云环境下大规模图像索引技术
2013-09-11韩晓光
雷 婷,曲 武,王 涛,韩晓光
(1.成都工业学院 通信工程系,四川 成都611730;2.材料领域知识工程北京市重点实验室,北京100083;3.北京启明星辰信息安全技术有限公司,北京100193;4.中关村科技园海淀园企业博士后科研工作站,北京100089;5.湖南城市学院 信息科学与工程学院,湖南 益阳413000;6.北京科技大学计算机与通讯工程学院,北京100083)
0 引 言
海量的高维数据在许多关键领域应用中快速产生,例如多媒体数据,地理信息数据,雷达数据,生物信息学数据,电子商务数据等,对此的研究也处于快速发展阶段。由于这类高维数据的规模巨大以及处理技术复杂,传统的顺序计算模型需要大量时间完成。目前,新出现的分布式计算模型Map-Reduce[1],由于良好的可扩展性和自组织性,丰富的平台支持,为高维大数据处理问题提供了潜在的解决方案。虽然Map-Reduce模型对于处理大规模数据具有很大优势,但它仅仅能够抽象独立处理单个的数据实体。而现实中的大数据应用往往并不适合直接使用这种简单模型。目前,对于Map-Reduce模型进行优化和扩展的研究范围较广,文献 [2]提出了一种改进型的Map-Reduce模型MBR模型,在一定程度上减少了整个Job的执行时间。与树形结构相关的应用普遍被用在几乎所有的计算领域。基于树形结构的应用,特别是涉及大规模数据密集型处理的情况,需要使用分布式计算和存储系统。因此,基于Map-Reduce框架的抽象树形结构是非常有帮助的,但由于树形结构及其相应算法的多样性,构建一个基于Map-Reduce框架的树形结构是非常有挑战性的。Ariel等人在文献 [3]中提出将Map-Reduce框架与R-Tree结合处理海量地理信息数据。在文献 [4,5]中,Sarje等人提出,基于 Map-Reduce计算模型进行树形结构的基本计算,例如合并,分解,选择等树形结构节点计算操作。
在Hadoop[6]环境中,树形索引结构的检索和计算抽象框架MRC-Tree框架被实现,该框架可以为树形结构及其相关算法应用提供充分的一般性。MRC-Tree框架包含需要用户指定的Map函数和Reduce函数,通过灵活组织这些函数,以多种方式实现树形结构中广泛使用的操作。同时,将存储机制、容错问题和并发问题等问题都移交给Hadoop平台管理。在MRC-Tree分布式树形框架基础上,基于KD-Tree索引结构,根据不同的建树方案,提出两种并行 化 KD-Tree的 方 法,MKDTM (build multiple KDTrees by splitting data equally based on Map-Reduce)和OKDTM (build one distributed KD-tree based on map-reduce)。最后,通过实验验证,分别从检索CPU时间、检索精度、吞吐量以及可扩展性4个方面来评估MKDTM和OKDTM树形索引结构的性能。通过理论分析和实验结果表明,基于 MRC-Tree框架,与 MKDTM索引结构相比,OKDTM索引结构具有更好的可扩展性、较高的空间利用率和检索效率。
1 MRC-Tree抽象框架
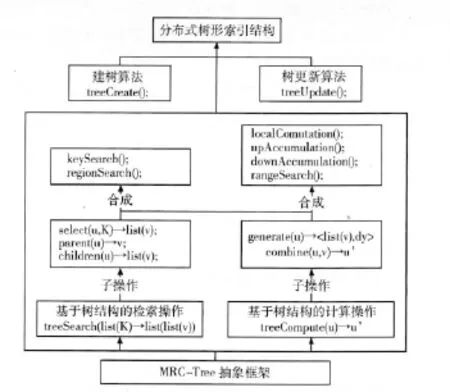
图1 MRC-Tree抽象框架
