改进关联规则数据挖掘在网络入侵检测中的应用
2013-09-17张群慧
张群慧
(湖南信息科学职业学院 湖南 410151)
0 引言
要从海量的数据中挖掘出有用的信息知识,关联规则是数据挖掘的主要工具之一。它主要是能够从大量的数据中寻找出数据之间的关联关系。作为传统网络安全技术的补充,入侵检测受到更多的重视。基于模式匹配、统计分析和完整性分析的传统入侵检测方法,逐渐不能适应快速发展的网络安全技术。将关联规则引入到入侵检测中,可以适应快速发展的网络技术并提高入侵检测的检测效率。
1 传统的关联规则挖掘算法
Apriori 是一种最有影响的挖掘频繁项集的算法。早在1994年Agrawal等人在项目集格空间理论的基础上提出了用于发现频繁项目集的Apriori算法。这种经典的Apriori算法是采用一种叫做“逐层搜索”的迭代方法。要使用k-项集来生成(k+1)-项集,首先必须对数据库进行扫描以计算出频繁l-项集的集合,将该集合记为:L1,然后再执行迭代过程来计算频繁k-项集,一直到生成频繁了k-项集的集合(记为:Lk)为空,其过程为:
(1)连接:用Lk-1进行自连接运算,来生成候选k-项集的集合(记为:Ck)。通过运算后,Ck集合将包含所有的频繁k-项集。
(2)剪枝:连接生成的Ck就是Lk的超集,通过扫描DataBase来计算Ck中每个候选项集的支持度。用户首先给定最小支持度,对于支持度大于给定的最小支持度的候选k-项目集就是频繁k-项目集。
Apriori算法存在以下缺点:
(1)可能产生大量的候选项集,特别是候选2-项集。如果有1000个频繁1-项集,那么该算法将会产生105数量级的候选2-项集。
(2)可能需要重复地扫描数据库。
(3)计数工作量可能非常大。
2 改进的Apriori 算法及其算法实验
采用自适应步长跃进。因为每个频繁项集对数据库需要扫描一次。为了减少对数据库的扫描次数,本算法是在己产生的Lk基础上以hi为步长,通过连接、剪枝一次性产生新的以hi为步长的(k+j)-itemset (j= 1,2…, hi)的候选频繁集,然后再扫描数据库,确定其中真正的频繁项集,从而可以大大减少数据库挖掘过程中的扫描时间,以提高效率。
3 动态修剪候选项集。频繁项集的特征
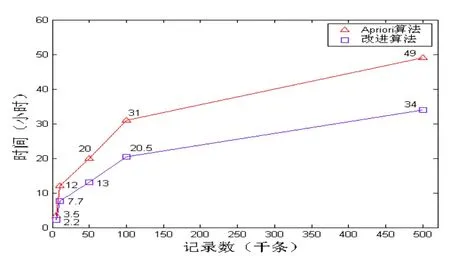
特征1: 若k维数据项目集I={i1,i2,…,ik}中,存在至少有一个im使得Nk-1(im) 特征2:对于不包含Ck-1的事务产生的任何项集,则删除该事务对Lj(j≥k)的计算没有影响。 本文主要是在一次生成候选项集的时候按照上述性质,通过缩减和删除数据集的规模,减少候选项集的个数,从而使得搜索空间比原来小,使Apriori算法在搜索空间上得到改进。 在原来的Apriori算法基础上,改进算法U-Apriori的实现的主要步骤如下: 输入:经过布尔化的数据库D,最小化支持阈值min_sup 输出:Li,D中的频繁项集。 (1)L1=find_freguent_1_itemset(D); (2)for(k=2;Lk≠ф;k++) (3)Ck=apriori_gen(Lk-1,min_sup); (4)for each c∈Ck); (5)for each p∈Lk-1&&q∈Lk-1; (6)if(p⊕q==c) (7)for(i=1;i (8)m[i]=p[i]*q[i]; (9)if(m[i]==1)m.count++ (10)if(m.count>=min_sup) (11)Insert_into_Lk(m) (12)return l=UkLk 特征3:改进Apriori 算法的实验。在一台计算机CPU Intel P4 2.0G, 内存为512M 上对Apriori 算法与其改进算法进行实验测试对比(时间单位:小时) 。试验仿真数据来源:chess数据集(http://fimi.cs. helsinki. fi/)。所得实验结果如图1所示。 从图1中可以看出, 在挖掘速度上,改进Apriori算法较改进前有比较明显的优势,在数据集大小为5万条以下不明显,但数据集超过10万时开始有较大区别,改进算法的优势已经很明显。这是应为改进算法因为减少了对数据库的扫描次数,并显著减小了候选集的大小,所以较大程度地提高了算法效率。 数据挖掘在入侵检测中的应用,主要是利用数据挖掘中的数据分类、关联分析和序列模式挖掘,对来自不同数据源的安全审计数据进行智能化的分析处理,通过提取数据本身存在的规律性,帮助系统生成入侵检测规则和建立异常检测模型,最大限度的降低在处理安全审计数据时对先验知识的要求。关联分析算法可用于挖掘描述入侵行为模式的关联规则,通过这些规则进行入侵检测。 图1 Aprior算法改进前和改进后算法性能比较 (1)数据获取:在网络上截取用于检测的数据。 (2)数据预处理:对网络上捕获到的原始网络数据,需要先进行预处理,将它们转换成ASCII码格式的网络分组信息,再将网络分组信息处理成网络连接记录,并将其放入审计记录库,为数据挖掘做准备。 (3)审计记录库:审计记录库存放从网络上得到的各种数据。 (4)数据训练集:在系统初期,需要收集数据进行训练,把已知系统缺陷和其他已知攻击模式装入知识库中。 (5)数据挖掘算法库:在挖掘算法库的指导下, 数据挖掘引擎对审计数据进行挖掘得出新的入侵规则,然后与知识库中的规则对比。 (6)知识库:此处存放数据挖掘所需要的领域知识,这些知识将用于指导数据挖掘的搜索过程或者用于帮助对挖掘结果的评估。 (7)数据挖掘引擎:这是数据挖掘系统的最基本部件,它通常包含一组挖掘功能模块,以便完成定性归纳、关联分析、分类归纳、进化计算和偏差分析等挖掘功能。 (8)决策模块:负责对非正常模式或未知模式进行人工判断。如果判断结果是正常模式,则将其添加到知识库中与其相近的正常模式。如果判断结果为异常模式,则把它添加到知识库中与其相近的异常模式,并立即执行必要的防范措施。 本文在传统的Apriori算法基础上,提出了引入自适应步长跃进、动态修剪候选项集的算法,大大减少了对数据库的扫描次数,并显著减少了候选集的数量,提高了算法的效率,具有重要的价值和广泛的意义。 [1]郭山清,谢立,曾英佩.入侵检测在线规则生成模型[J].计算机学报,2006(29),1523-1532. [2]胡亮,金刚,于漫等.基于异常检测的入侵检测技术[J].吉林大学学报( 理学版),2009(47),1264-1270.4 改进的算法在入侵检测中的应用
5 结束语
