基于信息熵的山西省“十二五”水污染物总量分配初探
2013-08-23周玉芬孙鹏程
周玉芬,曾 剑,孙鹏程
(山西省环境规划院,山西 太原 030002)
水污染的总量控制制度实施以来,其在推进企业污染治理、调整产业结构、促进经济发展方式转变、改善区域环境质量方面的作用有目共睹。山西作为我国重要的煤炭、电力、焦化、冶金和化工产业基地之一,在1985—2005年间,受产业结构不合理、环保基础设施落后等因素影响,省内水环境质量严重恶化。“十一五”期间,通过实施总量控制,山西省COD排放量逐年减少,2010年较2005年下降13.93%,超额完成减排目标。但是目前总量控制在实施过程中仍然存在一些问题,“十一五”期间简单按照各地历史排污量进行总量控制目标的确定与分配,给管理上带来诸多困难,如各市总量控制目标与环境容量不协调、客观上限制了某些经济落后地区的发展等问题。结合山西省“十二五”时期水污染物总量分配的管理目标要求和污染物总量管理的战略需求,以COD和氨氮为例,依据系统工程的信息论中常用的熵法,进行山西省各地市水污染物总量初步分配测算。
1 基于信息熵的水体污染物总量分配方法
1.1 信息熵简介
熵的概念起源于热力学。1908年,Shannon首先在信息论中引入了熵的概念,将其定义为信息熵。目前,信息熵已在工程技术、社会经济等领域得到了较多的应用。信息熵的概念可以用来评价系统的均衡性,个体之间越是接近,差异越不显著,信息熵就越大,系统越均衡。在决策方面,还可以利用信息熵的概念确定属性的权重。根据信息熵理论,信息熵是信息不确定性的度量,熵值越小,所蕴含的信息量越大,若某个属性下的熵值越小,则说明该属性在决策时所起的作用越大,应赋予该属性较大的权重。
1.2 信息熵应用于总量分配的思路
在全面了解各分配对象的自然属性和社会经济发展现状的前提下,以污染物排放量、人口、GDP、水资源量等作为控制指标,运用信息熵法对各分配对象排放的污染物总量进行分配。分配过程中以各地市削减比例可行上下限作为约束条件优化调整分配方案。基于信息熵的污染物总量分配技术路线,如图1所示。

图1 基于信息熵的污染物总量分配技术路线
1.3 总量分配指标的确定
结合国内外关于污染物影响要素的分解研究和山西省COD、氨氮减排的要素管理需求分析,在综合考虑系统内各区域间的客观差异的情况下,秉承公平效率的原则,从经济规模和结构、人口、科技、污染治理水平、水环境状况、水资源禀赋六方面构建山西省水体污染物总量分配指标体系,如表1所示。同时,根据各指标代表的实际意义以及公平分配准则,确定了指标的削减规则。
1.4 基于信息熵的总量分配方法
根据表1确定的指标体系收集各地市数据为基础指标(xij),列出判断矩阵,如表2所示。

表1 山西省水体污染物总量分配指标体系

5城镇生活污水COD(氨氮)去除率越大,说明处理边际成本高,应该少削减 N城镇生活污水COD(氨氮)去除率6单位国土面积排放强度水资源量越大,说明区域环境容量禀赋越好,可消纳污染物越多,允许该区域多削减污染源以充分利用其纳污能力单位国土面积排放强度越大,说明区域环境压力越大,区域发生环境风险的概率越大,应多削减 p 7水资源量P 8Ⅴ-劣Ⅴ类比重Ⅴ-劣Ⅴ类比重越大,表明该地区环境质量较差,区域污染物应多削减,以降低区域水环境风险 P
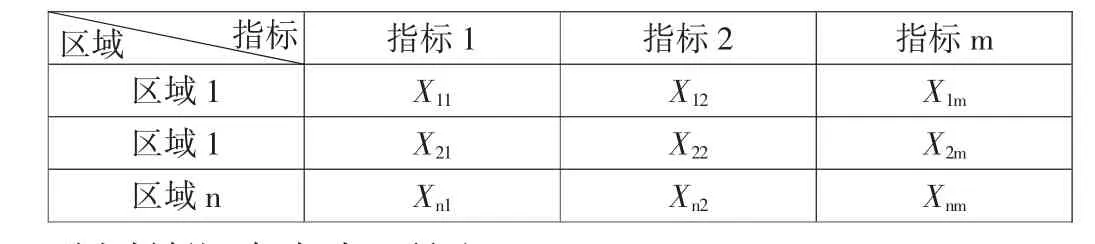
表2 指标矩阵
分别计算系统内各区域主要控制指标所占该指标总量的比重,以及单位指标负荷污染物的量,计算公式为:

式中:Xij——指标矩阵中第i个区域第j项指标的单位负荷污染物量;
Wij——第i个区域内分配污染物排放量即决策变量;
xij——第i个区域内第j项指标的实际值;
Pij——第j项指标下第i个区域的值在此指标中所占的比重。
推荐理由:作者透过自然、细致的画面,再现出老鼠们的智慧、勇敢、机警、群策群力、动脑创造的积极人生观。书里的画面丰富多彩、细腻唯美,每一页都隐藏着好多惊奇,好多神思,仔细阅读才会发现,反复体味才有惊喜。
计算每项控制指标的单位负荷污染物量的信息熵,当Pij=0时,Pij·lnPij=0,H(X)j=1,说明各个区域之间完全没有差异。
总量分配指标j的信息熵效用与其熵值成反比关系。根据信息熵熵权权重模型确定各项总量分配指标的权重wj.
各区域相对削减水平ci.

