成像声纳中基于SOPC的以太网高速数据传输设计※*
2013-09-21王静娇周建江何航峰黄慧杨成
王静娇,周建江,何航峰,黄慧,杨成
(南京航空航天大学 电子信息工程学院,南京 210016)
引 言
成像声纳具有作用距离远、图像直观显示观测区域状况和识别目标[1]等特点,提高分辨率是提高水下声纳成像质量的关键,而高分辨率也带来了数据传输量大、传输速率要求高的问题。
传统声纳数据传输模块通常采用百兆网卡,实现百兆以太网传输[2-4],面对日益趋大的数据量,该方法已经无法满足需求。为了适应更高的成像分辨率,满足大数据量的高速传输,本文基于Xilinx公司的SOPC架构,片上集成了千兆以太网控制器,无须外加专用的以太网控制芯片;移植VxWorks操作系统,采用TCP/IP协议与显示控制端通信。设计的数据传输系统,经测试得到了247Mbps的数据传输速率。
1 成像声纳数据传输系统总体设计
本文成像声纳指标:量程4~100m,波束数512,量程分辨率5cm,最高帧率15Hz,通信接口为以太网接口。
成像声纳中整个工作流程如图1所示,本文主要研究数据传输模块。数据传输的目的是实现从水下设备把大量的声纳成像数据通过以太网发送到干端计算机进行成像显示。当探测量程为100m时,帧率为7.5Hz,数据输入速率为7.68MB/s,所以要求网络传输速度能达到61.44Mbps。为了保证网络速度尽可能高,确保每帧接收到的图像都能传送出去,本文以2倍网速120Mbps为开发目标。
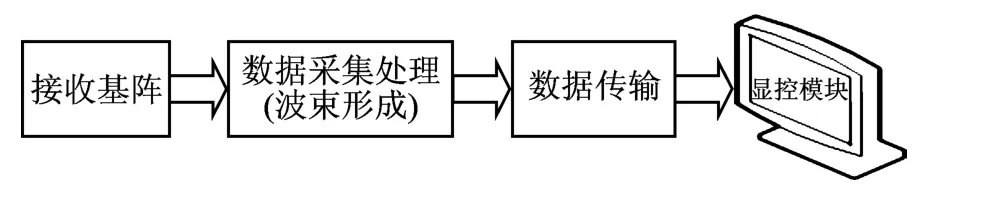
图1 成像声纳数据流向图
系统中的FPGA选用Xilinx公司Virtex-5系列XC5VFX70T,该FPGA内嵌PowerPC440处理器,最高主频可达550MHz。系统数据传输模块的总体方案如图2所示,以Virtex-5FPGA为核心,基于SOPC架构,以PLB为总线,在PowerPC440处理器上移植VxWorks操作系统。通过操作系统来管理网络、串口等外围接口,利用FPGA强大的逻辑资源和功能丰富的IP核,配合相应的外围芯片,在VxWorks操作系统上实现网络数据的传输。
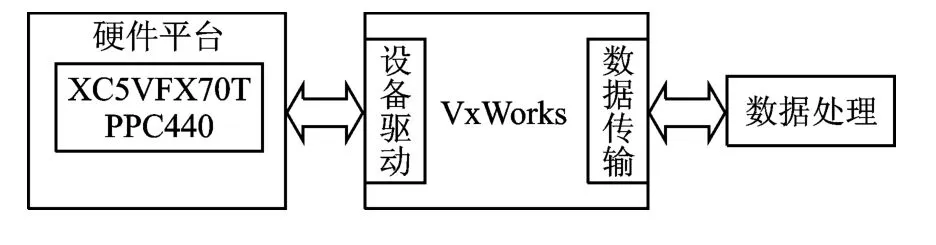
图2 系统总体设计框图
2 FPGA硬件逻辑设计
2.1 可编程片上系统构建
本文片上系统的设计框图如图3所示。由于系统调试需要,系统中加入了RS232串口;FLASH作为系统ROM,固化操作系统镜像、存储TVG曲线等参数;DDR2作为系统RAM,用于缓存数据,DDR2采用MPMC存储器控制器IP核;以太网MAC核采用Xilinx公司的xps_ll_temac三态以太网MAC IP核。在系统中,要传输的数据从自定义IP核中产生或者从外部输入,通过NPI接口暂存入DDR2中;数据达到一定数量后,通过DMA通道从千兆以太网发送出去。根据该设计框图在XPS中进行具体配置。

图3 基于Virtex-5的片上系统设计框图
2.2 千兆以太网硬件配置
以太网接口的通信速度由网卡决定,本系统在干端PC机采用高速率千兆以太网卡,千兆以太网技术具有传输速度快、距离远、向下兼容10/100Mbps以太网特性[4],可以满足系统需求。
在湿端数据发送端的FPGA中添加用于千兆以太网通信的 MAC核xps_ll_temac,它基于PLB总线控制,通过Xilinx LocalLink总线完成高效的数据传输与接收,无需通过verilog代码编写MAC协议等。为了达到千兆网速,本系统配置MAC核使用GMII接口运行频率125 MHz,工作在1Gbps的模式。外围以太网PHY物理层芯片配合选用美国Marvell公司的88E1111芯片,通过引脚配置芯片为千兆工作模式,从而进行引脚连接,保证硬件工作千兆状态。
