句类分析准则在作战文书地名识别中的应用
2013-09-11王青海池毓焕
李 颖,王青海,池毓焕
(1.装甲兵工程学院 科研部,北京100072;2.中国科学院 声学研究所,北京100190)
0 引 言
地名识别作为未登录词识别的子内容,一直是中文信息处理的热点之一[1-7]。通行的办法是 “统计与规则相结合”,即先通过统计模型大规模处理数据,再通过语法语义等知识制定规则加以修正,以期取得比较理想的识别结果。据文献 [5],中文地名识别结果的F值多在84%-92%之间。
作战文书是军队各级机关在作战和其他军事行动中形成和使用的电报、文件、图表的统称,是指挥员作战决心的体现,是军队作战行动的依据和实施作战指挥的重要工具。它通常采用文字记述式、表格式、地图注记式、网络图式等形式,有着特定而严格的格式规定。
作战文书自动处理是信息化战争条件下提高作战指挥效能的必然要求。目前,以一体化指挥平台和一体化信息系统为代表的指挥信息系统已陆续装备部队,在部队训练、战备值勤和非战争军事行动中发挥了重要作用。但文本情报信息生成态势图和作战文书注记图均依靠参谋业务人员手工标绘,影响和制约了系统的运行效率,迫切要求提高文-图转换的自动化水平。
原有的作战文书自动处理通常采用模板方式。近年来,不少专家学者提出了用自然语言处理 (natural language processing,NLP)技术来重新布局作战文书的计算机处理工作:顾晓明、翟玉庆[8]探讨了基于本体的军用文书理解,杨健等[9]、姜文志等[10]都对军事文图的自动转换进行了研究。从文献上看,他们大多只是提出构想或系统设计,较少提供可资比较的实验数据。
我们有关作战文书文图自动转换的总体思路如图1所示。

图1 作战文书文图自动转换逻辑
其中,XML等标记文件与态势图等标图文件之间的自动转换已经由标绘软件实现并进入实用化,而面向文图转换的结构化数据到XML等标记文件的格式变换纯粹是根据标记语言约定进行的严格变换,关键在于作战文书到结构化数据的作战文书要素萃取。
从军用要图标绘的角度看,作战文书的要素之一是地名及其坐标。作为三大军队标号之一的地域线直接由一系列的坐标构成,其他标图类型的基本参数都包括坐标。因此,地名识别构成作战文书处理的基本内容之一。
无可否认,现有的中文地名识别方法可直接应用于作战文书地名识别,但其效果将受制于通用技术应用于受限领域的隔靴搔痒效应。
我们的作战文书地名识别紧扣 “作战文书行文规范”这一特点,应用了句类分析所确立的若干准则,完全采用基于规则的方法。HNC (hierarchical networks of concepts)理论[11]是中国科学院声学研究所黄曾阳先生创立的、面向整个自然语言理解处理的原创理论。HNC理论把语言分析的3个基本环节分别命名为句类分析、语境单元萃取和语境生成,对应于组词成句、联句成群和形成段落篇章三级提升。可见,句类分析是HNC理论关于语句分析的专门术语。句类分析技术经过数十年的发展,已经比较成熟,广泛应用于文本分类[12]、信息过滤[13]、舆情分析[14]、机器翻译[15]等领域,但在作战文书自动处理领域应用还是首次尝试——中科院声学所已有的关于中文地名的研究仍然是走统计技术路线的,并未应用句类分析技术。
面向要图标绘这一特定目标,就地名识别这一专项,我们的实验取得了预期的效果 (F值在88%-97%之间)。
1 概念分析
对于中文地名构成,文献 [1]首先提出了 “地名特征词”、“地名前部词”、“特征词可信度”等概念并给出了较易实现的地名判断方法,在后续研究中这些概念得到了沿用。在这里,我们把 “地名前部词”称作地名的中文命名,而把 “地名特征词”称为 “地名层级标志符”,便于多层级串联地名的递归辨识,如 “四川省广安县协兴乡牌坊村”。