各区域削减率ri,分配量wi.
式中:r——全省“十二五”COD(氨氮)目标削减率;
wi(0)——地区的COD(氨氮)现状排放量。各区域基于现状的削减比例约束。

1.5 基础数据来源
2010年山西省统计年鉴、污染普查数据、环境质量监测数据、减排核查数据等。
2 水污染物总量分配方案确定
根据《山西省“十二五”主要污染物总量削减目标责任书》,计划到2015年,全省COD和氨氮排放量(工业、生活)分别比2010年减少10.6%、12.4%,农业源暂不分析。
2.1 数据处理及分配方案拟定
依据水污染物总量分配方法,对工业源、生活源水污染物进行初步分配,关键参数及分配方案如表3和表4所示。

表3 基于信息熵法的总量分配法的关键参数

表4 基于信息熵法的总量分配方案
综合考虑各地市水污染物总量控制预定目标,即(减排量-新增量)/现状排放量,并根据现状排放情况,对分配方案进行优化调整,优化后的分配方案如图2所示。

图2 优化调整的总量分配方案
2.2 结果分析
总量分配指标j的信息熵效用与其熵值成反比关系,指标的信息熵效用值越大,则表明该指标在总量分配中所起作用越大,最能突出分配对象之间的异质性特征;反之,则越小。由表3可知,影响COD和氨氮总量分配的指标主要有Ⅴ-劣Ⅴ类比重、单位工业增加值污染强度以及工业和生活污染物去除率。
由表4和图2可知,通过信息熵法确定的重点削减区域为运城、临汾、大同和太原等地区,COD和氨氮的削减比例分别为15.1%、11.64%、12%、11.2%和15.7%、13.2%、14%、13.8%,基本符合山西省各地市目前的水污染治理水平和削减潜力,表明该分配方案基本合理;运行SPSS软件分析Wi(0)与ri的相关性,得R2COD、R2氨氮分别为0.669,0.779,相关性较强。结合图2可知,Wi(0)和ri的大小之间并不是一一对应的关系,即最终优化分配方案并非是只针对污染物排放量大的地市。
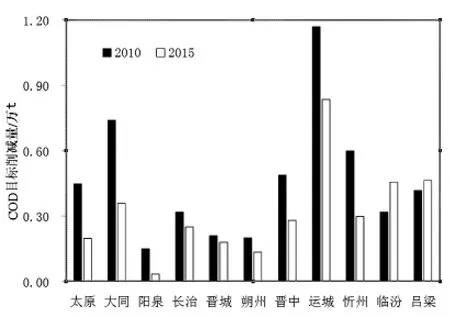
图3 调整后的分配方案与“十一五”分配方案比较
将调整方案与“十一五”期间我省水污染物总量分配方案进行对比,由图3可知,各地的削减量变化特征也有较大的差异,削减量大小与各地的削减率目标和COD总量基数有关,长治、晋城、朔州等地的削减量变化较小,而运城、大同、太原、忻州等地的削减量变化较大,有的地区是呈正向变化,如临汾、吕梁,表明这些地区的减排需求相对较大;从削减量分配的总体格局来看,以运城、大同、临汾、吕梁为主的格局仍未转变过来,尽管这些地区的削减率总体下降。
3 结束语
本文综合了现有的公平准则,尝试采用信息熵的概念来度量单位人口、经济和环境资源指标所负荷污染物区域差异的大小,以待分配区域的单位指标负荷污染物信息熵最大化作为评判水污染物总量区域分配公平的准则,客观反映分配量和指标之间机理和逻辑上的定量联系,减少污染物总量分配的主观性。
采用信息熵原理对“十二五”山西省水污染物总量进行分配,结果显示,该方法能较好地体现分配指标的相对重要性信息和山西省总量管理战略需求,且运行过程简单易操作、计算结果客观。优化后的各地市分配量与其人口、经济和环境资源状况匹配性提高,公平性增强,反映出区域差异对污染物总量分配方案的影响,分配结果可以为污染物总量控制工作提供决策依据。
[1]吴悦颖,李云生,刘伟江.基于公平性的水污染物总量分配评估方法研究[J].环境科学研究,2006,19(2):66-70.
[2]孙娟,吴悦颖,叶维丽,等.水污染物总量综合权重系数分配方法研究[J].水文,2011,31(4):40-44.
[3]刘娜,谢绍东.中国不同经济区域大气污染总量分配方法的选择研究[J].北京大学学报(自然科学版),2007,43(6):803-807.
[4]王媛,张宏伟,杨会民,等.信息熵在水污染物总量区域公平分配中的应用[J].水利学报,2009,40(9):1103-1105.
[5]刘巧玲,王奇.基于区域差异的污染物总量削减总量分配研究——以COD削减总量的省际分配为例[J].长江流域资源与环境,2012,21(4):512-517.
