基于用户兴趣模型的元搜索引擎算法研究
2013-08-20王倩宋朝
王倩,宋朝
(黄河科技学院 河南 郑州 450063)
搜索引擎是获取信息的重要手段[1],在使用普通搜索引擎搜索信息时,总是存在这样的问题[2-3]:返回的结果数目庞大,很多结果与查询并不相关,依然要花费大量的时间寻找有用的信息。为了帮助用户在避免无用信息干扰的情况下获得其所需的信息,提高查询效率,本文研究了基于用户兴趣模型的元搜索引擎实现技术,利用元搜索引擎修正普通搜索引擎搜索范围较窄,检索结果不够全面的缺点;利用构建用户兴趣模型消除歧义,缩小用户查询的范围,修正元搜索引擎在处理不同用户需求方面的不足。
1 构建用户兴趣模型
用户兴趣建模的过程是根据用户的个人信息和偏好的浏览内容进行归纳量化,设计出可以用数学方式表示的用户兴趣模型[4]。
1.1 用户兴趣模型总体结构
模型的结构及创建步骤如图1所示。用户的访问历史集存放在页面集合库中,长期兴趣库和短期兴趣库中按照时间长短存放经兴趣分析以及兴趣特征优化后得到的兴趣信息。

图1 用户兴趣模型总体结构Fig.1 User interest model structure
1.2 用户兴趣类别表示
在模型中的兴趣生成模块需要构建兴趣类别。我们通过对兴趣特征等级特性的定义来生成一个开放目录,对用户可能有的兴趣特征采用一个分类的层次结构模型表示。这是一个类似于对象继承的关系结构。兴趣特征基类包含兴趣特征派生类的所有共同特征,而兴趣特征派生类相比兴趣特征基类则具有各自不同的特点属性。结构如图2所示,图中兴趣类别用方框表示,特征词和扩充的特征词用椭圆表示。
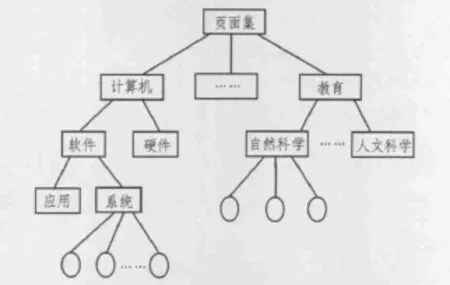
图2 用户兴趣分类参考模型Fig.2 User interest classification model
根据该参考模型,我们可以构建用户兴趣树形结构,考虑到用户兴趣的动态变化和局部性,对兴趣类别和特征词可以分别赋予不同的权值。
以 C 表示用户兴趣集,其包含元素为(c1,c2,…,cm),m 表示用户的兴趣类别总数目,ci(1≤i≤m)为集合C的一个元素,代表一个兴趣类别。以T(ci)表示用户兴趣特征词集合,其包含元素为(t1,t2,…,tk),k 表示用户兴趣特征词总数目,ti(1≤i≤k)表示为ci的特征词。所以用户所有特征词集的并集就是用兴趣特征词集,表示为T(C)。即:

