Fermi架构下各向异性扩散超声斑点噪声抑制
2013-09-12何兴无
何兴无
(1.成都师范学院网络与信息管理中心,成都 611130;2.成都农业科技职业学院电子信息分院,成都 611130)
1 概述
在医学影像技术中,医学超声诊断技术因为其易用性,无侵入性,实时性,廉价性等特点和优势在现代的医学诊断中,有着难以取代的作用[1]。然而在超声回波信号成像处理过程中,由于需要对位于成像介质内的超声随机散射点产生的信号进行叠加产生图像信号,导致在超声图像上往往会出现被称为斑点噪声的不规则斑点,通常会让人体组织难以识别,降低图像的分辨率,从而影响图像质量。因此通过去除斑点噪声来提高超声图像的质量具有非常重要意义。
在斑点噪声抑制算法中,传统的显式非线性扩散滤波方式可以达到比较好的期望效果,但仅限于有限的很小的时间步长范围内,对于全部时长则不稳定。半隐式加性算子分裂的方式来离散化扩散方程[2],使迭代过程对于任意步长都是稳定的,并且在边缘保持和噪声抑制方面都有非常好的处理效果,但在传统基于CPU处理时很难满足实时系统的要求,这阻碍了其在实际临床中的应用。随着多核时代的降临,并行处理技术日益成为解决计算瓶颈的最重要手段,一些复杂计算也可以通过并行处理平台进行显著加速。
随着GPU技术的发展,其浮点数处理能力大大超过了CPU,特别是Fermi架构GPU的出现,使这一新的处理平台的计算能力显著提高。相比较于早期的通用计算GPU设备,在保持图形性能的前提下,Fermi架构将通用计算技术提升到前所未有的高度,具体表现在[3]:计算资源更为丰富,每个多处理器拥有32个CUDA(Compute Unified Device Architecture,统一计算设备架构)核心(最基本的运算单元);其次,Fermi架构引入了缓存机制,使GPU拥有真正意义的可读写L1缓存和L2缓存;浮点计算精度和速度也有大幅提高。
与传统CPU方式不同,对于CUDA并行处理程序设计,要获得比较高的性能,需要考虑几个方面:首先是存储器操作,CPU的内存存取延迟主要是通过多级缓存来消除,而CUDA主要通过高度并行化和合并访问的方式来达到高的带宽利用率,即使在新一代Fermi架构下让CUDA程序尽可能满足合并访问,也会明显地提高性能;其次,并行处理方式的设计,即如何提高运算并行度,尽可能的使GPU占用率高。
第一部分已经介绍所作研究的相关背景和技术介绍,在第二部分中将详细阐述设计的并行算法。实验数据的结果及相关分析讨论放在的第三部分;最后在第四部分给出了工作总结和对未来工作的展望。
2 Fermi架构平台下基于各向异性扩散斑点噪声抑制并行处理算法
2.1 各向异性扩散斑点噪声抑制算法概述
