面向产品创新设计的专利文本分类研究
2013-08-27梁艳红檀润华马建红
梁艳红,檀润华,马建红
1 问题的提出
创新是企业生存与发展的关键,产品创新设计需要以知识为基础。产品创新设计过程是一种复杂的运用知识与经验的创造性活动过程,不再仅仅依赖于某领域狭窄的有局限性的知识,而是越来越需要跨学科、跨领域的知识,真正较强的创新是利用各个领域中的知识来解决特定领域中的问题。
产品创新设计领域最重要的理论之一——发明问题解决理论(Theory of Invention Problem Solving,TRIZ)认为,不同的发明创造往往遵循共同的规律,类似的问题和技术发明原则与解决方法在工业生产和科学研究中会反复出现。TRIZ理论将这些共同的规律归纳成40个发明原理,每一个发明原理是适用于不同领域、具有普遍意义的规律,针对具体的技术矛盾,可以基于这些发明原理、结合工程实际寻求具体的解决方案[1-2]。TRIZ理论解决技术冲突的一般过程是:当产品设计任务提出后,对产品需求进行分析,将待解决的问题转化为TRIZ一般问题,确定设计中的冲突;然后应用冲突矩阵找出相应的发明原理;最后设计人员在发明原理的指导下将待解决问题演绎为最终解决方案。设计人员在找到解决技术冲突的发明原理后,通过分析研究这些发明原理,寻找特定问题的特定解,将使得创新工作更有条理和可预见性。
然而,这些通用的发明原理未针对具体领域,其表达方法是描述可能解的概念,都是一些概括性相对较高的术语,不易理解,因此在最后一步——演绎成最终解决方案时,限于设计人员的知识积累和专业水平,总感觉到有一定的难度,有着难以逾越的知识“鸿沟”,如图1所示。Altshuller指出,一个人在着手解决高水平的发明问题时,他理应具有全部的技术知识、物理知识和化学知识[3]。然而,作为常人来说,不可能对各种专业知识都通盘了解,掌握几乎全人类的知识基础。因此,跨越这道知识“鸿沟”是TRIZ使用者的一个难点。要跨越这道“鸿沟”,关键在于知识的获取,如果设计人员能有包含相应发明原理的专利做参考,从中获取显性知识,结合自己已具备的隐性知识,则将有助于形成特定解。

专利既是创新的成果,又是扩展设计知识空间、促进产品创新的重要知识资源,是具有创新性和实用性特点的一种知识载体,它涉及到几乎所有技术领域的最新、最活跃的创新技术信息。国外统计资料表明,专利信息对新技术的报导比其他类信息(如学术论文)平均早3~5年,许多发明创造成果仅出现于专利文献中。据世界知识产权组织的调查,有90%~95%的世界发明以专利形式发布,其中80%并未记载在其他文献中,有效利用专利知识资源,可缩短60%产品研发时间,节省40%研发经费[4]。全世界现有超过4 000万件专利文献,每年约有80万件发明申请专利,这些专利数据大多能通过Internet获取,因此专利可望成为最具影响力的设计知识资源之一。
网上有很多专利库,使人们可以方便地在网上检索到专利。然而,目前专利的分类体系大多采用国际专利分类标准进程间通讯(Inter Process Communication,IPC)等,都是根据专利描述对象的所属工程领域来划分的。但从产品创新的角度看,以工程领域为分类标准进行专利分类,对有效地利用专利有很大的局限性。由于不同工程领域有许多相似问题,它们的解也常常是相同的。研发人员不仅需要在自身工程领域中寻找专利的发明技术,更需要在其他领域寻找利用相同的方法来解决类似技术矛盾的发明技术,激发创新灵感,这就需要按照新的分类标准重新对专利进行分类。