对于树形索引结构,用户可以通过父节点与子节点之间链接导航的拓扑结构来访问树节点上特定的应用信息。为了在超大的树形结构上支持数据和计算密集型应用,通过实现MRC-Tree抽象框架来提供多类并发计算,为了使算法更高效的执行,MRC-Tree抽象框架提供分布式计算方法,MRC-Tree框架如图1所示。在树形结构中,每个节点存储的信息由两部分组成:树的拓扑结构信息和特定的应用信息。树的拓扑信息,包括父节点与子节点之间的链接,节点在树中的层次等。树形结构的节点可以表示成μ,ν,ω,在节点μ中,使用元组μ=(kμ,Xμ)表示特定的应用信息,kμ为唯一的节点标识符,Xμ为存储在节点μ中的其他信息。例如,kμ可以是二叉检索树中的编号信息,八叉树中的域信息等。kμ和Xμ的数据类型是用户指定的。使用符号“→”表示MRC-Tree框架提供给用户的函数,符号 “→”表示由用户提供的函数。MRC-Tree框架包括两个关键操作,一个操作是用来表示多个检索在树形结构上并发执行,另一个操作是用来表示在树形结构的每个节点上执行计算。这两个操作都依赖于有限的用户指定函数,通过这些精心设计的函数可以实现不同类型的树及其基于树的操作。
1.1 基于树形结构的检索操作
基于树形结构的检索操作提供了自上而下的检索,从树的根开始遍历,递归向下一个或多个分支路径遍历,从一个节点遍历至另一个或更多的子节点。检索操作的结果是一个树节点列表。尽管并行执行特定类型树形结构的单次检索,一直是一个理论研究问题,为提高单次检索效率,往往是选择将数据分区索引,然后通过分布式检索算法进行检索以及结果整合。实践中往往使用并发多检索和数据分区检索相结合,可以充分利用分布式系统中的计算资源。而且对于并发多重检索问题,并行计算是非常有效的。通过检索项列表,treeSearch操作允许多个并发检索同时执行,最后以list(list(ν))方式返回所有检索结果。令K表示单一检索项,即,treeSearch(list(K))→list(list(ν))。其中,list(K)= (K1,K2,…Kn)是一个包含n个检索项的列表, 而 相 应 的 结 果 节 点 列 表 为 list(list(ν))=(list(ν1)list(ν2),…,list(νn))。操作依赖于用户指定的select函数,该函数从树形结构中取出一个节点μ,检索项K作为输入,输出一个节点列表:select(μ,K)→list(ν)。
其中,list(ν)有以下3种情况:
(1)list(ν)= (μ),这种情况下,检索停止在μ,μ被包括在检索结果集合中;
(2)list(ν)为空,检索停止,在这个检索路径上,没有节点被包含在检索结果集合中;
(3)list(ν)包含一个或多个μ的孩子。select被递归应用到list(ν)中的每个节点上。
为实现select函数,用户需要访问一个节点的孩子节点。一个节点的父节点和孩子节点分别通过以下系统指定方式获得:parent(μ)→ν和children(μ)→list(ν)。
1.2 基于树形结构的计算操作
函数treeCompute用于处理树形结构中的节点,计算节点中的信息:treeCompute(μ)→μ′。其中,μ′= (kμ,X′μ)表示更新节点μ。在更新节点μ过程中,其他节点的集合也需要被考虑。用户指定如何确定与μ相关的节点列表,并通过generate函数在μ上定义交集。使用用户指定的combine函数,合并节点μ与交集中的值,计算节点μ′。generate和combine函数定义如下:
(1)generate函数:generate函数将节点μ作为输入,返回一个包含节点μ上的交集和一个依赖标识dy。这个标识用来表明,若多个交集之间存在依赖,是否需要在函数中考虑,generate(μ)→ (list(ν),dy)。
(2)combine函数:合并函数需要指定如何合并关于节点μ的信息来计算它的更新值,这些信息来自节点μ的交集中所有节点,combine(μ,ν)→μ′。
1.3 映射树形结构操作到MRC-Tree框架