各向异性扩散斑点噪声抑制算法的核心是基于局部相干性,并且采用加性算子分裂方法进行离散化完成快速斑点噪声抑制。基于局部相干性信息的半隐式各向异性扩散的超声图像斑点噪声抑制算法[3]主要包括低通滤波、扩散系数表和三对角矩阵的生成及解三对角线性方程组三个环节。首先,各向异性扩散方程定义如下:

其中,扩散系数l(·)定义如下:
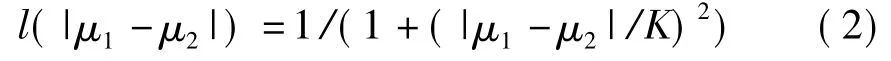
μ1和μ2是每点处结构矩阵的特征值,结构矩阵的定义为:J(▽Iσ)=(▽Iσ·▽ITσ)。▽Iσ是通过与一个二维高斯核进行卷积(方差为σ)得到的模糊的原图像I的梯度。把(1)式转化为一个矩阵和向量的形式,并且采用加性算子分裂方法离散化,即得如下方程:
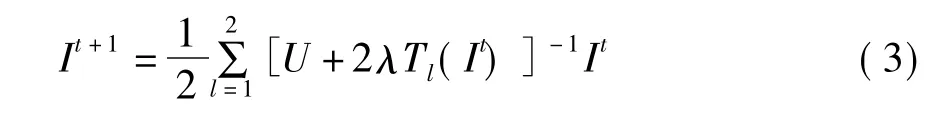
其中U是一个KL×KL的单位矩阵(K,L分别为图像的高和宽),λ是迭代步长,Tl(It)是一个三对角阵,Tl(It)=[tij(It)]。
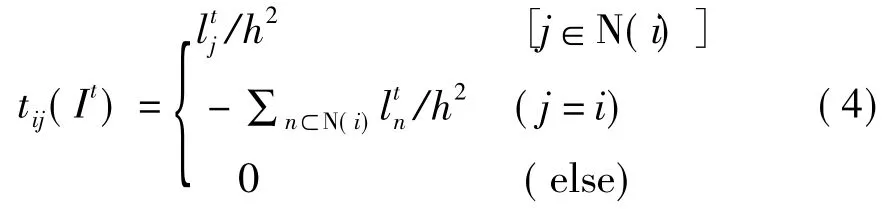
此处,l是扩散系数。N(i)是一个像素在某一个维度上i的两个相邻点的集合。h为滤波窗口的大小。
2.2 数据准备阶段
利用GPU平台进行通用计算,相比较一般CPU的处理方式,算法的参数和数据都必须首先从主机端传送到设备端才可以进行处理,主机端和设备端都有多种具有不同性能特性的存储器。因此在并行算法设计与实现时需要综合考虑以减少数据传输的开销。本算法中主要的处理数据是图像数据,而参数包括单个的系统参数如算法阈值,图像大小等。这些数据的存储器选择策略如下:
在主机端,主要进行的处理数据是每一帧图像。而在CUDA平台上为内存开放了两种类型的存储器,分页内存和页锁定内存。页锁定内存的带宽会比分页内存高出2倍多。页锁定内存一共提供了4种工作模式。其中,写结合模式可以使数据在通过PCI-e总线传输时不会被监视,这能够获得高达40%的传输加速,是最适合CPU是只写的情况。由于输入数据对于CPU来讲是只写的,因此可以使用页锁定内存中的这种写结合模式[6]。
在设备端,由于Fermi架构对全局存储器引入了缓存机制,因此可以使用二维对齐的线性显存空间存放来自主机端的输入数据。另外在实现中,可以将一些预定义好的单个参数合并入一个数组放入常量存储器供所有线程访问,这样不仅可以充分利用常量存储器带宽,也可以减少寄存器的占用率以提高整体运行的并行度。
2.3 低通滤波
在各向异性扩散方法中每次迭代都要先对原始图像进行一个低通滤波处理,常用的低通滤波器是高斯滤波器。它通常使用一个高斯核卷积实现。这里使用的是5×5的高斯核。对于一个2维的高斯卷积,为了减少冗余计算,可以将其分解为两个1维高斯核分别沿X,Y轴作卷积的结果。同时,可以用一个均值滤波代替高斯滤波。通过测试,两者的处理效果基本一致。但在CUDA程序设计时,采用均值滤波的处理能力更快,具体的并行实现方式是启动两个核函数分别进行沿X方向和沿Y方向的处理。让一个线程负责处理一行或一列,X方向的示意如下:
这里需要注意的是在沿X方向处理时,相邻线程访问的图像像素点是隔开的,并不满足合并访问规则,全局存储器在这种情况下效率极低。因此在进行X方向滤波时,图像数据应绑定到纹理存储器,然后将X方向一维滤波输出写入到全局存储器中供Y方向滤波使用。在进行沿Y方向滤波时,由于相邻线程同时读取图像一行的像素值(物理上是相邻并且对齐存储的),所以满足了全局存储器的合并访问条件,实现最优化访存。
2.4 扩散系数表和三对角矩阵的生成计算
由公式(3)可知,本算法需要进行多次迭代才能得到比较好的去噪效果,在每一次迭代中,扩散系数是不同的。如果在每次迭代过程中都要计算扩散系数,就会大大降低算法的效率[7]。于是在设计中采用生成扩散系数表,每次迭代用查表的方式得到扩散系数,这样就减少了大量的冗余计算。因为扩散系数与图像上某点的梯度有关,而梯度分量的取值范围为-255~255,所以生成的扩散系数表的大小为511×511。同时,利用式(4)查表可以得到三对角矩阵。
值得注意的是,为了减少数据传输时间,将扩散系数表的生成放在了GPU端,由多线程核函数完成。同时这里的扩散系数表在查表时是具有一定随机性的,因此采用二维纹理存储器来存储它,这样在查表的过程中就可以通过纹理缓存机制实现比较好的带宽利用率。二维纹理绑定的具体实现如下:
使用cudaMallocArray函数分配专为纹理拾取而优化的显存存储空间CUDA Array空间存放数据。然后设置纹理通道参数来决定纹理拾取的工作条件,并利用cudaBindTexture函数将扩散系数表绑定到纹理存储器。
2.5 解三对角线性方程组
本算法需要要解出的三对角线性方程组有如下形式:
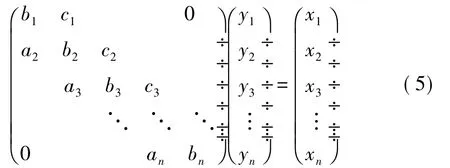
其中 ai,bi,ci和 xi,i=1,…,n,为已知。而解上式的三对角线性方程组是实现加性算子分裂方式离散化各向异性扩散方法的关键。在CPU上,一般使用Thomas算法求解三对角线性方程组[8]。Thomas算法是一种高效的串行算法,但是它并不能完全发挥GPU的并行计算能力,因此需要寻找一种能够并行化的求解方法。使用循环约化的方法来解这个三对角线性系统[5],可以在GPU上并行的实现。
采用GPU进行处理的循环约化的方法主要由四个部分组成:
(1)对图像的每一行建立一个三对角矩阵。
(2)并行地解三对角矩阵。
(3)对每一列重复以上两个步骤,即对图像的每一列建立三对角矩阵。
(4)循环约化法使用的是高斯消去法迭代地并行消去三对角矩阵中的奇数行。其伪代码如下:
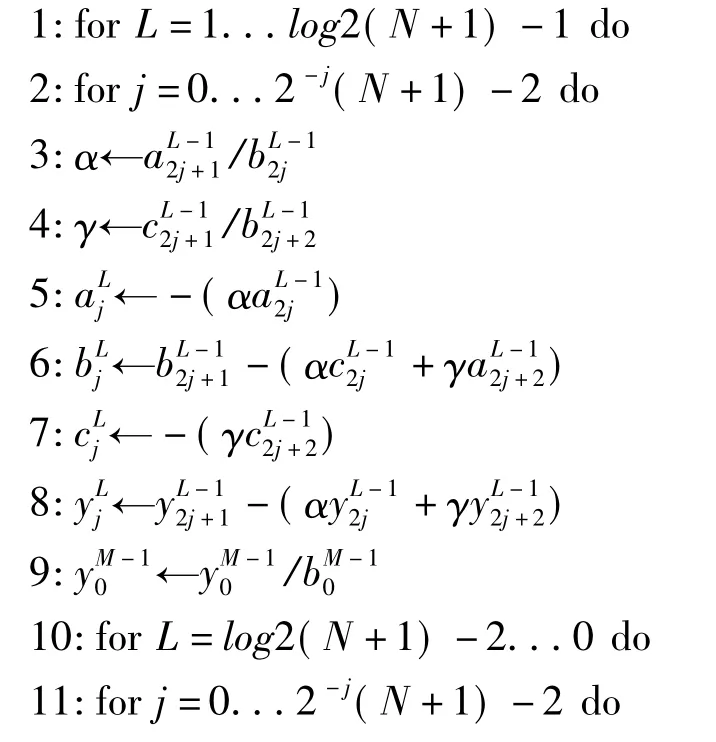