除此之外,现有的专利分类是依靠专家人工阅读专利文献来完成的,专利文献的急剧增加使人工分析专利需要耗费的人力和物力增多,而且专家自身知识的不统一也难以保证分类的一致性和准确性。因此,专利的分类标准和手段都亟待改进。
在此背景下,研究有效和快速地获取专利知识的方法,使之服务于产品创新设计,是必须面对的课题。本文应用文本挖掘技术,以发明原理为分类标准,对专利进行自动分类的研究,其目的是为了提高创新设计过程中专利知识使用的质量和效率,使设计人员在现代设计理论和方法的指导下,从各个领域的专利文献中抽取有用的信息,打破思维定势、拓宽设计思路,有效地提高创新设计能力。
2 专利文本分类的技术基础
专利文献是专利信息的载体,面向产品创新设计的专利文本分类以专利文献为研究对象,以发明原理为分类标准,以创新设计知识需求为目标导向。
2.1 专利文献的组成结构和知识表达
专利文本目前存在的格式,主要是tiff图像格式和html格式。与其他信息资源的表达方式不同,专利文献一般具有相对统一的组成结构,例如美国专利文献主要包括以下内容:
(1)标题(title) 一般是产品或结构的名称,有些专利标题中还包含手段功能。
(2)摘要(abstract) 一般概括描述解决方案的组成结构、用途或目的、采用或舍弃的方法或技术、原理、效应以及专利人对专利的评价等。通常,一篇专利的摘要由上述6项内容或者这6项内容中的几项构成。
(3)权力要求书(claims) 是申请人请求专利保护的范围,一般含有专利的结构特征。
(4)说明书正文(description) 清楚完整地描述发明创造的技术内容,说明书正文每部分均以小标题引导,一目了然。一般包括:
1)发明背景(background of the Invention)指明本发明所属的技术领域、现有技术状况和存在的不足,以及解决问题的方法和要达到的目的。
2)发明概要(Summary of the Invention) 概述本发明的内容,说明发明专利含有方案的原理效应和结构特征。
3)附图简介(Brief Description of the Drawings) 简要说明附图的参看方法。
4)最佳方案详述(Detailed Description of the Preferred Embodiment) 专利文献中最详细、完整、清晰地阐述发明内容的部分,主要描述专利的目的、手段功能、解决方案的组成结构、原理效应及其优缺点等,提供解决技术问题的最佳方案。
其中,摘要、权利要求书以及说明书正文等在专利文献中是显而易见的,都以标题的形式有着明确的标志;而专利的知识结构——解决方案的组成结构、发明原理和技术的发展趋势等,也都包含在专利文献中,但没有明确标志,是蕴含在专利内容中的。
2.2 专利代表成分选择