树形结构上的键值检索:对于一个可以完全有序集合,检索树被广泛用于索引集合中的键值检索。在 MRC-Tree框架上,使用treeSearch操作在检索树上实现多个检索并发执行。操作定义如下:
(1)域检索:基于Rd(d∈N)层次划分的空间树形结构种类较多,例如:四叉树、八叉树、KD-Trees、R+-Trees等。在这种情况下,检索键值K是d维空间中的一个区域,检索结果是一个叶子节点列表,其中每个节点都对应一个与K相交的区域。
(2)局部计算:树形结构中最简单的计算操作是在树的每个节点上进行局部计算,这时,无需考虑与其他节点的交集。treeCompute可以被用来简化定义generate函数,仅需要返回节点本身,同时也可以简化combine函数的计算
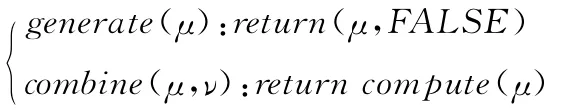
(3)向上聚类:是指对树中每个节点的数据聚类从它的后裔节点开始。并不直接从内部节点子树的所有叶子节点开始计算聚类,这样代价较大,而采用从节点孩子的聚类值进行计算。要做到这一点,在计算父节点的聚类之前,首先需要计算孩子节点的聚类值。为实现这种操作,将一个节点的交集定义为它的孩子,同时在函数generate中,将dy标识设为true。函数combine定义每个孩子节点的聚类操作,由⊕表示

(4)向下聚类:与向上树形结构聚类相反,向下树形结构聚类是指对树中每个节点的数据聚类从它的祖先节点开始。要做到这一点,首先取得一个节点父节点的聚类值,然后同当前节点值合并。为实现这种操作,generate函数被要求返回父节点,以及将dy标识设为true,数据聚类操作⊕,被定义在combine函数中
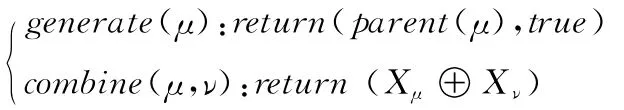
(5)范围检索:对于一个空间树形结构,树中每个节点都对应着Rd空间中的一个盒子。假设需要在树的每个节点上执行计算,计算使用的是与中心节点的距离范围为[d1,d2]的同层所有节点。
2 MKD-Tree
Kd-Tree是一种根据K维空间中的点集对空间进行分割的数据结构,采用多维索引值进行查找,常用于范围查找和最近邻查找等,是一种特殊的二叉空间分割树。在高维空间检索,特别是图形检索,诸如碰撞检测,遮挡剔除,游戏以及光线追踪等领域[7,8]应用广泛。本文基于 MRCTree框架,提出两种并行化KD-Tree的方法,MKDTM(build multiple KD-trees by splitting data equally based on map-reduce)和 OKDTM (build one distributed KD-tree based on map-reduce),如图2所示。
(1)MKDTM:如图2 (a)所示,并行化 KD-Tree最简单的方式,首先根据计算节点个数将数据集均匀切分为独立的n-1块 (1个根计算节点,n-1个子计算节点),近似保证每个数据块适合子计算节点的主存。接下来,为每个数据块在子计算节点上分别建立一个独立的KD-Tree。检索过程中,根计算节点接受目标检索特征向量,并将特征传递给所有的子计算节点,然后收集返回结果并整合,输出最终排序好的结果;
(2)OKDTM:如图2(b)所示,该方法并行化过程中仅仅建立一棵KD-Tree,其上部位于根计算节点,下部被切分到各个子计算节点,存储特征的叶子节点也位于这些子节点上。检索过程中,根据KD-Tree遍历退出位置,根计算节点引导目标检索特征向量到相应的子计算节点。子计算节点根据相应的KD-Tree子树计算最近邻,返回结果给根计算节点。最后,根计算节点进行结果整合排序,输出最终排序好的结果。