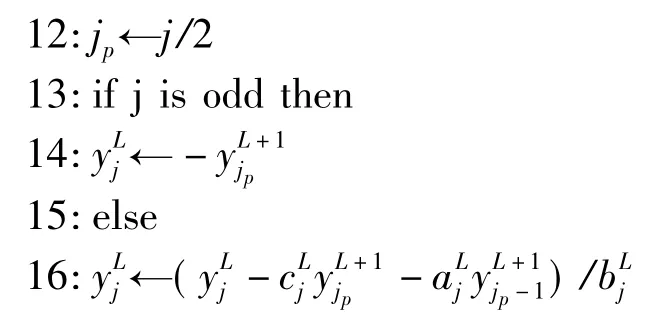
在GPU平台上实现时,设计两个CUDA核函数分别处理行向和列向。在线程结构方面,让一个线程对应与一行或一列,由于是在Fermi平台下,每个线程块内设计应至少为2个warp块,即64个线程,对于此处测试所用的平台,为了尽可能利用多处理器,块内线程数设置较小,在其它应用场合最好根据图像数据规模合理设置线程结构,以尽可能利用GPU计算资源。
在存储器使用方面,在Fermi架构下全局存储器已提供了L1缓存机制,因此在核函数处理设计时没有使用共享存储器作为中间运算的载体。而是直接在全局存储器完成,这里为了让L1更好的工作,使用cudaFuncSetCacheConfig函数将这两个核函数的执行配置设为L1优先模式,即让L1拥有48KB的空间,参数项为cudaFuncCachePreferL1。
2.6 图像显示
经过图像后处理的超声图像显示数据存放在显存上,要进行显示,既可以写回主机端然后进入图形学管线进行绘制,也可以直接利用CUDA技术与图形学管线的互操作接口如OpenGL进行资源共享。后者可以将显存中存放的数据直接写入到图形学纹理体素空间中进行图像渲染显示,这就避免内存和显存进行数据传输的时间消耗。具体的实现方式是首先初始化OpenGL设备,然后进行纹理资源创建与注册,并设定资源的读写属性。在把CUDA中处理完毕的图像数据写入到OpenGL纹理空间,就可以进行图像渲染,最后释放占有的资源。
3 实验结果与分析
实验平台为 2.20GHz的 AMD Althlon(tm)644200+,操作系统为Windows XP。GPU为 NVIDIA Geforce GTX 560 Ti,显存为 1GB,核心频率 1.645GHz,14个多处理器,使用4.0版本的CUDA toolkit及对应的开发包。编程环境为Visual Studio 2010。
为了测试提出的并行实现算法的处理效果和运行效率,使用由数字超声扫描器在超声系统iMago C21上采集得到的人体数据作为研究工作的实验数据。图1(a)和(b)显示的是由3.5MHz凸阵扫描器采集得到的人体组织的超声原图像,(c)和(d)是斑点噪声抑制后CPU处理结果。(e)和(f)是斑点噪声抑制后GPU的处理结果。通过对比知道CPU和GPU的处理结果完全保持一致,图像像素值误差为0,其中算法迭代次数为4,步长设置的是1.5。
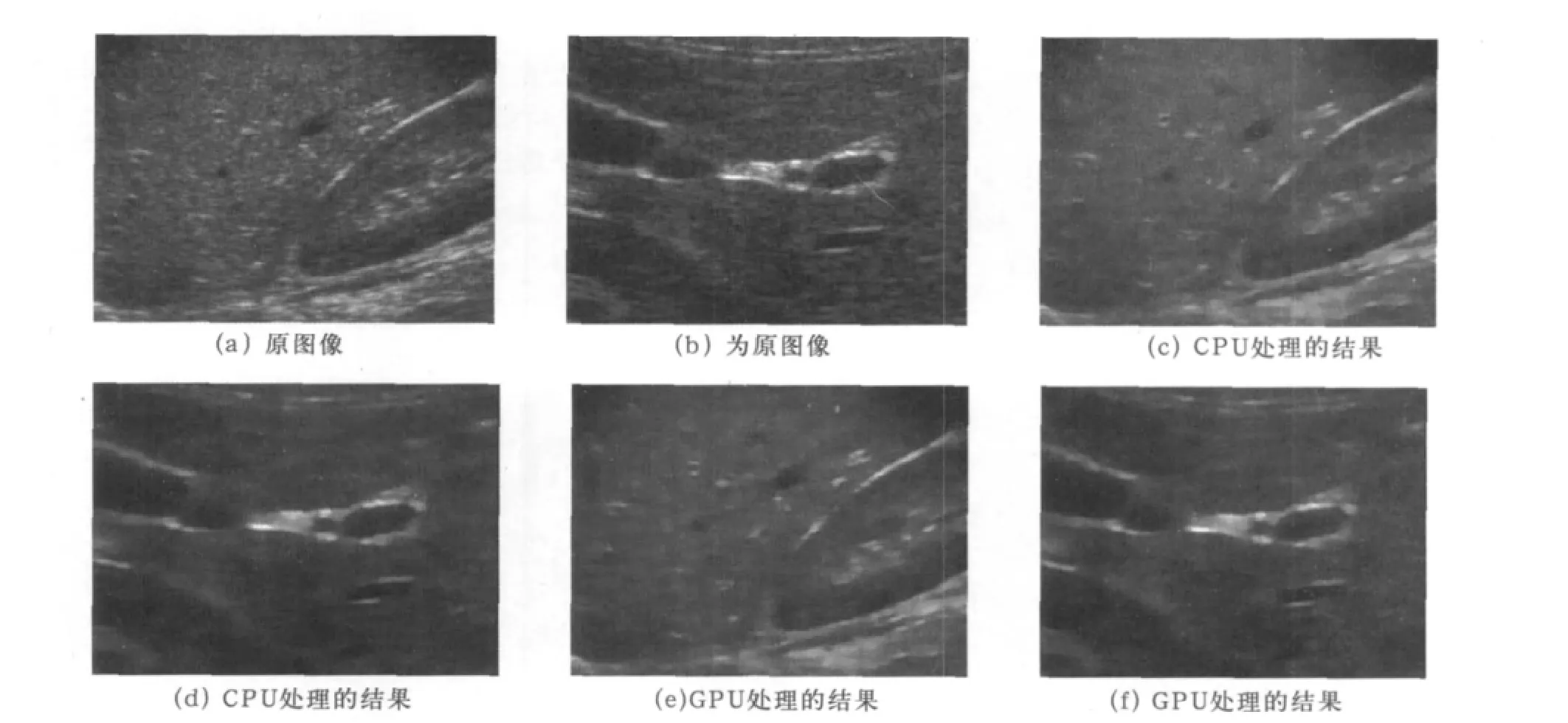
图1 采用超声凸阵扫描器采集得到的人体组织图像分别测试CPU和GPU的去噪效果对比图
表1给出了所研究的斑点噪声算法CPU和GPU处理的性能比较。程序的运行时间是图像数据进入显存后进行噪声抑制处理的全部运行时间。从表1可以明显看出,基于Fermi架构GPU并行处理算法相比较于传统的CPU串行处理提高了大约120倍。加速比也说明了数据计算规模越密集,GPU并行加速效果越明显。