利用计算机对专利进行分类,需要处理大量的文本内容,将整篇专利内容都进行分析,则文本长度庞大,不仅会大大增加计算机的计算量,并且实验证明其分类效果反而不好。因为专利中的信息繁杂,不同部分往往从不同的角度反映该篇专利的信息,如专利的背景主要说明同类或相关技术的背景和存在的问题,专利的权利要求部分则主要说明该专利所要求的法律保护部分。当选用专利的组成结构过多时,会产生过多的干扰信息,最终影响分类结果。因此需要将每篇专利内容进行分割,适当地选择专利中的某个或某些部分的组合代表专利中的技术信息。
究竟应选择专利的哪些部分代表专利信息,要具体问题具体分析,国外学者已进行了一定研究。Fall等[5]根据专利IPC分类标准对美国专利进行自动分类的研究中,分别用专利的标题、权利要求和专利文本的前300个单词代表整篇专利做实验,发现专利的标题对专利分类的影响很大,而专利的权利要求对分类效果的影响并不明显,专利文本的前300个单词能取得较好的分类效果。Chen等[6]认为摘要是专利中最重要的部分,并在从语义的角度对专利文献检索系统的研究实验中应用专利的摘要代表整篇专利信息。Tseng等[7]在应用文本挖掘技术进行专利分析的研究中,将一篇专利分为摘要、发明领域、发明背景、发明总结、最佳方案描述和权力要求6个部分。除权力要求外,分别选取其他五部分前面的几个语句进行组合代表整篇专利的信息,与整篇专利做为实验内容进行比较,分析得出结论:实验目的、不同选取的组合方式不同,最后效果也不同。Cong和Tong[8-9]在面向 TRIZ用户进行专利分类的研究中,将专利标题和摘要组合,作为整篇专利信息的代表,研究结果表明,这种组合方式的专利成分中所蕴涵的信息能较好地体现TRIZ发明原理。
涉及到分类问题,专利代表成分的选择与分类角度有关。在人工分析专利所蕴含的发明原理时,考察专利文献中的不同部分,发现摘要大都能揭示出解决冲突所用的发明原理。因此,本文采用两种专利成分选择方案代表整篇专利信息进行实验:①标题和摘要;②标题、摘要和发明概要,如果专利文献中没有发明概要这一部分,则用专利的说明(description)来代替。
2.3 发明原理的选取
本文对专利文本的自动分类采用的是基于统计的方法,利用的是描述专利的文本信息。通过分析40个发明原理的英文解释,发现有的发明原理是隐含在专利内容中的,很难从字面意义上进行判断,如3号发明原理——local quality。而有的发明原理却有很明显的描述性文本信息,对发明原理有较明显的暗示作用,如表1所示。收集专利样本并人工分析专利所应用的发明原理时,发现有明显的描述性文本信息的发明原理所对应的专利内容也经常包含相应的描述性信息,如美国专利US6626874应用了1号发明原理,该发明原理的描述性信息中有portion,comprise或divide等单词,专利US6626874内容里也有portion这个单词。

表1 有明显描述性信息的部分发明原理
在着手数据准备时,本文从美国专利商标服务局USPTO网站上的专利数据库中(http://patft.uspto.gov/)随机下载了600份专利,分析所应用的发明原理,根据发明原理对专利进行了人工分类。这种分类是在单标签假设的前提下,假设每个专利仅包含一个发明原理。然后从对应的专利数量比较集中并且有明显描述性文本表示信息的发明原理中选出了10个(发明原理的标号分别是1,7,10,14,15,17,28,31,35和40)做为本文要分类的类别。
2.4 专利样本集的收集