图2 分布式KD-Tree索引结构
显然,OKDTM最大的优点是对于单个特征向量仅需要访问少量子计算节点。因此,子计算节点可以同时并行处理多个特征向量,大部分计算都发生在子计算节点中,文献 [9]已经证实该方法是合理的。随着子计算节点数量的提高,根计算节点将会成为瓶颈,本文通过引入多个根计算节点副本来解决此问题。建立适用的OKDTM面临两个主要挑战:①如何建立一个包含超高维特征向量 (成千上万维)的KD-Tree,这种情况下,在单一计算节点上建立KD-Tree是不可行的;②在OKDTM上如何实现回溯。本文通过以下两个方案来解决这两个问题:
(1)OKDTM并不是在单个计算节点上建立KD-Tree,而是在根计算节点上建立一个特性分布树,即KD-Tree的上层。这是因为数据量庞大且维度较高,不可能在单个节点上满足特征向量所有维度,可以采取简单的对特征进行抽样,并在单个计算节点上使用尽可能多的内存。通过计算KD-Tree建树算法抽样的均值,上面的方法并不会影响最终KD-Tree的性能;
(2)OKDTM方法仅在子计算节点上执行回溯算法,根计算节点无需回溯。为判定需要访问哪个子计算节点,需要计算到切分点之间的距离,如果距离低于判定阈值,将该计算节点包含到下一步需要处理的过程中;
基于MRC-Tree框架实现 MKDTM和OKDTM,如图3所示,主要分为两个阶段:
(1)分布式建树阶段:特征向量Map-Reduce将向量集合切分到各个子计算节点,接下来通过索引Map-Reduce在各个子计算节点建立不同的KD-Tree。
(2)分布式检索阶段:通过分配Map-Reduce将目标特征向量分配到合适的子计算节点,然后通过匹配计算Map-Reduce检索相应的KD-Tree,并进行结果收集和整理,最后输出结果。

图3 基于Map-Reduce的分布式KD-Tree机制
对于MKDTM建树方法,如算法1所示,实现比较直接的。在分布式KD-Tree建立阶段,特征 Map-Reduce是空的,即无需任何操作,索引Map-Reduce根据分组后的特征向量集合并发建立各自的KD-Tree。在此过程中,Map通过Id对特征属性向量集合进行分组并分配到各个子计算节点,而Reduce根据分配给各个子计算节点的特征向量集合分别建立KD-Tree。在分布式检索阶段中,分配 Map-Reduce将目标特征属性向量发送到所有的子计算节点 (所有的KD-Trees)。匹配计算Map-Reduce过程中,Map负责并发遍历每个计算节点的KD-Tree,Reduce负责结果收集和排序。算法2阐述了OKDTM实现过程。与MKDTM方法最显著的区别在于特征Map-Reduce阶段,OKDTM方法在该阶段建立了KD-Tree的上层。根据子计算节点的个数M,KD-Tree 上层的深度应该为log2M,即保证至少有M个叶子节点。特征Map通过调用Emit函数抽取输入特征向量样本,抽取规则为每隔skip个输入特征抽取一个样本。特征Reduce使用这些样本建立KD-Tree。索引Map-Reduce建立M个子树作为KD-Tree的下半部分。其中,索引Map引导特征属性到KD-Tree相应的位置 (即相应的子树),这将是上部分KD-Tree的第一个叶子,也是检索过程中目标特征向量首次到达的深度。接下来,索引Reduce根据所获得的特征向量集合分别建立相应的子 (叶子)KD-Tree。在检索阶段,分配Map-Reduce根据目标特征向量到切分点之间的距离是否低于阈值St,决定将其派发到若干个相应的子计算节点。紧接着,匹配计算Map-Reduce在子计算节点(即子KD-Tree)执行检索操作,并进行结果收集和排序。

?

?