以二元组(c,w)表示用户兴趣节点 Node(c),c∈C,w 为 c的权重。 以二元组(t,w)表示 c 的特征词节点 Leaf(c,t),t∈T(c),w为t在c中的权重。以此为基础,我们以m元组U(C)来表示用户的兴趣向量,其表示形式为 Node(c1),Node(c2),…,Node(cm))。
1.3 用户查询到用户兴趣类别的映射算法设计
本节提出一种生成用户兴趣类的方法。通过该方法,可以对用户的查询信息确定用户兴趣类别[5-6]。这个过程的主要步骤是对用户查询信息与已建模的用户兴趣类别之间的相似度进行计算,把用户的查询结果限制在相似度最高的几个用户兴趣类别中。
将用户查询 q 表示为向量(t1,t2,…,tm),其中每个分量代表查询q的一个查询特征词,查询特征词的总数目为m。查询q的查询特征词集我们用Q表示。存在两种情况:
1)假设q中的查询特征词在用户兴趣树中所属的所有兴趣类别集合用C(q)表示,c(c∈C)表示用户兴趣类别,它的特征词表示为集合(w1,w2,…,wn),记作 p(c)。 其中 wi是它所对应的特征词ti在用户兴趣类别c中的权重,即
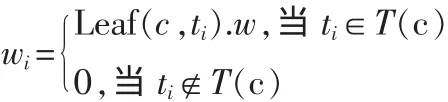
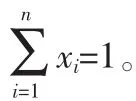
2)若用户查询对应的兴趣类别不存在于用户兴趣类别中,即T(C)∩Q=Φ,则可以进行如下定义:
用Cr表示兴趣分类参考模型中所有兴趣类别的集合,用户兴趣类别 c(c∈Cr)的查询特征词权重向量 p(c)中的 wi定义为:

根据上述两种情况,可以从用户兴趣向量U(C)和用户查询条件q得到计算用户查询条件和用户兴趣类别相似度的算法,进而得到跟用户查询条件相近的用户兴趣类别。
2 基于兴趣分类采样的成员引擎特征表示
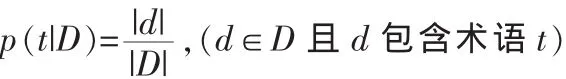
在构建数据库的特征表示之前,定义TD(ci)表示兴趣类别 ci的分类辞典,且有 TD(ci)={t|t∈T(ci)∧ci∈Cq},所有兴趣类别的分类辞典总辞典表示为 TD(Cq)={TD(c1),TD(c2),…,TD (cn)},n为兴趣类别的总数。也就是说TD来源于两个方面,一方面是表示ci的类别名;另一方面是类的特征词。
我们假设D′是由数据库D中采样文档d的集合组成,D′数据库创建的内容摘要为 S(D′),则 S(D′)就是数据库 D 的近似内容摘要[9]。对数据库D′按照用户兴趣分类,可以得到D′={D′(c1),D′(c2),...,D′(cn)},近似内容摘要 S′(D)也进行细分为 S′(D)={S′(c1,D),S′(c2, D),...,S′(cn, D)}, 其中 D′(ci)表示在数据库D′中根据兴趣类别ci采样得到文档的集合所组成的数据库。S′(ci,D)则表示以上数据的创建的近似内容摘要。
数据库D基于用户兴趣类别ci的近似内容摘要S′(ci,D)是由两个基本部分组成:
第一部分是 D′(ci)中实际文档总数目|D′(ci)|;
第二部分是数据库D′(ci)中包含的所有术语t及其权值p′(t|D′(ci)),其中
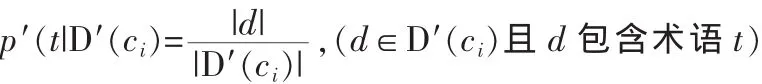
常用的成员引擎特征表示方法有:基于查询采样(Query-Based Sampling,QBS)[7]的近似内容摘要表示法和聚焦探测(Focused Probing,FP)[8]的近似内容摘要构建算法。我们将用户兴趣模型同近似内容摘要法相结合,提出了一种新的算法:基于用户兴趣分类的近似内容摘要表示法。
为方便构建算法,对近似内容摘要给出相关的描述如下。
首先规定数据库D的内容摘要S(D)由两部分组成:第一部分是D中实际文档总数,表示为|D|;第二部分是D中包含的所有术语t及其权值p(t|D),其中
利用以上描述就能够根据不同兴趣类别较好地表示对应数据库的近似内容摘要,并且可以表达出不同的搜索引擎数据库基于用户兴趣类别的文档信息。
3 基于用户兴趣模型的元搜索引擎调度算法
本节中提出的算法能根据用户的兴趣爱好来选择调度最接近用户偏好文档的搜索引擎。采用基于用户兴趣分类采样的特征表示算法来表示数据库的特征。在用户提交查询信息到搜索引擎时和用户兴趣类别进行映射,得到相应的兴趣类别。元搜索引擎调度模块首先根据用户兴趣类别对成员引擎数据库和用户查询信息之间相似度进行计算,然后根据计算所得的相似度结合用户兴趣类中成员搜索引擎的权重和搜索引擎对用户查询的平均响应时间计算得出成员搜索引擎同用户查询信息之间的相关度。算法原理及实现描述如下:
3.1 数据库与用户查询的相关度计算
假设 D 为数据库,M 元组(D1,D2,…,Dm)为元搜索引擎中所有成员搜索引擎的数据库集,记作DS[10]。根据上节可以得到各个数据库的近似内容摘要。第i个数据库Di的近似内容摘要记作 S′(D),S′(D)={S′(c1,Di),S′(c2,Di),...,S′(cj,Di)}(1≤i≤m,1≤j≤n)。 其中 n 为用户兴趣类别数目,S′(cj,Di)为数据库Di在用户兴趣类别ci的近似内容摘要。t表示用户查询术语,q表示用户查询,为 t的h元组集合,则 q=((t1,t2,...,th)。 其中,h 为查询术语数目。
还需要作查询q与数据库集合DS中包含的每个数据库相关度的计算[11]。假设查询q与数据库Di的相似度记为rel(q,Di),计算它的前提是要先完成三个值的计算[12-13],下面分别进行表述。
1)查询q与数据库的近似内容摘要的相似度计算
在前面的算法中我们已经得到了与查询q相关度最高的用户兴趣类别集合,一般我们取前2~3个,用CS表示。