对专利进行分类属于文本分类的范畴,需要将已经标记好类别的数据集作为分类样本,这是分类的基础。目前,还没有现成的以发明原理为分类标准的专利文本集,本文根据需要人工构建了用以分类的专利样本集。
对下载的600份美国专利,人工分析每份专利所包含的发明原理,如果一份专利不仅包含一个发明原理,则选择其主要的发明原理并做好类别标记。接下来根据发明原理将这些专利分类,确定每个发明原理对应多少份专利,再从中选出上文提到的10个发明原理所对应的专利。本着尽量使选出的各条发明原理所对应专利的数量比较平均的原则,总共选出了293份专利做为样本集。与文本分类方法类似,将样本集按照大约2∶1的比例分为训练样本集(简称训练集)和测试样本集(简称测试集)。训练集用于分类模型的学习,建立分类器;测试集用于测试、评价分类器的性能。每篇专利的下载存储均为文本格式(编码为ANSI),把训练样本和测试样本分别存储到不同的文件夹中,并分别建立训练样本和测试样本的索引文件。
3 面向创新设计的专利文本分类系统实现
3.1 面向创新设计的专利文本分类过程
专利文本分类的过程主要包括学习过程和分类过程两大部分。其中,学习过程又分为训练过程和测试过程。在训练过程中根据训练集(已预知类别的专利文本)学习建模,构建分类器;在测试过程中应用分类器对测试集(已预知类别的专利文本)进行分类,得到测试结果,并反馈给分类器,改进训练方法以提高分类器的性能,如此反复,直至达到预定的目标。学习过程是一个需要不断反馈、改进和反复进行的过程。分类过程是利用学习过程最终生成的分类器对新专利文本(类别未知)进行分类,得到其所属类别的过程。分类过程和学习过程的测试过程大部分是相同的,都通过分类器生成分类结果,只不过测试过程还需要根据分类结果对分类性能进行评价,以改进分类器。
以发明原理为分类标准的专利文本分类过程如图2所示。主要步骤包括:
(1)专利样本库的准备 专家对从USPTO网站下载的专利进行分析,确定每篇专利应用的发明原理,根据发明原理对专利做分类标记。结合上文提到的10个发明原理,对人工分类后的专利数据集,挑选有代表性的专利共293份作为专利样本库。再将其分为训练集(含198份专利)和测试集(含95份专利)两个部分。
(2)分析发明原理并对其进行知识表示 对选取的10个发明原理,基于工程语义,提取关键词,分别用描述性文本信息来表示(如表1)。
(3)选择专利中合适的成分作为专利信息的代表 专利文本一般具有相对统一的格式,包含几大部分,具有明确的标志引导,因此计算机选取每篇专利的某些部分代表该篇专利的全文容易实现。选择专利的哪些部分更好,需要通过人工分析专利所获取的经验和进行分类实证来确定。
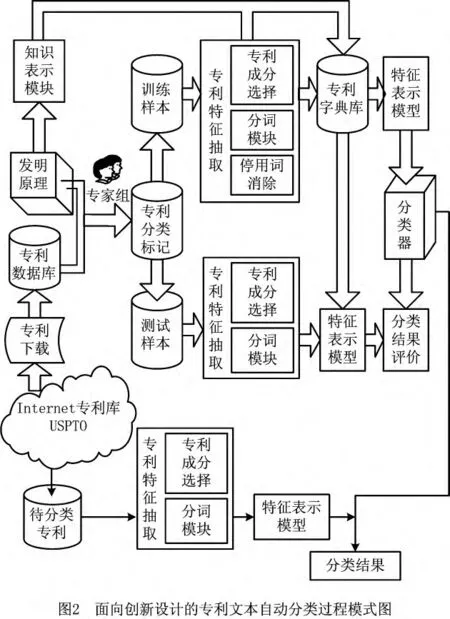

(4)对专利所选择的部分进行特征抽取 本实验所用的每篇专利文本都由单词、标点符号、数字、空格和其他符号等组成,系统以单词作为特征项,经过词根还原和去除停用词,将文本表示成字词集合(如图3)。本实验研究中引入著名的Porter算法进行词根提取。通过查阅停用词表来消除停用词,停用词表的建立参考了文献[10],并根据具体应用对停用词表进行了修正,在原停用词表的基础上追加了一些词汇,例如:invention,field,public,require,system,provide,thereby,technique,method等,停用词的增加或删除可以在系统实验中根据测试集的分类结果适当调整,以改进分类效果。