中文地名存在严重的重名情况。根据含超过68万条记录的中国地名库统计,县级及以上地名重名的共出现155例,占5% (分子为出现重名的记录累计数,下同;分母为3,592),主要是县市同名;乡级及以上地名重名的共出现5,202例,占30.9% (分母46,549);村级及以上地名重名的共出现70,594例,占58.9% (分母682,123)。由统计数据可以看出:越是底层,重名越多。
就使用语境而言,只要附近的地名不重复,全国村级地名大量重复并不影响语言的使用和指称的认定。但是,作战文书恰恰超越了地域限制,而所用地名很可能是村级或更细的某无名高地。人脑理解时自然而然用更高一层的地名管辖之,或者把心中的地图拉近、聚焦于目标区域,因此基本不受重名困扰。作战文书无法容忍地名指称的不确定性,因此作战文书地名使用的一大特点就是为地名附上坐标。有鉴于此,作战文书地名识别要紧抓这一特点。
坐标作为激活因子,基本确定了地名的右边界,最大的问题是左边界的识别。因此,作战文书地名识别可归结为空间概念短语的边界感知问题。
空间概念首先要分出空间点、空间线和空间面 (空间体暂不考虑)。其中空间点通常带坐标,也最常用;空间线由一系列的空间点构成,主要用于战斗分界线的表述;空间面主要用于总体作战区域的表述。
1.1 空间点 (地点)的辨识
关于空间点 (地点)的辨识,总策略是:充分利用坐标的激活信息,以及坐标加 “区域”、 “一线”、 “山区”、“方向”、“以东//西//……”、“左//右//后翼”等组合表示空间概念的词语激活,也需要一定规模的现实地名库支持。
1.1.1 坐 标
坐标统一采用以下格式:地名 (××、××)或地名(××,××),其中××系两位阿拉伯数字。
1.1.2 右边界
关于右边界,除了坐标终止符 “)”外,特别注意带方位数量的后缀也要组合到该地点的表述中
后缀=方位词+空间距离的数量词 {+ “无名高地”}其中:方位词=东//西//南//北//以东//以西//以南//以北//正东//正西//正南//正北//东侧//西侧//南侧//北侧//东北//东南//西南//西北//东北侧//东南侧//西南侧//西北侧;空间距离的数量词,一般以米为量词,前带阿拉伯数字,如 “250米”;{}中的成分为可选项。
1.1.3 左边界
关于左边界,涉及中文地名的命名规则:
中文地名=中文命名 (专名)+地名层级标志符;
其中:中文命名 (专名)一般为2字,少数3字,较少1字,不能为空 (少数民族地区因音译存在多于3字的情况);地名层级标志符=国//省、直辖市、自治区、州//市、府、盟、县、邑、县城、旗//镇、乡、都、街道、苏木//村、庄、社区、嘎查。
特别地,作战文书最常用的是:
军事专名=阿拉伯数字+ ‘高地’//‘高程点’
注意:军事专名的阿拉伯数字可能带小数点。另外,军用地名常把层级标志符省略。
县级及以上中文命名字数统计如表1所示 (总数3278)。
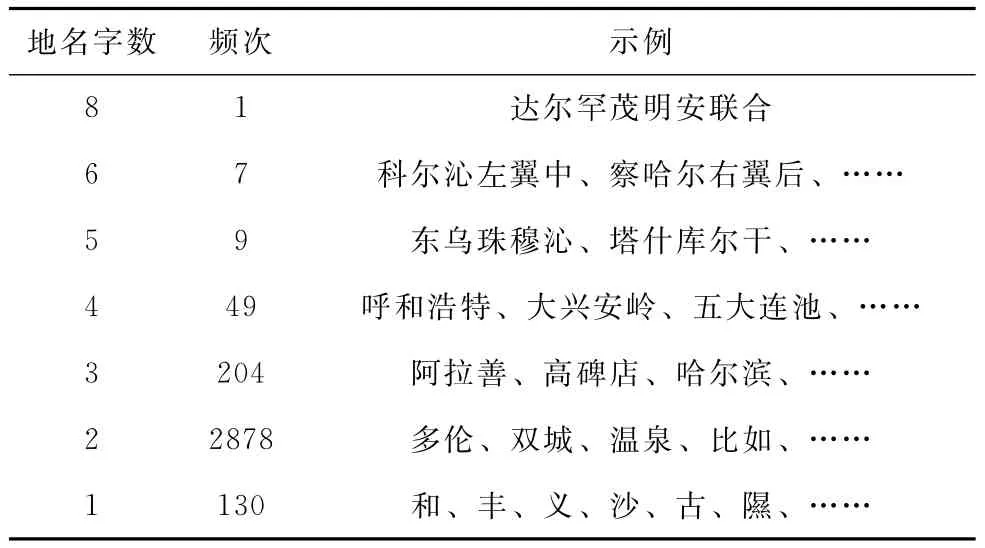
表1 县级及以上中文命名字数统计
可以说,三字以上多数为少数民族地名的音译,除非所处理的地区涉及到才需予以考虑。单字中出现了高频字“和”等,虽然与 ‘层级用字’组合匹配才识别成地名,但仍可能构成歧义;地名专用字如 ‘隰’倒是可靠依据。
1.2 空间线的辨识
关于空间线的辨识,因其由若干空间点构成,紧抓“一线”、“东西//南北+一线”、“相连之线”(“地段、方向”也作为备选)作为激活关键词 (并作为此空间线表述的右边界),依靠空间点识别的成果,按照 “至少两点、系列地名最大化 (贪食算法)”的原则左向搜索第一点,并把起始点的左边界作为空间线表述的左边界。
1.3 空间面的辨识
关于空间面的辨识,激活关键词为:“地域”、“地区”、“附近地区”、……。其前可能是空间线、若干个地点或者只有一个地名,如 “丹东地区”,故左边界较难确认,只能依托上述空间点和空间线的辨识成果。