3 实验验证及性能分析
这部分将显示和讨论分布式KD-Tree索引结构在IBM集群上获得的实验结果,如图3所示。在实验过程中,由于分布式环境对外提供其他计算服务,本文实验过程是与其他程序共享分布式资源,因此,在实验结果上可能会出现小幅波动。分布式环境构成:一个Master管理节点服务器,八个刀片服务器 (HS21)计算节点,一套8T磁盘阵列 (IBM DS3400)存储,具体软硬件配置如下:
(1)Master管理节点服务器:两颗英特尔四核至强E5420 2.5GHz/EM64T,12MB L2 缓 存),配 置 8GPC2-5300CL5ECC DDR2 667MHz内存;3块146G硬盘;
(2)刀片服务器 (HS21)计算节点:两颗四核Intel Xeon E5430(2.66GHz,12MB L2,1333MHz FSB,80W),8GB (4*2GB)PC2-5300FB-DIMM 内 存,1 块 146GB 10KSFF SAS Fixed HDD,双千兆以太网;
(3)磁盘阵列:DS3400磁盘柜 Single Controller,8*1T;
(4)软件系统:操作系统,RadHat Linux 5.3,64位;开发环境,NetBeans IDE 6.5和 Karmasphere Studio;分布式编程工具,Apache Hadoop;Hadoop-0.20.203.X。
3.1 数据集
在实验中使用两个不同统计类型的测试数据集,每种数据集都包括两种不同类型图像,如图4所示。

图4 数据集描述
(1)测试集:已经进行标注的图像,作为参照目的。这个集合中的每个对象包括两种类型的图像:基准图像,表示要被检索的真实图像,用来验证检索结果的正确与否;测试图像集,用来查询数据库,表示与基准图像相近,由基准图像经过变换后的图像,例如不同视角、光照条件、缩放比例等;
(2)干扰集:表示构成查询数据库的大部分图像,尽管这些图像在一定统计意义上与测试图像有联系,事实上与测试图像集无关。算法必须能够识别并过滤掉这些混乱和扭曲图像,并找到基准图像。在现实的图像集构造过程中,这个集合将包括所有与基准图像语义相近的图像,如图4所示,例如,与基准图像相近的语义是标注为建筑类的图像。
实验过程中,使用一个Holidays图片集测试分布式KD-Tree索 引 结 构 的 性 能。Holidays[10](1491 幅 图 片,4456个描述器,500个检索),这个数据集主要包含假日旅游的图片。扰乱数据集使用Flickr旅游图片,通过使用Flickr站点检索引擎,检索关键字为 “travel”和 “Holiday travel”,获取总计达1M张各种类型的假日旅游的图片 (自然,建筑,大海和火山等)。最后,该数据集总计1M张图片,500个检索图片,每个图片平均有1500个描述特征。对于所有图片,总计特征为15亿。在本文中,图片特征提取方法使用SIFT算法[11]。使用下面公式进行检索精度评估
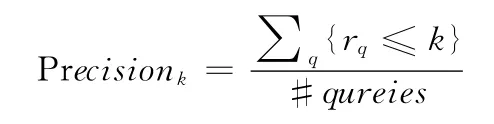
该公式表示,检索返回的Top-k个图片中包含基准图像在检索总次数中所占的比例。其中,rq表示基准图像在检索结果中的排名,若{rq≤k}为真,则{rq≤k}=1。
对于分布式KD-Tree,为了权衡精度和检索时间,本文限定了每个特征的回溯范围,而且这个范围由所有KDTree子树共享。例如,对于 MKDTM,回溯限定为B=3K,如果一个特征有两个子计算节点,则每个使用1.5K,若是3个子计算节点,则是1K。对于具有M个子计算节点的OKDTM,每个节点使用B/M个回溯步骤。
3.2 性能分析
实验中,通过改变分布式KD-Tree索引系统中计算节点的个M,其中2≤M≤8、距离阈值d,其中0.05≤d≤0.3、回溯步骤数Nb,其中512≤Nb≤30 K、图片规模Ns,其中1 K≤Ns≤10 M、检索图片次数Nr,1≤Nr≤150来调节、测试和分析分布式索引结构的性能。