(5)专利文本的特征选择和特征模型的建立通过特征选择,进一步滤除与任务不相关的冗余特征,选取与类别相关性较大的字词作为特征,并建立专利文本的向量空间模型。本实验中,应用文本分类中常用的特征函数信息增益和x2统计[11],对特征抽取后的所有特征进行计算,得到特征值,然后将其降序排列,选择值高的特征,这样对于每一个发明原理,筛选出针对该发明原理的特征项。特征选择后,为了满足计算机分析处理的需要,将专利文本表示成数学模型的形式,每篇专利中的每个特征用特征权重来表示。特征权重的常用计算方法为词频—文档倒排频率(Term Frequency-Inverse Document Frequency,TF-IDF),在传统的 TF-IDF公式的基础上,本实验提出了基于类别信息的特征权重计算方法,特征项的权重计算应用类别加权的TF-IDF公式来计算,如式(1)所示:
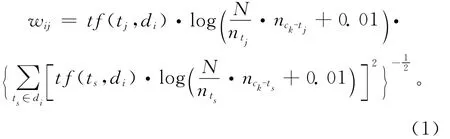
式中:wij表示特征tj在专利文本di中的权重,tf(tj,di)表示特征tj在di中的词频,N 为文本集中的文本总数,ntj为文本集中包含特征tj的文本数,nck-tj为某一类别ck(k=1,2,…,m )中包含特征tj的文本数,ts(ts∈di)为文本di中的各个特征。
(6)分类器的建立 选择分类方法并对训练样本集合的分类模型进行学习,构建分类器。本实验中的分类方法选用k最近邻(k Nearest Neighbor,kNN)[12]和朴素贝叶斯(Naive Bayes,NB)[13]。
(7)分类器的测试 应用分类器对测试集自动分类,将计算机分类的结果和人工分类结果进行比较,对分类器的性能进行评价。若结果不满意(如分类的准确率、所消耗的时间和空间等),则返回到(3)或(4)~(6),得到新的分类器,直至结果满意。
(8)分类器的实际应用 将分类器应用于待分类的专利,根据发明原理对专利进行分类。
在专利分类研究中,专利样本数量的多少、专利代表成分的选择、特征抽取、特征选择、分类方法和分类性能评价的方法,都是影响分类结果的重要因素。尤其是训练阶段发明原理的知识表示、特征抽取和特征选择,是分类的关键步骤,需要从自然语言的专利文本中把能代表分类特征的向量提取出来,为训练做准备。
3.2 专利文本分类的系统功能实现及其实验结果
3.2.1 系统实现和部分界面
本文以PC机为硬件基础,以Windows 2003为操作平台,应用面向对象的开发工具Visual Studio 2000,编程语言为Visual C++,开发了以发明原理为分类标准的专利文本分类软件系统。系统运行的主体界面如图4所示。

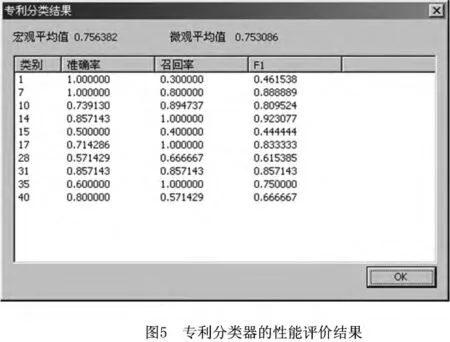
