运用聚类算法预测地区电网典型日负荷曲线
2013-08-31李翔,顾洁
李 翔,顾 洁
(1.上海市电力公司 浦东供电公司,上海 200122;2.上海交通大学 电气工程系,上海 200240)
0 引言
电力系统负荷曲线的变化过程是一个非平稳的随机过程。以不同的时间维度分析,负荷曲线的变化呈现1天、1周、1月以至1年的变化周期。
日负荷曲线是表示负荷需求在1昼夜内随时间变化的特性曲线。日负荷曲线预测是根据电力负荷、经济、社会、气象等历史数据,分析电力负荷历史数据变化规律,对未来负荷的影响寻求电力负荷与各种相关因素之间的内在联系,从而对未来某1天的日负荷曲线进行科学的预测。随着电力系统对数据挖掘的不断深入和信息采集功能的不断提升,大量、丰富的历史负荷数据为科学决策提供了依据[1-3]。
1 聚类模型
建立日负荷曲线预测的聚类模型时,主要考虑历史数据的预处理、初始聚类中心的设置、最优聚类数目的确定等问题。
1.1 历史数据的预处理
日负荷曲线的变化具有一定的周期性。例如:同一季节内的日负荷曲线与当日的星期类型有较强的关联,不同年份的季节典型日负荷曲线具有很高的相似性。因此,考虑对日负荷曲线的历史样本进行聚类,进而对所形成的各类样本进行变化特征挖掘,所得的结果能够比对日负荷曲线进行独立分析,更好地反映出本质变化规律。所以,日负荷曲线预测的聚类模型,必须建立在充分的历史数据样本基础上。
目前,大多数电力系统都能够提供包括若干年内每一天整点时刻的日类型、负荷以及温度、降水量、湿度等气象因素的历史数据积累,可以据此进行建模分析。其中日类型可以分为工作日和非工作日,作为预测模型的自变量,进行建模时前者用1表示,后者用0表示。而负荷和气象因素的绝对数据的数量级从100~103不等,计量单位也不统一,因此必须对数据的样本先进行归一化处理。
气象因素的归一化表达式为:

假设历史数据中负荷最大值为Pmax,第h时刻的负荷为Ph(h=1,2,…,t),以Pmax采用式(2)对负荷曲线进行归一化处理:
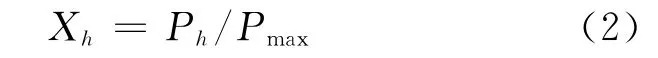
式中:Xh为归一化后的负荷曲线第h时刻的值。
1.2 聚类算法的选择
K均值聚类算法是一种常用的动态聚类算法,其实现过程是首先选择聚类中心,对样本作初始分类,再根据聚类准则,判断聚类是否合理,不合理就修改聚类,直至合理为止。相对于经典的无监督聚类算法而言,K均值聚类算法具有简化计算、加快收敛速度等特点,本文采用此算法对历史数据进行分析。
采用误差平方和函数作为聚类准则[4,5]:

式中:wi为类Ri的聚类中心;j为样本编号;xj为待聚类日的相关因素构成的向量;N为样本数;c为最初指定的聚类中心个数;dji为第j个样本是否属于第i类。
将dji定义为:
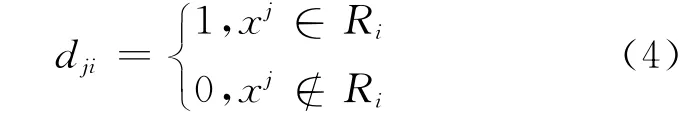
K均值算法可得到使误差平方和准则取得极小值时的聚类结果。
1.3 初始聚类中心的设置
K均值聚类算法是一种基于划分的聚类算法,目的是通过在完备数据空间的不完全搜索,使得目标函数取得最大值(或最小值)。由于局部极值点的存在以及启发算法的贪心性,该算法对初始聚类中心敏感,从不同的初始聚类中心出发,得到的聚类结果不一定相同,并不一定保证得到全局最优解。因此,怎样找到一组合适初始中心点,从而获得一个较好的聚类效果并消除聚类结果的波动性,对K均值聚类算法具有重要意义。
本文采用文献[6]介绍的解决方法:
① 算出样本总体的算术均值;
②找出所有样本到算术均值的最大距离max_d和最小距离 min_d;
③ 将(max_d-min_d)平均分成c等份,这样将形成c个区间,c为聚类数目;
④ 每个样本到均值的距离,将唯一地落在某个区间内,并据此把样本分成c类;
⑤ 每一类的算术均值作为初始聚类中心。
经验证,采用上述方法,可以使初始聚类中心的分布尽可能地体现数据的实际分布,获得较好的聚类效果。
1.4 最优聚类数目的确定
设置不同的聚类数目得到的聚类结果会有所差异,为了得出最优的聚类数目,需要对不同聚类数目的聚类结果进行评价,评价的内容主要是聚类的密集性和邻近性。
聚类密集性是一种有关聚类内方差的测量,方差越小说明数据集的同一性越高。给定一个数据集X,其簇内方差被定义为:


对聚类输出结果c1,c2,…,cc,聚类密集性被定义为:

式中:C为聚类个数;var(ci)为簇ci的方差。
每个聚类内的成员应尽可能地接近,所以聚类密集性越小越好。但是在极端情况下,当每个输入矢量被分为单独的类时,聚类密集性有最小值0。
聚类邻近性被定义为:

