A,I3,S)4 3 7 4 3
因为A表示(08:00:00~12:00:00)上午,P1表示(192.168.3.1),I3表示(540),S表示成功,因此由上表 (A,P1,I3),(A,P1,S)可以得出,支持度 s分别为 30% 和 70%,(A,P1,I3)产生如下关联规则

其中,支持度是说明该规则在所有事务中有多大的代表性,显然支持度越高,关联规则越重要.置信度是说明该规则的可信性,太低说明该规则不可信,太高说明存在普遍性.
例 有以下正常行为模式关联规则
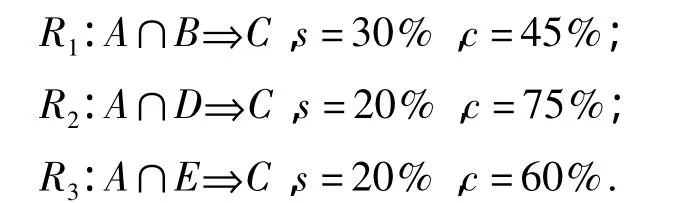
假设当前行为模式R4(R4=R1,当前行为R4是正常行为模式的一个子集):A∩B⇒C与正常行为模式的相似度为(0.45+0.75+0.60)/3=0.60,如果设定的最小相似度为0.5,则当前行为模式被认为是正常行为模式(0.6>0.5);如果设定的最小相似度为0.7,则当前行为模式就被认为是违规行为.
4 小结
对于确认的违规行为事件,笔者将依时间顺序回溯事件发生流程,重现事件过程,并以事件发生地点、事件以及行为主体的关联形式给出表格报告,并加以安全存储,以作证据进行责任认定.
[1]FOSTER I,KESSELMAN C.网格计算[M].金海,袁平鹏,石柯,译.北京:电子工业出版社,2004:1-20.
[2]张昭涛.数据挖掘聚类算法研究[D].成都:西南交通大学,2005.
[3]张磊.数据挖掘聚类算法研究与系统设计[D].成都:电子科技大学,2003.
[4]李强.基于支持向量机的文本分类方法研究[D].西安:西安科技大学,2009.
[5]平源.基于支持向量机的聚类及文本分类研究[D].北京:北京邮电大学,2012.
[6]黄林峰,罗文坚,王煦法.高维多目标进化算法中的密度评估策略研究[J].中国科学技术大学学报,2011(4):353-361.
[7]张君,薄华,王晓峰.基于改进谱聚类的合成孔径雷达溢油图像分割算法[J].上海海事大学学报,2011(3):68-73.
[8]马强.关联规则挖掘算法研究和应用[D].太原:太原理工大学,2004.
[9]孙金华.基于关联规则的Web日志数据挖掘研究与实现[D].南昌:南昌大学,2007.
[10]IBM Corp.International Technical Support Organization Introduction to Grid Computing with Globus[S].2003:131 -145.
[11]NAGGER R.Windows NT File System Internals:A Developer’s Guide[M].1st ed.[S.l.]:O'Reilly,1997,9:123 -165.