2 句类分析准则
根据字数确定地名左边界并不保险 (与地名库完全匹配的除外,如 “赞皇”),因此还是要寻找文本中出现的自然语言边界符,这就是我们引进句类分析若干准则的原因所在。
从句类分析的角度看,语句分析的根本任务是感知语块边界。
HNC理论认为:自然语言的语句是无限的,但都可归结为有限的句类,全部自然语言的句类就57组。语句由若干语块构成,而语块分为主块和辅块两大类,主块是句类的函数,辅块不是语句的必选构件。主块又分两类:特征块EK (Eigen chunK)和广义对象语块 GBK (General oB-ject chunK),前者又根据在句子中所处层级二分为全局特征块Eg(global)和局部特征块El(local),EK大体对应语法学中的谓语,后者三分为作用者语块AK(Actor chunK)、对 象 语 块 BK (oBject chunK)和 内 容 块 CK(Content chunK),这三者大体对应于施事、受事及间接宾语。既然有对应关系,似乎只是别出心裁另取他名,无特异之处。其实不然,因为HNC给出了句类的数学物理表达式如下

其中,SC指句类 (sentence category),SCr指实际出现的句类 (r即real),fK指辅块 (借用汉语拼音首字母)。 {}仍指该项为可选项,说辅块是可选的这好理解,因为这是辅块的本意;关键是EK被加上了可选符号,即存在五类无EK句类,例如汉语非常常见的简明状态句,S04J=SB+SC,“他||精明能干”。
上述句类表达式中的GBK下标m的取值最大为3,即一个句子最多有3个GBK (AK、BK和CK相继出现),加上EK,就是4主块,少则只有1个GBK。那么会不会出现没有任何GBK的情况呢?若出现,我们视为省略GBK1,因为句类物理表达式中至少有1个GBK。这样,全部句类可分成两大类:有AK出现的广义作用句,块数为3-4;没有AK出现的广义效应句,块数为2-3。二者的重大区别是:广义作用句的语块移位通常都有主块标记符加以突显,而广义效应句的语块移位一定没有 (不用)主块标记符。广义作用句例如 (括号中标注的是语句格式代码):

有了这些句类知识,语句分析的任务就是把任何一个自然语言的语句映射到句类物理表达式中,也就是分出每个语块的边界并检验其角色。
句类分析技术的实现过程中,曾提出了若干准则,命名为lv准则,即以逻辑概念l和动词v的同现作为语块边界感知和角色认定的根本依据。这些句类分析准则简要说明如下:
(1)语句的首尾边界是首块和末块的天然首尾边界,标点符号提供了语块边界的重要信息,因此,标点准则是句类分析最基础的准则。
(2)汉语的语块标志符特别发达,是语块移位的重要工具,如 “把、被、由、向、……”等,更有辅块的括号型标志,如 “在……中”等,因此,抓块标可概括为介词准则。
(3)句类分析中把EK当作其它语块的天然边界。而EK通常是复合结构,应视作一体,例如 “表示赞赏”、“大大改善了”等。特别地,作战文书中地名通常充当转移句的起、止、由对象,可以把地名或地名组直接当作空间对象语块。这是动词准则。
(4)指代在否定动词的Eg角色中发挥着一定作用,在识别语块边界方面亦不可或缺,例如 “本发明提供了一种提取植酸钙的方法”中的 “本”和 “一种”都否定其后动词的Eg角色,也是所在语块的左边界。这是代词准则。
上述句类分析准则应用于作战文书地名识别中,可形成如下具体规则:
规则1(顿号等标点符号):‘、’肯定是其后地名的左边界; ‘:’、 ‘——’、前单双引号,也是;句子分割符‘,’、‘;’、‘。’、 ‘?’、‘!’ (即地名居于句首),若其后为单字 (地名非空),是左边界;其后排除介词、动词、代词的情况,基本也是左边界;