2.3 自定义IP核设计
成像声纳中,前端波束形成后的数据输入,输入时钟频率为7.68MHz,每次输入8位数据。输入的数据要通过操作系统的TCP协议发送到上层软件,而VxWorks操作的数据是在DDR2中,这就需要将外部输入的数据写入DDR2,自定义IP核就主要完成这个工作,保证所有数据尽可能快地写入DDR2并发送给干端显控软件。
2.3.1 两种数据存储方法
①FIFO缓存。自定义IP核通过PLB总线连接PowerPC440处理器,处理器可以通过寄存器和底层通信,控制数据的传输。自定义IP核内部提供FIFO服务,外部数据可以先存入FIFO,然后操作系统端从FIFO中读出数据并存入DDR2。FIFO接口基于PLB总线控制,数据输入/输出工作时钟频率都为100MHz,FIFO宽度32位,则理论数据传输速率为3.2Gbps。
②NPI接口。MPMC是支持双数据传输模式(DDR和DDR2)和单数据传输模式(SDRAM)的参数化内存控制器,提供了8个相互独立的端口来存取内存[7]。NPI接口是让用户在自己的设计中利用MPMC特性的接口。选用MPMC作为DDR2的控制器,并将其配置为两端口模式,一个端口配置为PPC440MC,和PowerPC440处理器相连;另一个端口配置为NPI接口,和用户IP核相连,NPI接口可以直接把数据写入DDR2。DDR2和NPI接口的工作频率都为200MHz,数据宽度支持64位、32位[7],则理论数据传输速率最高可达12.8Gbps,完全可以满足系统需求。
2.3.2 本系统数据存储方法
由于数据输入时钟频率为7.68Hz,所以无论采用FIFO或者NPI接口,都需要先经过RAM调整时钟域。在自定义IP核设计中,先采用两个双口RAM进行乒乓缓存,然后采用NPI接口,直接把数据按帧写入DDR2中,图4为自定义IP核内部逻辑。clk 7.68MHz为数据输入时钟,en为帧使能信号,data 8位为输入数据。双口RAM写时钟即clk 7.68MHz,每次写入8位;读时钟为200MHz,每次读取32位,并写入NPI接口中,写NPI接口采用8字长带缓冲行写操作时序,在地址请求的同一周期给出地址确认信号。
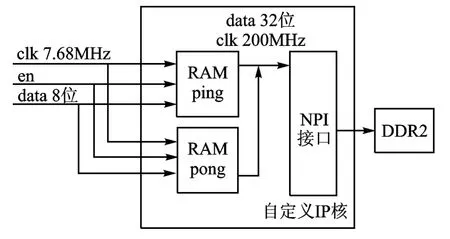
图4 自定义IP核内部逻辑图
3 VxWorks传输软件优化设计
3.1 VxWorks操作系统移植
VxWorks操作系统在Virtex-5FX70T上的移植主要包括板级支持包(BSP)的开发、BSP和VxWorks映像的编译和下载。BSP是介于主板硬件和操作系统之间的一层,主要目的是为了支持操作系统,使之能够更好地运行于硬件主板。BSP的开发主要通过修改Xilinx公司EDK套件中BSP生成器产生的BSP包完成。
①config.h文件修改:config.h文件主要设置启动行、内存地址和大小、屏蔽一些组件、自定义宏等,涉及的主要修改略——编者注。
②Makefile文件修改:Makefile文件是构造Vx-Works映像的批处理文件,本方案在生成SOPC架构时选择了硬件浮点单元,所以选用gnu为编译工具,并且ROM和RAM的宏定义和config.h中一致。代码略——编者注。
3.2 千兆网卡驱动文件优化
本方案采用 MAC(xps_ll_temac)+PHY(88E1111)方案,底层驱动程序在BSP包的ppc440_drv_csp\xsrc文件夹中。在xlltemac_end_adapter.c中选择使用DMA方式,并在xlltemac_end_adapter.h修改一些常量定义,如缓冲区、缓冲池的大小,产生中断的门限值等。由于本方案主要用于发送,所以增加发送默认BD值为2 048,这样在发送大数据包时可以一次性发送,而不需要分多次发送,从而减小延时。其他参数的修改略——编者注。