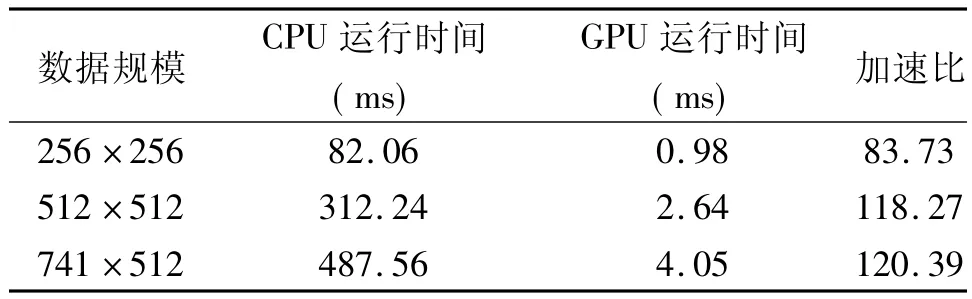
表1 性能比较
4 结 束 语
实验结果显示了基于Fermi架构GPU的超声斑点噪声抑制并行实现方法得到的图像去噪质量和通用CPU处理的结果保持基本一致,而在时间性能方面达到了实时系统的处理要求,得到大约120多倍的加速效果。在这样的GPU处理效率下,使用各向异性的方式进行超声图像斑点噪声抑制不仅可以取得比较好的图像噪声抑制效果,也可以满足临床超声检测系统的实时处理要求。另一方面,从加速比的分析来看,也说明了GPU并行处理平台对于计算密集的情况加速效果更好,这与Gustafson加速比模型分析一致[9]。
[1]李治安.临床超声影像学[M].北京:人民卫生出版社,2003.
[2]J.Weichert,B.Romeny,M.A.Viergever.Efficient and reliable schemes for nonlinear diffusion filtering[J].Image Processing,1998,7(3):398 -410.
[3]NVIDIA Corporation.CUDA ProgrammingGuide4.0[S/OL].[2011 -05 -06].http://www.nvdia.com.
[4]夏春兰,石丹,刘东权.基于CUDA的超声B模式成像[J].计算机应用研究,2011,28(6):2011 -2015.
[5]范正娟,刘东权.基于CUDA的超声彩色血流成像[J].计算机应用,2011,31(3):856 -859.
[6]NVIDIA Co..CUDA API Reference Manual 4.0[M].Santa Clara,CA,2011.
[7]Wang,Bo,Tan,Chaowei,Liu Dong C.Local Coherence based Fast Speckle Reducing Anisotropic Diffusion[C].Proceedings of 2008 International Pre-Olympic Congress on Computer Science,Nanjing:IACSS,2008:304 -309.
[8]Krüger J.,Westermann R..Linear Algebra Operators for GPU Implementation of Numerical Algorithms[J].ACM Transactions on Graphics.2003,22(3):908 -916.
[9]孙世新.并行算法及其应用[M].北京:机械工业出版社,2005.