首先选择专利成分代表专利的内容,点击“加载数据后”自动抽取专利代表份进行文本预处理,包括去除停用词和噪声词,取词根;然后在特征词选择组合框,选择一种特征选择方案进行特征选择;接着在分类选择组合框,选择一种分类方法。当选择测试专利时,系统对测试专利样本进行分类,并对分类器的性能进行评价,评价结果如图5所示;点击“预览结果”显示分类器的分类结果和实际类别,如图6所示。用户分析比较分类结果,确定分类器。分类器确定后,用户要对待分类的专利进行分类,经过加载数据,选择合适的特征选择方案,然后选择“分类文本路径”单选框,利用“浏览”按钮打开待分类专利的文件夹,选取合适的分类方法,即可完成分类。

3.2.2 实验结果及分析
在专利文本分类研究中,分类评价指标使用了查准率、查全率、F1测度[14]、宏平均F1和微平均F1[15],分别从专利文献中选取不同的代表成分,应用不同的特征选择评估函数,采用不同的分类方法,对专利进行分类并对分类结果进行性能评价和比较。表2的数据是对293份专利样本库,选取专利标题和摘要代表专利内容,采用基于文档频的x2统计进行特征选择的条件下选取不同的特征数,分别使用kNN和NB进行分类实验所记录的宏平均F1的部分数据。通过表2可以看出,朴素贝叶斯模型比k最近邻的分类效果要好,当特征数为90时,朴素贝叶斯分类的宏平均达到了0.756 382。

表2 两种分类器的分类性能评价数据
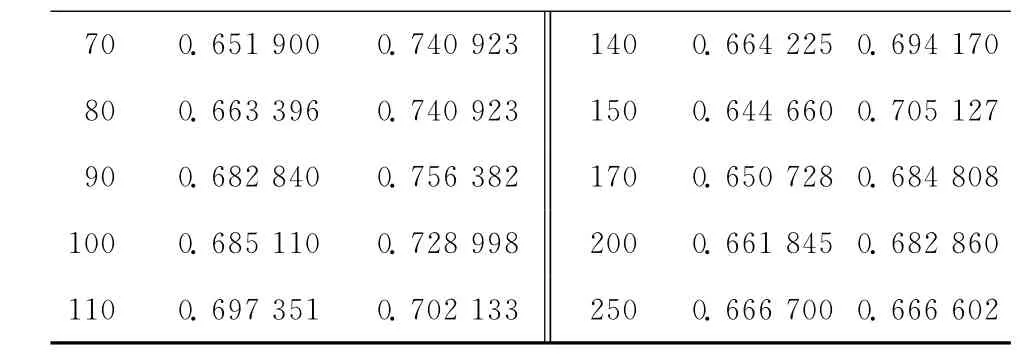
续表2
4 应用实例
融合发明原理和文本挖掘技术对专利进行自动分类的根本目的是提高产品创新的能力,作者已提出了针对 TRIZ用户的专利分析方法[16-17],并在此基础上开发了专利自动分类系统。下面结合圆网造纸机的创新设计具体说明。
4.1 造纸机的现有问题
为了提高生产率,需要提高圆网造纸机的圆网转速。在造纸机的成形部,湿纸的形成取决于纸浆在圆网上的着留率。当速度高于临界值后,离心力大于粘着力,纸浆脱离网,无法形成湿纸。因此面临的问题是如何提高车速、又要能形成湿纸,这是一个典型的技术矛盾问题。
4.2 利用TRIZ求解冲突
按照TRIZ理论中技术冲突解决问题的一般过程,应用39个工程参数将特定问题一般化,上述问题可描述为:如何提高速度,又不使物质的损失加剧。把冲突的描述翻译成标准工程参数,改进的工程参数为速度,恶化的工程参数为物质损失。然后利用冲突矩阵得到4个推荐的发明原理,分别是:No.10预操作、No.13反向、No.28机械系统的替代、No.38加速强氧化。接下来就需要根据发明原理得到一般解决方案。
4.3 原理方案的形成
下面以10号发明原理预操作为例,分析发明原理到一般方案的具体过程。
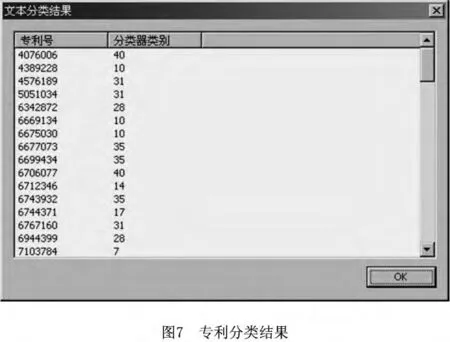
预操作的详细解释为:①在操作开始前,使物体局部或全部产生所需的变化;②预先对物体进行特殊安排,使其在时间上有准备,或已处于易操作的位置。虽然描述性的阐述对预操作进行了一定的解释,但表达简练抽象、不易理解。这种情况下,需要参考包含预操作原理的专利,来拓宽设计人员的思路。从美国专利商标服务局USPTO网站上的专利数据库中随机下载了80份专利,选取专利标题和摘要代表专利内容,利用专利分类系统进行了自动分类。学习样本是前面提到过的198份专利,应用基于文档频的x2统计进行特征选择(特征数=90),应用基于文档频的贝叶斯进行分类,部分结果如图7所示,其中美国专利号码为4389228,6669134等的专利被分类为10,即应用了10号发明原理预操作。