3.3 TCP网络数据发送设计
根据修改的BSP包建立VxWorks工程后,在userA-ppInit.c中编写网络通信程序,从而实现波束数据发送。网络通信一般可以通过套接字(socket)实现,一个套接口是通信的一端,VxWorks提供了标准的BSD套接字[10]。BSD套接字主要有流套接口和数据报套接口两种。数据报套接字使用UDP协议捆绑某一端口,而流套接字使用TCP协议捆绑某一端口。与TCP相比,UDP提供了一个相对简单但适应性很强的通信方式,两者都支持双向数据流,但是UDP协议并不保证数据的可靠、有序、无重复性,而TCP协议通过三次握手提供双向、有序、无重复的数据流服务,通信可靠,对数据有重发和校验机制[10]。
本设计中为了确保数据的正确传输,没有丢失,采用了TCP协议。图5为VxWorks中网络数据发送流程图,采用VxWorks多任务编程模式。SendProc负责发送数据,每次发送2 048个char类型的数据;StopProc任务实时接收停止命令。

图5 VxWorks网络数据发送
3.4 网络性能优化
通信系统的数据传输要经过OS内存处理、TCP/IP协议栈和网络设备及其驱动等,通信过程中的系统开销包括字节开销和分组开销[11]。为了提高数据传输性能,需要减少系统开销。
3.4.1 减少字节开销
字节开销主要来自系统中传送、拷贝数据和计算校验和。所谓计算校验和,即网络传输中由于各种干扰,会发生数据传输错误,为了检测这种错误,通常采用因特网校验和算法,从而增加了系统开销[11]。
通常在接收端和发送端的校验和都是由CPU计算,须有CPU从内存系统载入所有数据,再进行一系列加法操作,必然占用较多的系统资源。本设计通过采用硬件执行校验和算法,在PC机端和xps_ll_temac核中开启硬件校验和,由DMA接口的硬件来计算校验和,即校验和卸载,这样避免占用CPU资源,降低字节开销。
3.4.2 减少分组开销
分组开销包括分配和释放系统缓冲区、执行TCP/IP协议代码,以及处理设备中断带来的开销。在发送端,应用程序向接收端发送数据时,操作系统首先分配系统缓冲区,存放传输数据,执行TCP/IP协议代码,将数据分段处理为TCP/IP分组。当发送完一个分组后,就向操作系统发送设备中断,操作系统就要处理设备中断,释放系统缓冲区。TCP/IP段大小一般取 MTU尺寸,MTU即最大网络传输单元。所以,如果增大TCP/IP分组数据包大小,就可以减少分包的次数,从而减少开销。本设计在配置xps_ll_temac核时,增加接收与发送FIFO容量,并在VxWork网卡驱动中增加MTU的大小。在socket编程时,修改默认的接收发送缓冲区值,从而减少数据的传输阻塞,减少分组开销。
另外,在没有中断调节的情况下,系统要处理大量的中断,CPU的使用量以更高的数据速率增加,所以本设计中开启中断调节功能,设置中断节流率为中,根据网络的流量情况,动态调整发起处理器中断的频率。
4 测试结果与分析
在测试数据传输性能时采用的PC机的硬件平台为Intel奔腾,3.19GHz CPU,1.86GB内存,网卡为Intel 82578DM Gigabit Network网卡。
4.1 网速测试
测试网速时,采用while循环不停地向显控软件发送数据,测试网络接口所能达到的最大网络传输速度。网络传输速度测试结果如表1所列,和其他成像声纳数据传输方案的对比如表2所列,网速测试图略——编者注。

表1 网络传输速度测试

表2 和其他成像声纳数据传输方案对比