规则2(介词):在HNC中标为lq02的 “在、向、从、自、到、至、……”和标为hv的 “在、到、至、……”基本也是左边界。因为 ‘在’等字存在一定程度的多义性(‘在’若是句子中唯一动词,仍不妨适用本规则),其可靠性略有下降 (注意:这些单字多是分词处理后留下的孤立字,若是伪词中的这些字,可靠性更低);
另外,构成l5的概念如 ‘除’lq52ie2m…… ‘之外’lh52ie2m,也是左右边界之一;
规则3(动词):入选Eg//El的动词也是地名的天然前边界,如 “去、来、回、往、……”等及隐含空间概念的“进攻、攻占、占据、占领、进占、镇守、……”等,但有些地名可能就含有动词 (如云南边境有一地名 ‘打落’,其得名就因为日机在此地被打落),或者词语知识库对动词的标注太宽泛,其可靠性略低 (E+hv的情况在规则2中考虑;如有v+EH构成EK的也暂不考虑);
规则4(代词):常见 “我、敌、本、该、此、……”+地名层级标志符//‘高地’//‘高程点’,用于指代地名,需要指代消解 (实际的具体地名代入),但也可能不省略作为专名的地名成份,则此代词也构成左边界,功能上仍是地名指代。
3 实验及结果分析
作战文书地名识别基本流程为:
(1)判断带括号的标号段是否是地点坐标;
(2)以带括号的地点坐标为中心,向左寻找左边界(以动词和某些介词为准);
(3)以带括号的地点坐标为中心,向右寻找右边界(如果不是方向、地域等则停止)。
基于上述流程的处理结果为初步结果。然而,作战文书中的地名也不是全部标上坐标,若上文地名已有坐标则常常不再重复,因此由坐标激活的地名识别结果 (在坐标括号之前的部分)要形成一个动态地名库,视同已经带坐标,用于下文的地名识别。如此安排就引进了小小的动态记忆能力,其处理的结果则称改进结果。
我们选用了14篇共计3万多字的真实文本,人工进行军用命名实体标注,并以此测试处理结果。实验结果见表2。

表2 实验结果
左边界误识的例子如: “坚守4号高地 (80、66);”,把 “坚守”组合到地名中了,原因在于 “坚守”未列入动词准则所用的动词集内。
未召回的例子如:
(1)向石家庄右翼进攻;
(2)在大庄、大石桥张楞地区转入防御;
(3)19××年11月18日21时30分于井陉县。
未召回的主要原因是该地名在全文中均未有坐标信息,按上述流程处理无法获得激活信息。
通用地名库中的地名如 “河北省”、“石家庄”、“井陉县”等可能组合到机构名中 (如 “河北省独立第2师”),不宜直接作为地名识别结果。但在前述之顿号规则、介词规则 (如 “在”、 “于”等)、后缀辅助规则 (如 “右翼”、“左侧”、“地域”、“一线”等)共同作用下,也应该适当抓些通用地名,这是下一步改进的方向。
总之,超过99%的地名识别准确率已经符合此前预期的 “高准确率”要求,超过90%的召回率也堪用于后续的空间线//空间面识别、语块分析、句类分析、要图标绘等。
4 结束语
以往的地名识别系统的F值的平均值为88%,我们的初步结果就高达88%,改进结果达到97%,改进效果明显。
作战文书地名识别的准确率未达到100%,为什么我们仍称这个结果符合预期、“堪用”?除了自动标图的初步结果可以诉诸人工干预外,主要原因在于我们并不把这一结果当作最终结果而仅仅是作战文书预处理的步骤之一,后续的句类分析、语境分析还有纠错功能。当然,预处理的结果越接近于百分之百准确越好,已发现的若干错误原因可用于进一步改进现有程序。
[1]LI Lishuang,HUANG Degen.Identifying Chinese place names based on support vector machines and rules [J].Journal of Chinese Information Processing,2006 (5):51-57 (in Chinese).[李丽双,黄德根等.SVM与规则相结合的中文地名自动识别 [J],中文信息学报,2006 (5):51-57.]