式中:σ为高斯常数,简化计算时取2σ2=1;xci为聚类ci的中心;d(xci,xcj)为聚类ci中心与cj中心之间的距离。
各聚类应有效地分开,且聚类邻近性反比于聚类间距离,所以聚类邻近性越小越好。然而,当整个输入矢量被聚为一个类时,聚类邻近性有最小值0。
为了评价一个聚类系统的综合质量,可将上述聚类密集性与聚类邻近性组合为一种评价方法,称作聚类综合质量。它被定义为:
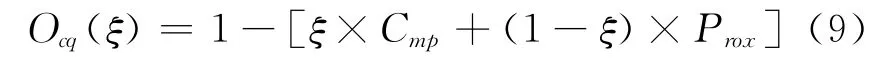
式中:ξ∈[0,1]为平衡聚类密集性与聚类邻近性的权值。例如,Ocq(0.5)表示两种评价有相等的权值。
显然,聚类综合质量越大越好。对于不同的给定聚类数目,分别算出每种聚类结果的聚类综合质量,该指标最大的聚类结果所对应的聚类数目即为最优聚类数目。
2 聚类结果的利用
对历史数据的聚类完成后,需要利用聚类的结果以及待预测日的相关参数预测出该日的日负荷曲线。待预测日的日类型是已知条件,其温度、降水量、湿度等气象因素可以通过气象部门获得,因此可计算待预测日的特征向量与各个类的相关程度,找出相关程度最大的类,待预测日的日负荷曲线即取为该类内每一天的日负荷曲线的平均值。
评价待预测日特征向量与各个类的相关程度可以用灰色关联度分析法。
设参考数列为X0,被比较数列为Xi,而且

则关联系数定义为:

式中:ΔXk=|X0(k)-Xi(k)|为第k个点X0与Xi的绝对误差为2级最小差为2级最大差;ρ为分辨率,0<ρ<1,一般取0.5。
综合各点的关联系数可得出整个Xi与参考曲线X0的等权关联度为:

3 日负荷曲线预测的聚类模型解算流程
日负荷曲线预测的聚类模型解算流程如图1所示。

图1 日负荷曲线预测的聚类模型算法流程图
4 典型日负荷曲线预测算例与分析
4.1 预测结果
以上海电网为研究对象,利用该电网2005年至2008年日负荷曲线及气象参数等历史数据,分别预测了2009年春夏秋冬4个季节的典型日负荷曲线,其中典型日的选取是按照当地电网长期以来的惯例,即春季、夏季、秋季和冬季的典型日分别选取每年的4月15日、夏季最高负荷日、10月15日和冬季最高负荷日,上述典型日如遇上节假日或周末则相应顺延。由于篇幅所限,仅给出2009年春季、夏季、秋季和冬季典型日负荷曲线的聚类模型预测结果。

图2 春季典型日负荷曲线

图3 夏季典型日负荷曲线

图4 秋季典型日负荷曲线

图5 冬季典型日负荷曲线
4.2 预测结果分析
预测结果表明:
1)大部分点的误差在3%的允许范围内2009年春季、夏季、秋季和冬季典型日负荷曲线表明,误差超过3%的点和待预测日相邻几天的对应点相比,差别基本上小于3%,说明这些点的误差主要是由突变因素造成的。
2)春季和秋季的预测误差明显小于夏季和冬季 这是因为上海地区春季和秋季的负荷特征主要为基本负荷,与气温、降水、湿度等气象因素关系不大,年间变化较小。而夏季有大量的降温空调负荷,冬季有大量的供暖空调负荷,它们均和气象因素特别是温度有很大关系,容易因气象因素的突变而发生剧烈变化。
5 结论
日负荷趋势预测是一项重要工作,也是电力系统安排日调度计划,决定开停机计划、经济分配负荷及安排旋转备用容量的基础,还可为研究电力系统的峰值、抽水蓄能电站的容量以及发输电设备的协调运行提供基础数据。而日负荷曲线预测的精确度和可信度,直接影响着电力系统运行的经济效益。
利用数据挖掘理论建立了日负荷曲线预测的聚类模型,以上海电网为研究对象,用该模型成功预测了2009年上海地区各季度典型日的日负荷趋势曲线,并对结果进行了分析。
从结果分析可以看出,模型较为全面地考虑了对日负荷曲线有显著影响的因素,包括日类型及气温、降水量、湿度等气象因素,较为准确地得出日负荷曲线预测结果,对于电力系统的运行及规划具有重要的参考价值。
[1]康重庆,夏清,刘梅.电力系统负荷预测[M].北京:中国电力出版社,2008.
[2]Park DC,Sahrawi M A,Marks R J,et a1.Electric Load Forecasting Using Artificial Neural network.IEEE Trans on Power Systems,1991,6(2):442-449.
[3]牛东晓,曹树华,赵磊,张文文[M].北京:中国电力出版社,1988.
[4]程其云.基于数据挖掘的电力短期负荷预测模型及方法的研究[M].北京.重庆大学,2004.
[5]姜飞,龙子泉,林峰.模糊神经网络在电力短期负荷预测中的应用[J].控制理论与应用,2003,22(8):23-26.
[6]艾学勇.地区电网典型日负荷曲线预测方法研究[学位论文].上海,上海交通大学,2009.