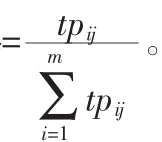
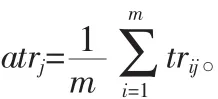

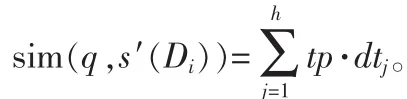
2)用户对成员引擎的偏好权重的计算
用户若频繁使用搜索引擎,应该会察觉到某些成员搜索引擎会比其他成员引擎更好地搜索到有用的信息,也会较多地点击该成员引擎返回的结果。系统会记录最近k次用户对查询结果的点击情况以监测成员引擎对用户查询的帮助表现。用户越多地浏览从某个数据库返回的结果,越说明这个数据库更受用户的偏好。

3)成员引擎对用户查询的平均响应时间计算。
为避免使用响应时间太长的成员引擎,系统会记录成员引擎在用户的最近k次查询中响应时间的平均值tr。系统事先规定th为响应时间阈值,to为响应超时时间[14],若对于某个成员引擎Di,tr的值大于th,则该成员引擎对用户查询的权值减少量为 pr(Di)=(tr-th)2/(to-th)2。
4)查询q与数据库的相关度计算
有了上面3个值之后,查询q与数据库Di的相关度可用下式计算出来:

3.2 元搜索引擎调度成员引擎的过程
1)将用户查询q与各成员引擎数据库的相关度计算出来;2)将成员引擎根据相关度降序排列;
3)根据排序后的列表,选择相关度最大的几个成员引擎为用户提供查询服务。
3.3 调度算法的特性分析
根据前文中对调度算法的推导过程可以做如下特性分析:
1)若成员引擎的所有文档中与用户查询映射的兴趣类相关的较多,则该成员引擎与用户查询的相关性较高;
2)用户查询若具有较高的区分能力,则更易于选择合适的成员引擎用于此查询。
3)成员引擎越多地被用户点击,就越能获得较高的相关度;
4)成员引擎对用户查询的响应时间也会影响其相关度高低。
4 结束语
随着信息技术的不断发展,网络已经成为人们工作和生活都离不开的工具,同时人们对从网上获取信息的方式也提出了更高的要求,用户迫切要求改进搜索方式。本文本着应对用户需求,提高搜索效率和精度的目标,研究了怎样将个性化搜索技术融入到元搜索引擎中,在理论上确定了可行算法。本文根据用户描述信息设计了用户兴趣模型,并进行了量化表示;研究了将用户查询映射到用户兴趣模型的算法,便于推测用户兴趣范围,提高查询结果精度。同时本文改进了元搜索引擎的成员引擎调度算法,选择对用户最可能有用的成员引擎完成检索工作,使查询质量和查询效率能明显改进。
[1]乔亚男,齐勇,侯迪.文本信息检索实验方法研究[J].中国科技论文在线,2009,4(2):126-129.
QIAO Yan-an,QI Yong,HOU Di.Research on experimental methods of text information retrieval[J].Sciencepaper Online,2009,4(2):126-129.
[2]张宗仁,杨天奇.基于主题树的个性化元搜索引擎[J].计算机工程与设计,2011,32(1):149-152.
ZHANG Zong-ren,YANG Tian-qi.Personalized meta search engine based on subject tree[J].Computer Engineering and Design,2011(32):149-152.
[3]杨智奇,朱大勇.个性化元搜索引擎的研究与设计[J].计算机与现代化,2009,(9):52-55.
YANG Zhi-qi,ZHU Da-yong.Research on personal meta search engine[J].Computer and Modernization,2009, (9):52-55.
[4]LI Zheng-wei,XIA Shi-xiong,NIU Qiang,et al.Research on the User Interest Modeling of personalized Search Engine[J].Wuhan University Journal of Natural Sciences,2007,12(5):893-896.
[5]Gauch S,Wang G,Gomez M.ProFusion:Intelligent fusion from multiple,distributed search engines[J].Journal of Universal Computer Science,1996,2(9):637-649.
[6]Howe A E,Dreilinger D.SavvySearch:A meta-search engine that learns which search engines to query[J].AI Magazine,1997,18(2):19-25.
[7]Callan,J.P.; Connell,M.,Query-based sampling oftext databases[Z].ACM TOIS, 2001,19(2)
[8]Panagiotis,G.,Ipeirotis,Gravano,L., Summarizing and searching hidden-web databases.hierarchically using focused probes[R].Technical Report CUCS-015-01,Columbia University, Computer Science Department,2001.
[9]徐科,黄国景,崔志明.元搜索引擎中基于用户兴趣的个性化调度模型[J].清华大学学报:自然科学版,2005,45(S1):1916-1919.
XU Ke,HUANG Guo-jing,CUI Zhi-ming.Personalized scheduling algorithm based on user profile for meta search engine[J].J Tsinghua Univ:Sci&Tech,2005,45(S1):1916-1919.
[10]ZHANG Wei-feng,XU Bao-wen,ZHOU Xiao-yu,etal.Scheduling in a meta search engine by Genetic Algorithm[J].Wuhan University Journal of Natural Sciences,2001,(Z1):541-546.
[11]Salton G,McGill M J.Introduction to Modern Information Retrieval[M].New York:McGraw-Hill,1983:103-106.
[12]任洪平.中文元搜索引擎成员搜索引擎的选择策略研究[J].图书馆学研究,2009(01):40-43.
REN Hong-ping.Study on Sub-Search Engine Scheduling Strategy for Chinese Meta Search Engine[J].Researches in Library Science,2009(1):40-43.
[13]李村合,孟文杰.基于分类评价的元搜索引擎调度策略[J].计算机工程与设计,2008,29(5):1065-1066.
LI Cun-he,Meng Wen-jie.Scheduling strategy for meta search engine based on categorizing measurementof members[J].Computer Engineering and Design,2008,29(5):1065-1066.
[14]Dreilinger D,Howe A.Experiences with selecting search engines using metasearch[J].ACM TOIS,1997,15(3):195-222.
[15]Callan JP,ConnellM.Query-based sampling oftext databases[J].ACM TOIS,2001,19(2):102-108.