[2]QIAN Jing,ZHANG Jie,ZHANG Tao.Research on Chinese person name and location name recognition based on maximum entropy model [J].Journal of Chinese Computer Systems,2006,27 (9):1761-1765 (in Chinese).[钱晶,张杰,张涛.基于最大熵的汉语人名地名识别方法研究 [J].小型微型计算机系统,2006,27 (9):1761-1765.]
[3]FENG Yuanyong,SUN Le,LI Wenbo,et al.A rapid algorithm to Chinese named entity recognition based on single character hints [J].Journal of Chinese Information Processing,2008 (1):1-22 (in Chinese).[冯元勇,孙乐,李文波,等.基于单字提示特征的中文命名实体识别快速算法 [J].中文信息学报,2008 (1):1-22.]
[4]LI Nuo,ZHANG Quan.Chinese place name identification with Chinese characters features [J].Computer Engineering and Applications,2009,45 (28):230-232 (in Chinese).[李诺,张全.利用地名用字分析的中文地名识别处理 [J].计算机工程与应用,2009,45 (28):230-232.]
[5]LI Nuo.Identification and annotation of Chinese place name and temporal information[D].Beijing:Institute of Acoustics,Chinese Academy of Sciences,Master Thesis,2009 (in Chinese).[李诺.中文地名与时间的识别和标注 [D].北京:中国科学院声学所硕士学位论文,2009.]
[6]QIU Sha,A Yuan.Study on automatic recognition of Chinese location names based on statistical method [J].Computer Technology and Development,2011 (11):35-38 (in Chinese).[邱莎,阿圆.基于统计的中文地名自动识别研究 [J].计算机技术与发展,2011 (11):35-38.]
[7]LI Lishuang,DANG Yanzhong.Recognition of Chinese location names based on CRF and rules [J].Journal of Dalian University of Technology,2012 (2):285-289 (in Chinese).[李 丽双,党延忠.CRF与规则相结合的中文地名识别 [J].大连理工大学学报,2012 (2):285-289.]
[8]GU Xiaoming,ZHAI Yuqing.Design of military document understanding system based on ontology [J].Modern Computer,2006,231 (3):69-72 (in Chinese).[顾晓明,翟玉庆.一种基于本体的军用文书的理解系统设计 [J].现代计算机,2006,231 (3):69-72.]
[9]YANG Jian,GAO Wenyi,WANG Yanbo.Documents based automated military plotting method [J].Journal of PLA University of Science and Technology (Natural Science Edition),2006,7 (6):543-547 (in Chinese).[杨健,高文逸,王衍波.一种作战文书军事标图自动化方法 [J].解放军理工大学学报 (自然科学版),2006,7 (6):543-547.]
[10]JIANG Wenzhi,WANG Di.The design of key models for automatic generation of military instruction [J].Command Control &Simulation,2007,29 (6):28-30 (in Chinese).[姜文志,王迪.作战指令自动生成的关键模块设计 [J].指挥控制与仿真,2007,29 (6):28-30.]
[11]JIN Yaohong.Natural language understanding technology based on HNC theory and its application [M].Beijing:Science Press,2006 (in Chinese).[晋耀红.HNC语言理解技术及其应用 [M].北京:科学出版社,2006.]
[12]JIA Ning.Using concept primitive feature for text classification [J].Computer Engineering and Applications,2007,43(1):24-26 (in Chinese).[贾宁.使用概念基元特征进行自动文本分类 [J].计算机工程与应用,2007,43 (1):24-26.]
[13]LI Ying,CHI Yuhuan.Applications of word tendentiousness to analysis of text orientation [C]//Recent Advances in Lexical Semantic:Symposis of the 10th Chinese Lexical Semantic Workshop,2009:89-94 (in Chinese).[李颖,池毓焕.词语褒贬性在文本倾向性分析中的应用 [C]//第十届汉语词汇语义学论文集,2009:89-94.]
[14]WEI Xiangfeng,ZHANG Quan.Event sentiment analysis based on semantic chunks [J].Journal of Chinese Information Processing,2012,26 (3):44-48 (in Chinese).[韦向峰,张全.基于语义块的事件倾向性分析研究 [J].中文信息学报,2012,26 (3):44-48.]
[15]LI Ying,WANG Kan,CHI Yuhuan.Semantic chunk transformation in Chinese-english machine translation [M].Beijing:Science Press,2009 (in Chinese).[李颖,王侃,池毓焕.面向汉英机器翻译的语义块构成变换 [M].北京:科学出版社,2009.]