首先,使用1M图片数据集,测试不同的参数对与分布式KD-Tree性能的影响:距离阈值d、回溯步骤数Nb和子计算节点个数为M。如图5所示,随着距离阈值的增大,OKDTM将会访问更多的子 (叶子)计算节点,由于回溯步骤Nb是固定的,叶子节点的子树不能够访问足够深度,因此检索精度会逐渐降低。而由于回溯步骤确定,检索CPU时间没有明显变化。而对于MKDTM,距离阈值变化并不会影响需要访问的子计算节点,因此预测精度不会变化,检索时间会随之略微下降,因为这是显而易见的,图中并没有画出。如图6所示,随着回溯步骤的增大,子 (叶子)计算节点的个数是固定的,访问叶子节点的深度会随之增大,检索精度也随之提高,检索CPU时间也随之提高;显然,随着回溯步骤的增大,OKDTM在检索精度和检索CPU时间方面,与MKDTM相比更具优势。如图7显示图像规模增长对这两种索引结构的影响。随着图像规模的增大,树的深度会随之提高,由于回溯步骤、计算节点个数和距离阈值的恒定的,所以预测精度随之下降,检索CPU时间呈上升趋势,吞吐量,对于两种方法,在峰值之前都成上升趋势,显然OKDTM的吞吐量远高于MKDTM,而且当图像规模为10M时,OKDTM吞吐量继续呈上升趋势,而MKDTM开始下降。显然,与MKDTM相比,OKDTM具有更高的检索精度、更低的CPU时间代价和更高的吞吐量。如图8所示,随着计算节点个数的增大,回溯步骤、数据集规模和距离阈值都恒定的情况下,OKDTM的预测精度和检索CPU时间几乎不变,吞吐量明显提高;对于MKDTM,预测精度下降,检索CPU时间提高,吞吐量也相应提高,但提高幅度没有OKDTM明显;对于OKDTM,树顶层的层数在特征 Map-Reduce阶段被构造。对于MKDTM,定义了图像数据集被分组的个数。对于相同数目的计算节点,OKDTM的总体性能 (检索精度,检索CPU时间和吞吐量)优于MKDTM。特别是,随着计算节点的个数增长,OKDTM的检索CPU时间几乎不变,而MKDTM呈增长趋势。这是因为,尽管回溯步骤被分布到所有机器上,特征向量仍然需要拷贝并发送到所有计算节点上,内存拷贝需要耗费大量CPU时间。同时注意到,吞吐量也随着计算节点的个数增加而增加,OKDTM的吞吐量远远大于MKDTM。图9显示,不同Top-k的k值对于检索精度的影响,k的范围是从1-150。显而易见,随着k值增大,检索精度随之提高,而且图像规模越小检索精度越高。因为,从10M图像库中查找一幅图像,命中正确图像的概率为10-7。显然,数据库规模越大,命中概率越低,检索精度越低。
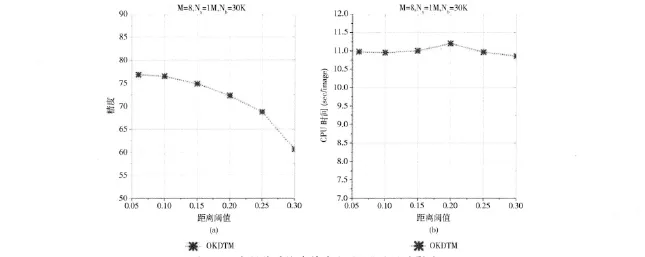
图5 距离阈值对检索精度和CPU时间的影响

图6 回溯步骤对检索精度和CPU时间的影响

图7 图像数据库规模对检索精度、CPU时间和系统吞吐量的影响
4 结束语
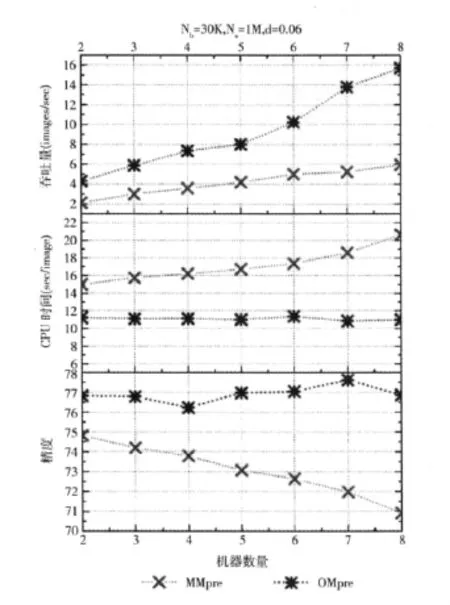
图8 计算节点个数对于检索精度、CPU时间和系统吞吐量的影响
在Hadoop环境下,基于Map-Reduce模型,本文为树形结构的检索和计算实现一个高层次的分布式架构,MRC-Tree。尽管树形结构及其应用在上面的算法类型多种多样,本文实现的抽象方法可以为更广泛的应用提供充分的一般性。然后,基于 MRC-Tree框架,根据原始的KD-Tree索引结构,本文实现了两种分布式KD-Tree索引结构构建方法,OKDTM和MKDTM,通过理论分析和实验结果表明,基于MRC-Tree框架的分布式KD-Tree索引结构具有良好的可扩展性和较高的检索效率。而且实验结果表明,OKDTM结构比MKDTM具有更好的性能。
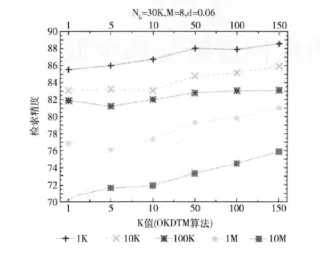
图9 Top-k查询中k值和数据集规模对检索精度的影响 (OKDTM算法)
[1]Dean J,Ghemawat S.Map-reduce:Simplified data processing on large clusters[J].Commun ACM,2008 (51):107-113.