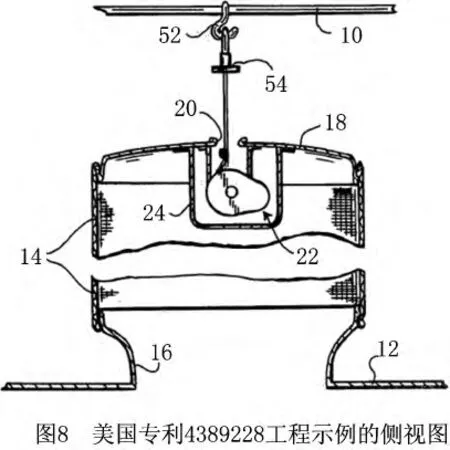
美国专利4389228的大致描述如下:固定张力调整装置(constant tensioning device),国际专利分类号为B65H75/38,该专利的简要描述如下:一种对过滤袋装配保持适当张力的张力调整装置,包括一个旋转的凸轮、使凸轮沿一个方向旋转的扭转弹簧和一个用来对抗弹簧压力的环绕凸轮的缆绳。由于凸轮形状的原因,缆绳与凸轮转动轴之间连续不断变化的距离使缆绳产生拉力。弹簧、凸轮和缆绳按照要求排列,这样当弹簧对凸轮施加一个相对较大的弹力时,缆绳从距离凸轮转轴较远的距离对凸轮施加一个反作用力。反之,当弹簧对凸轮施加一个相对较小的弹力时,缆绳从距离凸轮转轴较近的距离施加作用力。一个恒力拉索就这样产生了。电缆给的压力是个常量。这个装置可以安装在过滤袋和过滤袋的支撑结构中,如图8所示。即使过滤袋在长度上变化,张力也会保持不变,因为它所引起的弹力的改变可由作用在凸轮不同位置的缆绳弥补。
从专利4389228受到启示,得到原理方案:既然提高速度会加大离心力,那么如果能预先提供一个和离心力相反的力,以抵消离心力的作用,将会减少纸浆从网笼上的飞出。沿着这个方向可以找到解决问题的两个方法:①在笼外加压,使得笼外的压力高于笼内,这样产生一个向内的压力,抵消部分离心力,这种圆网称为压气式圆网;②将圆网笼内抽真空,使笼内压力低于笼外,这样将产生一个向心力,可以抵消部分离心力,这种圆网称为真空圆网。
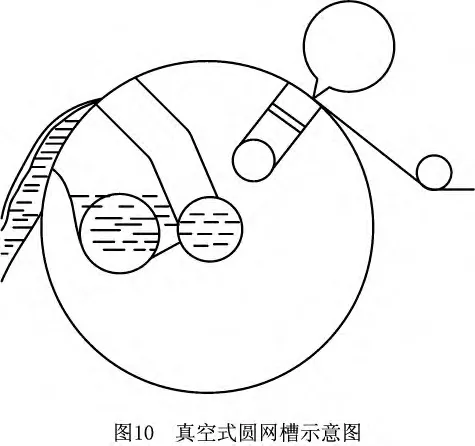
压气式圆网是在网笼的外面形成正压,对已成形的湿纸页施加一定的气垫压力。其结构如图9所示。由贴在网面上的湿纸页、浆槽内的纸料液面、网槽两边的侧板和后板、毛毯等组成一个封闭小室,用鼓风帆向室内送入空气,使小室内保持一定的压力。这样可以抵消部分离心力的作用。真空圆网和压气圆网原理相反,是在网内抽真空以增大脱水压力差,其结构如图10所示。

压气式圆桶和真空式圆桶都可以抵消部分离心力的作用,可以较好地完成创新性能要求,压气式圆桶的实现更容易,因此采用压气式圆通的创新设计方案。
通过造纸机的技术改进,可以看出找到冲突进行求解的过程中,对发明原理的应用和理解是产生设计方案的核心,产品创新需要不同领域知识的支持,专利知识库是创新设计研究的基础工作之一。
5 结束语
应用TRIZ得到能实现设计需求的发明原理,由发明原理转化为原理解的捷径是借助运用同种发明原理的现有产品专利。为迅速发现对口专利,本文提出并进行了面向创新设计对专利进行分类的研究,不仅延展了专利研究的角度和应用,还可促进发明原理对应专利知识库的建设,推动TRIZ理论自身的发展和完善。本文针对创新设计中专利知识挖掘的方法和应用进行了一定深度的研究和探索,取得了初步成果,但还有很多工作需要深化和提高,今后将探索专利文献中包含的工程语义,结合关联规则、模式匹配、语义相似度等方法,进行进一步的研究。
[1] ZLOTIN B,ZUSMAN A.Directed evolution philosophy,theory and practice[M].San Francisco,Cal.,USA:Ideation International Inc.,2001,3:40-48.