通过测试可以看出,基于Virtex-5FPGA和VxWorks的SOPC架构下网络数据传输方案实际可以达到的网络传输速度平均为245Mbps,达到千兆网性能的25%,并且性能明显优于参考文献[2][3]的数据传输方案。
4.2 IP核数据传输测试
实际测量,对比自定义IP核把外部数据写入DDR2的两种方案。通过对比测试可以看出,采用MPMC存储器中的NPI接口写DDR2,然后进行网络传输数据,速度明显优于FIFO读写,并超过了120Mbps的设计目标。两种传输方案对比如表3所列。
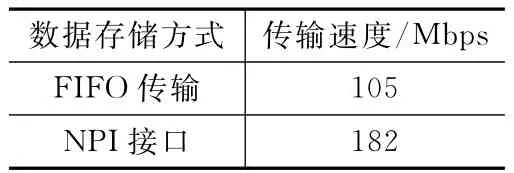
表3 两种传输方案对比
结 语
本文在Xilinx Virtex-5FX70T上基于SOPC嵌入式架构,移植VxWorks操作系统进行数据传输时,网络利用率达到25%,明显优于参考文献[2][3]的数据传输方案。并且,采用MPMC存储器控制器的NPI接口,将声纳成像数据写入DDR2并进行网络传输,网络利用率仍能达到18%。该设计方式已经成功应用于项目,并取得了良好的效果。此外,根据成像声纳的实际工作性能需求,该方案不仅能满足当前的成像声纳数据传输61.44Mbps的需求,还可以适应以后更高分辨率的声纳图像传输,甚至将接口稍作改变,可以应用于其他需要高速率网络数据传输的领域。
编者注:本文为期刊缩略版,全文见本刊网站www.mesnet.com.cn。
[1] 王晓峰.成像声纳波束形成新技术研究[D].哈尔滨:哈尔滨工程大学,2011:3-8.
[2] 巫琴.成像声纳数据传输和显控软件的设计与实现[D].哈尔滨:哈尔滨工程大学,2011.
[3] 张晓蕾.基于SOPC的成像声纳数字系统设计[D].哈尔滨:哈尔滨工程大学,2011:2-4.
[4] IEEE.IEEE 802.3-2005:1-5.Carrier Sense Multiple Access With Collision Detection(CSMA/CD)Access Method and Physical:Layer Specifications[S].
[5] 张文沛,彭先蓉,徐勇.基于SOPC的千兆以太网数据传输设计[J].仪器仪表用户,2010,17(3):66-68.
[6] 温小勇.基于FPGA和SOPC技术的视频图像处理系统的研究[D].天津:天津师范大学,2008.
[7] 叶肇晋,张稀楠,马磊.基于XILINX FPGA片上嵌入式系统的用户IP开发[M].西安:西安电子科技大学出版社,2008.
[8] A Barbalace,A Luchetta,G Manduchi,et al.Performance Comparision of VxWorks,Linux,RTAI,and Xenomai in a Hard Real-Time Application[J].IEEE Transactions on nuclear science,2008,55(1):435-439.
[9] 张峰,任国强,申会民.片上PowerPC在 VxWorks下的UDP千兆网通信[J].应用天地,2008(2):52-54.
[10] 孙祥营,柏桂枝.嵌入式实时操作系统VxWorks及其开发环境Tornado[M].北京:中国电力出版社,2002:15-45.
[11] 周敬利,杨芳,汪雪磊.千兆以太网中通信系统优化策略的研究[J].计算机工程与应用,2004(4):149-150.
[12] Chase J S,Gallatin A J,Yocum KG.End-System optimizations for high-speed TCP[J].IEEE Communications Magazine,2001,39(4):68-74.