[2]LI Yulin,DONG Jing.Study and improvement of MapReduce based on hadoop [J].Computer Engineering and Design,2012,33 (8):3110-3116 (in Chinese).[李玉林,董晶.基于Hadoop的MapReduce模型的研究与改进 [J].计算机工程与设计,2012,33 (8):3110-3116.]
[3]Cary Ariel,SUN Zhengguo,Hristidis Vagelis,et al.Experiences on processing spatial data with MapReduce[C]//Proceedings of the 21st International Conference on Scientific and Statistical Database Management,2009:302-319.
[4]Abhinav SARJE,Srinivas ALURU.A map-reduce style framework for trees[R].Technical Report,2009.
[5]Abhinav SARJE.A map-reduce style framework for computations on trees[C]//39th International Conference on Parallel Processing,2010:343-352.
[6]Lam Chuck.Hadoop in action [M].Manning Publications,2010.
[7]GUO Jie,XU Xiaoyang,PAN Jingui.Build KD-Tree for virtual scenes in a fast and optimal way [J].Acta Electronica Sinica,2011,39 (8):1811-1817 (in Chinese). [过洁,徐晓旸,潘金贵.虚拟场景的一种快速优化KD-Tree构造方法 [J].电子学报,2011,39 (8):1811-1817.]
[8]Aly Mohamed,Munich Mario,Perona Pietro.Indexing in large scale image collections:Scaling properties and benchmark[C]//Proceedings of the IEEE Workshop on Applications of Computer Vision,2011:418-425.
[9]Jegou H,Douze M,Schmid C.Hamming embedding and weak geometric consistency for large scale image search[C]//ECCV Proceedings of the 10th European Conference on Computer Vision:Part I,2008,304-317.
[10]Silpal Anan C,Hartley R.Optimised KD-trees for fast image descriptor matching[C]//IEEE Conference on Computer Vision and Pattern Recognition,2008:1-8.
[11]Beril Sirmacek,Cem Unsalan.Urban area and building detection using SIFT keypoints and graph theory[J].IEEE Transactions on Geoscience and Remote Sensing,2009,47 (4):1156-1167.