[2] TAN Runhua.Innovation design—TRIZ:theory of inventive problem solving[M].Beijing:China Machine Press,2002(in Chinese).[檀润华.创新设计——TRIZ:发明问题解决理论[M].北京:机械工业出版社,2002.]
[3] ALTSHULLER G.Creation is an exact science[M].Guangzhou:Guangdong People's Press,1987(in Chinese).[阿里特舒列尔.创造是精确的科学[M].广州:广东人民出版社,1987.]
[4] GUO Jieting,XIAO Guohua.The Study of patent information analysis[J].Journal of Information,2008(1):12-15(in Chinese).[郭婕婷,肖国华.专利分析方法研究[J].情报杂志,2008(1):12-15.]
[5] FALL 段 ,TORCSVARI A,BENZINEB K,et al.Automated categorization in the international patent classification[J].ACM SIGIR Forum,2003,37(1):10-25.
[6] CHEN L,TOKUDA N,ADACHI H.A patent document retrieval system addressing both semantic and syntactic properties[C]//Proceedings of the ACL 2003Workshop on Patent Corpus Processing.Stroudsburg,Pa.,USA:ACL,2003:1-6.[7] TSENG 段 ,LIN L N,LIN L N.Text mining techniques for patent analysis[J].Information Processing and Management,2007,43(5):1216-1247.
[8] LOH 段 ,HE C,SHEN H .Automatic classification of patent document for TRIZ users[J].World Patent Information,2006,28(1):6-13.
[9] HE C,LOH 段 .Grouping of TRIZ inventive principles to facilitate automatic patent classification[J].Expert System with Applications,2006,34(1):788-795.
[10] Stop word list-words filtered out by search engine spiders[EB/OL].[2012-03-18].http://www.seo-innovation.com/support files/stopwordlist.pdf.
[11] YANG Y.PEDERSEN 段 .A comparative study on feature selection in text categorization[C]//Proceedings of the 14th International Conference on Machine Learnings.San Francisco,Cal.,USA:Morgan Kaufmann,1997:412-420.
[12] YANG Y.An evaluation of statistical approaches to text cate
gorization[J].Information Retrieval,1999,1(1/2):69-90.
[13] LEWIS 段 .Naive(bayes)at forty:the independence assumption information retrieval[J].Lecture Notes in Computer Sciences,1998,1398:4-15.
[14] VAN RIJSBERGEN 段 .Information retrieval[M].Boston,Mass.,USA:Butterworth,1979.
[15] LEWIS 段 .Evalatig text categorization[C]//Proceedings of Speech and Natural Language Workshop.San Francisco,Cal.,USA:Morgan Kaufmann,1991:312-318.
[16] LIANG Yanhong,TAN Runhua,WANG Chaoyang,et al.Computer-aided classification of patents oriented to TRIZ[C]//Proceedings of the IEEE International Conference on Industrial Engineering and Engineering Management.Washiton,D.C.,USA:IEEE,2009:2389-2393.
[17] LIANG Yanhong,TAN Runhua,MA Jianhong.Patent analysis with text Mining for TRIZ[C]//Proceedings of the 4th IEEE International Conference on Management of Innovation and Technology.Washington,D.C.,USA:IEEE,2008:1147-1151.
